目录
思维导图:
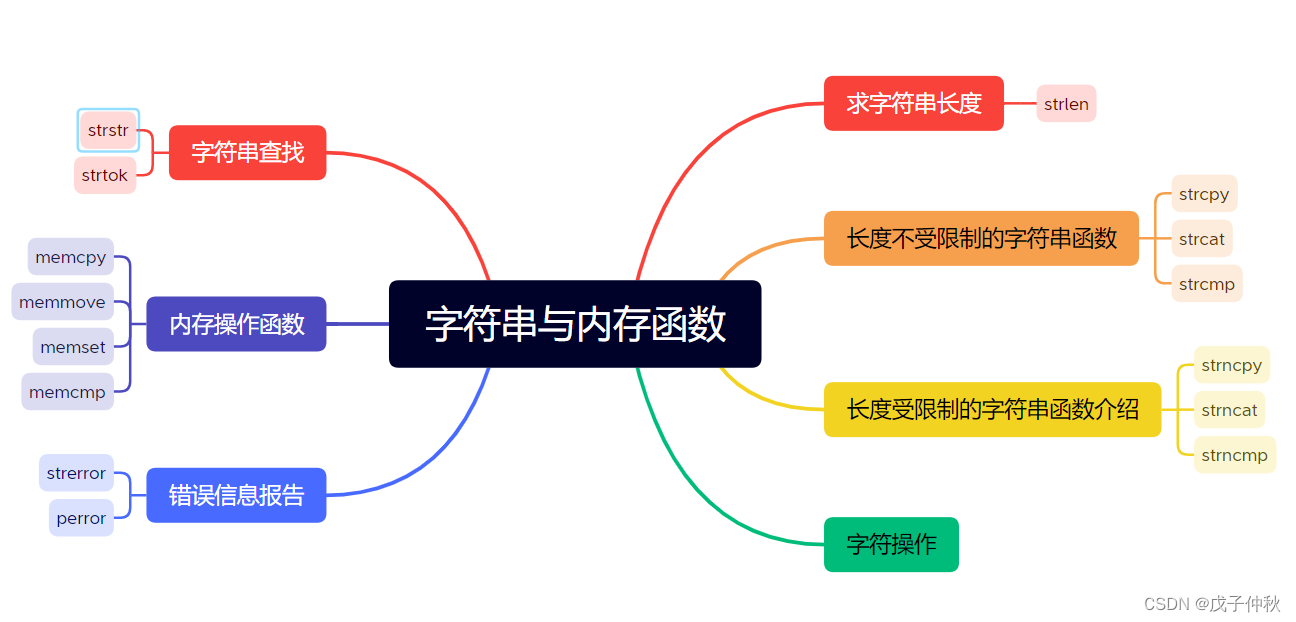
字符串与内存函数
求字符串长度
strlen
长度不受限制的字符串函数
strcpy
strcat
strcmp
长度受限制的字符串函数介绍
strncpy
strncat
strncmp
字符串查找
strstr
strtok
错误信息报告
strerror
perror
字符操作
内存操作函数
memcpy
memmove
memset
memcmp
写在最后:
思维导图:
字符串与内存函数
求字符串长度
strlen
size_t strlen ( const char * str )
其实我们对于strlen函数并不陌生,
他能通过字符串首地址求出字符串长度。
既然如此,我们来挑战一下,用三种不同的方法实现strlen函数:
第一种:循环
#include <stdio.h>
#include <string.h>
#include <assert.h>
//size_t strlen(const char * str)
size_t my_strlen(const char* str)
{
assert(str);
int count = 0;//计数
while (*str)//遍历数组
{
str++;
count++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}输出:
输出:6第二种:递归
#include <stdio.h>
#include <string.h>
#include <assert.h>
//size_t strlen(const char * str)
size_t my_strlen(const char* str)
{
assert(str);
if (*str != '\0')
return 1 + my_strlen(str + 1);
else
return 0;
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}输出:
输出:6第三种:指针减指针
#include <stdio.h>
#include <string.h>
#include <assert.h>
//size_t strlen(const char * str)
size_t my_strlen(const char* str)
{
assert(str);
const char* start = str;
while (*str)
{
str++;
}
return str - start;//指针之间隔着一整个数组
//数组在内存中是连续存储的,start与str之间相差6个字节
}
int main()
{
char arr[] = "abcdef";
int len = my_strlen(arr);
printf("%d\n", len);
return 0;
}输出:
输出:6怎么样,学会了吗?
