前言
一个 C 程序究竟是怎么变成可执行程序的,这其间发生了什么?本文将带你简要了解 C 程序编译过程,文章为 《程序员的自我修养—链接、装载与库》的读书笔记,更为详细的过程可以阅读原书。
比如下面一个经典的 C 程序,它可以用来测试我们开发环境是否配置正确,那它经历了什么?
// hello.c
#include <stdio.h>
int main() {
printf("hello world!\n");
return 0;
}
在 Linux 下,我们使用 GCC 来编译该程序只需如下命令:
$ gcc hello.c
$ ./a.out
hello world!
实际上,上述过程可以分为 4 个步骤,分别是预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking)。
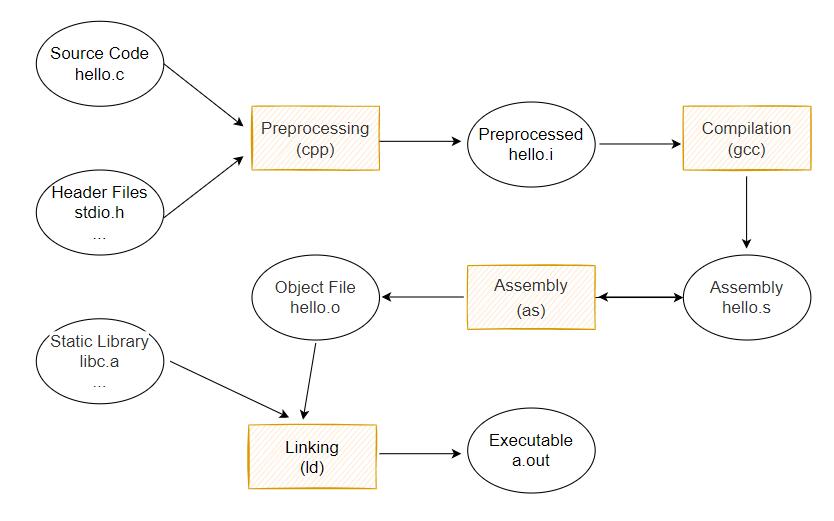
预处理
首先是源代码文件 hello.c 和相关头文件,如 stdio.h 等被预处理器 cpp 预处理成一个 .i 文件。
想得到预处理后的文件可以使用如下命令(-E 表示预处理后便停止):
$ gcc -E hello.c -o hello.i
预处理过程主要工作是处理源代码中以 # 开头的预处理指令。比如 #include、#define 等,主要处理规则如下:
- 删除所有的注释
- 替换所有的宏定义,并将所有的 #define 删除
- 添加行号及文件名标识
- 以便编译时产生编译错误或警告时能显示行号
- 编译时编译器产生调试用的行号信息
- 处理条件编译指令,如 #ifdef、#endif
- 处理 #include 指令,将被包含的文件插入到该预处理指令的位置
- 这个过程是递归进行的,因为被包含的文件可能还包含其他文件
- #include <filename>,将根据相应规则查找该文件
- 就是在编译器定义的一系列标准位置查找函数库头文件
- Linux 的 C 编译器在 /usr/include 目录查找函数库头文件
- #include “filename”,将在源代码所在位置查找该文件
- 如果失败,编译器再按照函数库头文件的处理方式对它们处理
- 保留 #pragam 编译器指令,该语句在编译时使用
经过预处理后的 .i 文件不包含任何宏定义,所有的宏已经被展开了,包含的头文件也已经被插入了。
编译
编译过程就是把预处理完的文件进行一系列的词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。
想得到编译后的文件可以使用如下命令(-S 表示编译后便停止):
$ gcc -S hello.c -o hello.s
编译过程一般可以分为 6 步:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化。
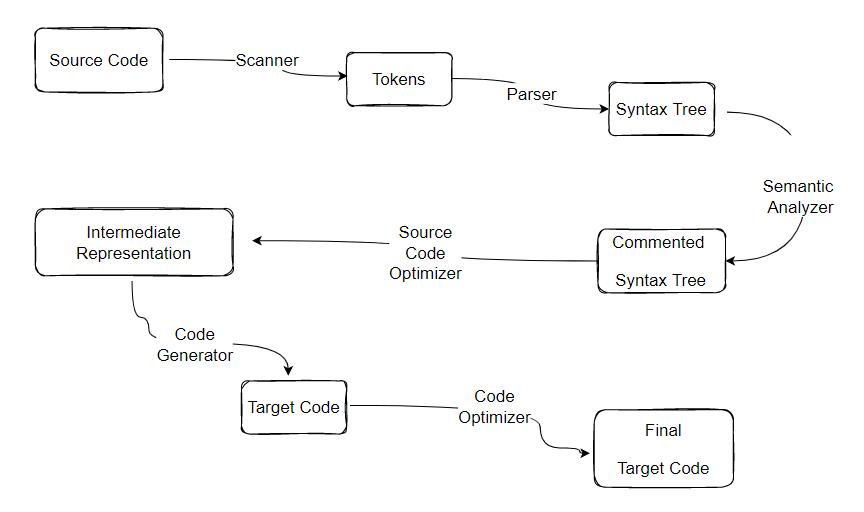
下面以一段简单的 C 语言代码来介绍这个过程:
array[index] = (index + 4) * (2 + 6);
词法分析
首先源代码程序被输入到扫描器(Scanner),它简单地进行词法分析,将源代码的字符序列分隔成一系列的记号(Token)。
上述代码经过扫描后,产生的记号如下:
| 记号 | 类型 |
|---|---|
| array | 标识符 |
