目录
Apache Hive概述
一、分布式SQL计算-Hive
二、为什么使用Hive
Hive架构
一、Hive组件
Apache Hive概述
Apache Hive是一个在Hadoop上构建的数据仓库基础设施,它提供了一个SQL-Like查询语言来分析和查询大规模的数据集。Hive将结构化查询语言(SQL)语句转换为MapReduce任务或Tez任务,并在Hadoop集群上执行这些任务。
Hive的设计目标是为数据分析提供高效和易用的工具。它支持大规模的数据处理,并且可以处理PB级的数据。Hive的查询语言类似于传统的SQL,这使得开发人员和分析人员可以更轻松地使用它进行数据探索和分析
一、分布式SQL计算-Hive

对数据进行统计分析,SQL是目前最为方便的编程工具。
大数据体系中充斥着非常多的统计分析场景所以,使用SQL去处理数据,在大数据中也是有极大的需求的。
但我们hadoop里边的MapReduce支持程序开发(Java、python),但不支持SQL开发。
如果有一个什么办法,让我们大数据体系内支持SQL的话,这样就好办了。那怎么样支持呢?这就是我们的Apache Hive了。
Apache Hive是一款分布式SQL计算的工具,其主要功能是:
- 将SQL语句翻译成MapReduce程序运行
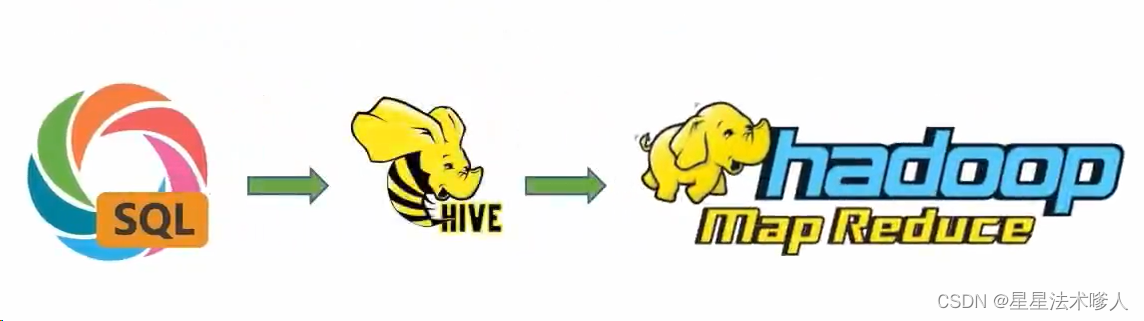
基于Hive为用户提供了分布式SQL计算能力,写的是SQL、执行的是MapReduce。
二、为什么使用Hive
现在很少有人去写MapReduce代码了,主要就是因为有一点就是MapReduce的代码写起来非常非常复杂。
使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高,需要掌握java、python等编程语言
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理
Hive架构
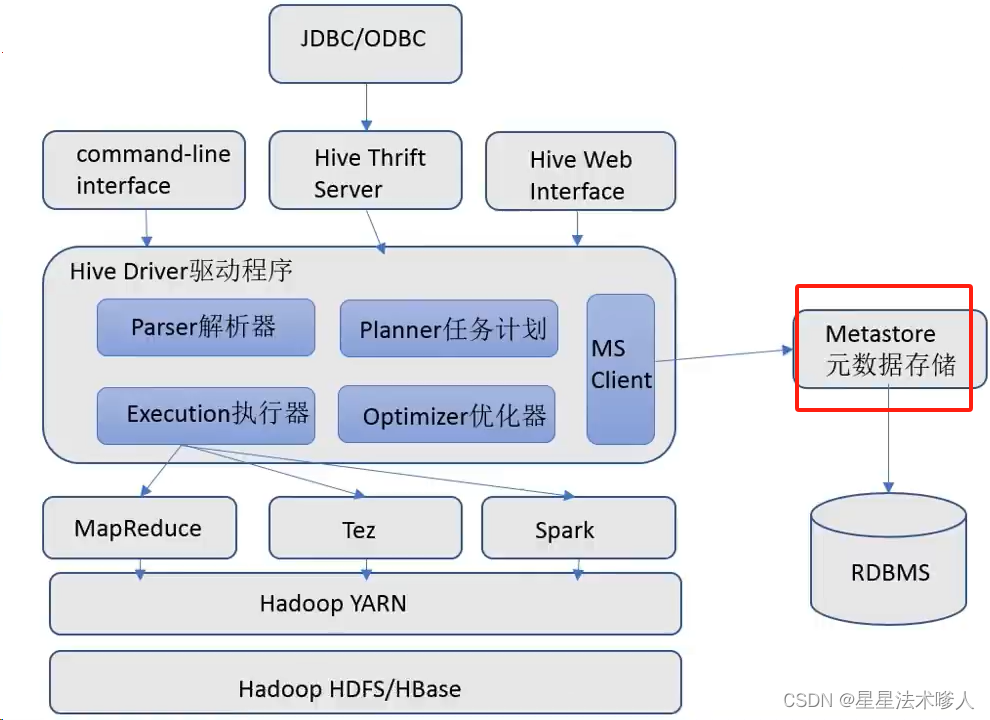
一、Hive组件
- 元数据存储
通常是存储在关系数据库如 mysql/derby 中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-----Hive提供了MetaStore服务进程提供元数据管理功能。
- SQL解析器(Driver驱动程序)、包括语法解析器、计划编译器、优化器、执行器
完成SQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行引擎调用执行。
这部分内容不是具体的服务进程,而是分装在Hive所依赖的Jar文件即Java代码中。


![下列程序定义了NxN的二维数组,并在主函数中自动赋值。请编写函数fun(int a[][N],int n),该函数的功能是:使数组右上半三角元素中的值乘以m。](https://img-blog.csdnimg.cn/direct/810d3107b3ec45bc8500a4afedf90d0e.png)