游戏是智能应用最好的平台,可惜的是:只用了少部分计算AI,还没有用到智能的计算计
1 引言
从1950年香农教授提出为计算机象棋博弈编写程序开始,游戏人工智能就是人工智能技术研究的前沿,被誉为人工智能界的“果蝇”,推动着人工智能技术的发展。
2 概念
如果我们知道了什么是人工智能,游戏人工智能的含义也就不言而喻了,那么什么是人工智能呢?比起人工智能更基础的概念是智能,那么什么是智能呢?权威辞书《韦氏大词典》的解释是“理解和各种适应性行为的能力”,《牛津词典》的说法是“观察、学习、理解和认识的能力”,《新华字典》的解释是“智慧和能力”,James Albus在答复Henry Hexmoor时说“智能包括:知识如何获取、表达和存储;智能行为如何产生和学习;动机、情感和优先权如何发展和运用;传感器信号如何转换成各种符号;怎样利用各种符号执行逻辑运算、对过去进行推及对未来进行规划;智能机制如何产生幻觉、信念、希望、畏惧、梦幻甚至善良和爱情等现象”。而人工智能作为一门科学的前沿和交叉学科,至今尚无统一的定义,但不同科学背景的学者对人工智能做了不同的解释:符号主义学派认为人工智能源于数理逻辑,通过计算机的符号操作来模拟人类的认知过程,从而建立起基于知识的人工智能系统;联结主义学派认为人工智能源于仿生学,特别是人脑模型的研究,通过神经网络及网络间的链接机制和学习算法,建立起基于人脑的人工智能系统;行为主义学派认为智能取决于感知和行动,通过智能体与外界环境的交互和适应,建立基于“感知-行为”的人工智能系统。其实这三个学派从思维、脑、身体三个方面对人工智能做了一个阐述,目标都是创造出一个可以像人类一样具有智慧,能够自适应环境的智能体。理解了人工智能的内涵以后,我们应该怎么衡量和评价一个智能体是否达到人类智能水平呢?目前有两个公认的界定:图灵测试和中文屋子,一旦某个智能体能够达到了这两个标准,那么我们就认为它具备了人类智能。
游戏人工智能是人工智能在游戏中的应用和实践。通过分析游戏场景变化、玩家输入获得环境态势的理解,进而控制游戏中各种活动对象的行为逻辑,并做出合理决策,使它们表现得像人类一样智能,旨在提高游戏娱乐性、挑战智能极限。游戏人工智能是结果导向的,最关注决策环节,可以看做“状态(输入)”到“行为(输出)”的映射,只要游戏能够根据输入给出一个看似智能的输出,那么我们就认为此游戏是智能的,而不在乎其智能是怎么实现的(Whatever Works)。那么怎么衡量游戏人工智能的水平呢?目前还没有公认的评价方法,而且游戏人工智能并不是特别关心智能体是否表现得像人类一样,而是更加关心游戏人工智能的智能极限——能否战胜人类的领域专家,如:Waston在智能问答方面战胜了 Jeopardy! 超级明星 Ken Jennings 和 Brad Rutter;AlphaGo在围棋上战胜了欧洲冠军樊麾。
3 游戏机理
3.1人类的游戏机理
游戏对我们来说并不陌生,无论是小时候的“小霸王学习机”,还是五子棋、象棋等各种棋类游戏都是童年的美好回忆,但人类玩游戏的整个过程是什么样的呢?
