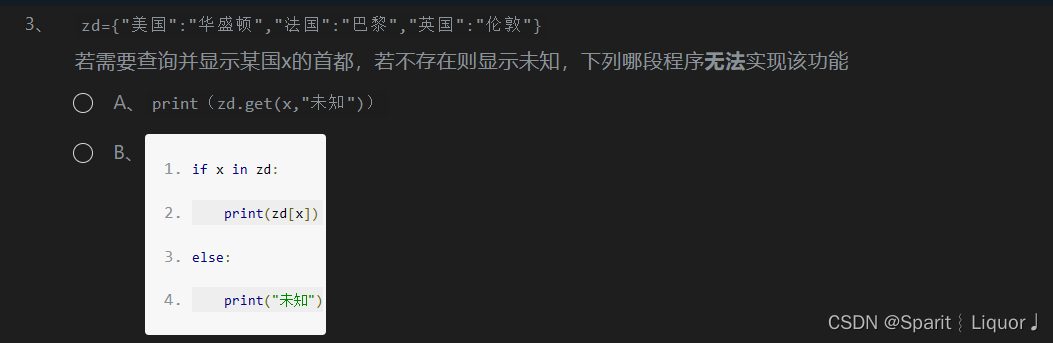
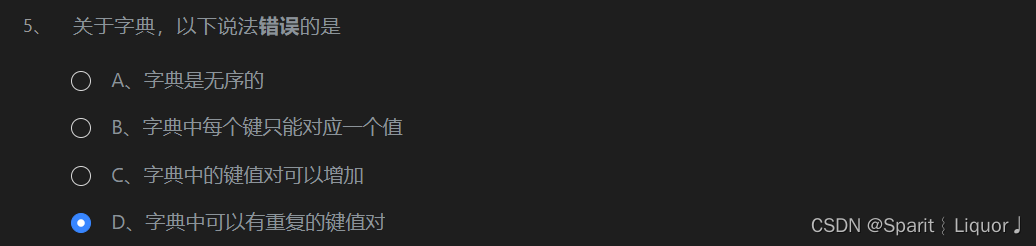
教学案例十 字典
1. 判断出生地
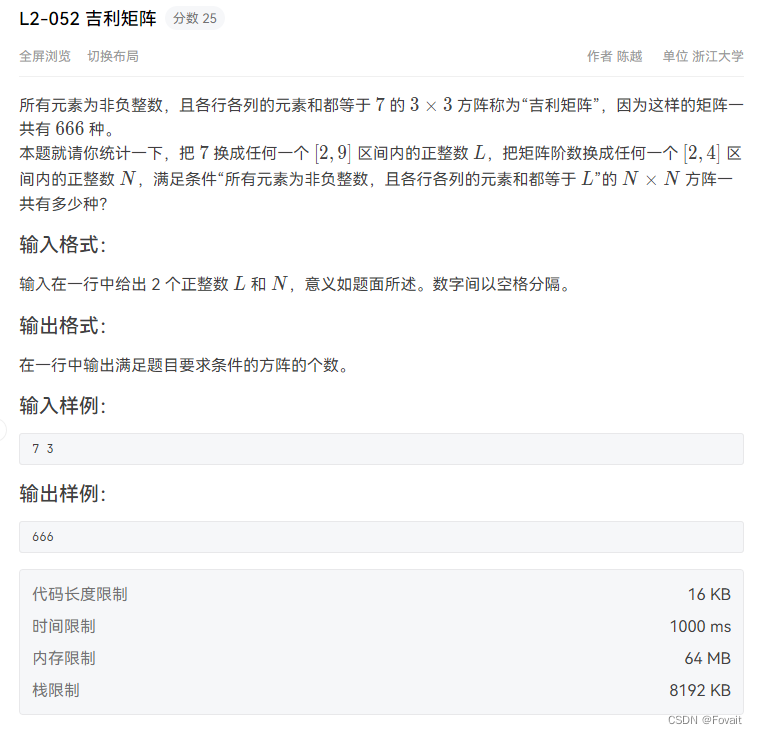
sfz.txt文件中存储了地区编码和地区名称
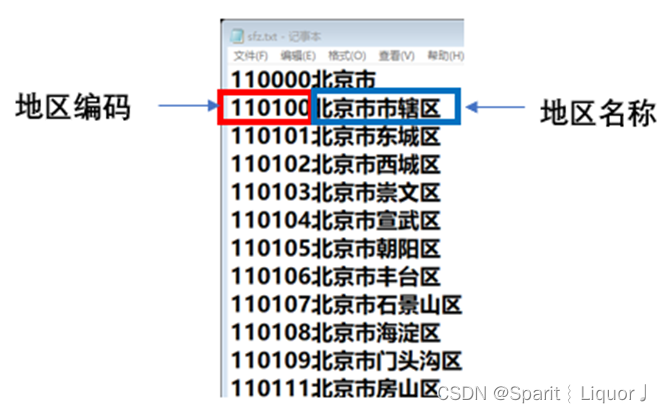
身份证的前6位为地区编码,可以在sfz.txt文件中查询到地区编号对应的地区名称

