目标检测:YOLO V2思路解读
- YOLO V1存在的问题
- 主要改进
- Batch Normalization
- High Resolution Classifier
- Convolutional With Anchor Boxes
- Dimension Cluster
- Direct location Prediction
- Fine-Grained Features
- Multi-Scale Training
- Loss Function
YOLO V1存在的问题
- 对于小或者多的目标识别效果不好(由于grid cell 少且每个grid cell预测两个框)
- 与同时期的检测网络相比recall 比较低
- 速度与精度都不如ssd
主要改进
Batch Normalization
如果还不了解BN层:Batch Normliaztion 详细指南
BN层起初作者认为可以缓解 内部斜变量便宜,后来通过实验说其实是通过对每个batch的每个神经元➕噪声来缓解过拟合,增加泛化性能,这也是它不与DropOut在一起用的原因。作者在每一个卷基层后都加上了BN层,与原始的YOLO相比,加入BN层为模型精度贡献了2%左右的mAP。
High Resolution Classifier
作者原始在YOLOV1中使用了在ImageNet数据上Pre-Train的模型BackBone,由于检测任务对feature map的 细粒度要求苛刻,作者把224 * 224 的input size 换成了 448 * 448,但是ImageNet数据集的图片的尺寸是224 * 224 ,这意味着模型需要去适应新的尺寸,所以我们把把imagenet448尺寸的图像在backbone中训练了10个epoch以达到fine-tune的效果,这个操作为我模型精度贡献了4%左右的mAP。
切换尺寸不需要改变模型结构的原因是结尾的全连接层用全局平均池化层代替。
Convolutional With Anchor Boxes
RCNN系列论文解读
