常见容器性质总结
1.vector 底层数据结构为数组 ,支持快速随机访问
2.list 底层数据结构为双向链表,支持快速增删
3.deque 底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间
不能)快速增删,也支持随机访问
deque是一个双端队列(double-ended queue),也是在堆中保存内容的.它的保存形式如下:
[堆1] --> [堆2] -->[堆3] --> …
每个堆保存好几个元素,然后堆和堆之间有指针指向,看起来像是list和vector的结合品.
4.stack 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容
耗时
5.queue 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩
容耗时(stack和queue其实是适配器,而不叫容器,因为是对容器的再封装)
6.priority_queue 的底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现
7.set 底层数据结构为红黑树,有序,不重复
8.multiset 底层数据结构为红黑树,有序,可重复
9.map 底层数据结构为红黑树,有序,不重复
10.multimap 底层数据结构为红黑树,有序,可重复
11.unordered_set 底层数据结构为hash表,无序,不重复
12.unordered_multiset 底层数据结构为hash表,无序,可重复
13.unordered_map 底层数据结构为hash表,无序,不重复
14.unordered_multimap 底层数据结构为hash表,无序,可重复
每种容器对应的迭代器
| 容器 | 迭代器 |
|---|---|
| vector、deque | 随机访问迭代器 |
| stack、queue、priority_queue | 无 |
| list、(multi)set/map | 双向迭代器 |
| unordered_(multi)set/map、forward_list | 前向迭代器 |
vector
vector数据结构
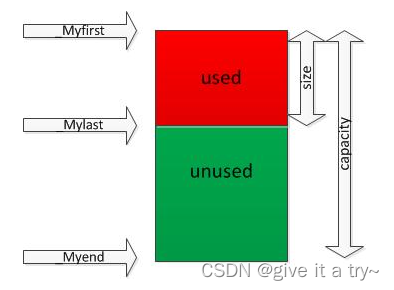
vector和数组类似,拥有一段连续的内存空间,并且起始地址不变。因此能高效的进行随机存取,时间复杂度为o(1);但因为内存空间是连续的,所以在进行插入和删除操作时,会造成内存块的拷贝,时间复杂度为o(n)。另外,当数组中内存空间不够时,会重新申请一块内存空间并进行内存拷贝。连续存储结构:vector是可以实现动态增长的对象数组,支持对数组高效率的访问和在数组尾端的删除和插入操作,在中间和头部删除和插入相对不易,需要挪动大量的数据。它与数组最大的区别就是vector不需程序员自己去考虑容量问题,库里面本身已经实现了容量的动态增长,而数组需要程序员手动写入扩容函数进形扩容。vector中有三个指针first,last,end, 分别指向了数组的开头, 数组的结尾+1以及数组的最大容量结尾
vector扩容
● 可以使用reserve(n)预先分配一块较大的指定大小的内存空间,这样当指定大小的内存空间未使用完时,是不会重新分配内存空间的,这样便提升了效率。只有当n>capacity()时,调用reserve(n)才会改变vector容量。
● resize()成员函数只改变元素的数目,不改变vector的容量。
● vector以连续的数组存放数据,当vector空间已满时会申请新的空间并将原容器中的内容拷贝到新空间中,并销毁原容器
● 存储空间的重新分配会导致迭代器失效
● 因为分配空间后需要进行拷贝,编译器会预分配更多空间以减少发生拷贝影响程序效率
● 扩容的大小叫做扩容因子,扩容因子由编译器决定,VS的扩容因子为1.5,G++中,扩容因子为2
为什么是2倍扩容
理由一:
倍数方式空间拷贝数据次数
假设总共有n个元素,以m倍的形式增长。(比如现在举例n=100, m=2),所以,vector的push_back的操作次数可以是logmN,也就是log2(100),换算下来大概是需要进行7次扩容。这样的话,相当于旧空间数据到原空间数据的拷贝有7次。
个数方式空间拷贝数据次数
和倍数方式假设相同,n=100;这次m代表的是每次新空间的大小位n+m;m为新空间新增大小,比如这次m为10(每次新增10个空间)。所以这次的扩容次数为 100/10 = 10次,也就是说,插入100白个元素,需要扩容10次。
但是,如果n=1000的情况下, 以个数形式进行扩容就不能在为10了,否则拷贝空间次数将会太多
有的小伙伴要问:但是可以取100呀,想想,如果n=10的情况下,取100又不太合适,所以,以个数的形式来进行扩容显然不符合所用n的取值。
所以在STL中vector以倍数的形式进行扩容
理由二:
如果以大于2倍的方式来进行扩容,下一次申请空间会大于之前申请所有空间的总和,这样会导致之前的空间不能再被重复利用,这样是很浪费空间的操作。所以,如果扩容一般基于(1, 2] 之间进行扩容
vector缩容
首先vector删除元素时会不会释放空间,erase()函数,只能删除内容,不能改变容量大小;
由于vector的内存占用空间只增不减,比如你首先分配了10,000个字节,然后erase掉后面9,999个,留
下一个有效元素,但是内存占用仍为10,000个。所有内存空间是在vector析构时候才能被系统回收。
