在强化学习中,环境(Environment)是智能体(Agent)进行学习和互动的场所,它定义了状态空间、动作空间以及奖励机制。Env Wrapper(环境包装器)提供了一种方便的机制来增强或修改原始环境的功能,而不需要改变环境本身的代码。
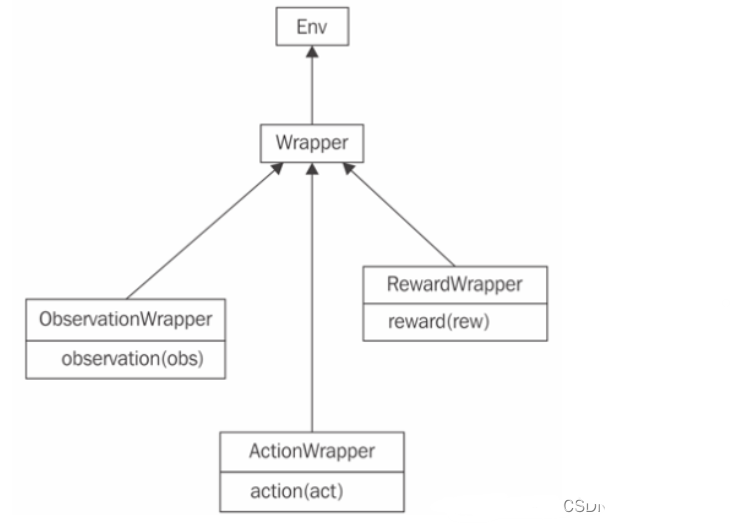
Env Wrapper主要有以下的几个特性
1.预处理和归一化:
- 为了提高学习效率和稳定性,很多时候需要对环境的状态进行预处理,例如归一化处理,使得所有的输入特征都处在同一量级上,以便于智能体更好地学习。
- Env Wrapper可以在不修改原始环境代码的情况下,添加这些预处理步骤。
2.奖励形状改变(Reward Shaping):
- 有时原始环境的奖励信号太稀疏或不利于学习,Env Wrapper可以用来修改奖励信号,使之更加符合特定学习任务的需求。
3.动作和状态空间修改:
- 如果需要对动作空间进行离散化或者对状态空间进行降维,Env Wrapper允许用户实现这样的变换。
- 这对于将复杂环境简化以适应低容量智能体或算法尤其有用。
4.实验一致性和复现性:
- 当研究者想要分享他们的实验设置或与其他研究者进行比较时,使用Env Wrapper可以确保所有人都在相同的环境变种上进行实验。
5.代码的模块化和复用:
- 通过Env Wrappers,可以创建可复用的模块,对不同的环境应用相同的处理逻辑。
- 这样可以避免代码冗余,提高开发效率。
6.易于维护和扩展:
- 当需要更新环境处理逻辑时,只需修改对应的Env Wrapper,而不需要重新触碰环境本身的实现。
例如,若要为一个环境添加噪声处理或者状态的标准化处理,可以创建一个Env Wrapper来实 现这些功能。这样,当需要在不同的环境中实施同样的噪声或标准化处理时,只需要将环境
通 过这个Env Wrapper传递即可,而不需要为每个环境单独编写处理代码。
DI-engine 提供了大量已经定义好的、通用的 Env Wrapper
DI-engine 继承和扩展了 OpenAI Gym 的设计,提供了一系列通用的 Env Wrapper,以便用户可以轻松地根据自己的需求来修改环境。以下是这些 Env Wrapper 的简介:
1.NoopResetEnv:
- 在环境启动时随机执行一定数量的无操作(no-op)步骤,然后再重置环境。这有助于提供更多样化的初始状态。
2.MaxAndSkipEnv:
- 在连续的几个帧中执行相同的动作,并从中选取两个连续帧的最大值作为代表,这样做可以减少环境内的非必要变化,有助于稳定训练。
3.WarpFrame:
- 将输入的图像帧缩放到固定的大小(例如 84x84)并转换为灰度图像,这是许多深度强化学习工作中的常见做法。
4.ScaledFloatFrame:
- 将图像帧的像素值从整数转换为浮点数,并将其标准化到 0 到 1 的范围内。
5.ClipRewardEnv:
- 将奖励剪裁为 -1, 0, 或 +1,根据奖励的正负性。这样做有利于限制梯度更新的规模,有时能够增加训练的稳定性。
6.FrameStack:
- 将连续的几个帧堆叠在一起作为网络的输入,以提供给智能体关于动作的时间连续性信息。