编写程序,输入身份证号,查询并显示对应的地区名称 若该地区编码不在文件中,显示地区名称 未知
文件操作
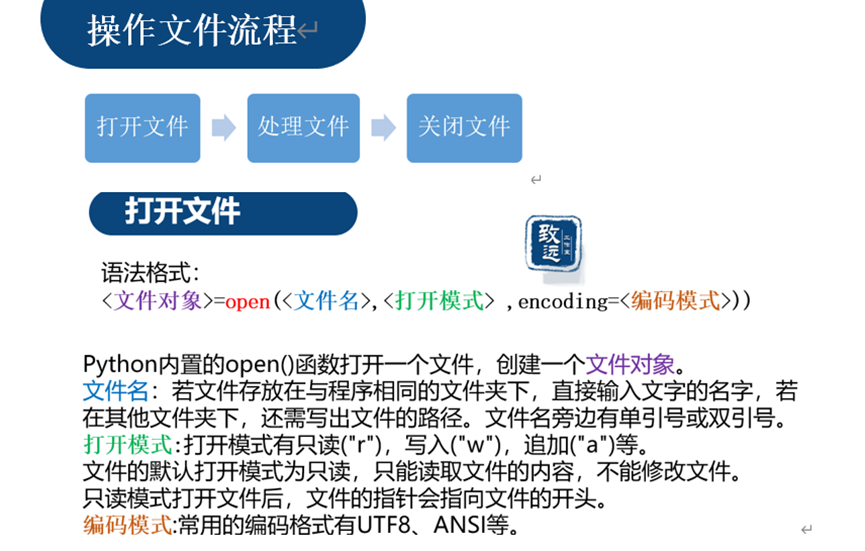

例

 注意:字符串.strip(指定字符)方法,返回去除字符串尾部的指定字符后的字符串。若不指定字符,则去除尾部的空格和换行符。
注意:字符串.strip(指定字符)方法,返回去除字符串尾部的指定字符后的字符串。若不指定字符,则去除尾部的空格和换行符。
字典的建立

若要建立以地区编码为键,地区名称为值的字典,可以打开文件,读取一行,将前六个字符(地区编号)作为键,第七个字符到最后(地区名称)作为值,建立字典。
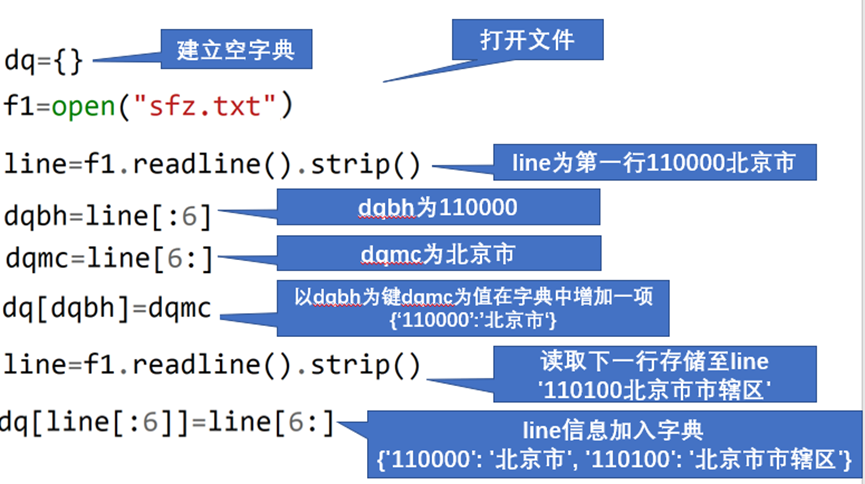
对所有的行循环,就可以建立所有地区编号和名称的字典。