具体过程如图1所示:首先玩家眼球捕捉显示屏上的游戏画面并在视网膜上形成影像;然后经过视觉神经传至V1区,并提取线条、拐点等初级视觉信息;初级视觉信息经过V2区传至V4区,并进一步提取颜色、形状、色对比等中级视觉信息;中级视觉信息经过PIT传至AIT,进而提取描述、面、对象等高级视觉信息并传至PFC;在PFC进行类别判断,并根据已有的知识制定决策,然后在MC的动机的促发下产生行为指令并传至响应器官(手);响应器官执行操作;至此,玩家的游戏机制已经完成。计算机在接收到玩家的输入(键盘、鼠标等)以后,根据游戏的内部逻辑更新游戏状态,并发送至输出设备(显示屏)展示给用户,自此计算机游戏环境更新完成。然后玩家展开下一次游戏机理,并循环直至游戏结束或玩家放弃游戏。
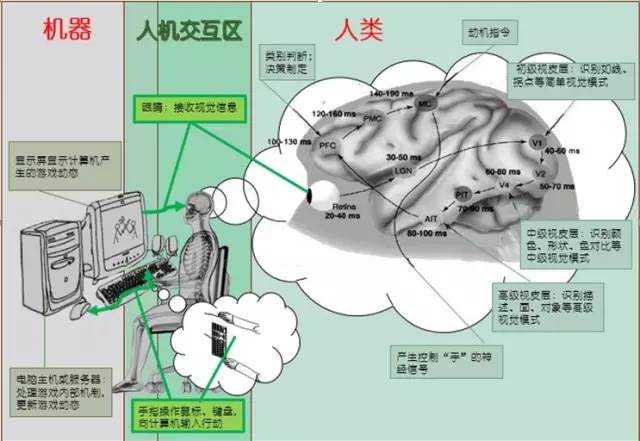
图 1 人类游戏机理
3.2计算机的游戏机理
游戏人工智能是创造一种代替人类操作游戏的智能体,想要让机器玩好游戏,我们就需要了解“它”玩游戏的机理,这样才能更好地改进它。
计算机的游戏机理如图2所示:首先通过某种方式(读取视频流、游戏记录等)获得环境的原始数据,然后经过去重、去噪、修正等技术对数据进行预处理,并提取低级语义信息;然后经过降维、特征表示(人工或计算机自动提取)形成高级语义信息;然后通过传统机器学习方法进行模式识别,进一步理解数据的意义;最后结合先前的经验(数据挖掘,或人工提取,或自学习产生的领域知识库)决策生成行动方案,进而执行改变环境,并进行新一轮的迭代。在每次迭代的过程中,智能体还可以学习新的经验和教训,进而进化成更加智能的个体。
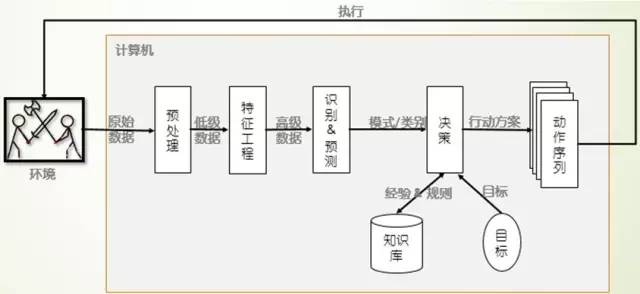
图 2 计算机游戏机理
3.3 游戏的一般性机理
从人类和计算机的游戏机理,我们可以总结出游戏玩家的一般性机理,如图3所示:游戏玩家可以看做是一个态势感知过程,接收原始数据作为输入,输出动作序列,在内部进行了态势觉察产生低级信息、态势理解形成高级认知、态势预测估计将来的态势,并根据已有的经验和规则,在目标和动机的驱动下产生行动方案,从而指导游戏向更有利于玩家的方向进行,然后进入下一个循环序列。
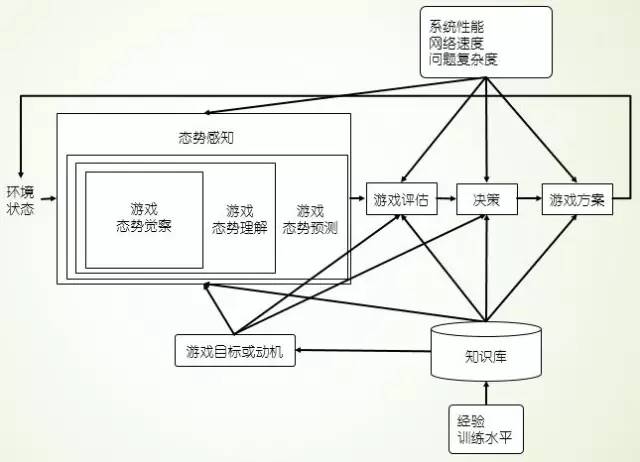
图 3 游戏一般过程机理(SA图)
