在《C++11实现一个自旋锁》介绍了分别使用TAS和CAS算法实现自旋锁的方案,以及它们的优缺点。TAS算法虽然实现简单,但是因为每次自旋时都要导致一场内存总线流量风暴,对全局系统影响很大,一般都要对它进行优化,以降低对全局系统的负面影响,本文讨论一下它的优化方案。
下面是使用atomic_flag原子类+TAS算法实现的自旋锁代码。
class spin_lock final {
atomic_flag lock_var{false}; // 锁变量
public:
void lock() {
while (lock_var.test_and_set(memory_order_acquire));
}
void unlock() {
lock_var.clear(memory_order_release);
}
};
从上面的代码可以看到,在调用lock()函数申请锁时,只要锁变量lock_var的值不是false,就会无条件的循环执行test_and_set(),执行的太频繁了,以至于其它CPU的运行都要受到影响。因为一个CPU在test_and_set()执行时要原子事务写lock_var变量到内存中,每执行一次就导致一场内存总线流量风暴,其它CPU要访问内存就得竞争内存总线。如果竞争不到,得停下来等待内存总线的释放,造成CPU一定程度上处于“失速”状态。如果几个线程同时在申请锁,每一次TAS的原子事务写内存,都会加剧内存总线的竞争程度。
如何进行优化呢?
双检查机制
在实现单例模式时,我们知道有一种针对互斥锁的优化方案,叫做双检查锁机制,它的基本思想是先使用执行成本低的代码来检查条件是否满足,如果条件满足,再使用执行成本高的代码,即互斥锁的方式去检查条件。
可以借鉴这个思想来对TAS算法进行优化,基本思路是在调用TAS之前,先读取锁变量,此过程是只读内存操作,相比RMW操作是轻量级的操作,没有全局影响和副作用,执行成本较低。然后对读取的值进行判断,如果是true,则继续循环重复此过程,直到返回false,说明有线程已经释放锁了,此时退出循环,再进行重量级的TAS操作。也就是仅在必要的时候才执行TAS操作,这样,即使TAS操作导致的全局影响很大,但是它发生的次数却大为降低了。
因为C++11版的atomic_flag原子类没有提供读取原子变量的接口,直到C++20版本才提供了成员函数test(),它返回原子变量的值,可以使用这个接口来实现双检查操作。下面是修改后的lock()函数代码:
void lock() {
while (true) {
// 第一次检查:使用Test操作
while (lock_var.test(memory_order_relaxed));
// 第二次检查并设置:TAS操作
if (!lock_var.test_and_set(memory_order_acquire)) {
break; // 成功获得锁,跳出循环
}
}
}
与前面的实现相比,多了一个test()循环调用,同时原来的test_and_set()循环调用变成了单次调用,只有在test()检测到lock_var为false时退出循环之后,才会进行test_and_set()调用。
循环代码“while (lock_var.test(memory_order_relaxed))”就是上面说的第一次检查操作,调用atomic_flag::test()接口返回lock_var的值,这里没有内存顺序的需要,因此使用了最松散的内存序,如果返回值是true,则继续循环,如果是false,则退出循环,立刻进入第二次检查,这时为什么还要进行检查呢?因为第一次检查不能原子地设置lock_var为true,所以还得要使用TAS操作,由于已经检测到lock_var为false了,这次执行TAS成功的几率非常高。
