对可能是中本聪的实体所表现出的挖矿行为的技术分析。
文 | Jameson Lopp. 原标题:Was Satoshi a Greedy Miner?. 2022/9/16.
* * *

如果你在加密生态系统中待了足够久的时间,那么你无疑会听到这样的论点,即某些项目的代币分配不公平,因为它们是由项目创始人在项目初始启动时就“预挖”/“立即挖矿”/“快速挖矿”,有效地令项目创始人自己致富。
项目创始人若是愤愤不平,希望反击代币分配的批评,就不可避免地会指出,中本聪似乎拥有大约 110万枚 比特币 —— 接近 5% 的比特币总供应量。
* * *
Patoshi模式的序言
免责声明:出于以下文章的目的,我将假设所谓的“Patoshi模式”实际上是一个矿工实体,而这个实体就是 Satoshi(中本聪)。因此,我将互换使用“Satoshi”和“Patoshi”。虽然不可能超越合理怀疑进而证实这一点,但这位矿工表现出的行为表明,有人在比特币存在的早期就对比特币有着极其深刻的了解 —— 中本聪级别的理解。但这是另一篇文章的主题。
什么是 Patoshi模式?如果你熟悉比特币挖矿的基础知识,那么你就会知道矿工会通过增加 nonce值 来尝试创建一个 哈希值满足给定难度目标的 有效区块。位于 coinbase 交易中的 ExtraNonce 字段在每次 nonce 字段溢出时递增,这意味着搜索空间已用尽。由于 nonce 字段的长度为 32 位,而最初的比特币难度目标需要平均扫描 32 位,因此 nonce 有时会溢出,但并非总是如此。
1. ExtraNonce 用作“自由运行计数器”,不会在挖掘的块之间重置为零。
2. 根据原始比特币源代码,某个矿工增加 ExtraNonce 的速率比其实际哈希值指示的速率快得多。
3. 挖矿过程中每隔几秒检查一次最佳区块。如果最佳块发生变化,则 ExtraNonce 会额外增加。通常每个收到的外部块都会增加 ExtraNonce,除了特殊的矿工 Patoshi,它似乎不遵循这个规则。
在绘制图表时,这些 ExtraNonces 允许 Patoshi 模式的可视化,我们可以观察到 ExtraNonces 的连续斜率。
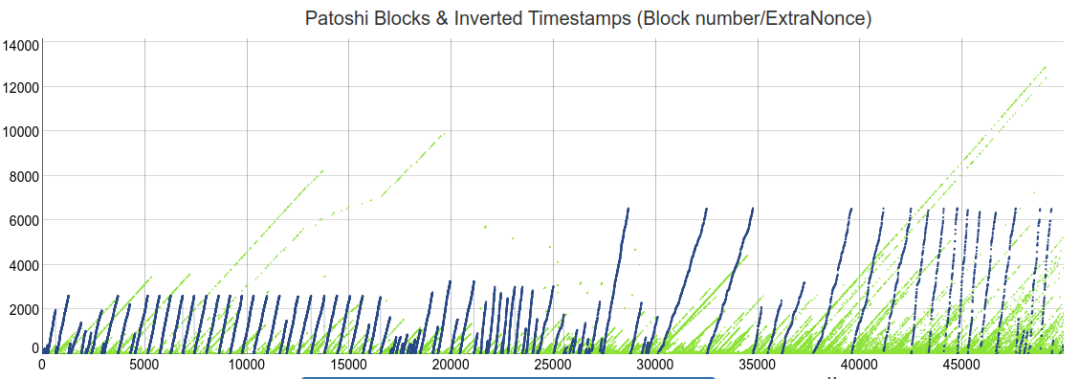
此外,Patoshi 矿工在他们为区块找到的 nonce 值中表现出奇怪的限制。关于为什么会出现这种情况有多种理论,但我认为最合理的是 Patoshi 开发了多线程挖矿软件,并将这些范围分配给不同的 CPU 内核,这样每个内核都会并行地扫描一个缩小的 nonce值空间。