7.ObsTransposeWrapper:
- 重新排列观测数组的维度,这在处理图像输入时特别有用,如将图像数据从 HxWxC 调整为 CxHxW。
8.RunningMeanStd:
- 计算和更新环境观测值的均值和标准差,通常用于环境状态的归一化处理。
9.ObsNormEnv:
- 使用实时更新的均值和标准差归一化观测值,以保持输入值的分布稳定。
10.RewardNormEnv:
- 使用实时更新的均值和标准差归一化奖励值,帮助稳定训练过程。
11.RamWrapper:
- 将环境的 RAM 状态转换为类似图像的格式,这对于处理非图像的原始状态表示特别有用。
12.EpisodicLifeEnv:
- 当智能体“死亡”时,即使游戏没有真正结束,也会结束当前的 episode。这可以让智能体更快地学习有关失败的信息。
13.FireResetEnv:
- 在某些游戏中,环境重置后需要执行一个 “fire” 动作来开始游戏。这个 Wrapper 自动处理这个动作。
二、如何使用 Env Wrapper
下一个问题是我们如何给环境包裹上 Env Wrapper。最简单的一种方法就是手动地显式对环境进行包裹:
from ding.envs.env_wrappers.env_wrappers import NoopResetWrapperenv = gym.make(env_id) # 'PongNoFrameskip-v4'env = NoopResetWrapper(env, noop_max = 30)env = MaxAndSkipWrapper(env, skip = 4)我们也可以尝试在gym中使用FrameStack环境包裹器
import gymfrom gym.wrappers import FrameStack# 创建并包裹环境env_id = 'CartPole-v1'env = gym.make(env_id)env = FrameStack(env, num_stack=4)# 使用包裹后的环境运行一些episodefor episode in range(2): obs = env.reset() done = False step = 0 while not done: action = env.action_space.sample() # 随机选择动作 obs, reward, done, info = env.step(action) print(f"Episode: {episode}, Step: {step}, Observation Shape: {obs.shape}, Reward: {reward}, Done: {done}") step += 1 print(f"Episode {episode} finished after {step} steps.")# 关闭环境env.close()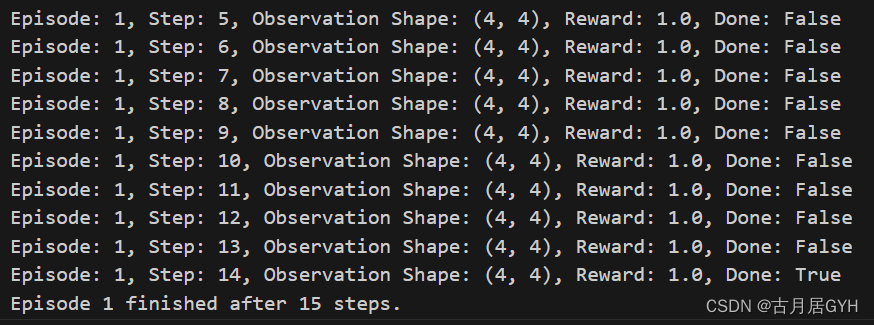
以下是在 Python 中非显式的使用 Env Wrapper 的具体示例:
点击DI-engine强化学习入门(九)环境包裹器(Env Wrapper) - 古月居可查看全文