游戏的一般性机理还可以看做是一个“状态”到“动作”的映射,游戏的环境状态、玩家的目标是自变量,玩家的操作是因变量,而映射关系是正是游戏一般机理的核心部分。它可以通过如神经网络这种技术来对自变量进行特征提取和表征,也可以直接使用自变量,利用公式计算获得输出值,进而映射到相应的动作。
4 里程碑
自香农发表计算机象棋博弈编写程序的方案以来,游戏人工智能已经走过了半个多世纪,在这65个春秋的风雨兼程中,无数的科学家贡献了自己的才华和岁月,所取得的成果更是数不胜数,本文罗列了游戏人工智能的重大里程碑,意欲读者能够把握游戏人工智能的研究现状,为今后的研究方向给予启示,具体如表1所示:
表 1游戏人工智能里程碑表
年份 | 名称 | 作者 | 描述及意义 |
1950 | 计算机象棋博弈编写程序的方案 | 克劳德·艾尔伍德·香农 | 机器博弈的创始; 奠定了计算机博弈的基础。 |
1951 | Turochamp | 艾伦·麦席森·图灵 | 第一个博弈程序; 使用了博弈树。 |
1956 | 西洋跳棋 | 阿瑟·塞缪尔 | 第一个具有自学习能力的游戏; 使用了强化学习算法,仅需自我对战学习就能战胜康涅狄格州的西洋跳棋冠军。 |
20世纪60年代 | 国际象棋弈棋程序 | 约翰·麦卡锡 | 第一次使用Alpha-beta剪枝的博弈树算法; 在相同计算资源和准确度的情况下,使得博弈树的搜索深度增加一倍。 |
1980 | Pac-man | Namco公司 | 第一次使用了一系列的规则与动作序列及随机决策等技术; |
1989 | Simcity | Maxis公司 | 第一次使用了人工生命、有限状态机技术; |
1990 | 围棋弈棋程序 | 艾布拉姆森 | 第一次将把蒙特卡洛方法应用于计算机国际象棋博弈的盘面评估; |
1996 | Battlecruiser 3000AD | 3000AD公司 | 第一次在商业游戏中使用神经网路; |
1996 | Creature | NTFusion公司 | 第一次引入“DNA”概念、遗传算法 |
1997 | Deep Blue | IBM公司 | 第一个达到人类国际大师水平的计算机国际象棋程序; 使用了 剪枝的博弈树技术,以3.5:2.5战胜世界棋王卡斯帕罗夫 |
2011 | Watson | IBM公司 | 第一次在智能问答方面战胜人类; 使用了Deep QA技术,战胜了 Jeopardy! 超级明星 Ken Jennings 和 Brad Rutter |