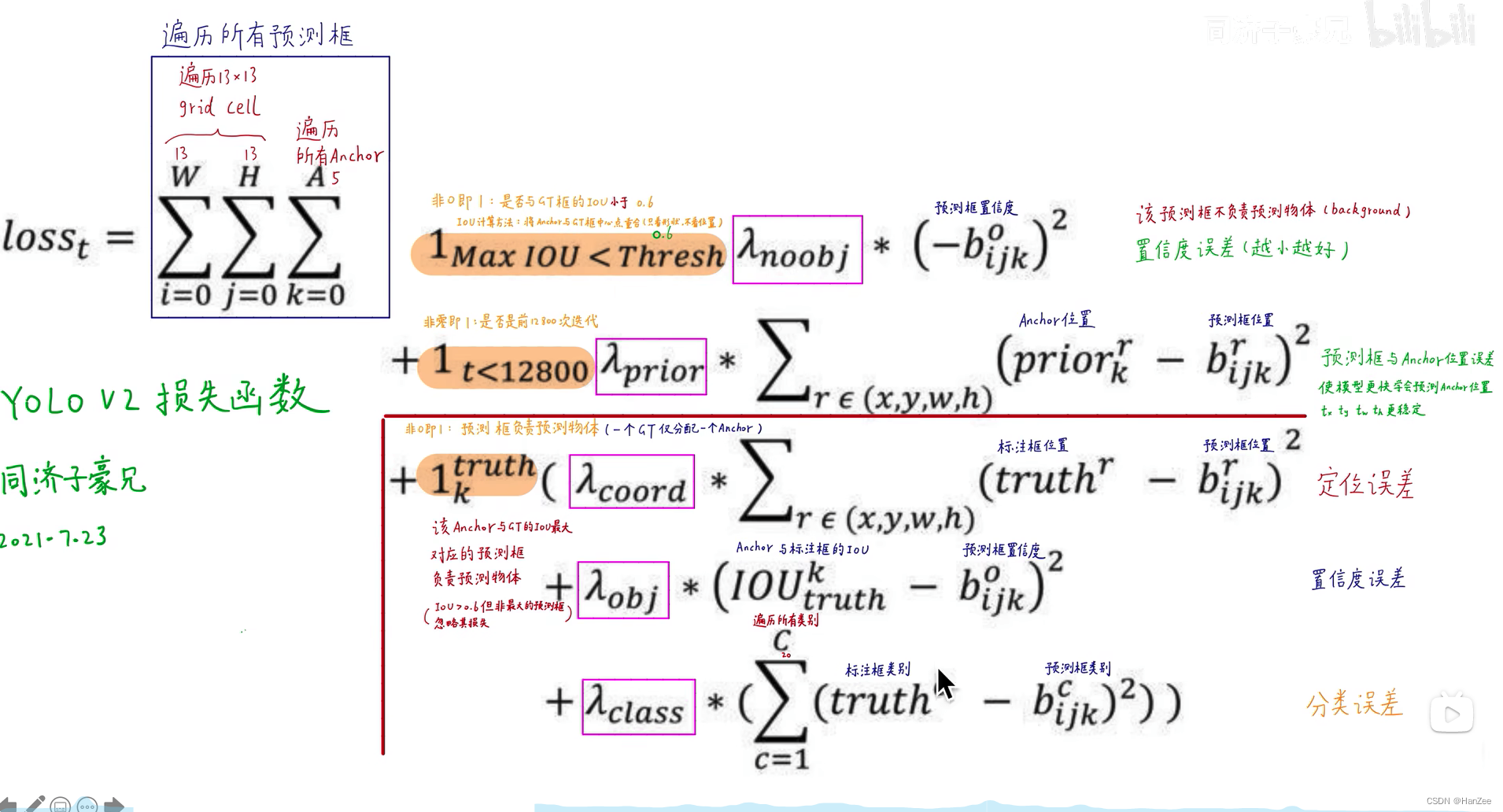
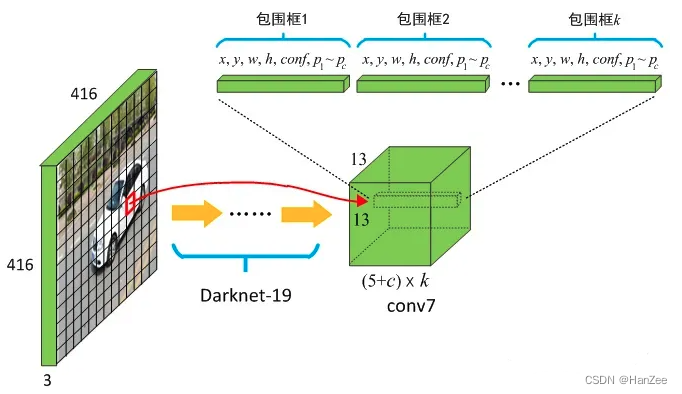
在YOLO V1中,每个grid cell 采取直接预测bounding box坐标的方式,而Faster RCNN是采取Anchor的机制来预测(手动采取先验框),为了简化学习目标,作者在YOLO中也加入了Anchor的机制,预测的是偏移量,具体细节下方详细介绍。
其次作者把input size 从448改为416,当出现特别的大目标的时候,通常占据了正常图像的很大一部分,作者希望负责预测的这个大目标的grid cell的位置在图像正中央,而416刚好可以划分出grid cell长宽个数为基数,也就是正中央存在唯一的 grid cell。
最后 image通过卷积网络后得到 13 * 13 * 125 (25 * 5 5个anchor ,每个anchor有 4个坐标+ confidence + 20class)的feature map。
通过上述操作,为模型反而减少了0.2的map,但是recall从 81%增加到了 88%,但是这意味着模型有更大的提升空间。
Dimension Cluster
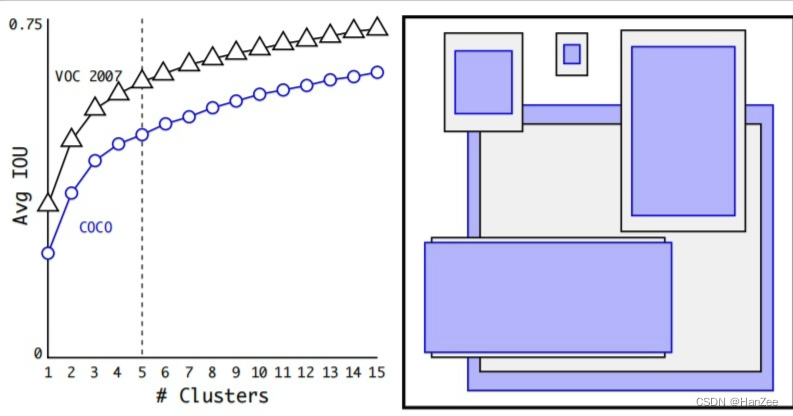
在采取anchor机制的时候遇到了两个问题,第一个问题是在anchor的大小需要手动选择,网络不能根据数据去调整来得到更好的priors,为了让模型更好与容易的学习检测任务,作者通过k-means方法聚类数据集中真实框,收敛后,每个聚类中心就是我们anchor的尺寸,我们划分多少个聚类中心,每个gird cell就有多少个anchor,最后作者选择5来达到一个速度与精度的权衡。
对于特定问题,作者也采取特定的distance metric:
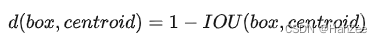
最后作者通过实验对比发现: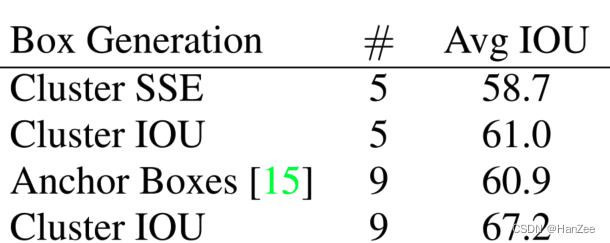