长度不受限制的字符串函数
strcpy
char* strcpy(char * destination, const char * source )
strcpy是字符串拷贝函数,可以拷贝字符串
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "welcome to my blog";
char arr2[30] = { 0 };
strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}输出:
输出:welcome to my blog注:
1.源字符串必须以 '\0' 结束,
2.该函数会将源字符串中的 '\0' 拷贝到目标空间,
3.目标空间必须足够大,以确保能存放源字符串。
接下来我们可以模拟实现一下strcpy函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
//char* strcpy(char* destination, const char* source)
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);
char* ret = dest;
while (*dest++ = *src++)
{
;
}
return ret;//返回的是目标字符串的首字符地址
}
int main()
{
char arr1[] = "welcome to my blog";
char arr2[30] = { 0 };
my_strcpy(arr2, arr1);
printf("%s\n", arr2);
return 0;
}输出:
输出:welcome to my blogstrcat
char * strcat ( char * destination, const char * source )
strcat是个字符串追加函数,可以追加字符串。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[30] = "welcome to";
char arr2[] = " my ";
strcat(arr1, arr2);
strcat(arr1, "blog");
printf("%s\n", arr1);
return 0;
}输出:
输出:welcome to my blog注:
1.源字符串必须以 '\0' 结束,
2.目标空间必须有足够的大,能容纳下源字符串的内容,
3.目标空间必须可修改。
接下来我们可以模拟实现一下strcat函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
//char* strcat(char* destination, const char* source)
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);
const char* ret = dest;
while (*dest)//指针到'\0'停下
{
dest++;
}
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[30] = "welcome to";
char arr2[] = " my ";
my_strcat(arr1, arr2);
my_strcat(arr1, "blog");
printf("%s\n", arr1);
return 0;
}输出:
输出:welcome to my blogstrcmp
int strcmp ( const char * str1, const char * str2 )
strcmp是字符串比较函数,可以用来进行字符串之间的比较。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcd";
char arr2[] = "abcz";
int ret = strcmp(arr1, arr2);//按照字典序来排
if (ret > 0)
printf("arr1>arr2\n");
else if (ret == 0)
printf("arr1=arr2\n");
else
printf("arr1<arr2\n");
return 0;
}输出:
输出:arr1<arr2注:
1.第一个字符串大于第二个字符串,则返回大于0的数字,
2.第一个字符串等于第二个字符串,则返回0,
3.第一个字符串小于第二个字符串,则返回小于0的数字。
接下来我们可以模拟实现一下strcmp函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
int my_strcmp(const char* src, const char* dest)
{
int ret = 0;
assert(src &&dest);
while (!(ret = *(unsigned char*)src++ - *(unsigned char*)dest++) && *dest && *src)
{ //!ret如果ret!=0则跳出循环,ret=0则继续,*dest=0和*src=0也跳出循环
;
}
if (ret < 0)
ret = -1;
else if (ret > 0)
ret = 1;
return ret;
}
int main()
{
char arr1[] = "abcd";
char arr2[] = "abcz";
int ret = my_strcmp(arr1, arr2);//按照字典序来排
if (ret > 0)
printf("arr1>arr2\n");
else if (ret == 0)
printf("arr1=arr2\n");
else
printf("arr1<arr2\n");
return 0;
}输出:
输出:arr1<arr2以上就是长度不受限制的字符串函数。
长度受限制的字符串函数介绍
strncpy
char * strncpy ( char * destination, const char * source, size_t num )
strncpy可以控制拷贝过去的字符串的字符个数。
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[20] = "xxxxxxxxxxxxx";
char arr2[] = "hello";
strncpy(arr1, arr2, 3);
printf("%s\n", arr1);
strncpy(arr1, arr2, 6);//\0也会被拷贝过去
printf("%s\n", arr1);
return 0;
}输出:
输出:
helxxxxxxxxxx
hello他的实现方式与strcpy自然也是大同小异。
例:
#include <assert.h>
#include <stdio.h>
#include <string.h>
//char* strncpy(char* destination, const char* source, size_t num)
char* my_strncpy(char* dest, const char* src, size_t num)
{
assert(dest && src);
char* ret = dest;
for (int i = 0; i < num; i++)
{
*dest++ = *src++;
}
return ret;//返回的是目标字符串的首字符地址
}
int main()
{
char arr1[20] = "xxxxxxxxxxxxx";
char arr2[] = "hello";
my_strncpy(arr1, arr2, 3);
printf("%s\n", arr1);
my_strncpy(arr1, arr2, 6);//\0也会被拷贝过去
printf("%s\n", arr1);
return 0;
}输出:
输出:
helxxxxxxxxxx
hellostrncat
char * strncat ( char * destination, const char * source, size_t num )
strncat可以控制追加字符的数量。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[30] = "welcome to";
char arr2[] = " my ";
strncat(arr1, arr2, 2);
strncat(arr1, "blog", 2);
printf("%s\n", arr1);
return 0;
}输出:
输出:welcome to mbl我们也能将它模拟实现一下:
#include <assert.h>
#include <stdio.h>
#include <string.h>
//char* strncat(char* destination, const char* source, size_t num)
char* my_strncat(char* dest, const char* src, size_t num)
{
assert(dest && src);
const char* ret = dest;
while (*dest)//指针到'\0'停下
{
dest++;
}
for (int i = 0; i < num; i++)
{
*dest++ = *src++;
}
return ret;
}
int main()
{
char arr1[30] = "welcome to";
char arr2[] = " my ";
my_strncat(arr1, arr2, 2);
my_strncat(arr1, "blog", 2);
printf("%s\n", arr1);
return 0;
}输出:
输出:welcome to mblstrncmp
int strncmp ( const char * str1, const char * str2, size_t num )
strncmp可以控制比较的字符串的字符数。
例:
#include <stdio.h>
#include <string.h>
void print(int ret)
{
if (ret > 0)
printf("arr1>arr2\n");
else if (ret == 0)
printf("arr1=arr2\n");
else
printf("arr1<arr2\n");
}
int main()
{
char arr1[] = "abcd";
char arr2[] = "abcz";
int ret = strncmp(arr1, arr2, 3);
print(ret);
ret = strncmp(arr1, arr2, 4);
print(ret);
return 0;
}输出:
输出:
arr1=arr2
arr1<arr2字符串查找
strstr
strstr函数可以查找字符串中的字符,并返回他们的地址。
如果找不到对应字符或字符串,就返回空指针。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "welcome to my blog";
char* p = strstr(arr, "my");
printf("%s\n", p);
return 0;
}输出:
输出:my blog例2:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abbbcdbbcef";
char arr2[] = "bbcb";
char* ret = strstr(arr1, arr2);
if (ret == NULL)
{
printf("找不到\n");
}
else
{
printf("%s\n", ret);
}
return 0;
}输出:
输出:找不到接下来我们可以模拟实现一下strstr函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
//char* strstr(const char* str1, const char* str2)
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
if (*str2 == '\0')
{
return (char*)str1;
}
const char* s1 = NULL;
const char* s2 = NULL;//初始化指针
const char* cp = str1;//cp指针的作用是作为遍历字符串str1的起始地址
while (*cp)//如果*cp已经等于'\0'了就证明查找失败了,不再进入循环
{
s1 = cp;//如果没找到,s1指针返回cp地址,也就是遍历开始的地址
s2 = str2;//而s2指针返回str2的地址,重新对应查找
while (*s1 != '\0' && *s2 != '\0' && *s1 == *s2)//匹配
{
s1++;
s2++;
}
if (*s2 == '\0')
{
return (char*)cp;
}
cp++;//没找到,遍历的地址向前一个字节
}
return NULL;
}
int main()
{
char arr1[] = "abbbcdbbcef";
char arr2[] = "bbc";
char* ret = my_strstr(arr1, arr2);