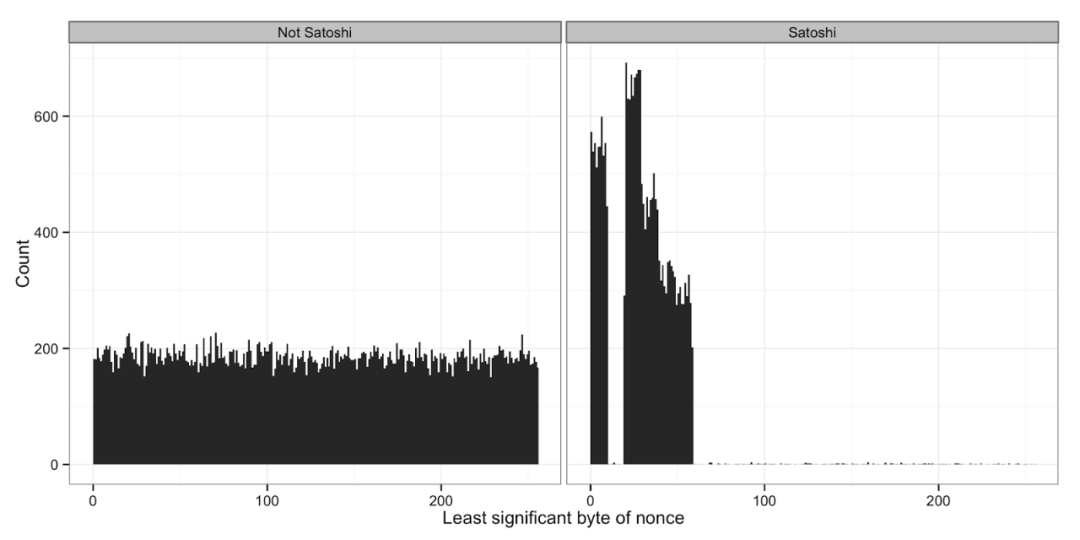
来源: http://organofcorti.blogspot.com/2014/08/168-little-more-on-satoshis-blocks_15.html
注意:用于识别 Patoshi 区块的技术涉及一些不确定性,并且与来自其他矿工的 ExtraNonce 模式相交的非 Patoshi 区块存在冲突。但是,错误分配的块的错误率可能会限制在远低于 1% 的范围内。
* * *
Patoshi的特点
如果我们通读十几篇分析似乎由中本聪开采的区块的技术文章,我们可以得出关于这个矿工的几个结论:
1. 他们使用自定义编码的多线程比特币客户端进行挖掘,该客户端的行为与公开可用的比特币客户端不同。用外行的话来说,现代 CPU 有多个内核 —— 一个物理单元内的多个处理器。但是,除非你以一种可以跨多个内核并行分配计算的方式编写软件,否则它只能使用一个内核。早期的公共比特币客户端并没有编写多线程功能;它只在一个 CPU 内核上开采。
2. 他们的哈希率一次连续数月保持不变,然后出现系统性下降。
3. 22,000 多个区块中只有不到 20 个(0.09%)被花费。
4. 中本聪似乎是以编程的方式打开和关闭他们的矿机。
* * *
沉睡的中本聪
中本聪开采的区块的时间分布有一个奇怪的点:它们不遵循我们对花费 100% 的时间进行挖矿的矿工所期望的分布。事实上,他们几乎从不连续开采相距不到 5 分钟的区块!一个简单的解释是,他们在挖出一个区块后暂停了他们的矿工 5 分钟。
正如 Sergio 在他的研究中解释的那样,Patoshi 的矿工有可能在找到一个区块后继续挖矿,但他们的定制挖矿软件会人为地将下一个区块的时间戳增加不少于 300 秒。
无论如何,这是一个有趣的现象,显然是矿工的深思熟虑的决定。我们可以深挖一下吗?我通过几种不同的方式分析了 Patoshi 的区块分布。首先,如果我们只观察 Patoshi 和 Patoshi 挖出的区块之间的时间戳差异,我们可以很明显地看到他们很少挖出间隔小于 5 分钟的区块。在难度目标为 1 时,每秒 4.35 兆哈希 (Mhps) 的矿工的预期时间戳增量分布趋势线以蓝色显示。出于此图表的目的,我只使用了他们在似乎以 4.35 Mhps 的速度挖掘期间的 Patoshi 块数据。