通过聚类只要生成5个 anchor就能达到Faster RCNN9个anchor的作用。
Direct location Prediction
作者在引入anchor机制后遇到的第二个问题就是在模型训练的初期,预测框的坐标以前的计算公式参考了Faster RCNN的方法,公式如下:
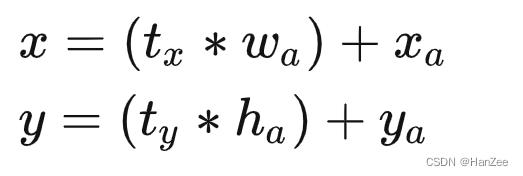
其中x y 为预测框的中心点,tx ty为模型预测的偏移量, wh为anchor的宽高,xa ya为anchor的中心点,但是这个方法tx ty是不受限制的,在训练初期数值不稳定,于是作者对其做了归一化处理,具体处理方法如下:
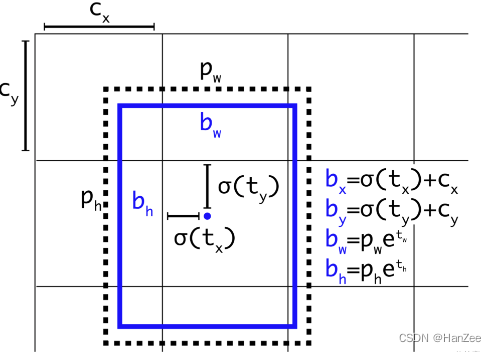
对tx ty做了sigmid归一化,其中b 为预测框的坐标,tx为模型输出的偏移量,而这个偏移量与rcnn的方式不同,这个偏移量不是相对于anchor,而是相对于grid cell左上角坐标的偏移量,也 cx cy 就是grid cell左上角的坐标。
上述操作会让学习变得更稳定,问模型的mAP贡献了1%的精度。
Fine-Grained Features
这种方法主要是把浅层特征与深层特征融合在一起,可以更好的适应大小目标,方法省略。
Multi-Scale Training
多尺度的训练原始的YOLO使用448×448的输入分辨率。通过添加锚框,我们将分辨率改为416×416。然而,由于我们的模型只使用卷积层和池化层,因此可以实时调整大小。我们希望YOLOv2能够鲁棒地运行在不同尺寸的图像上,所以我们将多尺度训练应用到模型中。
我们不需要修改输入图像的大小,而是每隔几个迭代就改变网络。每10个批次,我们的网络就会随机选择一个新的图像尺寸。由于我们的模型缩减了32倍,我们从以下32的倍数中抽取:{320, 352, …, 608}。因此,最小的选项是320 × 320,最大的是608 × 608。我们将调整网络的尺寸,然后继续训练。
Loss Function