if (ret == NULL)
{
printf("找不到\n");
}
else
{
printf("%s\n", ret);
}
return 0;
}输出:
输出:bbcdbbcefstrtok
char * strtok ( char * str, const char * sep )
strtok函数可以通过分隔符sep分割字符串,并标记
如果之后传空指针,也能通过标记继续分割字符串。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "asdf@hjkl.qwer";
char* p = "@.";
char buf[20] = { 0 };
strcpy(buf, arr);
char* pa = strtok(buf, p);
printf("%s\n", pa);
pa = strtok(NULL, p);//传空指针
printf("%s\n", pa);
pa = strtok(NULL, p);
printf("%s\n", pa);
return 0;
}输出:
输出:
asdf
hjkl
qwer但是,我们发现,想上面那样写的话,
代码有一点冗余了,该怎么解决呢?
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "asdf@hjkl.qwer";
char* p = "@.";
char buf[20] = { 0 };
strcpy(buf, arr);
char* ret = NULL;
for (ret = strtok(buf, p); ret != NULL; ret = strtok(NULL, p))
{
printf("%s\n", ret);
}
return 0;
}输出:
输出:
asdf
hjkl
qwer写成循环的形式就好多啦。
错误信息报告
strerror
C语言的库函数在运行的时候,如果发生错误,
就会将错误码存在一个变量中,这个变量是:errno。
而strerror 函数能将错误码翻译成错误信息。
例:
#include <stdio.h>
#include <string.h>
int main()
{
//错误码是一些数字:1 2 3 4 5 ,他们都有不同的含义
printf("%s\n", strerror(0));
printf("%s\n", strerror(1));
printf("%s\n", strerror(2));
printf("%s\n", strerror(3));
printf("%s\n", strerror(4));
printf("%s\n", strerror(5));
return 0;
}输出:
输出:
No error
Operation not permitted
No such file or directory
No such process
Interrupted function call
Input/output error
perror
但在平时,perror用的也很多,
举个例子:
#include <stdio.h>
#include <string.h>
#include <errno.h>//这个是errno的头文件
int main()
{
//打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
printf("%s\n", strerror(errno));//实际上我们并没有这个文件,就能通过strerror报错
return 1;
}
//读文件
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}输出:
输出:No such file or directory但是使用perror 函数会更方便和灵活。
#include <assert.h>
#include <stdio.h>
#include <string.h>
int main()
{
//打开文件
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
//关闭文件
fclose(pf);
pf = NULL;
return 0;
}输出:
输出:fopen: No such file or directory字符操作
字符分类函数:
| 函数 | 如果他的参数符合下列条件就返回真 |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v' |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A~F |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母a~z或A~Z |
| isalnum | 字母或者数字,a~z,A~Z,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
例:
#include <stdio.h>
#include <ctype.h>
int main()
{
int ret = isdigit('Q');//参数是十进制数字 0~9返回真,否则返回假
printf("%d\n", ret);
return 0;
}输出:
输出:0还有一些字符操作函数:
例:
#include <stdio.h>
#include <ctype.h>
int main()
{
printf("%c\n", toupper('a'));//转成大写
printf("%c\n", tolower('A'));//转成小写
return 0;
}输出:
输出:
A
a内存操作函数
memcpy
void * memcpy ( void * destination, const void * source, size_t num )
memcpy是内存拷贝函数:
1.函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
2.这个函数在遇到 '\0' 的时候并不会停下来。
3.如果source和destination有任何的重叠,复制的结果都是未定义的(会出问题)。
例:
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = { 0 };
memcpy(arr2, arr1 + 2, 17);//17个字节
int sz = sizeof(arr2) / sizeof(arr2[0]);
print(arr2, sz);
}
输出:
输出;3 4 5 6 7 0 0 0 0 0接下来我们可以模拟实现一下memcpy函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