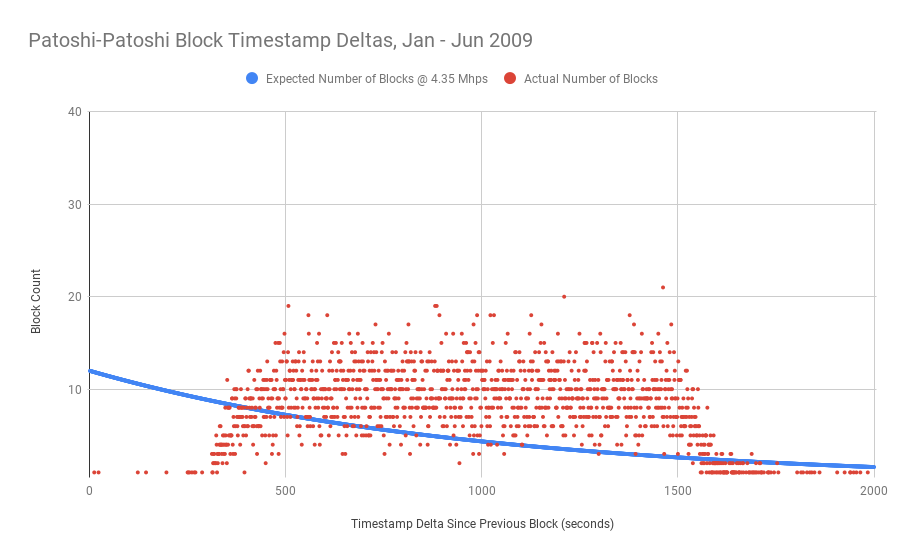
前 6 个月由 Patoshi 开采的两个区块之间的时间戳差异
所以我们可以看到缺少“快速”块的明显的巨大间隔。如果我们查看所有 Patoshi 区块增量,包括在非 Patoshi 区块之后开采的区块,会怎样?
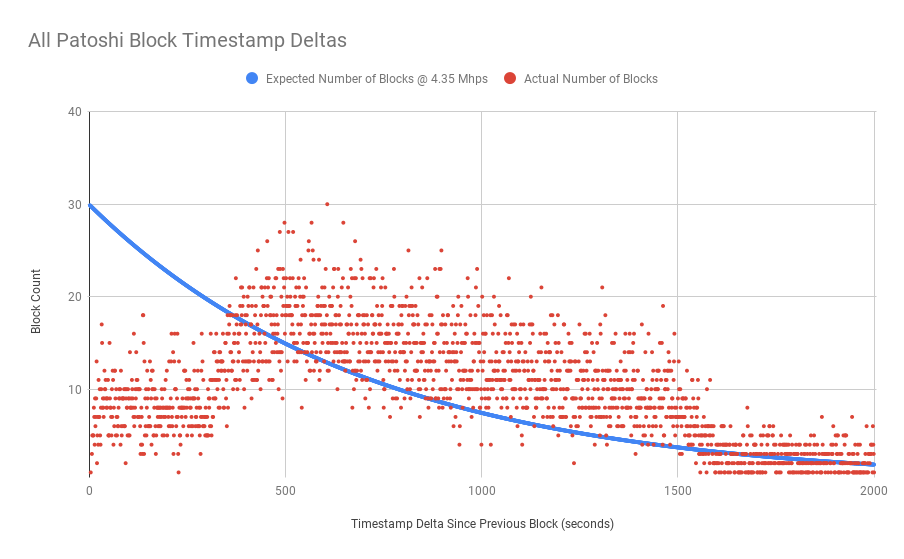
Patoshi 挖出的每个区块与其父区块的时间戳差异
这看起来好多了 —— 很明显,Patoshi 在收到其他人开采的区块后 5 分钟(300 秒)内没有关闭他们的矿工(或调整他们的区块模板时间戳)。但是我们也可以看到,耗时超过10分钟的出块数量比预期的要多很多!虽然这部分是由于中本聪随着时间的推移降低了哈希率,但由于其中一种挖矿操纵的发生,这种情况可能会加剧。
接下来,我从之前的图表中获取数据集,每当有一个区块在前一个区块之后被开采超过 5 分钟时,我就从时间增量中减去 5 分钟。我们可以看到,这为我们提供了一个更符合预期分布的结果数据集。
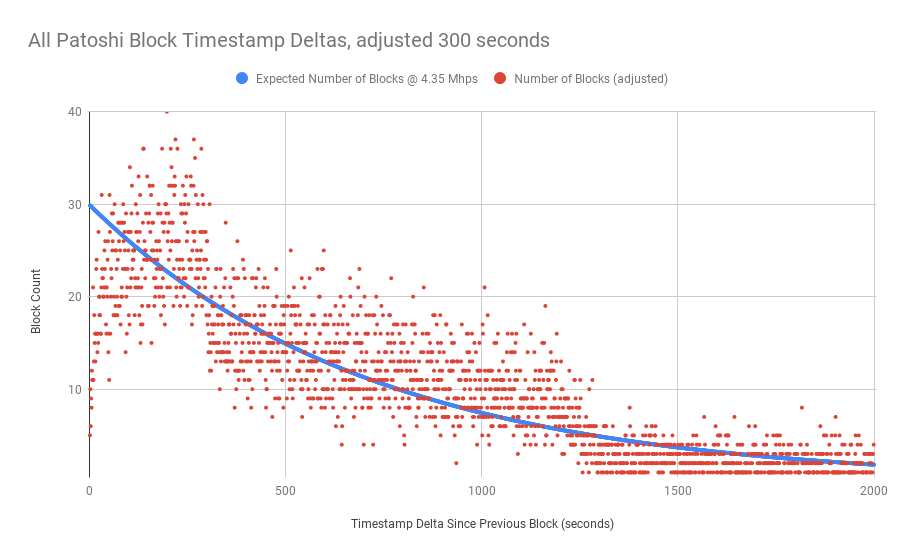
如果你还没有读过我之前关于块时间方差的研究[1],那么你可能会问自己这些图是否真的有意义 —— 也就是说,我们可以将它们与对照组进行比较吗?为了比较,这里是在 GPU 挖矿流行起来之前的比特币“CPU 时代”期间挖出的所有区块的图表:
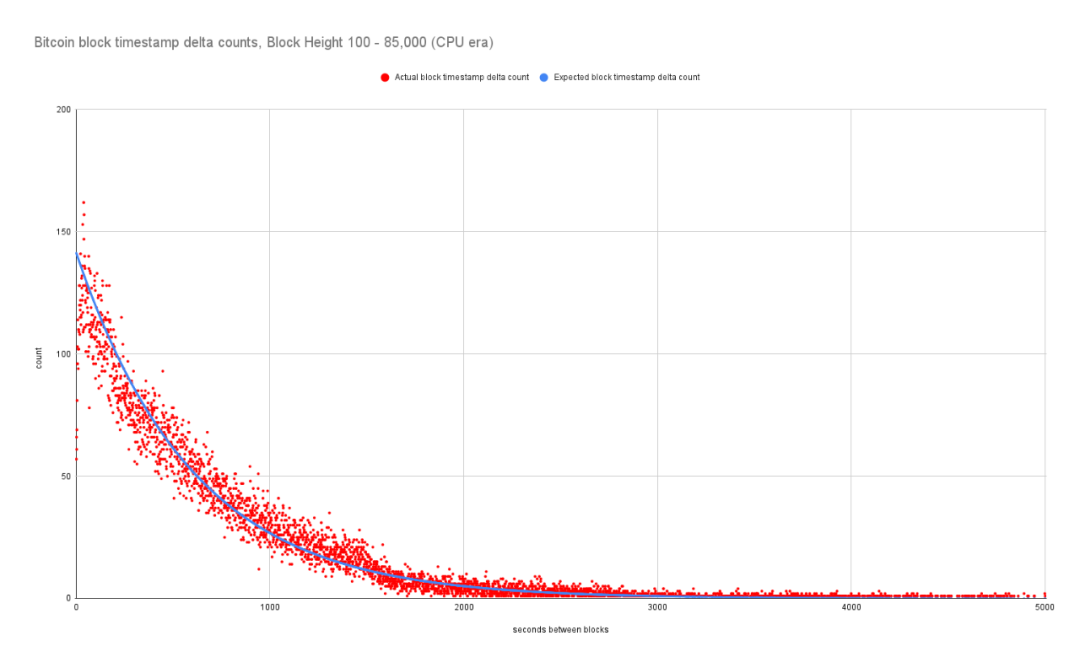
所以问题仍然存在:这种独特的现象是由于中本聪将他们的矿工关闭 5 分钟,还是由于他们将时间戳操纵了 5 分钟?我坚信中本聪的机器睡着了。为什么?
一个思想实验:如果 Patoshi 在找到一个块后简单地将他们的块时间戳设置为未来 5 分钟,那么我们可以预期异常高比例的孩子区块是非 Patoshi 块,且具有比第二个 Patoshi 块更早的时间戳,因为矿工会基于他们本地机器的时钟来设置时间戳。让我们搜索一下:
1. Patoshi块-> Patoshi块->非Patoshi块的序列
2. 第二个 Patoshi块 必须在第一个之后的 10 分钟内被开采
3. 找到第二个 Patoshi块 和 非Patoshi块 之间的时间戳增量
所以我写了个脚本[2]来搜索具有这些特征的块。该脚本找到了 1,881 个匹配的块。在这些块中:
* 只有 1 个具有来自父 Patoshi 块的负时间戳增量
* 只有 5 个 (0.3%) 是在父 Patoshi 块后不到 5 分钟内铸造的
