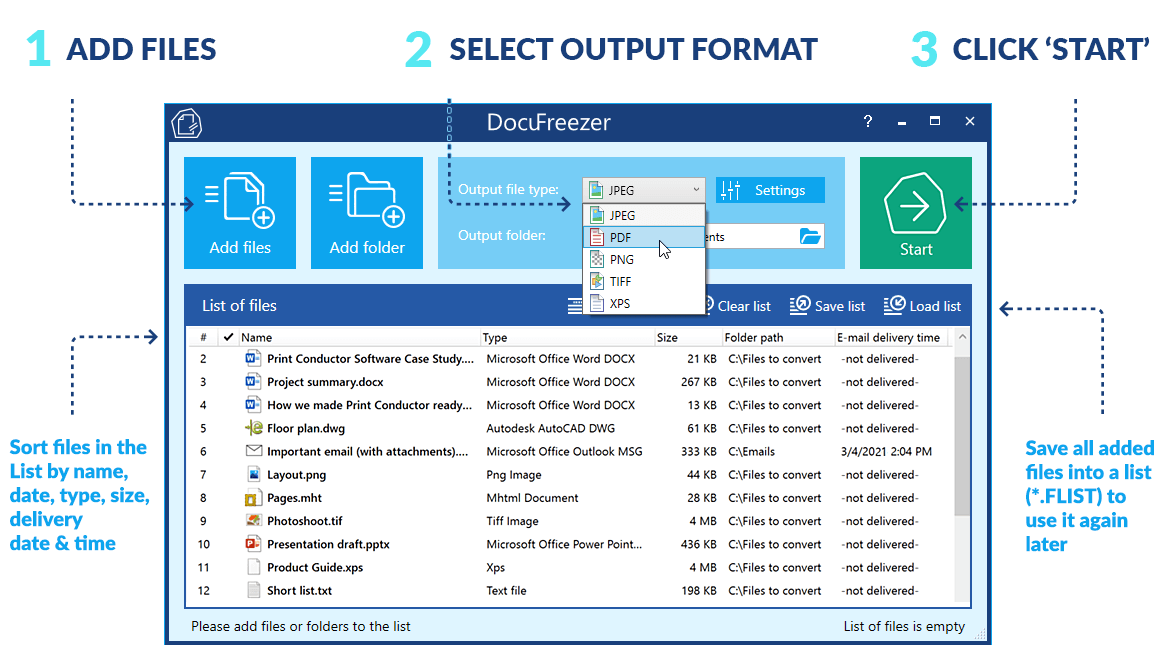
一、下载原理
1)找到目标音频的专辑网页,这里以 kite runner mp3为例。(需要自己找)
https://www.xi___ma___la_____ya.com/album/71718770
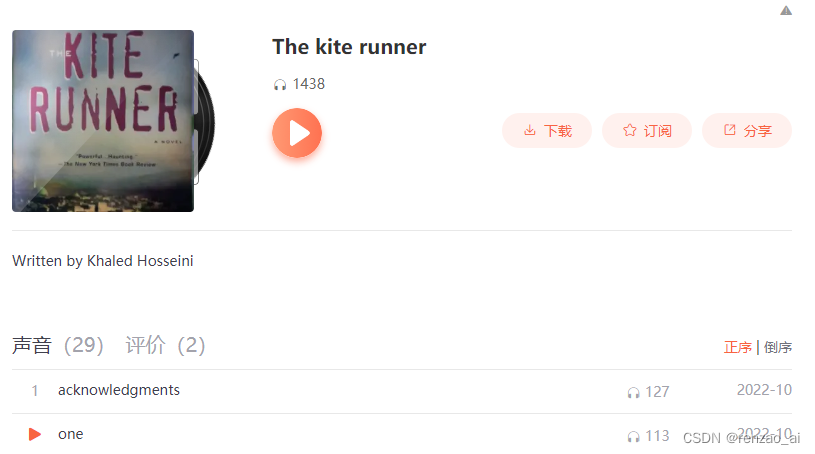
2)进入详细页(称为一次请求URL)(不需要自己找)
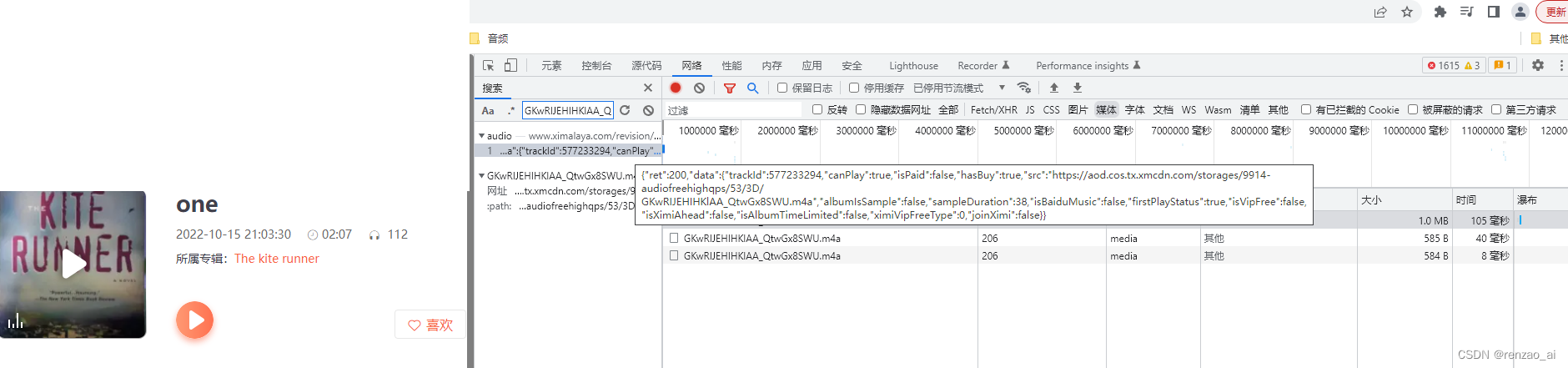
音频为m4a格式,不会立即返回。进入到详细页后,人工点击播放键,发送二次请求才能返回m4a,第二次请求包装在json格式中。(不需要自己找了,脚本自动找)
即 ‘data’ : { … ‘src’: ’ xxx.m4a’}
3)第二次请求时url的变化在于 id,格式如下
https://www.xi____ma_____la_____ya.com/revision/play/v1/audio?id=577233294&ptype=1
脚本自动查找如下tag,并分析出id和title,其中id用于组织每次的m4a请求url, 而title用于迅雷下载时自动改名。
a href=“/album/https://www.xi_____ma_____la_____ya.com/sound/593062498”>nineteen</a
二、代码如下
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import os
from win32com.client import Dispatch
Headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
def get_xima_url(url):
wd_data = requests.get(url,headers=Headers)
wd_data.encoding = 'UTF-8'
soup = BeautifulSoup(wd_data.text,'lxml')
return soup
def get_xima_json(url):
wd_data = requests.get(url,headers=Headers)
return wd_data.json()
def get_m4a(url):