2013 | 玩“Atari 2600”的程序 | DeepMind团队 | 第一个“无需任何先验知识”“自学习”“可迁移”的游戏引擎; 使用了CNN+Q-learning的DRN技术,输入为“原始视频”和“游戏反馈”,无需任何人为设置,可从“零基础”成为7款“Atari 2600”游戏的专家。 |
2016 | AlphaGo | Google DeepMind团队 | 第一个在全棋盘(19*19)无让子的情况下战胜人类专业棋手的“围棋程序”; 使用了SL(有监督学习)+RL(强化学习)+MCTS(蒙特卡罗树搜索)方法,战胜了欧洲围棋冠军Fan Hui。 |
5 游戏人工智能实现技术
5.1有限状态机
当你设法创造一个具有人类智能的生命体时,可能会感觉无从下手;一旦深入下去,你会发现:只需要对你所看到的做出响应就可以了。有限状态机就是这样把游戏对象复杂的行为分解成 “块”或状态进行处理的,其处理机制如图4所示:首先接收游戏环境的态势和玩家输入;然后提取低阶语义信息,根据每个状态的先决条件映射到响应的状态;接着根据响应状态的产生式规则生成动作方案;最后执行响应动作序列并输入游戏,进入下一步循环。由图4和图2比较可知:有限状态机方法是计算机游戏机理的一种简单实现:根据规则人为将原始数据映射到“状态”完成“特征工程和识别”,根据产生式系统将“状态”映射到响应的动作完成“决策制定”。
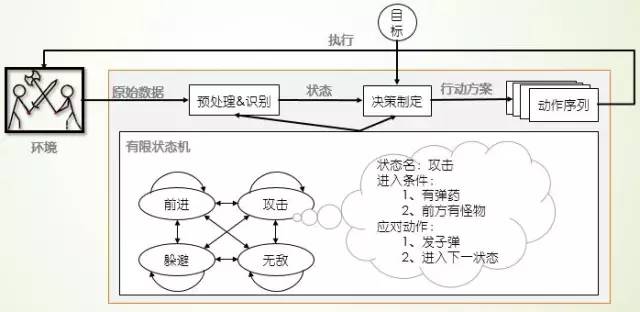
图 4 有限状态机游戏机理
那么理论层次上的“有限状态机”又是怎么描述的呢?有限状态机是表示有限个状态以及在这些状态之间转移和动作等行为的特殊有向图,可以通俗的解释为“一个有限状态机是一个设备,或是一个设备模型,具有有限数量的状态,它可以在任何给定的时间根据输入进行操作,使得从一个状态变换到另一个状态,或者是促使一个输出或者一种行为的发生。一个有限状态机在任何瞬间只能处在一种状态”。通过相应不同游戏状态,并完成状态之间的相互转换可以实现一个看似智能的游戏智能引擎,增加游戏的娱乐性和挑战性。
5.2搜索
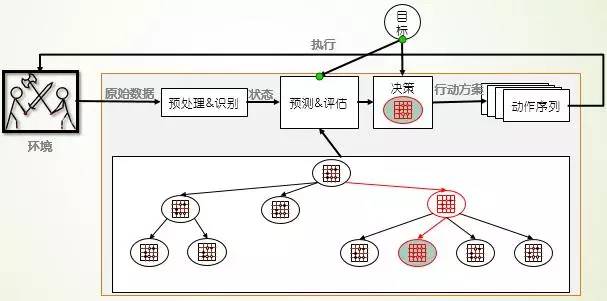
图 5博弈树游戏机理
“人无远虑,必有近忧”,如果能够考虑到未来的所有情况并进行评估,那么只需要筛选最好的选择就可以了。当前棋类游戏几乎都使用了搜索的方式来完成决策的,其中最优秀的是 搜索树、蒙特卡洛搜索树。搜索的游戏人工智能更关注的是预测和评估,决策的制定只是挑选出预测的最好方式即可,如图5所示。
5.3有监督学习