由此可见,该方式在自旋锁中的实现逻辑是Test-Test-And-Set,所以也简称为TTAS算法。
为了查看TTAS的实现细节,我们看一下它的汇编指令代码,下面是使用-std=c++20编译选项,生成的汇编指令:
spin_lock::lock():
mov edx, 1
.L17:
// 从内存中读取锁变量的值
movzx eax, BYTE PTR [rdi]
// 判断是否是0,即false,第一次检查 Test
test al, al
// 如果不是0,则回退
jne .L17
mov eax, edx
// 第二次检查并设置:TAS操作
xchg al, BYTE PTR [rdi]
test al, al
jne .L17
ret
看第一次检查(第3-9行),在每次检查时都要从内存[rdi]处读取变量lock_var,然后检查是否为0,即false,如果不为0,则继续退回去重新读取再检查,一直循环执行“读取-判断-回退”的逻辑,直到读出的lock_var为0为止。注意,这里的读取指令是“movzx eax, BYTE PTR [rdi]”,是非常简单的指令,它从内存中加载一个字节的数据到寄存器al中,也是一条原子操作指令,但该指令不会锁总线。根据MESI缓存一致性协议,如果lock_var的值没有被别的CPU修改过,那么它就在当前CPU的L1 cache缓存中会一直有效,也就是只要内存中的lock_var的值没有被更新,该指令执行时就会一直从L1 cache中读取,即没有访问内存,也就不会占用内存总线,不会影响其它CPU,只在本CPU中循环,所以第一次的循环检查也被称为“本地自旋”(见汇编指令代码第5(读取)、7(判断)、9(回退)行)。
1、提高了整体吞吐量性能
同TAS算法相比,TTAS算法大大减轻了对内存总线的竞争程度,也降低了TAS执行时为了维持cache一致性而产生的内存总线流量。使用《利用C++11原子操作实现自旋锁》中的测试代码,所测试的TTAS以及TAS、CAS算法的性能数据如下:
TTAS所用时钟周期 TAS所用时钟周期 CAS所用时钟周期
337427552 432447222 177915346
394388223 502814284 279384821
390494013 556108365 227520077
401288104 513192991 346827330
可见,在同样的测试条件,TTAS算法要比TAS算法性能要好,但是仍然比CAS算法要差。
2、增大了个体CPU申请锁时延迟的可能性
TAS算法实现自旋锁时,如果返回了false同时也就获得了锁,检查和设置是一个原子操作,而使用TTAS算法时要对锁变量进行两次检查判断,第一次检查返回false时,只是有可能会获得锁,能否获得还得要使用后面的TAS算法。因此,使用TTAS算法实现,申请锁的速度没有TAS算法快,也就是申请锁时的延迟要比TAS算法大。
因此,可以把Test和TAS的位置调换一下,先进行TAS算法,当一个线程刚进入lock()时,如果锁是释放状态,可能会马上通过TAS来获得锁,而不用等到从Test循环中退出,再使用TAS来竞争锁,能降低一点申请锁的延迟,当然如果第一次没有竞争到锁,就进入了本地自旋,等待lock_var变为false,仍然还是存在延迟。代码如下:
void lock() {
while (true) {
// 第一次检查并设置:TAS操作
if (!lock_var.test_and_set(memory_order_acquire)) {
break; // 成功获得锁,跳出循环
}
// 第二次检查:使用Test操作
