上海AI Lab,香港中文大学等
论文标题:InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
论文地址:https://arxiv.org/abs/2404.06512
Code and models are publicly available at https://github.com/InternLM/InternLM-XComposer
一、问题提出
大型视觉语言模型(LVLM)对image captioning和视觉问答 (VQA)等任务的熟练。然而,由于分辨率有限,它们很难处理包含精细细节的图像,例如图表、表格、文档和信息图表。最近的进展旨在提高大视觉语言模型(LVLM)的分辨率。【Cogagent、Mini-Gemini、Kosmos-2.5、Vary】直接采用高分辨率视觉编码器。然而,Vision Transformer (ViT) 架构在处理不同分辨率和长宽比的图像时存在不足,从而限制了其有效处理不同输入的能力。或者,【mplug-docowl 1.5、Otterhd 、Monkey 、Sphinx、Llava-next、Textmonkey 、 Llava-uhd 】保持视觉编码器的分辨率,将高分辨率图像分割成多个低分辨率图像块。然而,这些方法受到分辨率不足的限制,通常在1500×1500左右,不能满足日常内容的需求,例如网站截图、文档页面和蓝图设计图。此外,它们仅限于一些预定义的高分辨率设置或有限的分辨率范围。
二、方法提出
InternLM-XComposer2-4KHD的模型架构主要沿用了InternLM-XComposer2的设计(为简单起见,下面简称为XComposer2),包括轻量级视觉编码器OpenAI ViT-Large/14、大型语言模型InternLM2-7B ,以及用于高效对齐的部分 LoRA。
1、High-Resolution Input.
动态图像分区 “Dynamic Image Partition.”
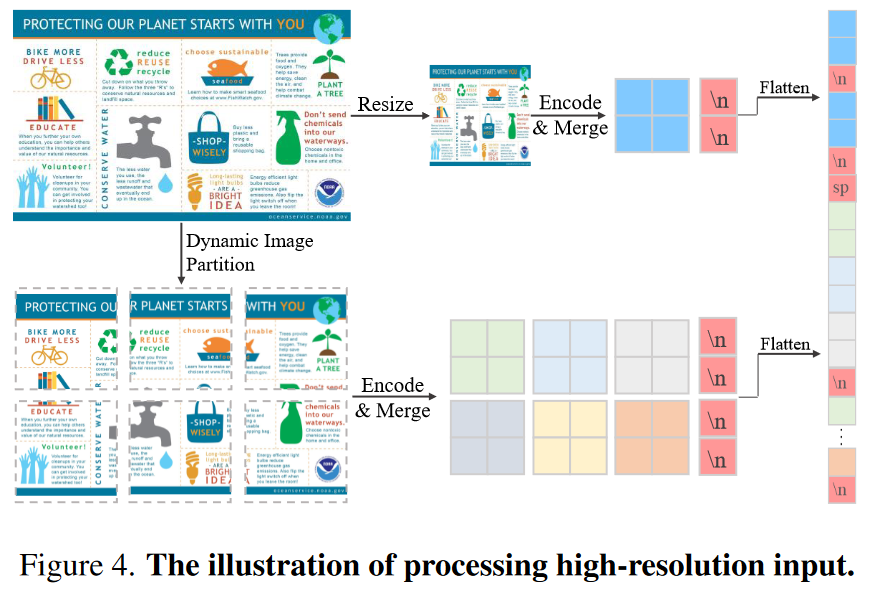
利用静态输入图像大小来处理高分辨率图像,尤其是那些具有不同纵横比的图像,既不高效也不有效。为了克服这一限制,引入了一种动态图像Partition方法。策略性地将图像分割成更小的块,同时保持原始图像长宽比的完整性。
给定最大分区数 H,大小为 [h, w] 的图像 x 被调整大小并填充到大小为 [ph × 336, pw × 336] 的新图像 x’:
![]()
pw 和 ph 分别代表每行和每列的 patch 数量。然后将 x’ 分割成 ph × pw 不重叠的patch。每个patch都是一个 336 × 336 大小的小图像,将这些补丁视为 ViT 的单独输入。使用“HD-H”来表示具有 H 个patch约束的高分辨率设置。例如,HD-9最多允许 9 个patch,包括一系列分辨率,例如 1008×1008 (3*3)、672×1344(2*4)、336×3024(1*8) 等。
Global-Local Format.