此外,如果 Patoshi 只是在操纵他们开采的区块的时间戳,他们将无法隐藏他们在很长一段时间内开采的区块的总分布,因此也无法隐藏他们的有效哈希率。对于本文的其余部分,请记住以下数字:4.35 Mhps 和 6 Mhps。
* * *
中本聪的哈希率优势
我们可以观察到中本聪的矿工有 4 个不同的哈希时期。他们最初遵循的计划是每五个月将哈希率降低 1.7 Mhps,但在第二次下降一个月后,他们放弃了这种方法,转而采用持续降低哈希率的方法。
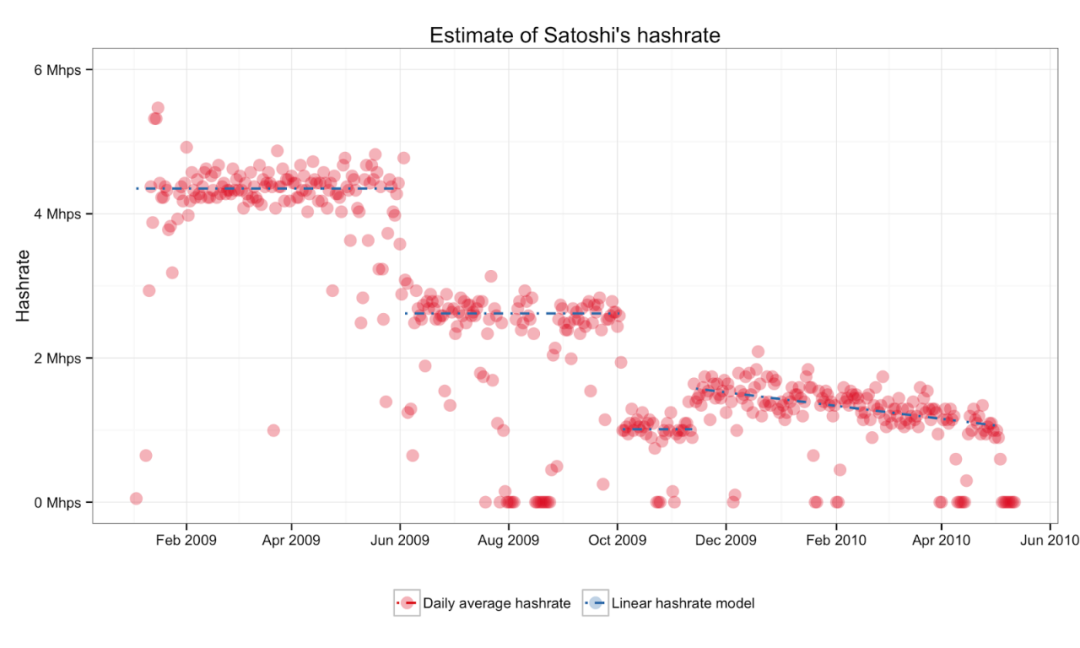
来源: http://organofcorti.blogspot.com/2014/08/167-satoshis-hashrate.html
当我们将中本聪的算力与网络的其他部分进行比较时,我们可以更清楚地观察到随着中本聪进一步后退,其他矿工对算力的自举从 2009 年 10 月开始起飞。
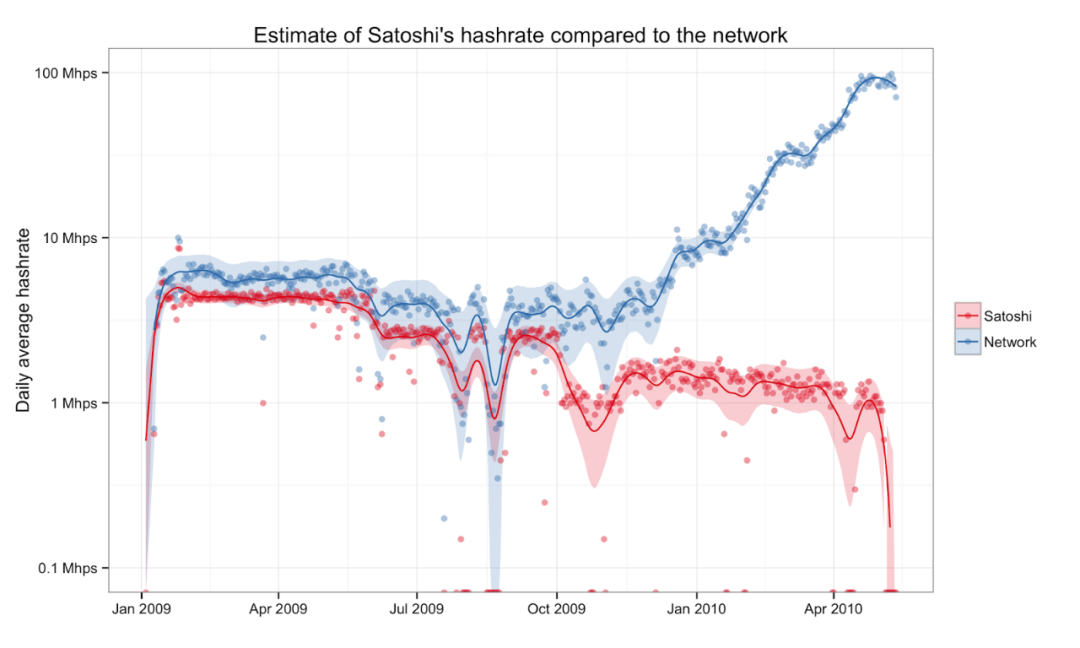
来源: http://organofcorti.blogspot.com/2014/08/167-satoshis-hashrate.html
事实上,直到 2009 年 10 月,中本聪一直处于危险的主导地位,拥有超过一半的网络哈希率。

来源: http://organofcorti.blogspot.com/2014/08/167-satoshis-hashrate.html
更有趣的是,中本聪在多次自愿降低算力后,才成为少数算力矿工。
这表明了几件事:
* 中本聪计划一直降低其哈希率。
* 中本聪最初对其哈希率有一个粗略的控制。
* 中本聪后来对其哈希率进行了非常细粒度的控制。
* * *
双螺旋
你可能已经注意到,“沉睡的中本聪”部分中的第一个时间戳分布图从其数据集中排除了块 1400-1916。为什么?因为在这个时间范围内发生了一个独特的现象,它搞砸了 Patoshi 块时间戳增量计算。有2台Patoshi矿机同时运行!
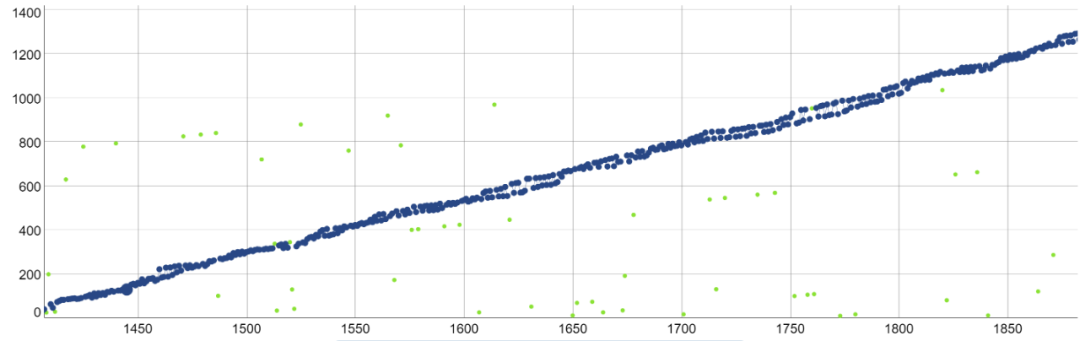
双螺旋 Patoshi 模式(块 1400-1916)
你可以在 SatoshiBlocks 网站[3]上探索这种模式。双螺旋模式可能是由并行运行的 Patoshi 软件的两个实例引起的。我们不知道这是 Patoshi 犯的错误还是他在测试什么。我们可以从这个现象中推断出什么呢?
