Dataset & DataLoader
PyTorch 提供了两个数据处理的基本方法:torch.utils.data.DataLoader torch.utils.data.Dataset 允许使用预加载的数据集以及自己的数据。 Dataset 存储样本及其对应的标签, DataLoader 在 Dataset 基础上封装了一个可迭代的对象,以方便访问样本。
PyTorch 提供了许多预加载的数据集(如 FashionMNIST ) 这些数据集继承了 torch.utils.data.Dataset 类,并实现了特定数据的函数。它们可以用来创建模型原型和基准测试。Image Datasets, Text Datasets, 和 Audio Datasets
Loading a Dataset (加载数据集)
下面是一个加载 FashionMNIST 数据集的例子。 FashionMNIST 数据集包含了 60000 个训练样本和 10000 个测试样本,每一个样本是 28*28 的灰度图像和对应标签(一共 10 个类别)。
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="../../data", # 存放数据的路径
train=True, # 是训练数据集还是测试数据集
download=True, # 如果存储的路径里没有数据集的话,就从网络下载数据集
transform=ToTensor() # 数据转换
)
test_data = datasets.FashionMNIST(
root = "../../data", # 存放数据的路径
train=False, # 是训练数据集还是测试数据集
download=True, # 如果存储的路径里没有数据集的话,就从网络下载数据集
transform=ToTensor() # 数据转换
)
Iterating and Visualizing the Dataset (迭代和可视化数据集)
我们可以像索引列表一样对数据集进行索引,如 training_data[index], 使用 matplotlib 对数据进行可视化。
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(10, 10))
cols, rows = 3, 3
for i in range(1, rows * cols + 1):
sample_idx = torch.randint(0, len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.numpy().reshape(28, 28), cmap="gray")
plt.show()

Creating a Custom Dataset for your files (用自己的文件定制数据集)
一个定制的数据集需要实现 3 个函数: __init__, __len__, __getitem__。 FashionMNIST 图片存储在 img_dir 里,它们的标签存储在 CSV 标注文件里。
下一个章节中,我们会详细分析这些函数。
import os
import numpy as np
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
__init__
当实例化 Dataset 对象时,__init__ 函数执行一次,需要包括包含图片和标注文件的路径,以及它们是否需要转换。
labels.csv 文件结构如下:
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
__len__
__len__ 函数返回数据中样本数量。
__getitem__
__getitem__函数从给定索引 idx 处的数据集中加载并返回一个样本。基于索引,它识别图像在磁盘上的位置,使用 read_image 将其转换为一个 tensor ,从 csv 数据中提取对应的标签,调用它们上的变换函数(如果适用),并在元组中返回 tensor 图像和相应的标签。
Preparing your data for training with DataLoaders
Dataset 每次从一个样本中提取我们数据集中的特征样本和标签用于训练模型,通常情况下,我们希望在每个 epoch 传递多个样本 “minibatches” ,打乱顺序从而可以减少模型的过拟合,并且可以加速数据的提取。 DataLoader 是一个迭代器,将这些复杂的事情抽象成一个非常简单的 API 。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=4, num_workers=0)
test_dataloader = DataLoader(test_data, batch_size=4, num_workers=0)
Iterate through the DataLoader ( 通过 DataLoader 迭代取数据 )
我们已经将 dataset 加载进 DataLoader 里了,并且可以通过 dataset 迭代取数据。每个迭代返回一批 train_features 和 train_labels。 见 Samplers。
train_features, train_lables = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.shape}")
print(f"Label batch shape: {train_lables.shape}")
img = train_features[0].squeeze()
label = train_lables[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
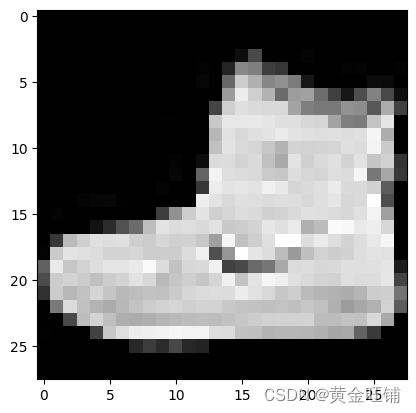
Feature batch shape: torch.Size([4, 1, 28, 28])
Label batch shape: torch.Size([4])
Label: 9
【参考】
Datasets & DataLoaders — PyTorch Tutorials 1.13.1+cu117 documentation