对于每个输入图像,将其以两个视图呈现给模型。第一个是全局视图,其中图像大小调整为固定大小( 336 × 336)。这提供了对图像的宏观理解。根据经验,这对于 LVLM 正确理解图像至关重要。第二个视图是局部视图。使用前面提到的动态图像分区策略将图像划分为补丁,并从每个patch中提取特征。特征提取后,补丁被重新组装成一个大的特征图。经过简单的标记合并过程后,特征图将被展平为最终的局部特征。
Image 2D Structure Newline Indicator.
图像具有 2D 结构,并且图像比例是动态的,每行的token数量在不同图像中可能会有所不同。这种变化可能会混淆 LVLM,从而难以确定哪些token属于图像的同一行,哪些token属于下一行。这种混乱可能会阻碍 LVLM 理解图像 2D 结构的能力,而这对于理解文档、图表和表格等结构图像内容至关重要。为了解决这个问题,在flatten前在图像特征的每行末尾引入了一个可学习的换行符(‘\n’)。最后,concate全局视图和局部视图,在它们之间插入一个特殊的‘separate’ token来区分这两个视图。
2、Pre-Training
在预训练阶段,LLM 被冻结,同时视觉编码器和部分 LoRA 都经过微调,以使视觉token与 LLM 保持一致。预训练数据主要遵循 XComposer2 中的设计,其设计考虑了三个目标:1) general semantic alignment, 2) world knowledge alignment, 3) vision capability enhancement。重点关注高分辨率和结构图像理解。因此,收集了更多相关数据来增强这一特定能力。
CLIP ViT-L-14-336 作为视觉编码器。使用“HD-25”。对于每个图像或patch,通过简单的‘merge’操作,图像token数量减少到 1/4。通过在channel维度将附近的 4 个 token 连接成一个新 token,然后通过 MLP 将其与 LLM 对齐。 “separate”和“\n”标记是随机初始化的。对于部分 LoRA,为 LLM 解码器块中的所有线性层设置等级为 256。训练4096 的批大小,2 个epoch。在训练step的前 1% 内,学习率线性增加到 2 × 10−4。此后,根据余弦衰减策略减小到 0。为保留视觉编码器预先存在的知识,应用分层学习率(LLDR)衰减策略,并将衰减因子设置为0.90。
3、KHD Supervised Fine-tuning
低分辨率输入可能会扭曲密集的文本信息,导致模型无法理解。为解决这个问题,引入混合分辨率训练策略以实现更高效的训练。对于需要高分辨率的任务,在训练期间采用“HD-55”。这样就可以输入 4K (3840 × 1600) 图像,而无需额外的图像压缩。对于其他任务,实施动态分辨率策略。图像的大小会调整到原始大小和“HD25”设置指定的大小之间的范围内。这种动态方法增强了 LVLM 针对输入分辨率差异的鲁棒性,从而使 LVLM 在推理过程中能够利用更大的分辨率。例如,观察到使用“HD30” vs “HD25”设置下进行训练时,HD30可以在大多数 OCR 相关任务上产生更好的结果。
联合训练批大小为 2048 的所有组件,超过 3500 个step。来自多个源的数据以加权方式采样,权重基于每个源的数据数量。由于“HD55”设置比“HD-25”具有双倍图像tokens,因此调整dataloader以启用不同的批大小,并相应地调整它们的权重。最大学习率设置为5×10−5,每个组件都有自己独特的学习策略。对于视觉编码器,将 LLDR 设置为 0.9,这与预训练策略一致。对于LLM,采用固定的学习率比例因子 0.2。这减慢了LLM的更新速度,在保留其原有能力和使其与视觉知识保持一致之间取得了平衡。
三、实验
1、LVLM Benchmark results.