在这 4 天 3 小时的时间里,中本聪挖出了 458 个区块。由此我们可以估计在这段时间内它们的总哈希率约为 5.5 Mhps。这是值得注意的,因为中本聪在 2009 年前 5 个月的哈希率平均为 4.3 Mhps。这也解释了与早期哈希率图表的突出差异。
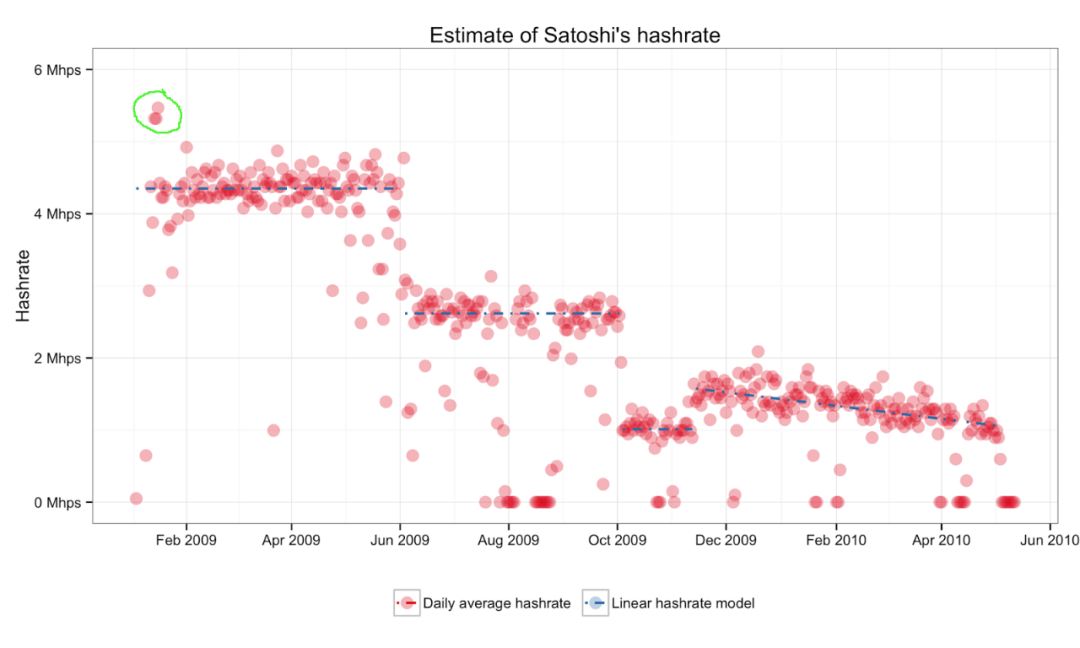
为什么这很有趣?如果中本聪设置了一台与第一台类似的单独机器进行挖矿,我们预计在双螺旋时期它们的整体哈希率将接近 8.6 Mhps。然而,他们的哈希率仅高出 28%,而不是高出 100%。我们可以看到,与每个其他 Patoshi 斜率相比,每个挖矿实例的性能都降低了,导致两个实例的 ExtraNonces 斜率一致下降。为什么?最简单的解释是因为两个挖矿实例中的线程都在竞争相同的 CPU 内核!
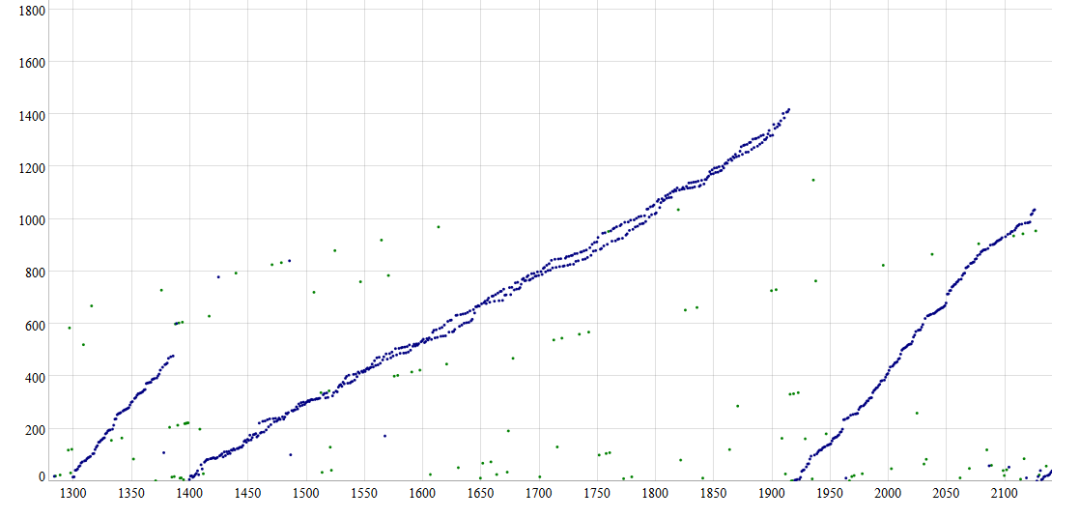
请注意,当单个实例正在运行时,它具有更高的哈希率,因此具有更陡峭的 ExtraNonce 斜率
Sergio Lerner 认为我们可以从中推断出中本聪的计算机可能是四核的。我认为这符合预期,因为当时的平均单线程矿工似乎达到了 1 Mhps 多一点的哈希率。无论如何,我认为可以肯定地猜测中本聪的双螺旋模式来自他们在同一硬件上运行的定制软件的两个实例。
几年前,我从电子邮件、论坛帖子和代码提交中汇总了中本聪的所有公开活动时间戳,生成了以下图表。我的结论是,中本聪保持着与太平洋时区的人一致的睡眠时间表。
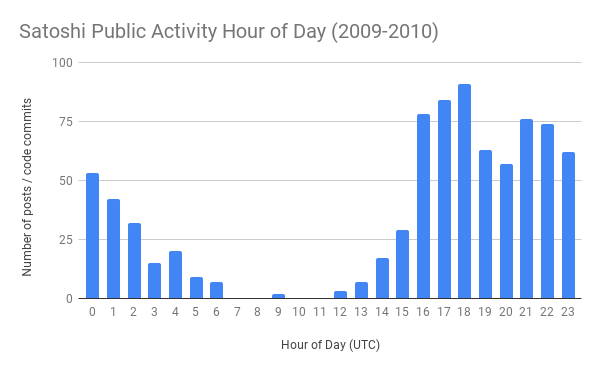
我为什么要提这个?为了支持我解释双螺旋现象的理论!这是我认为发生的事情:
* 中本聪于 2009 年 1 月 22 日太平洋时间下午 4 点开采了 1386 区块
* 中本聪的挖矿硬件/软件此后不久就崩溃了
* 第二天太平洋时间上午 8 点前不久,中本聪醒来检查他们的矿机,却发现它出现了故障
* 他们重新启动了矿机,并在太平洋时间上午 8 点发现了一个区块
* 中本聪不知道,他们不小心启动了 2 个挖矿实例