字典的查找
<字典>.get(<键>,<默认值>) 在字典中,若存在该键,则返回相应的值,否则返回默认值 如果地区字典dqzd已经建立,通过get方法可以查找编码对应的地区名称,若无法找到,则返回未知

sfzh=input("请输入身份证号")
#代码开始
f1=open("step6//sfz.txt","r",encoding='GBK')
dq = {}
for i in f1.readlines():
i = i.strip()
dq[i[:6]]=i[6:]
print("地区名称",dq.get(sfzh[:6],"未知"))
#代码结束2. 统计文档中作者作品数量
编写一个能计算文档《唐诗.txt》中各位作者作品数量的程序。 遍历文档中每一行,提取作者的姓名,将其作为键加入到字典中,字典的值为作品数量。 然后将字典转换为二维列表,按作品数量的降序排列。

字典的操作
字典是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示 d = {key1 : value1, key2 : value2 } 建立空字典 d={} 向字典添加新内容的方法是增加新的键/值对 d["范仲淹"]=1 则d为{"范仲淹":1} 修改键值对的方法为 d["范仲淹"]=2 则d为{"范仲淹":2} d["范仲淹"]的值为2
d.get(key,default)键存在则返回相应值,否则返回默认值
字典转换为二维列表
lt = list(d.items()) 可将字典转换为二维列表, 二维列表的每项值为列表,列表的第一项为字典的键,第二项为字典的值
f1=open("sy9//唐诗.txt","r",encoding='GBK')
#代码开始
zd = {}
for i in f1.readlines():
i = i.strip()
if i[:3].isdigit()==True:
n = i.split(":")[0][3:]
zd[n]=zd.get(n,0)+1
lb = list(zd.items())
lb.sort(key=lambda x:x[1],reverse=True)
#代码结束
for i in lb:
print("诗人{}作品{}".format(i[0],i[1]))
f1.close()
3. 计算成绩及排序
成绩.csv如下所示,记录了同学的语数外的成绩、综合测评和体育成绩

综合测评有ABCD四个等级,体育成绩有优秀良好及格不及格四个等级 ABCD折算为100、80、60、0。 优秀良好及格不及格折算为100、80、60、0 现计算每个人的总分并从高到低的排序,显示姓名和总分。
f1=open("sy9//成绩.csv","r",encoding="utf8")
zh={"A":100,"B":80,"C":60,"D":0}
ty={"优秀":100,"良好":80,"及格":60,"不及格":0}
#代码开始
xx = []
for i in f1.readlines():
i = i.strip().split(",")
cj = int(i[1])+int(i[2])+int(i[3])+zh[i[4]]+ty[i[5]]
xx.append([i[0],cj])
xx.sort(key=lambda x:x[1],reverse=True)
#代码结束
for mm in xx:
print("姓名{}成绩{}".format(mm[0],mm[1]))
f1.close()4. 统计语文成绩各等级人数
成绩.csv如下所示,记录了同学的语数外的成绩、综合测评和体育成绩

现要统计语文科目优秀(90分及以上)、良好(80分-90分)、及格(60分-80分)、不及格人数
f1=open("sy9//成绩.csv","r",encoding="utf8")
yw={"优秀":0,"良好":0,"及格":0,"不及格":0}
#代码开始
for i in f1.readlines():
i = i.strip().split(",")
n = int(i[1])
if n >= 90:
yw["优秀"] += 1
elif n >= 80:
yw["良好"] += 1
elif n >= 60:
yw["及格"] += 1
else:
yw["不及格"] += 1
#代码结束
print("语文")
for mm in yw:
print("{}人数{}".format(mm,yw[mm]))
f1.close()5. 统计语数外成绩各等级人数
成绩.csv如下所示,记录了同学的语数外的成绩、综合测评和体育成绩