while (lock_var.test(memory_order_relaxed));
}
}
3、TTAS是比TAS更“忙”的算法
在TTAS算法中,第一个Test检查过程是本地自旋,它不同于TAS自旋,它的性能更高,执行的速度更快:
首先,先看指令部分,是个微小循环,可以被CPU的循环流检测器(识别和锁定微操作指令队列中小的循环)检测到,并放入trace-cache中,可以在下一次循环时直接使用。下图是它的指令流截图,非常短小精悍,仅有三行指令,指令长度是17-10=7个字节度,被译码单元译码后的微操作码应该也不多(其中jne指令和它前面的test指令还会被宏融合为单一的微操作码),它们存放在CPU的trace-cache里面肯定绰绰有余,注意里面存放的是已经解码完的微操作码,可以被执行引擎直接派发和执行。也就是说对于这个本地自旋小循环,不但不需要从指令cache中获取指令,而且连指令解码过程也被省掉了,此时不会因为程序流程发生跳转了,需要重新从指令cache中加载指令和译码的过程,导致CPU出现流水线的中断。
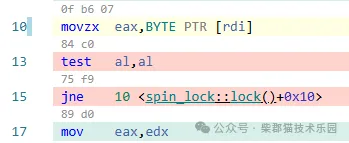
再看数据部分,因为对锁变量数据lock_var是一个只读操作,此时作为热点数据都在L1 cache中,读取时不需要从内存中获取,速度极快,因此,在本地自旋时,也不会出现因为需要加载数据导致CPU流水线中断的情况。此外,因为这个本地自旋运行次数很多,CPU的分支预测单元会发挥作用,知道下一步要跳转到第10行去执行,CPU就会预测执行,这样这三条指令就可以并行执行,即test指令在判断当前lock_ver值的同时,又在读取下一次的lock_var值为下一次test指令做准备,这是指令级的并行化(因为有寄存器重命名机制,第10行更新eax(al是它的低8位)寄存器和第13行测试al寄存器不会冲突,这个写后读是假依赖,可以同时执行)。
也就是说,当CPU处于本地自旋时,无论是指令还是数据,它们都处于CPU的内部,不会发生因为cache miss而中断CPU流水线去等待它们,而且还可以进行指令级的并行化,会一直处于高速运转中,也就是它更“忙”了,当然副作用就是耗电量非常大,这是TTAS算法不好的一面。
4、一旦进入本地自旋,大概率是要空转
再看TTAS算法的代码实现,当第一次检查时,如果一个CPU从本地自旋中退出,说明此时已经有别的CPU把这个lock_var变量置为false了,即别的线程已经把锁释放了。当接着使用TAS操作进行第二次检查时,如果没有设置成功,说明在第一次检查结束和第二次检查开始之间出现了状况:第一种可能它是和别的CPU在执行时间上有重叠,但别的CPU抢先获得了锁;第二种可能是执行流程被中断后又返回了,即有中断或者优先级更高的线程把它抢占了,这个CPU也就暂时没有参与自旋锁的竞争。
我们现在讨论第一种情况,别的CPU抢先获得了锁,然后进入临界区进行业务处理,这也暗示着自旋锁不会马上被释放,那么本CPU肯定会再次进入“本地自旋”并且会持续一段时间。我们不妨估算一下大概需要自旋多长时间:如果想让CPU从本地自旋中退出,至少要等到另一个CPU执行完临界区代码后,调用unlock把false值写入内存变量lock_var,本CPU读取lock_var变量时发现缓存和内存中的值不一致,重新从内存中加载;假设临界区的最小执行时间为t,也就是说最少也要等待CPU一次原子事务写内存的时间,加上一次读内存的时间,再加上t,小于这个时间是不会从循环中退出的,这段时间CPU一直处于空转状态。
也就是说,只要进入本地自旋,大概率是要一直空转的,一直到别的线程执行完临界区代码释放锁后才有可能停止空转。那么,这个空转既然避免不了,在这期间CPU有什么优化措施吗?