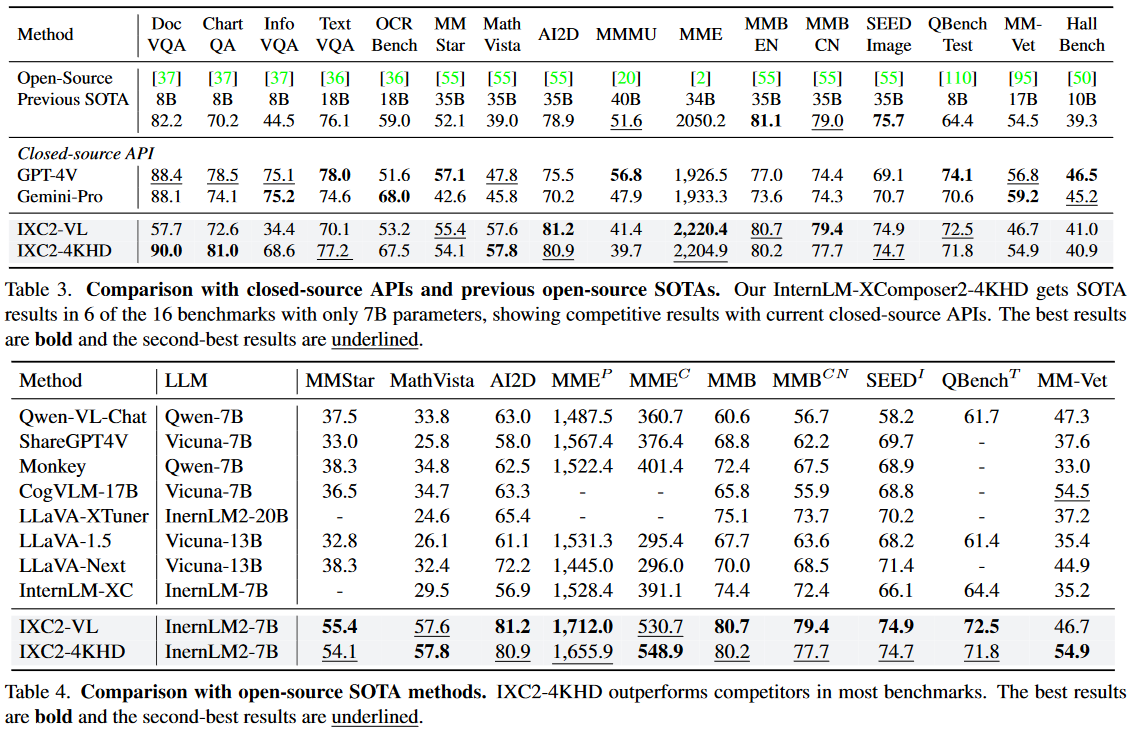
在表 3 和表 4 中,在一系列基准测试中将 IXC24KHD 与 SOTA 开源 LVLM 和闭源 API 进行了比较。评估主要在OpenCompass VLMEvalKit上进行,以便统一复现结果。
High-resolution Understanding Evaluation.
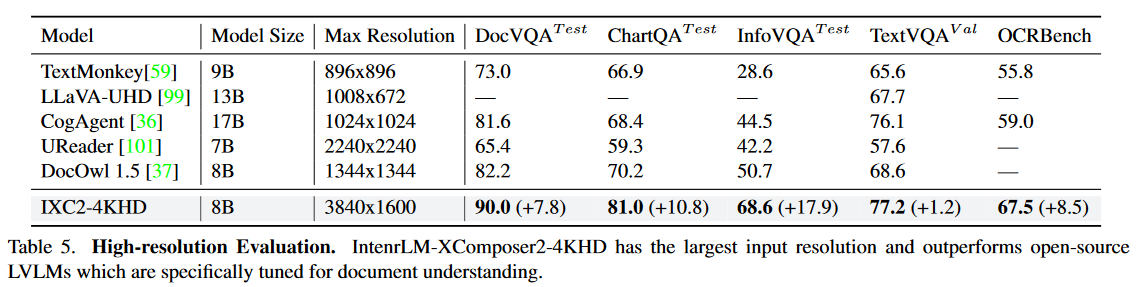
2、Dive into Resolution
High-Resolution Training is Critical for HD-OCR tasks
研究四种分辨率设置:HD-9(最多 1561 个图像token、HD16(2653 个token)、HD-25(4057 个token)和 4KHD(8737 个token)。在这里,报告了 InfoVQA、DocVQA 和 TextVQA 的验证集、ChartQA 和 AI2D 的测试集、MMBench EN-Test 以及 SEEDBench 的 2k 子集(将其表示为 SEED*)。
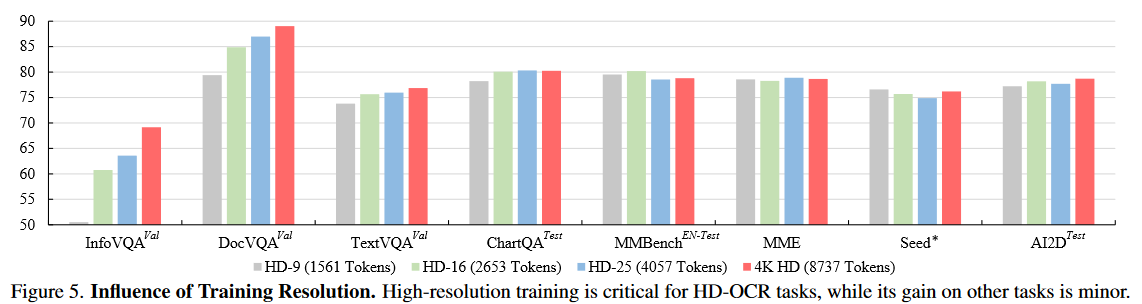
Higher Inference Resolution Leads to better results on Text-related Tasks.