m4a_soup = get_url(url)
m4a_hrefs = m4a_soup.find_all("a",attrs={'href':True})
pattern = '/album/..*/sound/(\d+)'
o = Dispatch("ThunderAgent.Agent64.1")
for alink in m4a_hrefs:
#print(alink)
res = re.match(pattern,alink['href'])
name = alink.string
if res is not None:
id = res.group(1)
m4a_url = "https://www.xi_____ma____la____ya.com/revision/play/v1/audio?id=" + id + "&ptype=1"
json = get_xima_json(m4a_url)
m4a = json['data']['src']
o.AddTask(m4a, name)
o.CommitTasks()
#<a href="/album/https://www.xi____ma____la____ya.com/sound/593062498"><span class="title b_t">nineteen</span></a>
if __name__ == '__main__':
url = "https://www.ximalaya.com/album/71718770"
get_m4a(url)
说明一:
m4a_hrefs = m4a_soup.find_all(“a”,attrs={‘href’:True}) 可以过滤掉不需要的tag a。
三、如何用于自己感兴趣的内容下载
只需要修改 倒数第二行的url最后的数字为你找到的专辑目录网页对应的数字。


![[硬核] Bootstrap Blazor Table 综合演示例子](https://img-blog.csdnimg.cn/img_convert/83cc3b1324c50758031c1c2cf53d6547.gif)
![[Android Studio] 如何查看Android Studio的版本信息](https://img-blog.csdnimg.cn/24b696d76d374a9992017e1625389592.gif)