//void* memcpy(void* destination, const void* source, size_t num)
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;//记住起始地址
while (num--)
{
*(char*)dest = *(char*)src;//一个字节一个字节的拷贝
++(char*)dest;
++(char*)src;
}
return ret;
}
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = { 0 };
my_memcpy(arr2, arr1 + 2, 17);//17个字节
int sz = sizeof(arr2) / sizeof(arr2[0]);
print(arr2, sz);
}输出:
输出:3 4 5 6 7 0 0 0 0 0memmove
void * memmove ( void * destination, const void * source, size_t num )
memmove函数的功能与memcpy的功能类似,但也有差别:
1.和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
2.如果源空间和目标空间出现重叠,就得使用memmove函数处理
例:
如果使用memcpy,拷贝的结果就会出问题:
#include <assert.h>
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
//void* memcpy(void* destination, const void* source, size_t num)
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;//记住起始地址
while (num--)
{
*(char*)dest = *(char*)src;//一个字节一个字节的拷贝
++(char*)dest;
++(char*)src;
}
return ret;
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memcpy(arr1 + 2, arr1, 17);//17个字节
int sz = sizeof(arr1) / sizeof(arr1[0]);
print(arr1, sz);
}
输出:
输出:1 2 1 2 1 2 1 8 9 10我们想要的结果是:1 2 1 2 3 4 5 8 9 10
(注:在VS2019的环境下,memcpy的库函数实现已经和memmove一样了)
那就得使用memmove函数:
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr1 + 2, arr1, 17);//17个字节
int sz = sizeof(arr1) / sizeof(arr1[0]);
print(arr1, sz);
}输出:
输出:1 2 1 2 3 4 5 8 9 10这样就成功得到我们想要的值了。
接下来我们可以模拟实现一下memmove函数:
#include <assert.h>
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
//void* memmove(void* destination, const void* source, size_t num)
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
if (dest < src)//通过判断避免数组内容覆盖导致的错误
{
//从前往后拷贝数组内容
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else
{
//从后往前拷贝数组内容
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
}
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr1 + 2, arr1, 17);//17个字节
int sz = sizeof(arr1) / sizeof(arr1[0]);
print(arr1, sz);
}输出:
输出:1 2 1 2 3 4 5 8 9 10memset
void * memset ( void * ptr, int value, size_t num )
memset是内存定义函数,我们一般用它来进行初始化操作。
例:
#include <stdio.h>
#include <string.h>
void print(int* arr, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };
memset(arr1, 0, sizeof(arr1));//设置成0
char arr2[20] = "hello world";
memset(arr2, 'x', 5);//把五个字节的内容设置成‘x’
int sz = sizeof(arr1) / sizeof(arr1[0]);
print(arr1, sz);
printf("%s\n", arr2);
}输出:
输出:
0 0 0 0 0 0 0 0 0 0
xxxxx worldmemcmp
int memcmp ( const void * ptr1,const void * ptr2,size_t num )
memcmp函数能比较从ptr1和ptr2指针开始的num个字节,
ptr1 > ptr2 返回 >0 的数,
ptr1 < ptr2 返回 <0 的数,
ptr1 = ptr2 返回 =0 的数。
例:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "abcd";
char arr2[] = "abcz";
int ret = memcmp(arr1, arr2, 4);//比较四个字节的内容
if (ret > 0)
printf("arr1>arr2\n");
else if (ret == 0)
printf("arr1=arr2\n");
else
printf("arr1<arr2\n");
return 0;
}输出:
输出:arr1<arr2写在最后:
以上就是本篇文章的内容了,感谢你的阅读。
如果喜欢本文的话,欢迎点赞和评论,写下你的见解。
如果想和我一起学习编程,不妨点个关注,我们一起学习,一同成长。
之后我还会输出更多高质量内容,欢迎收看。