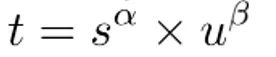【爬虫】第七部分 scrapy
文章目录
- 【爬虫】第七部分 scrapy
- 7. scrapy
- 7.1 基本使用
- 7.2 项目的文件结构
- 7.3 response的方法和属性
- 7.4 小案例
- 7.5 scrapy 工作原理
- 7.6 管道的使用
- 7.7 多管道下载
- 7.8 下载分页类型和get请求的使用
- 7.9 下载多层级类型
- 7.10 post请求的使用
- 总结
7. scrapy
7.1 基本使用
-
pip install scrapy安装 -
在终端运行以下代码:
scrapy startproject 项目名字创建爬虫项目(名字不要中文) -
cd 进入到 spiders,再运行下面创建爬虫文件的指令

scrapy genspider 爬虫文件名 要爬取的网页 创建爬虫文件(名字不要中文)
ex: scrapy genspider xxx www.xxx.com
这个时候我们就会看到spiders下面生成了xxx.py文件

- 运行爬虫文件
scrapy crawl 爬虫文件名字,注意运行之前到settings中将robot协议改了,才可以爬取

7.2 项目的文件结构
scrapy 项目的文件结构
- 项目名
- 项目名
- spiders
init
自定义的爬虫文件
- init
- items 定义数据结构的地方
- middleware 中间件 代理
- pipelines 管道 用来处理下载下来的数据
- settings 配置文件 robots协议 us定义等
7.3 response的方法和属性
extract(): 这个方法返回的是一个数组list,里面包含了多个string,如果只有一个string,则返回[‘ABC’]这样的形式。
extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫文件的名字,用于运行爬虫的时候使用
name = 'baidx'
# 允许访问的域名
allowed_domains = ['www.baidx.com']
# 起始的url地址,指的是第一次要访问的域名
# 这里需要注意一下,一般情况下将start_urls中 / 给去掉,不然容易出现一些问题
start_urls = ['http://www.baidx.com']
# 该方法中的response相当于 response = requests.get()
def parse(self, response):
res1 = response.text # 拿到的是字符串,网页源码
res2 = response.body # 拿到的是二进制数据
print("===========================================================")
# 可以直接使用xpath的方法
content = response.xpath('//input[@id="su"]/@value')
# 使用extract()方法进行提取
print(content.extract())
7.4 小案例
爬取汽车信息
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://xxx.autohome.com.cn/price/brand-15.html']
start_urls = ['https://xxx.autohome.com.cn/price/brand-15.html']
def parse(self, response):
print("===========================")
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever-right"]/div/span/span/text()')
for i in range(len(name_list)):
res = name_list[i].extract() + '---> ' + price_list[i].extract()
print(res)
7.5 scrapy 工作原理

根据上述的流程图,绘制下图:

- 首先将spiders向引擎提供url
- 引擎将要爬取的url给调度器
- 调度器会将url生成请求对象放入到指定的队列中,队列中出队一个请求给引擎
- 引擎将请求件给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载回来
- 下载器将数据返回给引擎
- 引擎将数据交给spiders,通过xpath解析数据
- 解析后的 数据 或者 url 交给引擎
- 引擎进行判断,如果是url则交给调度器,进行上述操作,如果是数据就交给管道保存下来
7.6 管道的使用
-
创建项目 :
scrapy startproject dangdang -
进入到spiders去创建爬虫文件 :
scrapy genspider dang_data https://book.dangdang.com/01.03.htm?ref=book-01-A -
编写创建出来的爬虫文件
import scrapy # 导入定义数据结构 from dangdang.items import DangdangItem class DangDataSpider(scrapy.Spider): name = 'dang_data' allowed_domains = ['https://book.dangdang.com/01.03.htm?ref=book-01-A'] start_urls = ['https://book.dangdang.com/01.03.htm?ref=book-01-A'] def parse(self, response): # src //ul[@class="list_aa"]//li[@type="rollitem"]//li/a/img/@src # bookname //ul[@class="list_aa"]//li[@type="rollitem"]//li/p[@class="name"]/a/text() # author //ul[@class="list_aa"]//li[@type="rollitem"]//li/p[@class="author"]/text() base = response.xpath('//ul[@class="list_aa"]//li[@type="rollitem"]//li') # 只要是selector对象就可以继续调用xpath for item in base: # 在这里需要注意加上 . ,表示当前 src = item.xpath('./a/img/@src').extract_first() bookname = item.xpath('./p[@class="name"]/a/text()').extract_first() author = item.xpath('./p[@class="author"]/text()').extract_first() # book实际上就是通过items整理好的对象,将该对象交给pipelines下载 book = DangdangItem(src=src, bookname=bookname, author=author) # 使用yield 把对象交给pipelines yield book -
在items文件中定义数据结构
import scrapy class DangdangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 在这里需要去定义你要下载的数据有哪些 # 图片 src = scrapy.Field() # 书名 bookname = scrapy.Field() # 作者 author = scrapy.Field() -
settings去开启管道