* 矿机在接下来的 3 天里跑了一个周末,中本聪没有注意到
* 1 月 25 日太平洋时间晚上 10 点 30 分开采区块 1916 后不久,矿机再次崩溃
* 中本聪在 1 月 26 日太平洋时间早上 7 点前不久醒来并检查他们的矿机,发现它已经崩溃,并将其恢复正常
* * *
中本聪的连胜
我们知道中本聪在 2009 年的前 9 个月拥有大部分哈希率;我们可以从他们最长的连续区块中发现什么吗?我写了一个连胜发现脚本,确定中本聪从 80 到 127 的高度有 47 个区块的连胜。
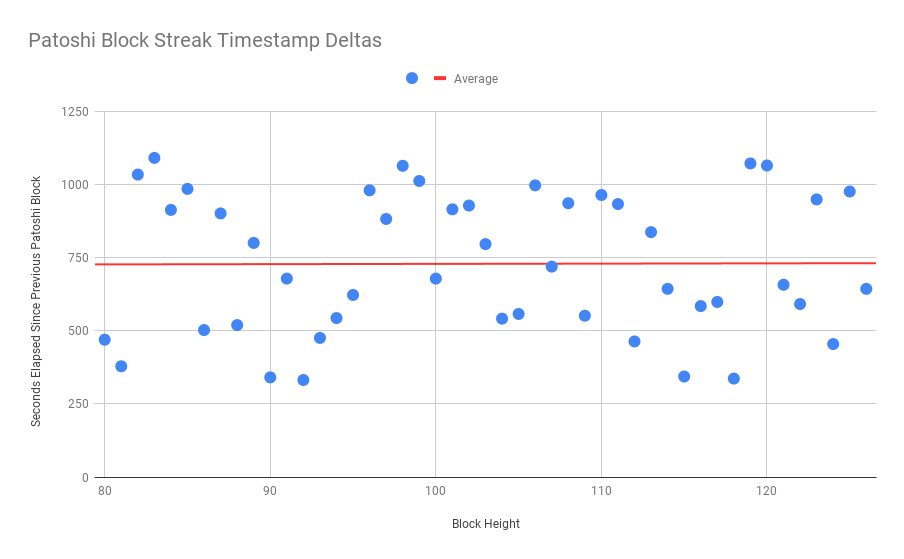
鉴于这是一个约 8 小时的窗口,并且随着你观察的时间范围缩短,哈希率估计变得不那么准确,这当然应该有所保留,但我们可以看到平均块时间为 720 秒,这使我们得以估计在此期间,他们的哈希率为 5.97 Mhps。
* * *
中本聪调慢挖矿速度是为了保持低难度吗?
回想一下,我们有多个数据点表明中本聪的机器,虽然通常观察到的哈希率为 4.35 Mhps,但可能只能达到 6 Mhps 的最大潜在哈希率。在 6 Mhps 的哈希率下,这导致预期的平均块时间为 708 秒。请记住,在过去的 2016 个区块以低于 600 秒的平均速度被开采之前,难度目标不会调整。因此,每个难度单位的全球网络哈希率可以表示为:
每秒哈希 = 2^32 / 600 = 每秒 7,158,278 个哈希
因此,为了使平均区块铸造时间足够快,以便比特币将难度目标从 1 调整到 2,网络上需要超过 7,158,278 * 1.5 = 10737417 哈希每秒 = 10.7 Mhps。
这意味着如果中本聪尽可能快地挖矿,网络上的其他矿工将需要超过 4.7 Mhps 才能提高难度目标。很难确切地说这会相当于多少台机器,尽管根据此处提供的一些 CPU 基准测试,我猜测使用早期、未优化的单线程比特币矿工的普通台式机处理器可能产生略高于 1 Mhps 的速度。还有早期矿工在 BitcoinTalk 上发布他们的哈希率的轶事证据。我们还可以观察这一点,并通过比较非 Patoshi 矿工的 ExtraNonce 斜率与 Patoshi 开采的 ExtraNonce 斜率来证明它的可能性 —— Patoshi 的比其他矿工的斜率高 3 倍。因此,我们只需要网络上的 4 或 5 个其他矿工来提高难度。
