一、前言
今天在网上偶遇一款html解析利器HtmlAgilityPack,免费下载地址:入口。
HtmlAgilityPack是.net下的一个HTML解析类库,支持用XPath来解析HTML。通过该类库,先通过浏览器获取到xpath获取到节点内容然后再通过正则表达式匹配到所需要的内容,无论是开发速度,还是运行效率都有提升。
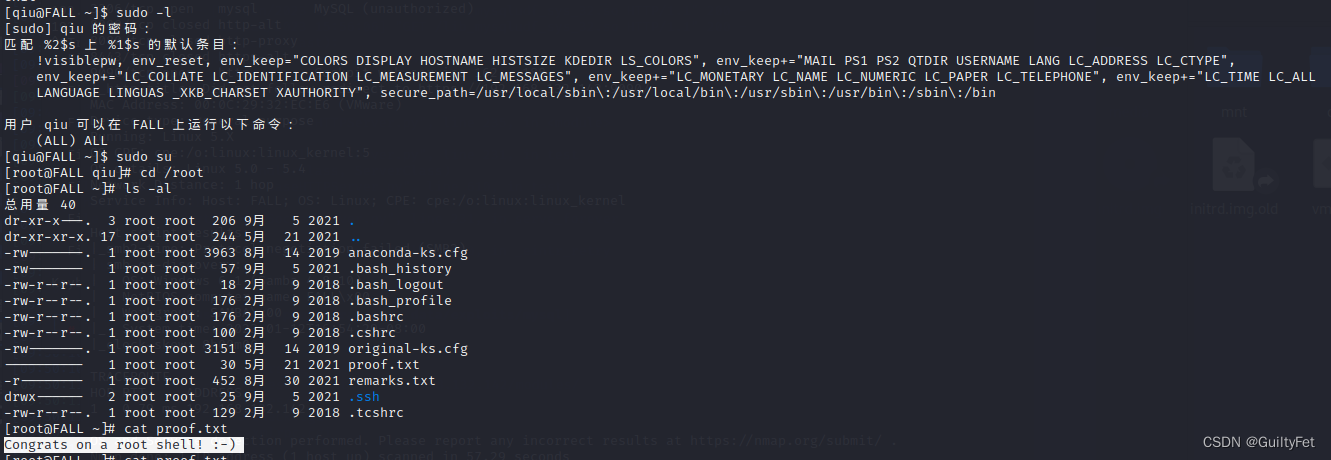
二、效果图
这里拿我的博客主页试试手,先看解析结果:

三、程序分析
1、主程序如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
string uri = @"https://blog.csdn.net/marcopro/article/list/1";
HttpWebRequestHelper httpReq = new HttpWebRequestHelper();
string strHtml = httpReq.Get(uri);
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(strHtml);
HtmlNodeCollection articleList = htmlDoc.DocumentNode.SelectNodes("//div[@class='article-item-box csdn-tracking-statistics']");
if (articleList.Count > 0)
{
foreach (var item in articleList)
{
string itemHtml = item.InnerHtml;
Regex re = new Regex(@"<a[^>]*href=(""(?<href>[^""]*)""|'(?<href>[^']*)'|(?<href>[^\s>]*))[^>]*>(?<text>.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
Match m = re.Match(itemHtml);
if (m.Success)
{
string link = m.Groups["href"].Value;
string text = Regex.Replace(m.Groups["text"].Value, "<[^>]*>", "");
text = text.Replace("原创", "").Trim();
Console.WriteLine("link:{0}\ntext:{1}", link, text);
}
}
}
Console.Read();
}
}
}2、获取页面html
string uri = @"https://blog.csdn.net/marcopro/article/list/1";
HttpWebRequestHelper httpReq = new HttpWebRequestHelper();
string strHtml = httpReq.Get(uri);这里获取html的时候需要注意编码问题,不让会出现中文乱码,这里我用了utf-8编码
/// <summary>
/// 获取页面html encodingname:gb2312/utf-8
/// </summary>
/// <param name="uri">访问url</param>
/// <returns></returns>
public string Get(string uri)
{
return Get(uri, uri, "utf-8");
}
/// <summary>
/// 获取页面html encodingname:gb2312
/// </summary>
/// <param name="uri">访问url</param>
/// <param name="refererUri">来源url</param>
/// <returns></returns>
public string Get(string uri, string refererUri)
{
return Get(uri, refererUri, "utf-8");
}
/// <summary>
/// 获取页面html
/// </summary>
/// <param name="uri">访问url</param>
/// <param name="refererUri">来源url</param>
/// <param name="encodingName">编码名称 例如:gb2312</param>
/// <returns></returns>
public string Get(string uri, string refererUri, string encodingName)
{
return Get(uri, refererUri, encodingName, (WebProxy)null);
}
/// <summary>
/// 获取页面html
/// </summary>
/// <param name="uri">访问url</param>
/// <param name="refererUri">来源url</param>
/// <param name="encodingName">编码名称 例如:gb2312</param>
/// <param name="webproxy">代理</param>
/// <returns></returns>
public string Get(string uri, string refererUri, string encodingName, WebProxy webproxy)
{
string html = string.Empty;
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(uri);
request.ContentType = "text/html;charset=" + encodingName;
request.Method = "Get";
request.CookieContainer = cookieContainer;
if (null != webproxy)
{
request.Proxy = webproxy;
if (null != webproxy.Credentials)
request.UseDefaultCredentials = true;
}
if (!string.IsNullOrEmpty(refererUri))
request.Referer = refererUri;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (Stream streamResponse = response.GetResponseStream())
{
using (StreamReader streamResponseReader = new StreamReader(streamResponse, Encoding.GetEncoding(encodingName)))
{
html = streamResponseReader.ReadToEnd();
}
}
}
return html;
}2、获取博客清单html
根据获取的html源码稍作分析会发现,博客园的博客清单都有标签class='article-item-box csdn-tracking-statistics',所以通过HtmlAgilityPack的解析,直接获取所有博客清单div。
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(strHtml);
HtmlNodeCollection articleList = htmlDoc.DocumentNode.SelectNodes("//div[@class='article-item-box csdn-tracking-statistics']");
3、 解析博客标题和链接地址
HtmlAgilityPack解析出来的只是代码段,还需要把博客的标题和链接抽取出来,这里用到了则正则表达式来处理
if (articleList.Count > 0)
{
foreach (var item in articleList)
{
string itemHtml = item.InnerHtml;
Regex re = new Regex(@"<a[^>]*href=(""(?<href>[^""]*)""|'(?<href>[^']*)'|(?<href>[^\s>]*))[^>]*>(?<text>.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
Match m = re.Match(itemHtml);
if (m.Success)
{
string link = m.Groups["href"].Value;
string text = Regex.Replace(m.Groups["text"].Value, "<[^>]*>", "");
text = text.Replace("原创", "").Trim();
Console.WriteLine("link:{0}\ntext:{1}", link, text);
}
}
}至此,就解析出完整的博客清单了。
四、小结
观察一下url地址:https://blog.csdn.net/marcopro/article/list/1
这里博客会有分页,我们可以再加一次页码遍历即可获取所有的博客清单