在机器学习和深度学习的世界中,线性回归模型是一种基础且广泛使用的算法,简单易于理解,但功能强大,可以作为更复杂模型的基础。使用PyTorch实现线性回归模型不仅可以帮助初学者理解模型的基本概念,还可以为进一步探索更复杂的模型打下坚实的基础。⚔️
💡在接下来的教程中,我们将详细讨论如何使用PyTorch来实现线性回归模型,包括代码实现、参数调整以及模型优化等方面的内容~
💡我们接下来使用Pytorch的API来手动构建一个线性回归的假设函数损失函数及优化方法,熟悉一下训练模型的流程。熟悉流程之后我们再学习如何使用PyTorch的API来自动训练模型~
import torch
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
import random
def creat_data():
x, y, coef = make_regression(n_samples=100, n_features=1, noise=10, coef=True, bias=14.5, random_state=0)
# 所有的特征值X都是0,目标变量y的平均值也会是14.5(加上或减去由于noise参数引入的噪声)
# coef:权重系数,表示线性回归模型中每个特征的权重,y_pred = x * coef + bias
x = torch.tensor(x)
y = torch.tensor(y)
return x, y ,coef # x , y 不是按顺序的, 而是随机顺序的
def data_loader(x, y, batch_size):
data_len = len(y)
data_index = list(range(data_len))
random.shuffle(data_index)
batch_number = data_len // batch_size
for idx in range(batch_number):
start = idx * batch_size
end = start + batch_size
batch_train_x = x[start: end]
batch_train_y = y[start: end]
yield batch_train_x, batch_train_y # 相当于reutrn, 返回一个值,但是不会结束函数
🧨这一部分creat_data是来生成线性回归的数据,coef=True(截距)表示所有的特征值X都是0时,目标变量y的平均值也会是14.5(加上或减去由于noise参数引入的噪声)
# 假设函数
w = torch.tensor(0.1, requires_grad=True, dtype=torch.float64)
b = torch.tensor(0.0, requires_grad=True, dtype=torch.float64)
def linear_regression(x):
return w * x + b
# 损失函数
def square_loss(y_pre, y_true):
return (y_pre - y_true) ** 2
# 优化方法(梯度下降)
def sgd(lr=0.01):
w.data = w.data - lr * w.grad.data / 16 # 批次样本的平均梯度值,梯度累积了16次
b.data = b.data - lr * b.grad.data / 16
def train():
# 加载数据集
x, y, coef = creat_data()
# 定义训练参数
epochs = 100
learning_rate = 0.01
# 存储训练信息
epochs_loss = []
total_loss = 0.0
train_samples = 0
for _ in range(epochs):
for train_x, train_y in data_loader(x, y, batch_size=16):
y_pred = linear_regression(train_x)
# 计算平方损失
loss = square_loss(y_pred, train_y.reshape(-1, 1)).sum() # 16个tensor(16行1列)
# print(loss)
total_loss += loss.item()
train_samples += len(train_y)
# 梯度清零
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
# 自动微分
loss.backward()
sgd(learning_rate)
print('loss:%.10f' % (total_loss / train_samples))
# 记录每一个epochs的平均损失
epochs_loss.append(total_loss / train_samples)
# 先绘制数据集散点图
plt.scatter(x, y)
# 绘制拟合的直线
x = torch.linspace(x.min(), x.max(), 1000)
y1 = torch.tensor([v * w + b for v in x])
y2 = torch.tensor([v * coef + b for v in x])
plt.plot(x, y1, label='训练')
plt.plot(x, y2, label='真实')
plt.grid()
plt.legend()
plt.show()
# 打印损失变化曲线
plt.plot(range(epochs), epochs_loss)
plt.grid()
plt.title('损失变化曲线')
plt.show()
if __name__ == '__main__':
train()🧨 我们将整个数据集分成多个批次(batch),每个批次包含16个数据。由于每个批次的数据都是随机抽取的。这样可以增加模型的泛化能力,避免过拟合。分批次训练可以提高学习的稳定性。当使用梯度下降法优化模型参数时,较小的批次可以使梯度下降方向更加稳定,从而更容易收敛到最优解。
🧨我们将这批数据每次分成16份训练,并且这样重复训练epochs次,可以更深入地学习数据中的特征和模式,有助于防止模型快速陷入局部最优解,从而提高模型的泛化能力,而且适当的epoch数量可以在欠拟合和过拟合之间找到平衡点,确保模型具有良好的泛化能力。