我写了另一个脚本[4]来从区块链中提取难度历史。
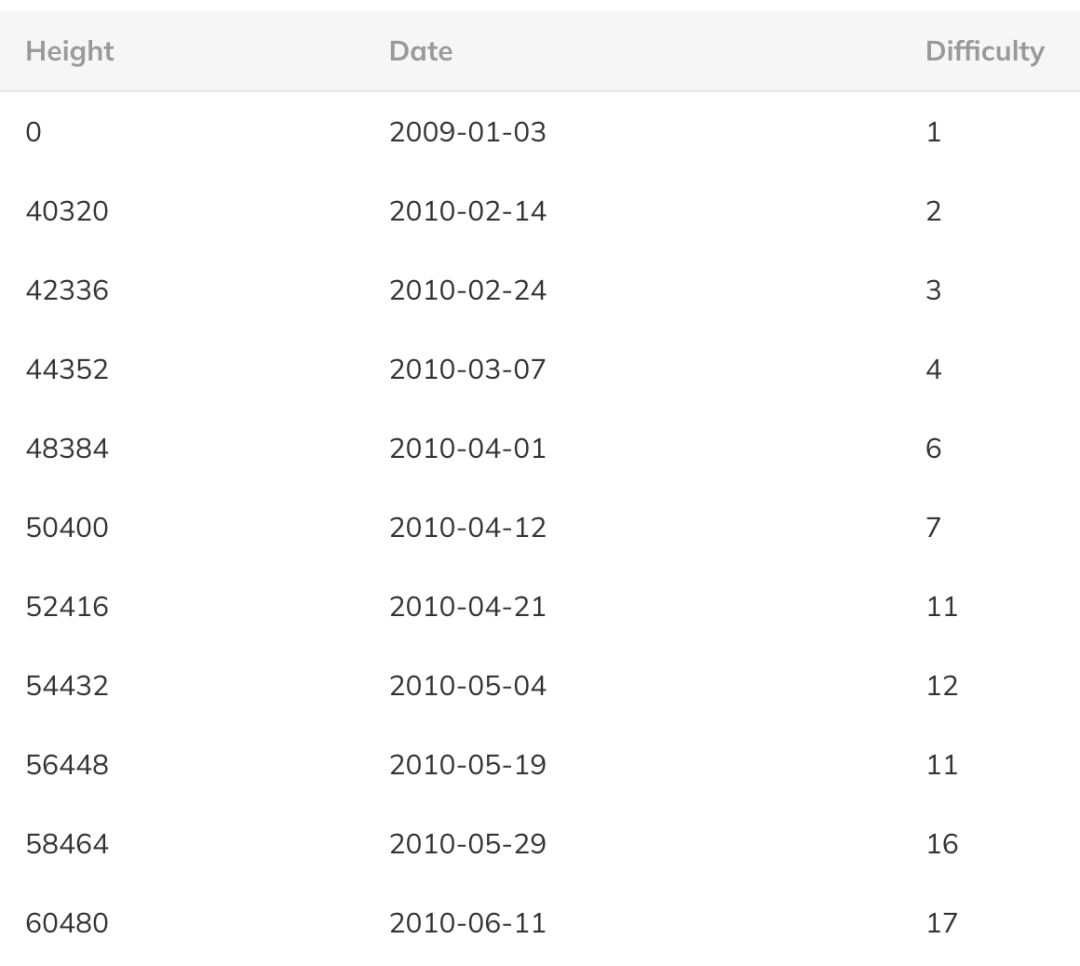
以下是问题相关时期的总网络哈希率图表:
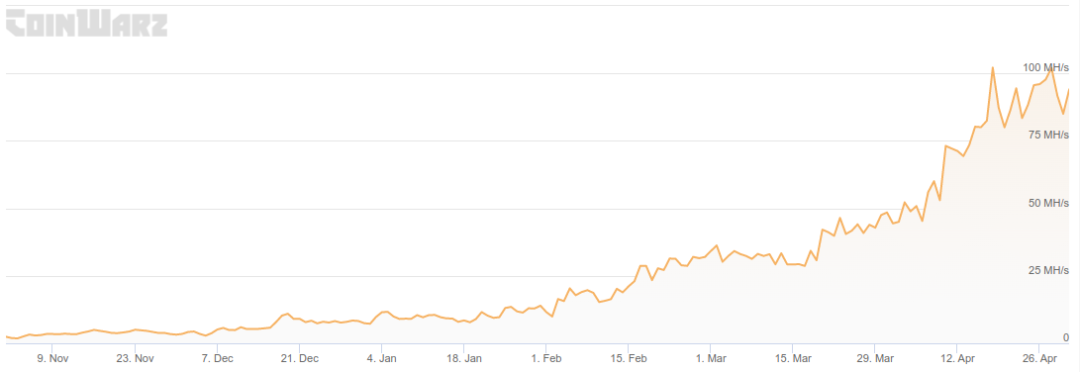
来源:https://www.coinwarz.com/mining/bitcoin/hashrate-chart
要了解难度重设会如何变化,我们必须问,如果中本聪以最大 6 Mhps 的速度进行挖矿,全球网络哈希率会在什么时候超过 10.7 Mhps。

通过查看图表并添加来自中本聪的缺失的潜在额外哈希率,看起来网络在 2009 年 12 月中旬已经超过 10.7 Mhps,并且难度在大约 2.5 个月前的区块 32256 处调整为 2。
所以,不,关于中本聪调慢挖矿速度以保持低难度的说法是荒谬的。他们本可以开采更多的区块,从而通过在不增加难度的情况下以最大潜在哈希率运行来赚取更多的比特币。当难度实际增加时,中本聪已经大幅降低了他们的哈希率。
* * *
一个贪婪的中本聪会有什么不同的做法?
Sergio 的 Patoshi 模式分析已将约 22,000 个区块确定为 Patoshi 候选区块。其中一些肯定是误报,但有充分的理由相信(由于用了多种指纹来鉴别区块)误报率低于 1%。因此,这将估计中本聪的总开采量约为 1,100,000 BTC。
如果中本聪在 2009 年底没有决定多次降低他们的哈希率,他们会多赚多少 BTC?如果我们假设恒定的难度目标为 1,则计算起来很简单。通过观察中本聪的区块铸造率和 1 的难度目标,我们知道他们的初始哈希率约为每秒 4,350,000 哈希(4.35 Mhps。)最后一个归属于中本聪的区块为 54,316;在创世块被开采后整整 14 个月。如果中本聪在 1 的难度目标下花费 4.35 Mhps 运行 14 个月,他们可以开采多少个区块?