-
在pipelines文件中编写
# 在使用管道前,需要去settings下开启管道 class DangdangPipeline: # 这是一个在爬虫文件开始之前就执行的一个方法 def open_spider(self, spider): self.f = open('book_msg.json', 'w', encoding='utf-8') def process_item(self, item, spider): # 这里的item就是yield返回过来的对象 # write方法必须接受一个字符串而不能是其他的对象,需要强转 self.f.write(str(item)) # 注意一定要返回 return item # 在爬虫文件执行完之后执行的一个方法: def close_spider(self, spider): self.f.close()
7.7 多管道下载
-
在pipelines原先的基础上模仿写
# 在使用管道前,需要去settings下开启管道 class DangdangPipeline: # 这是一个在爬虫文件开始之前就执行的一个方法 def open_spider(self, spider): self.f = open('book_msg.json', 'w', encoding='utf-8') def process_item(self, item, spider): # 这里的item就是yield返回过来的对象 # write方法必须接受一个字符串而不能是其他的对象,需要强转 self.f.write(str(item)) return item # 在爬虫文件执行完之后执行的一个方法: def close_spider(self, spider): self.f.close() import urllib.request # 开启多管道下载 class DangdangDownload: def process_item(self, item, spider): url = 'https:' + item.get('src') filename = './books/' + item.get('bookname') + '.png' urllib.request.urlretrieve(url=url, filename=filename) return item -
到settings文件中去添加新的管道,一样模仿这写
# 开启管道,管道是有优先级的,优先级的范围是1-1000,值越小优先级越高 ITEM_PIPELINES = { 'dangdang.pipelines.DangdangPipeline': 300, # 开启多管道 'dangdang.pipelines.DangdangDownload': 301 }
7.8 下载分页类型和get请求的使用
创建出来的爬虫文件
import scrapy
import json
from pptmodel.items import PptmodelItem
class PptDemoSpider(scrapy.Spider):
name = 'ppt_demo'
# 对于下载分页这种类型,allowed_domains需要写成域名
allowed_domains = ['theuser.zhuisoft.com']
start_urls = [
'http://theuser.zhuisoft.com/template/ajax_web/data_list?class=&type_id=0&order_by=0&title=&format=&page=0&num=40']
def parse(self, response):
res = response.text
data = json.loads(res).get('data')
for item in data:
title = item.get('title')
img = item.get('cover_img')
ppt = PptmodelItem(title=title, img=img)
yield ppt
# 下载3页
for i in range(1, 3):
url = f'http://theuser.zhuisoft.com/template/ajax_web/data_list?class=&type_id=0&order_by=0&title=&format=&page={i}&num=40'
# scrapy.Request 就是scrapy的get请求,注意这里调用函数不能写括号
yield scrapy.Request(url=url, callback=self.parse)
7.9 下载多层级类型
创建出来的爬虫文件
import scrapy
from movie_demo.items import MovieDemoItem
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['0dytt.com']
start_urls = ['https://0dytt.com/frim/1.html']
"""
案例描述:
1. 需要在首页拿到电影名和跳转的链接
2. 请求跳转的链接,xpath解析,拿到电影海报
"""
def parse(self, response):
# href //div[@class="hy-video-list"]//li/a/@href
# title //div[@class="hy-video-list"]//li/a/@title
base = response.xpath('//div[@class="hy-video-list"]//li/a')
for i in base:
href = 'https://0dytt.com' + i.xpath('./@href').extract_first()
film_name = i.xpath('./@title').extract_first()
# 这个时候去请求拿到的新链接
# 在这里使用meta参数用来将电影名传入parse_picture
yield scrapy.Request(url=href, callback=self.parse_picture, meta={"film_name": film_name})
# 因为页面结构的不同不能像上一个案例那样调用自己,所以需要创建一个新的函数
def parse_picture(self, response):
all_actor = ''
style = response.xpath('//div[@class="hy-video-details clearfix"]//a/@style').extract_first()
lead_actor = response.xpath('//div[@class="hy-video-details clearfix"]//ul/li[1]//a/text()').extract()
for actor in lead_actor:
all_actor = all_actor + actor
film_name = response.meta['film_name']
start = style.find('(')
end = style.find(')')
src = 'http' + style[start + 6:end]
info = MovieDemoItem(src=src, film_name=film_name, lead_actor=all_actor)
yield info
pipelines文件
class MovieDemoPipeline:
def open_spider(self, spider):
self.f = open('movie.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.f.write(str(item) + ',')
return item
def end_spider(self, spider):
self.f.close()
import urllib.request
import random
class MoviePicture:
def process_item(self, item, spider):
src = item.get('src')
filename = 'posters/' + item.get('film_name') + '.jpg'
# 在这里遇到了防爬,所以需要进行伪装
ua_list = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.62',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'
]
# 创建opener对象
opener = urllib.request.build_opener()
# 给opener添加请求头
opener.addheaders = [('User-Agent', random.choice(ua_list))]
# 将opener设置为全局安装
urllib.request.install_opener(opener)
urllib.request.urlretrieve(url=src, filename=filename)
return item
7.10 post请求的使用
import scrapy
import json
class TranslateSpider(scrapy.Spider):
name = 'translate'
allowed_domains = ['fanyi.baidu.com']
# start_urls = ['http://fanyi.baidu.com/sug']
# def parse(self, response):
# pass
"""
这里的写法,和我们使用get请求就不一样了
因为post请求需要携带参数,而start_urls第一次请求没有办法携带,
导致parse函数接收不到response,所以注释掉
"""
def start_requests(self):
url = 'http://fanyi.baidu.com/sug'
data = {
"kw": "hello"
}
# scrapy.FormRequest()就是post请求
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_1)
def parse_1(self, response):
res = response.text
print(json.loads(res))
总结
以上就是今天要讲的内容,希望对大家有所帮助!!!