关于backward方法: 调用loss.backward()时,PyTorch会计算损失函数相对于所有需要梯度的参数的梯度。在我们的例子中,backward() 方法被调用在一个张量(即损失函数的输出)上。这是因为在 PyTorch 中,backward() 方法用于计算某个张量(通常是损失函数的输出)相对于所有需要梯度的参数的梯度。当 backward() 方法被调用时,PyTorch 会自动计算该张量相对于所有需要梯度的参数的梯度,并将这些梯度累加到对应参数的 .grad 属性上。
我们再来看一个例子:
def test03():
# y = x**2
x = torch.tensor(10, requires_grad=True, dtype=torch.float64)
for _ in range(500):
# 正向计算
f = x ** 2
print(x.grad)
# 梯度清零
if x.grad is not None:
x.grad.data.zero_()
# 反向传播计算梯度
f.backward()
# 更新参数
x.data = x.data - 0.01 * x.grad
print('%.10f' % x.data)
虽然
f本身不是损失函数,但在 PyTorch 中,任何需要进行梯度计算的张量都可以使用backward()方法来帮助进行梯度更新。这是自动微分机制的一部分,使得无论f是简单函数还是复杂的损失函数,都能利用相同的方法来进行梯度的反向传播。
我们看一下训练后的效果:
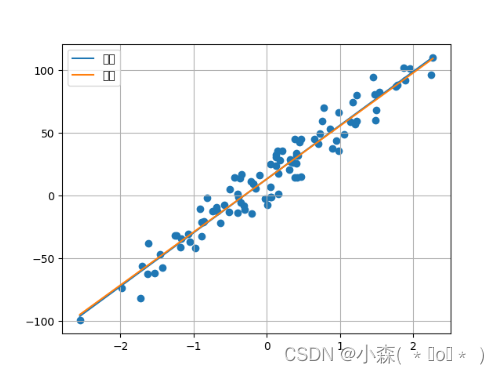
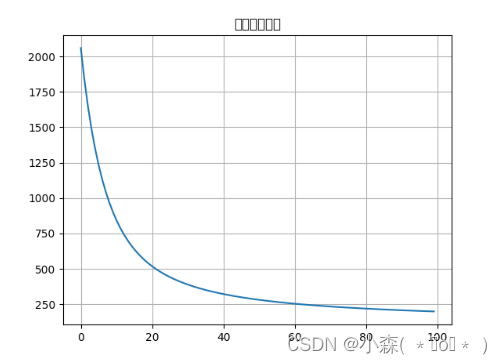
可以看到经过重复训练几乎和原本的真实直线吻合, 我们在每次epochs后都会记录平均损失,看一下平均损失的下降趋势:
回顾:随机梯度下降算法(SGD)
from sklearn.linear_model import SGDRegressor- 随机梯度下降算法(SGD)
- 每次迭代时, 随机选择并使用一个样本梯度值
由于FG每迭代更新一次权重都需要计算所有样本误差,而实际问题中经常有上亿的训练样本,故效率偏低,且容易陷入局部最优解,因此提出了随机梯度下降算法。其每轮计算的目标函数不再是全体样本误差,而仅是单个样本误差,即 每次只代入计算一个样本目标函数的梯度来更新权重,再取下一个样本重复此过程,直到损失函数值停止下降或损失函数值小于某个可以容忍的阈值。
但是由于,SG每次只使用一个样本迭代,若遇上噪声则容易陷入局部最优解。
🥂接下来我们看一下PyTorch的相关API的自动训练:
模型定义方法
- 使用 PyTorch 的 nn.MSELoss() 代替自定义的平方损失函数
- 使用 PyTorch 的 data.DataLoader 代替自定义的数据加载器
- 使用 PyTorch 的 optim.SGD 代替自定义的优化器
- 使用 PyTorch 的 nn.Linear 代替自定义的假设函数
- PyTorch的
nn.MSELoss():这是PyTorch中用于计算预测值与真实值之间均方误差的损失函数,主要用于回归问题。它提供了参数来控制输出形式,可以是同维度的tensor或者是一个标量。- PyTorch的
data.DataLoader:这是PyTorch中负责数据装载的类,它支持自动批处理、采样、打乱数据和多进程数据加载等功能。DataLoader可以高效地在一个大数据集上进行迭代。- PyTorch的
optim.SGD:这是PyTorch中实现随机梯度下降(SGD)优化算法的类。SGD是一种常用的优化算法,尤其在深度学习中被广泛应用。它的主要参数包括学习率、动量等,用于调整神经网络中的参数以最小化损失函数。- PyTorch的
nn.Linear:这是PyTorch中用于创建线性层的类,也被称为全连接层。它将输入与权重矩阵相乘并加上偏置,然后通过激活函数进行非线性变换。nn.Linear定义了神经网络的一个线性层,可以指定输入和输出的特征数。通过这些组件,我们可以构建和训练复杂的网络模型,而无需手动编写大量的底层代码。
接下来使用 PyTorch 来构建线性回归:
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
def create_data():
x, y, coef = make_regression(n_samples=100,
n_features=1,
noise=10,
coef=True,
bias=14.5,
random_state=0)
x = torch.tensor(x)
y = torch.tensor(y)
return x, y, coef
def train():
x, y, coef = create_data()
dataset = TensorDataset(x, y)
# 数据加载器
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
model = nn.Linear(in_features=1, out_features=1)
# 构建损失函数
criterion = nn.MSELoss()
# 优化方法
optimizer = optim.SGD(model.parameters(), lr=1e-2)
# 初始化训练参数
epochs = 100
for _ in range(epochs):
for train_x, train_y in dataloader:
y_pred = model(train_x.type(torch.float32))
# 计算损失值
loss = criterion(y_pred, train_y.reshape(-1, 1).type(torch.float32))
# 梯度清零
optimizer.zero_grad()
# 自动微分(反向传播)
loss.backward()
# 更新参数
optimizer.step()
# 绘制拟合直线
plt.scatter(x, y)
x = torch.linspace(x.min(), x.max(), 1000)
y1 = torch.tensor([v * model.weight + model.bias for v in x])
y2 = torch.tensor([v * coef + 14.5 for v in x])
plt.plot(x, y1, label='训练')
plt.plot(x, y2, label='真实')
plt.legend()
plt.show()
if __name__ == '__main__':
train()