找到一个块的预期秒数 = 难度 * 2^32 / 每秒哈希
1 * 2^32 / 4,350,000 = 987.35 秒每个块对于中本聪
36817200 秒(14 个月)/987.35 个区块 = 37302 个区块 = 1,865,100 BTC
不幸的是,这个问题其实有点儿复杂,因为挖矿难度从 2010 年 2 月 14 日的区块 40320 开始增加,而中本聪至少持续挖矿到 2010 年 5 月 3 日。复杂度甚至更进一步,如果我们考虑中本聪以最大哈希率挖矿可能导致将第一个难度目标更改提前了约 2.5 个月。
因此,我们可以使用之前发布的历史难度变化表,将时间框架向前移动那么些。如果我们假设中本聪仍然以 4.35 Mhps 的持续速度挖矿 479 天,那么这将导致大致如下数据:
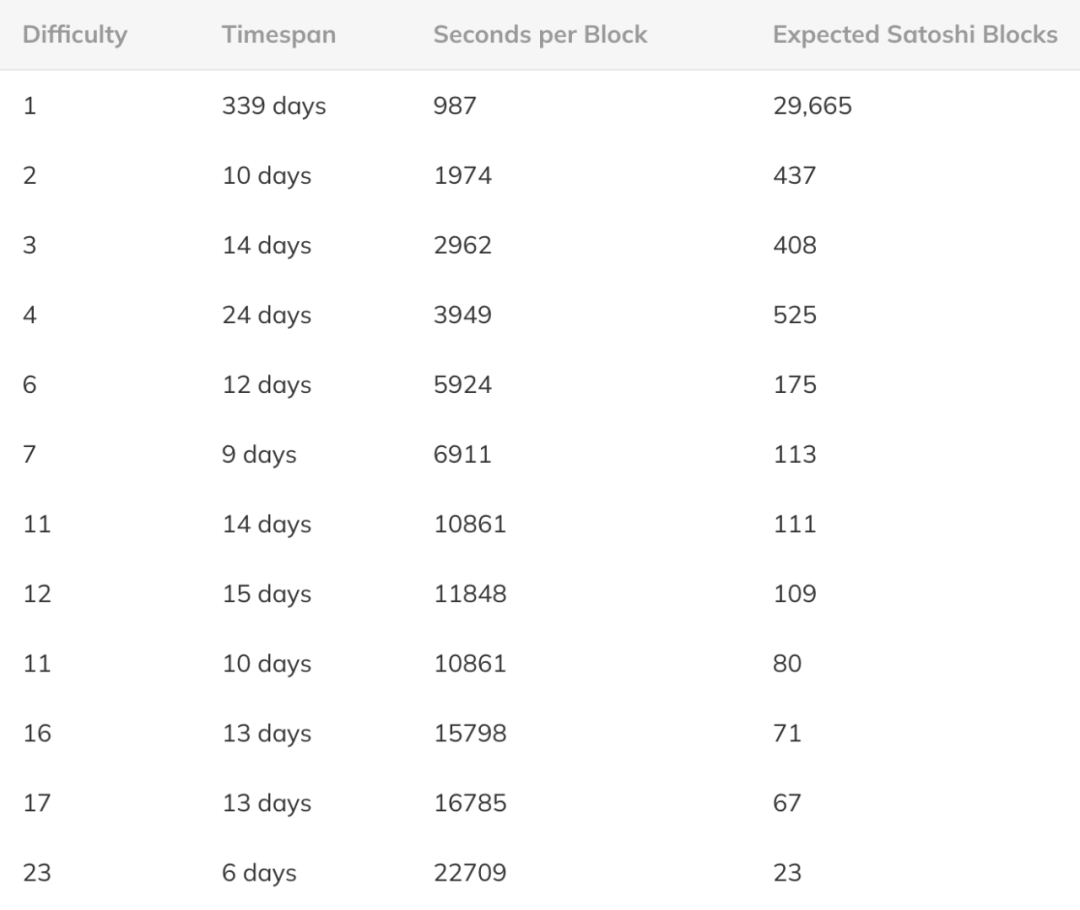
结果是 31,783 个区块或总共 1,589,150 BTC。
然而,我们还必须记住,当中本聪发现间隔不到 5 分钟的区块时,他们会定期关闭他们的矿机。这实际上是对其哈希率的额外的故意限制。那么中本聪实际在表面上留了多少算力呢?根据我们对区块的泊松分布的了解,我们可以得到一个很好的估计。旁注:如果你想深入那个兔子洞,你可以查看我之前关于区块时间方差的文章。
预计在前一个区块后不到 5 分钟内开采出区块的概率是百分之几?1 - exp(−5/10) = 39.35%。因此,中本聪的最大潜在哈希率实际上更像是 6.06 Mhps。这是一个有趣的结果,因为它也非常接近在双螺旋时代观察到的 5.5 Mhps 的哈希率,并且非常接近在早期连续 47 个区块期间观察到的 5.97 Mhps 的哈希率。
因此,让我们重新运行之前的计算,但这次假设中本聪以 6 Mhps 的理论最大哈希率运行他们的硬件。

总共是 43,829 个区块或 2,191,450 BTC。
* * *
为什么中本聪不销毁他们的比特币?
2010 年 8 月 10 日,第一笔向可证明无法使用的地址存款的交易是 1111111111111111111114oLvT2,我能找到的第一篇引用它的帖子[5]是在一个月后,并指出这是“可能的最小比特币地址”,而其他帖子[6]称它为 “零地址”,因为它是从全零的哈希值创建的。这些讨论倾向于围绕比特币地址有效性的边缘案例,而不是围绕有意销毁硬币的用例。
据我所知,第一次有意识地使用销毁地址是在 2011 年 6 月 20 日,当时交易对象是 1BitcoinEaterAddressDontSendf59kuE。我能找到的关于销毁地址的最古老的讨论发生在 2011 年 6 月 23 日,在关于“比特币黑洞”的 BitcoinTalk 跟帖[7]上。
中本聪在 BitcoinTalk 上的最后一次活动是 2010 年 12 月 13 日。最后一次有人收到他们的消息是在 2011 年 4 月 26 日。中本聪从未考虑过将其代币销毁作为一种选择,这似乎是合理的。
* * *
结论
在区块 54,316 之后,中本聪是否停止使用 Patoshi 矿工进行挖矿?我们无法知道挖矿软件是否被更改并因此变得无法检测,或者中本聪是否继续使用公开可用的挖矿软件进行挖矿。
关于中本聪,我有哪些确定的结论呢?
* 他的目标是在网络启动时保持网络的“心跳”。
* 他在一台最大哈希率为 6 Mhps 的机器上进行挖矿。
* 如果他全力开采,他本可以轻松赚取两倍以上的 BTC。
* 他不希望处于主导网络哈希率的位置,但在最初的日子里,由于只有不到五个矿工,网络更加脆弱,他可能觉得有必要。
* 他非常关心难度调整。调整算法是中本聪最伟大的创新之一,他对这个话题的看法比几乎任何其他人都多。
* 他希望尽可能多的人能够在家用 PC 上挖矿(中本聪谴责 FGPA / GPU 挖矿竞赛)
「为了网络的利益,我们应该达成君子协议,尽可能推迟 GPU 军备竞赛。如果新用户不必担心 GPU 驱动程序和兼容性,则他们更容易上手。很高兴任何人现在只要一个 CPU 就可以公平地竞争。」——中本聪
任何声称中本聪贪婪的人根本就没有做过上面这些计算。
* * *
参考资料:
- [1] https://blog.lopp.net/bitcoin-block-time-variance/
- [2] https://github.com/jlopp/bitcoin-utils/blob/master/findNonPatoshiDeltasAfterFastPatoshiBlocks.php
- [3] http://satoshiblocks.info/?bn=1600
- [4] https://github.com/jlopp/bitcoin-utils/blob/master/generateDifficultyHistoryCSV.php
- [5] https://bitcointalk.org/index.php?topic=1019.msg12683#msg12683
- [6] https://bitcointalk.org/index.php?topic=3635.msg53755#msg53755
- [7] https://bitcointalk.org/index.php?topic=21552.0
公众号:刘教链(同名推特:@liujiaolian)
根据央行等部门发布的“关于进一步防范和处置虚拟货币交易炒作风险的通知”,本文内容仅用于信息分享,不对任何经营与投资行为进行推广与背书,请读者严格遵守所在地区法律法规,不参与任何非法金融行为。