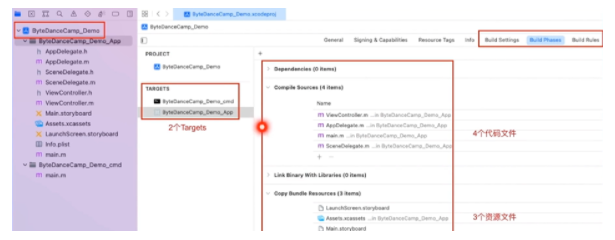
目录
- 适应性学习率 Adaptive learning rate
- 为什么不是临界点仍会导致训练停止
- 示例一
- 示例二
- RMS
- RMSProp
- Adam
- 学习率还和时间有关
- Learin Rate Decay
- Warm up
- 为什么不是临界点仍会导致训练停止
2021 - 类神经网络训练不起来怎么办(三) 自动调整学习率 (Learning Rate)
适应性学习率 Adaptive learning rate
一般训练过程中训练不起来,很少是critical point的问题。大部分都是gradient优化器的问题。
上图中loss不再变化,但gradient向量值并不会很小,并不在临界点上。 这种现象的出现在gradient($
w_{i+1}=w_i-\eta \times \frac{\partial loss}{\partial w}|_{w=w^0}
$)中主要是因为η太大导致在临界点周围反复横跳,如下图


为什么不是临界点仍会导致训练停止

示例一
起初,gradient比较大,若此时学习率η也比较大,会导致参数在error surface两边震荡更新如上图。

示例二
起初,gradient比较大,若此时学习率η比较小,则参数更新的程度也会比较小,从而能够到达临界点附近,但因为临界点附近gradient比较小,而此时学习率η也比较小,故参数的更新程度就会比较小,从而无法到达local
minima的位置

📌因此,对于参数的不同位置我们需要设置不同的学习率。当gradient梯度较大时,将学习率设置较小。当gradint梯度较小时,将学习率设置较大
此时gradient优化器公式为:
w i + 1 = w i − η σ i t g i t w_{i+1}=w_i-\frac{\eta}{\sigma^t_i}g^t_i wi+1=wi−σitηgit
RMS
RMS即root mean square 此时的sigma规律如下:
当error surface某点附件的gradient梯度偏大时,sigma值偏大导致
eta/sigma偏小从而实现小程度的参数更新;当error surface某点附件的gradient梯度偏小时,sigma值偏小导致
eta/sigma偏大从而实现大程度的参数更新、但RMS仍存在一些问题:它是等可能的参照过去现在所有的gradient,但是在实现的过程中我们需要对目前的gradient置以更高或更低的参与可能,从而有了RMSProp

RMSProp
RMSProp在RMS的基础上将sigma定义如下:(引入了新的超参数alpha)

Adam
目前最常用的优化器,是结合RMSProp和Momentum动量的gradient。其内部实现如下:

学习率还和时间有关
Learin Rate Decay
随时间的进行,训练的越来越接近local minima,故让学习率eta逐渐减小,不要出现下图的在local minima处的震荡:


Warm up
随时间的进行,学习率eta先增大至最高再逐渐减小,此时超参数还包括何时升至最高值及最高值多少和下降到哪个最低值
(大概解释:一般刚开始时我们过去的gradient较少,因此此时最后的学习率/sigma不是很精准,所以我们设置较小的学习率eta,不要让参数偏太多。随着时间慢慢进行,过去的gradient比较丰富,此时可以设置较大的eta之后再按照Learing
Rate Decay进行)