分类是有监督学习方法,旨在具有标签的数据中挖掘出类别的分类特性,也是游戏人工智能的重要方法。有些游戏人类就是通过学习前人经验成为游戏高手的,棋类游戏更是如此。进过几千年的探索,人类积累了包括开局库、残局库、战术等不同的战法指导玩家游戏。而数据挖掘就是在数据中挖掘潜在信息,并总结成知识然后指导决策的过程。Google DeepMind的围棋程序AlphaGo就使用了有监督学习训练策略网络,用以指导游戏决策;它的SL策略网络是从KGS GO服务器上的30,000,000万棋局记录中使用随机梯度上升法训练的一个13层的神经网络,在测试集上达到57.0%的准确率,为围棋的下子策略提供了帮助。
5.4遗传算法
遗传算法是进化算法的一种。它模拟达尔文进化论的物竞天择原理,不断从种群中筛选最优个体,淘汰不良个体,使得系统不断自我改进。遗传算法可以使得游戏算法通过不断的迭代进化,可以从一个游戏白痴进化成为游戏高手,是一个自学习的算法,无需任何人类知识的参与。
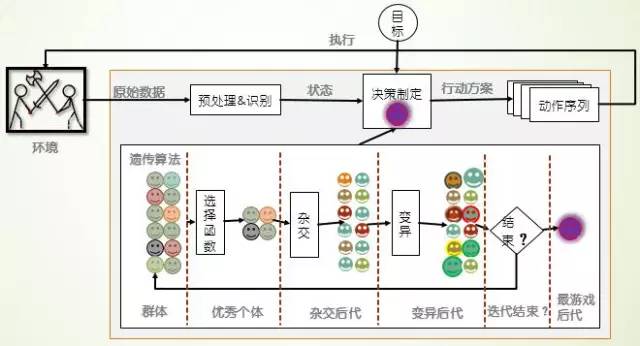
图 6 遗传算法游戏机理
在系统中,每个个体具有一串遗传信息,这串信息代表了我们所要优化对象的全部特征。算法维持一个由一定数量个体组成的种群,每一轮,算法需要计算每个个体的适应度,然后根据适应度选出一定数量存活的个体,同时淘汰掉剩余落后的个体。随后,幸存的个体将进行“繁殖”,填补因为淘汰机制造成的空缺。所谓的繁殖,就是个体创造出和自己相同的副本。然而为了实现进化,必须要有模仿基因突变的机制。因此在复制副本的时候也应当使得遗传信息产生微小的改变。选择-繁殖-进化这样的过程反复进行,就能实现种群的进化。
5.5强化学习
强化学习也是一种自学习的算法,1956阿瑟·塞缪尔的西洋跳棋程序仅通过算法自己和自己对战就可以战胜康涅狄格州的西洋跳棋冠军。强化学习来源于行为主义学派,它通过Agent与环境的交互获得“奖惩”,然后趋利避害,进而做出最优决策。
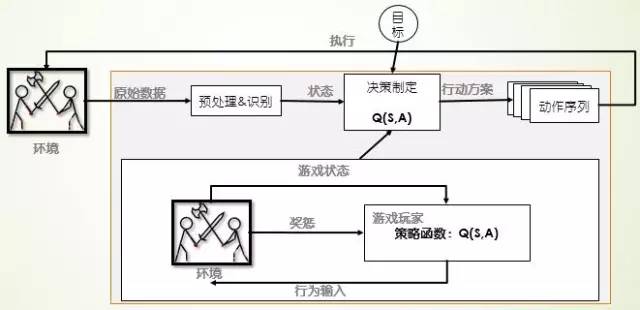
图 7 强化学习游戏机理
强化学习有着坚实的数学基础,也有着成熟的算法,在机器人寻址、游戏智能、分析预测等领域有着很多应用。现有成熟算法有值迭代、策略迭代、Q-learning、动态规划、时间差分等学习方法。
5.6 DRN