现要统计语数外各科目成绩优秀(90分及以上)、良好(80分-90分)、及格(60分-80分)、不及格人数。

f1=open("sy9//成绩.csv","r",encoding="utf8")
djrs=[]
km="语文","数学","英语"
for i in range(3):
djrs.append({"优秀":0,"良好":0,"及格":0,"不及格":0})
#代码开始
for i in f1.readlines():
i = i.strip().split(",")
for j in range(3):
n = int(i[j+1])
if n >= 90:
djrs[j]["优秀"] += 1
elif n >= 80:
djrs[j]["良好"] += 1
elif n >= 60:
djrs[j]["及格"] += 1
else:
djrs[j]["不及格"] += 1
#代码结束
for i in range(3):
print(km[i])
for mm in djrs[i]:
print("{}人数{}".format(mm,djrs[i][mm]))
f1.close()6. 统计文件词语的词频
编写一个能统计文档中词语词频小程序。

统计文件中词频最高的15个词语(除了词牌名和作者) 注意:标题行的空格是全角空格" "(可复制此空格) 由于有一个词牌名为东风第一枝,需要将文件中的词牌名删除。(否则会多一个东风)

jieba库分词
jieba是Python中一个重要的第三方中文分词函数库 Jieba库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组。 jieba.lcut(s) 精确模式对字符串s分词,产生一个列表
import jieba
f1= open("sy9//唐诗.txt", "r",encoding="GBK")
#代码开始
lb = []
for i in f1.readlines():
i = i.strip()
if i[:3].isdigit()==True:
i = i.split(":")[1]
if i[3:5]=="二首":
i = i[:3]
n = jieba.lcut(i)
for j in n:
lb.append(j)
zd = {}
for i in lb:
if len(i) == 1:
continue
else:
zd[i]=zd.get(i,0)+1
zd["东风"]=zd.get("东风",0)-1
items=list(zd.items())
items.sort(key=lambda x:x[1],reverse=True)
#代码结束
for i in range(15):
print("{} {}".format(items[i][0],items[i][1]))
7. 唐诗文件词云图片
根据唐诗文件生成一个词云图片文件,存放在sy9文件夹的pict文件夹下的sc1.png ,要求图片宽1000,高700背景颜色白色,最多300个词 ,注意:字体使用sy9文件夹下的simhei.ttf字体文件

生成词云图片
wordcloud库概述 wordcloud是python的一个三方库,称为词云也叫做文字云,是根据文本中的词频,对内容进行可视化的汇总.
wordcloud.WordCloud(参数)
font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,
如:font_path = 'sy9//simhei.ttf’
width : int (default=400) #输出的画布宽度,默认为400像素
height : int (default=200) #输出的画布高度,默认为200像素
background_color : color value (default=”black”) #背景颜色,如background_color='white',背景颜色为白色
max_words : number (default=200) #要显示的词的最大个数
import jieba
import wordcloud
f1= open("sy9//唐诗.txt", "r",encoding="GBK")
#代码开始
txt = f1.read()
pc = set()
f1.seek(0,0)
for line in f1:
if " " in line:
cp=line[:line.find(" ")]
pc.add(cp)
xm=line[line.find(" ")+1:].split("\n")
pc.add(xm[0])
for i in pc:
txt = txt.replace(i,"")
zd = {}
words = jieba.lcut(txt)
for i in words:
if len(i) > 1:
zd[i] = zd.get(i,0)+1
print(zd)
f1.close()
w=wordcloud.WordCloud(font_path="sy9//simhei.ttf",background_color="white",max_words=300,width=1000,height=700)
w.generate_from_frequencies(zd)
#代码结束
w.to_file("sy9//pict//sc1.png")8. 选择题