模型在以稍高的分辨率进行推断时,往往会在文本相关任务上产生更好的结果。 HD-9、HD-16 和 HD-25 的结果。
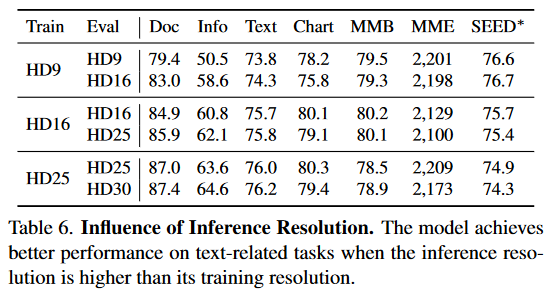
训练中使用的自然图像token长度增强了 LVLM 的鲁棒性,当图像中的文本在更高分辨率的输入中更加“清晰”时,会产生更好的结果。相反,在此设置下,ChartQA 的结果始终会下降。这可能是由于当分辨率改变时模型对图表结构变得混乱。此外,与图 5 中的观察结果类似,分辨率对感知相关基准的影响似乎相当小。
可视化结果

3、High-Resolution Strategy Ablation
The Role of Global-View.
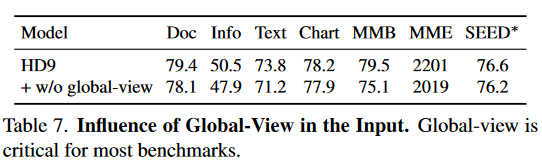
发现全局视图对于 LVLM 准确理解输入图像至关重要。当它被删除时,模型在所有基准测试中的表现都会变差。全局视图提供了对图像的一般宏观理解,而该模型很难从局部视图中的大量标记中得出这种理解。
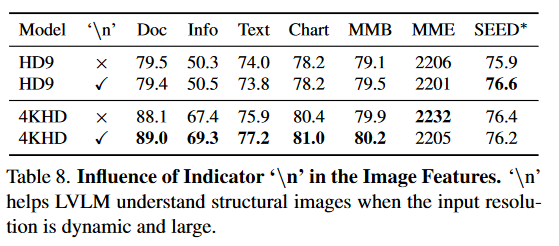
The Role of the Newline Token.
在展平操作之前,在图像特征的每行末尾合并一个特殊的换行符。该token用作图像 2D 结构的指示符。当采用固定高分辨率策略 HD-9 时,观察到换行token带来的好处很小。这可能归因于 LVLM 能够处理训练后图像比例的有限差异。然而,当实施更具挑战性的 4KHD(HD-25 + HD-55)策略时,该策略在图像比例和标记数量方面都表现出显着的多样性,在没有换行符的情况下,LVLM 在 OCR 相关任务上表现出显着的性能下降。当图像标记直接展平为一维序列时,LVLM 很难理解图像的形状。换行标记可以帮助模型更好地理解图像的结构。
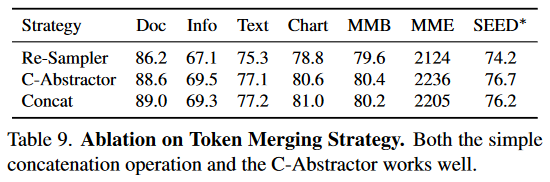
Influence of Token Merging Strategy.
采用一种简单的合并策略,沿着channel维度concate四个相邻的token。发现这种方法可以有效地减少图像标记的数量。研究了两种额外的策略:ReSampler和C-Abstractor,其默认设置和相同的压缩率0.25,即将具有576个token的图像减少到144个token。结果表明,串联和 C-Abstractor 都工作良好,并且在大多数基准上得到相似的结果。然而,ReSampler的性能比其他方法差,并且有明显的余量。认为这是由于用于收集信息的可学习查询需要大量数据进行训练而引起的,预训练数据对于它完全收敛来说有些轻量级。
![40+ Node.js 常见面试问题 [2024]](https://img-blog.csdnimg.cn/img_convert/f95dcda7bc8d02d3c8ce811ac5651d49.jpeg)


![【Hadoop】-Apache Hive概述 Hive架构[11]](https://img-blog.csdnimg.cn/direct/f5070b63db8f4e439514474a37c5a988.png)