| [ | 左方括号 |
| index | 标识符 |
| ] | 右方括号 |
| = | 赋值 |
| ( | 左圆括号 |
| index | 标识符 |
| + | 加号 |
| 4 | 数字 |
| ) | 右圆括号 |
| * | 乘号 |
| ( | 左圆括号 |
| 2 | 数字 |
| + | 加号 |
| 6 | 数字 |
| ) | 右圆括号 |
词法分析产生的记号大致可分为:关键字、标识符、字面值(数字、字符串等)和特殊符号(如加号、减号)。在标识记号的同时,扫描器将标识符放到符号表,将数字、字符串常量存放到文字表。
语法分析
接下来语法分析器(Grammar Parser)将对由扫描器产生的记号进行语法分析,从而产生语法树(Syntax Tree)。由语法分析器生成的语法树就是以表达式(Expression)为节点的树。
上述记号经语法分析器以后形成如下的语法树:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wISRmb6L-1673746047276)(https://qin1230.oss-cn-shenzhen.aliyuncs.com/boke/Syntax%20Tree.jpg)]
整个语句被看作是一个赋值表达式,赋值表达式左边是一个数组表达式,它的右边是一个乘法表达式,等等。
在此阶段如果出现了表达式不合法,比如括号不匹配、表达式中缺少操作符等,编译器就会报告语法分析阶段的错误。
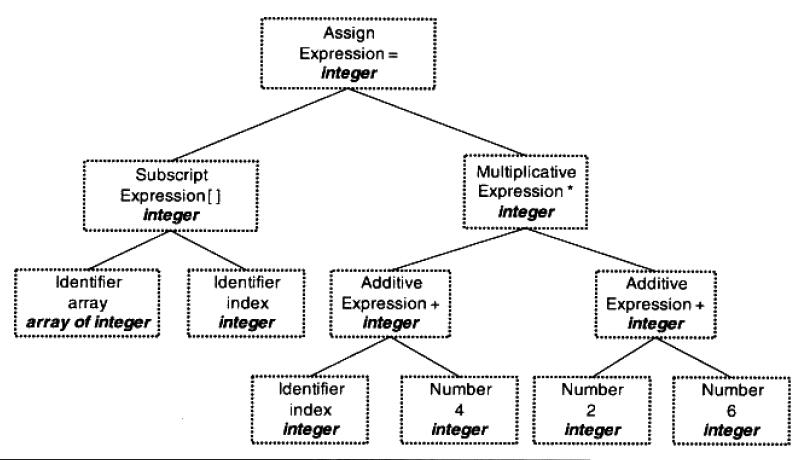
语义分析
接下来进行语义分析,由语义分析器(Semantic Analyzer)来完成。语法分析器仅仅是完成了对表达式的语法层面的分析,但它并不了解这个语句是否有意义。比如 C 语言中两个指针做加法或乘法运算是没有意义的,但这个语句在语法上是合法的。编译器所能分析的语义是静态语义,是指在编译期就可以确定的语义,与之对应的是动态语义只有在运行期才能确定。
静态语义通常包含声明和实际类型的匹配,类型的转换是否可以进行。动态语义一般指在运行期出现的语义相关的问题,比如除 0 错误。
经过语义分析阶段以后,整个语法树都被标识了类型,如果有类型需要类型转换,语义分析会在语法树插入相应的转换节点。
上述语法树经过语义分析后形成下图:
源代码优化
现在的编译器有着很多层次的优化,往往在源代码级别会有一个优化过程。
源代码优化器(Source Code Optimizer)会在源代码级别进行优化,在上例中,(2 + 6)这个表达式可以被优化掉,因为它的值在编译期就可以被确定。
还有一个常见的源代码级别的优化如下:
// 此处的 i++ 会被优化成 ++i
// 因为 i++ 会产生一个临时变量,此处也用不到该临时变量
// 优化成 ++i 可以提高效率
for (int i = 0; i < 10; i++) { ... }
经过优化的语法树如图:
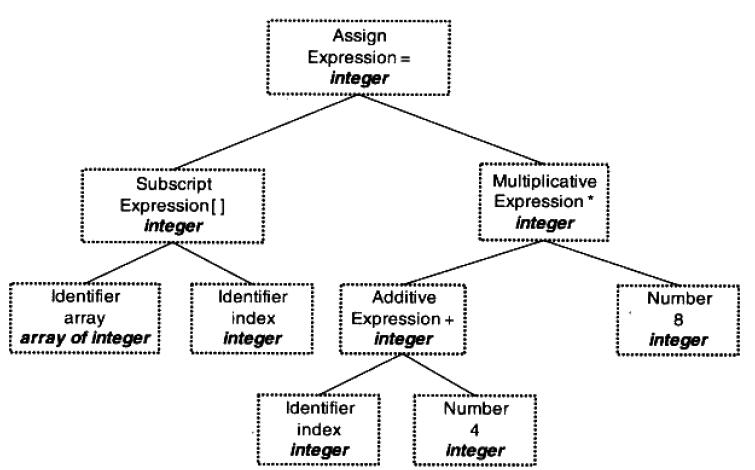
因为直接在语法树上优化比较困难,所以源代码优化器往往将语法树转换成中间代码(Intermediate Code),它是语法树的顺序表示。
三地址码是一种常见的中间代码,它像这样:
x = y op z
这个三地址码表示将 y 和 z 进行 op 操作后,赋值给 x。这里 op 操作可以是算数运算,也可以是其他可以应用到 y 和 z 的操作。上述例子被翻译成三地址码后是这样的:
t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
arrat[index] = t3
这里用到了三个临时变量 t1、t2 和 t3。其中 t1 和 t3 都是不必要的,优化如下:
t2 = index + 4;
t2 = t2 * 8
arrat[index] = t2
目标代码生成及优化
该过程由代码生成器(Code Generator)和目标代码优化器(Target Code Optimizer)完成。
代码生成器将中间代码转化成目标机器代码,上述代码可能会生成如下代码序列(使用 x86 汇编语言表示,并假设 index 的类型为 int,array 的类型为 int 型数组):
movl index, %ecx ; value of index to ecx
addl $4, %ecx ; ecx = ecx + 4
mull $8, %ecx ; ecx = ecx * 8
movl index, %eax ; value of index to eax
movl %ecx, array(, eax, 4) ; array[index] = ecx
最后目标代码优化器对上述目标代码进行优化,比如使用位移来代替乘法、删除多余指令等。乘法由一条相对复杂的基址比例变址寻址的 lea 指令完成,随后由一条 mov 指令完成最后的赋值操作。
movl index, %edx
leal 32(, %edx, 8), %eax
movl %eax, array(, %edx, 4)
经过上述所有过程,源代码最终变成了目标代码。但还有一个问题就是:index 和 array 的地址还没有确定。如果 index 和 array 定义在跟上面的源代码同一个编译单元里面,那么编译器可以为它们分配空间并确认它们的地址,那如果是定义在其他的程序模块呢?这就是之后链接要解决的问题了。
汇编
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编过程相对简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译。
想得到汇编后的目标文件(Object File)可以使用如下命令(-c 表示汇编后便停止):
$ gcc -c hello.c -o hello.o
链接
假如我们在程序模块 main.c 中使用另外一个模块 func.c 中的函数 foo()。我们在 main.c 模块中每一处调用 foo 的地方都必须知道 foo 的地址,但是由于每个模块都是单独编译的,在编译器编译 main.c 的时候它并不知道 foo 函数的地址,所以它暂时把这些调用 foo 的指令的目标地址搁置,等待最后链接的时候由链接器去将这些指令的目标地址修正。
链接器在链接的时候,会根据我们所引用的符号 foo,自动在其他编译模块中查找,在 func.c 模块找到 foo 的地址,然后将它的地址填在 main.c 模块中引用到 foo 的指令的地方。









![[硬核] Bootstrap Blazor Table 综合演示例子](https://img-blog.csdnimg.cn/img_convert/83cc3b1324c50758031c1c2cf53d6547.gif)