x86的pause指令
现代CPU大多提供了超线程技术(即逻辑CPU),即在一个物理核上有两个逻辑核,它们有自己独享的寄存器,但是需要共享执行单元、系统总线和缓存等硬件资源。如果执行自旋操作的CPU是一个逻辑核,当它进入本地自旋的时候,会加剧物理核中的执行资源和系统总线的竞争程度,从而影响其它同一个逻辑核的执行效率。
我们再分析一下TTAS的lock代码的结构特点:代码虽然不多,但是严重同质化,有两次数据传输操作,两次test操作,一次比较交换操作,也就是它们使用相同执行单元的可能性非常大。如果处于自旋的两个线程刚好被分配到同一个物理核的两个逻辑核上运行,两个逻辑核共享执行单元和系统总线,它们在自旋操作时可能会遭遇资源冲突,反而导致整体性能下降。
为了改善这种情况,Intel开发者手册建议使用pause指令优化。intel的CPU针对自旋等待的场景提供了一个指令:pause,该条指令的功能是给CPU一个提示:当前正在进行自旋等待,可以暂停一下,比如等待一个或几个内存总线操作周期的时间之后,然后再继续运行(因为在这期间,CPU是大概率获取不到自旋锁的,与其让CPU自旋忙等,不如停下来休息一下)。因此,一个逻辑核进入了pause状态,也就不再使用系统资源了,这样,同物理核的另一个逻辑核就可以独享物理核的全部资源了,提高了申请锁时响应速度,也降低了CPU的电量消耗。
因为C++中没有相应的函数来执行pause指令,可以在代码中嵌入汇编指令,下面是基于TTAS算法修改后的代码(同样也可以使用pause指令优化基于CAS算法实现的自旋锁):
void lock() {
while (true) {
if (!lock_var.test_and_set(memory_order_acquire)) {
break;
}
while (lock_var.test(memory_order_relaxed)) {
asm("pause");
}
}
}
这情况下能够大大降低CPU执行资源和电量的消耗。不过,这种方法会进一步增加获取锁的延迟性,因为每次自旋条件不符合时就得先pause一段时间,如果在pause期间,锁被释放了,也不会及时的获取锁,只能等到CPU从pause中退出时才有可能。而且这个延迟的时间也不固定:有可能CPU刚刚开始pause,锁就释放了,显然此时延迟最大;也有可能CPU从pause退出时,恰好锁就释放了,显然此时延迟最小,这是最理想的场景。如果应用场景是对响应性能敏感的场景,就得要慎重考虑了,能否容忍使用pause指令带来的延迟损失。
同时我们也知道,当CPU处于pause状态时,什么也不做,不像操作系统提供的yield命令,可以让CPU执行别的任务。让CPU资源处于闲置状态,可能会感觉有点可惜,不过在支持超线程技术的CPU架构体系中可以利用这个特点,在一定程度上缓解逻辑核的资源竞争问题,提高超线程的执行速度,因为一个逻辑核执行pause而处于暂停状态,也在一定程度上缓解了CPU的耗电问题。
不过需要指出的是,当自旋锁保护的临界区执行时间很短时,比如只是简单的几个内存访问和计算,可以使用pause机制;如果自旋锁保护的临界区执行时间很长时,或者一个线程获得自旋锁后接着被抢占了,使用pause机制会让其它申请自旋锁的CPU长时间处于暂停状态,也是一种资源浪费。显然这种情况下不如把CPU分配给别的线程使用,此时涉及到线程被调度的情况了,就得考虑让操作系统参与进来了,比如调用yield,把CPU调度给别的任务,或者直接把当前线程挂起,等到解锁时再唤醒它。
总结
1、TAS算法实现自旋锁,会导致内存总线流量风暴,全局系统影响大。
2、TTAS虽然抑制了流量风暴的产生,减轻了全局内存总线的竞争程度,但是又导致CPU耗电量大、发热等情况。
3、使用pause指令缓解了超线程核心的系统资源竞争和降低了耗电量,但是又增长了获取锁时的延迟。
4、TTAS算法和pause指令是在程序和CPU上面对自旋锁的优化,如果获取不到锁时,线程仍然处于自旋中,不会发生调度和阻塞现象,没有改变自旋锁的本质特征。
参考:
1、https://zh.cppreference.com/w/cpp/atomic/atomic_flag/test
2、Intel® 64 and IA-32 Architectures Software Developer’s Manual
3、《现代x86汇编语言程序设计》 丹尼尔-卡斯沃姆
附录:
下面内容是Intel手册对pause指令的描述。
PAUSE—Spin Loop Hint
Improves the performance of spin-wait loops. When executing a “spin-wait loop,” processors will suffer a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops.
An additional function of the PAUSE instruction is to reduce the power consumed by a processor while executing a spin loop. A processor can execute a spin-wait loop extremely quickly, causing the processor to consume a lot of power while it waits for the resource it is spinning on to become available. Inserting a pause instruction in a spinwait loop greatly reduces the processor’s power consumption.