目录
卷积神经网络介绍
卷积神经网络原理
卷积层:通过在原始图片上平移来提取特征
激活层:增加非线性分割能力
池化层polling(下采样层):减少学习参数,去掉不重要的样本,降低网络的复杂度
卷积神经网络介绍
卷积神经网络与传统多层神经网络对比
传统多层神经网络只是输入层、隐藏层、输出层,其中隐藏层的层数根据需要而定,没有明确理论推导说明到底多少层合适
卷积神经网络,在原来多层的基础上加入更加有效的特征学习部分,具体就是在全连接层之前加上卷积层和池化层。
卷积神经网络原理
结构:卷积层 激活层 池化层 全连接层
卷积层:通过在原始图片上平移来提取特征
1、卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成,每个卷积单元的参数都是通过反向
传播算法最佳化得到的。卷积运算的目的是特征提取,第一层卷积层可能只能提取一些低级的特征
如边缘、线条和角等层级,更多层的网络能从低级特征中选代提取更复杂的特征。
2、 卷积核
卷积核 - filter -过滤器 -模型参数
卷积如何计算?带着若干权重和偏置,进行特征加权运算
卷积核常用大小:1*1 3*3 5*5
个数:多个卷积核进行卷积,得到多个结果 不同卷积核带的权重和偏置不一样
步长:每次平移步长
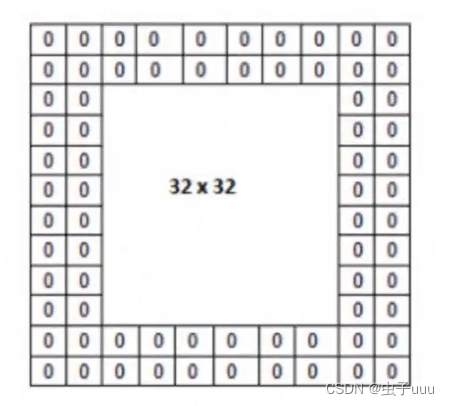
零填充大小:在图片像素外围填充一圈值为0的像素(根据需求定大小)
输出大小计算:

例:输出图像32*32*1,50个Filter,大小5*5,移动步长1,零填充大小1,求出输出大小?
H1 = 32 D1 = 1 K = 50 F = 5 S = 1 P = 1
H2 = (32-5+2) / 1 + 1 = 30
D2 = 50
输出为(30,30,50)
3、卷积网络API
tf.nn.conv2d(input, filter, strides=, padding=, name=None)
计算给定4-D input和filter张量的2维卷积
input:输入图像,形状具有[batch,heigth,width,channel],类型为float32,64
filter:指定过滤器的权重数量,[filter_height,filter_width,in_channels,out_channels]
strides:strides=[1,stride,stride,1],步长
padding:“SAME”,“VALID”
SAME(使用更多):越过边缘取样,取样的面积和输入图像的像素宽度一致。
VALID:不越过边缘取样,取样的面积小于输入人的图像的像素宽度。不填充

不能保证每次都完全在取的范围内,增加零填充就不会存在超出边缘
激活层:增加非线性分割能力
之前使用的sigmold计算量大,反向传播可能会出现梯度消失
1、ReLU
ReLU = max(0,x)
计算速度非常快
解决了梯度消失
图像没有负的像素值
2、激活函数API
tf.nn.relu(feature,name = None)
ferture:卷积后加上偏置的结果
return:结果
池化层polling(下采样层):减少学习参数,去掉不重要的样本,降低网络的复杂度
max_polling:取池化窗口的最大值
avg_polling:取池化窗口的平均值
池化层计算与卷积层一样
池化层API
tf.nn.max_pool(value, ksize=, strides=, padding=,name=None)
输入上执行最大池数
value: 4-D Tensor形状batch, height, width, channels]
channel:并不是原始图片的通道数,而是多少filter观察
ksize:池化窗口大小,[1,ksize,ksize,1]
strides:步长大小,[1,strides,stride,1]
padding:“SAME”,“VALID”,使用的填充算法的类型,默认使用“SAME”
使用max_polling进行池化