DRN是Google DeepMind在“Playing Atari with Deep Reinforcement Learning”中结合深度学习和强化学习形成的神经网络算法,旨在无需任何人类知识,采用同一算法就可以在多款游戏上从游戏白痴变成游戏高手。首先使用数据预处理方法,把128色的210*160的图像处理成灰度的110*84的图像,然后从中选出游戏画面重要的84*84的图像作为神经网络的输入;接着使用CNN自动进行特征提取和体征表示,作为BP神经网络的输入进行有监督学习,自动进行游戏策略的学习。
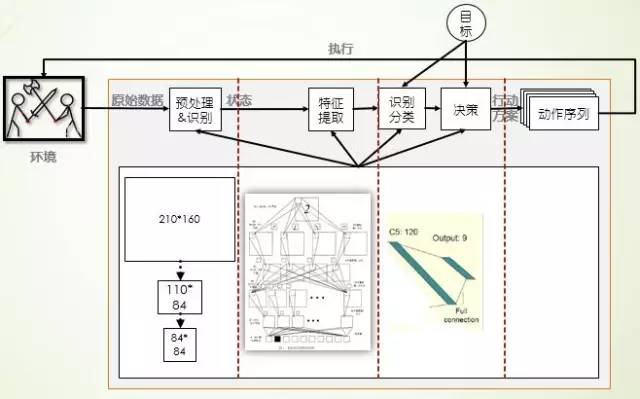
图 8 DRN游戏机理
5.7深度学习+强化学习+博弈树
Google DeepMind的AlphaGo使用值网络用来评价棋局形式,使用策略网络用来选择棋盘着法,使用蒙特卡洛树用来预测和前瞻棋局,试图冲破人类智能最后的堡垒。策略网络使用有监督学习训练+强化学习共同训练获得,而值网络仅使用强化学习训练获得,通过这两个网络结构总结人类经验,自主学习获得对棋局的认知;然后使用蒙特卡洛树将已经学得的知识应用于棋局进行预测和评估,从而制定着法的选择。
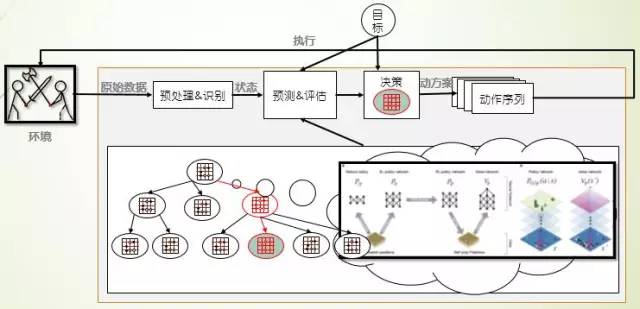
图 9 AlphaGo的游戏机理
6 总结
与模糊人类与机器的边界不同,游戏人工智能更关注挑战智力极限,表征是游戏战胜人类最强者;与教导人类成为领域专家不同,游戏人工智能更关注培育自学习能力的智能体,表征是无经验自主学习;所以当前最先进的两个游戏引擎均使用了深度学习和强化学习两方面的知识,旨在培育具有自学习能力的高智能个体。
当前大家最关注的莫过于2016年3月AlphaGo与李世石的围棋之战。那么一旦围棋战胜李世石之后,是否表示机器已经突破人类最后的堡垒呢?是否表示达到智能极限,游戏人工智能下一步的研究关注点又应该是什么呢?我认为机器即使战胜李世石也没有达到人类智能的极限,与记忆和速算一样,搜索与前瞻的能力也不能代表人类智能,人类还有情感、有思想、能快速学习等等能力,所以AlphaGo即使战胜李世石也只是在某个领域里面比人类更强而已;游戏人工智能不能使用图灵测试、中文屋子来衡量人工智能的程度,因为人类在游戏(特别是棋类游戏)上的智能并不突出,因为人脑的复杂度有限,并不能计算游戏的最优值,只是在能力范围内做出较优的决策,所以我认为“游戏人工智能的关注点应该是:同一游戏引擎作为双方对战,总是同一方(先手或后手)取胜,而且能够战胜人类最强者”。所以即使AlphaGo战胜李世石,那么棋类智能仍有探索的空间:游戏的最优值!

游戏是智能应用最好的平台,可惜的是:只用了少部分AI计算,还没有用到智能的计算计