empty()用来检测容器是否为空的,clear()可以清空所有元素。但是即使clear(),vector所占用的内存空
间依然如故,无法保证内存的回收。
如果需要空间动态缩小,可以考虑使用deque。如果vector,可以用swap()来帮助你释放内存
vector(Vec).swap(Vec); 将Vec的内存空洞清除;
vector().swap(Vec); 清空Vec的内存;
std::vector<T> tmp(v);
tmp.swap(v);
vector<int>(v).swap(v); //关键的内存收缩语句
vector与list中sort的区别
vector中内存是连续分配的,而list是基于双向链表的。所以sort的时候,vector的sort是基于快排的,而list的sort是基于归并排序的
vector中下标越界访问
通过下标访问vector中的元素时不会做边界检查,即便下标越界。
也就是说,下标与first迭代器相加的结果超过了finish迭代器的位置,程序也不会报错,而是返回这个地
址中存储的值。
如果想在访问vector中的元素时首先进行边界检查,可以使用vector中的at函数。通过使用at函数不但
可以通过下标访问vector中的元素,而且在at函数内部会对下标进行边界检查。
push_back和emplace_back的区别
使用push_back()函数需要调用拷贝构造函数和转移构造
函数,而使用emplace_back()插入的元素原地构造,不需要触发拷贝构造和转移构造
list
- list不再能够像vector一样以普通指针作为迭代器,因为其节点不保证在存储空间中连续存在;
- list插入操作和结合才做都不会造成原有的list迭代器失效;
- list不仅是一个双向链表,而且还是一个环状双向链表,所以它只需要一个指针;
- list不像vector那样有可能在空间不足时做重新配置、数据移动的操作,所以插入前的所有迭代器在插
入操作之后都仍然有效; - deque是一种双向开口的连续线性空间,所谓双向开口,意思是可以在头尾两端分别做元素的插入和
删除操作;可以在头尾两端分别做元素的插入和删除操作; - deque和vector最大的差异,一在于deque允许常数时间内对起头端进行元素的插入或移除操作,二
在于deque没有所谓容量概念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间
并链接起来,deque没有所谓的空间保留功能
map,set
他们的底层都是以红黑树的结构实现,因此插入删除等操作都在O(logn)时间内完成,因此可以完成高
效的插入删除;
红黑树是怎么能够同时实现这两种容器
在这里我们定义了一个模版参数,如果它是key那么它就是set,如果它是map,那么它就是map;底
层是红黑树,实现map的红黑树的节点数据类型是key+value,而实现set的节点数据类型是value
为什么使用红黑树
因为map和set要求是自动排序的,红黑树能够实现这一功能,而且时间复杂度比较低
unordered_map(hash_map)和map的区别
- unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是
unordered_map不会根据key的大小进行排序, - 存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的,而map中的
元素是按照二叉搜索树存储,进行中序遍历会得到有序遍历。 - 所以使用时map的key需要定义operator<。而unordered_map需要定义hash_value函数并且重载
operator==。但是很多系统内置的数据类型都自带这些, - 那么如果是自定义类型,那么就需要自己重载operator<或者hash_value()了。
- 如果需要内部元素自动排序,使用map,不需要排序使用unordered_map
- unordered_map的底层实现是hash_table;
- hash_map底层使用的是hash_table,而hash_table使用的开链法进行冲突避免,所有hash_map采
用开链法进行冲突解决。 - 什么时候扩容:当向容器添加元素的时候,会判断当前容器的元素个数,如果大于等于阈值—即当前
数组的长度乘以加载因子的值的时候,就要自动扩容啦。 - 扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组
无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。
unordered_map内部是一个hash_table,是由一个大vector,vector的每个元素节点挂一个链表来实现的(就是开链法实现的哈希桶)
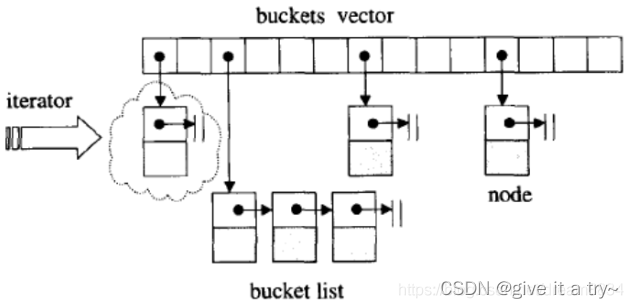
hashtable中的bucket所维护的list既不是list也不是slist,而是其自己定义的由hashtable_node数据结
构组成的linked-list,而bucket聚合体本身使用vector进行存储。hashtable的迭代器只提供前进操作,
不提供后退操作
在hashtable设计bucket的数量上,其内置了28个质数[53, 97, 193,…,429496729],在创建hashtable
时,会根据存入的元素个数选择大于等于元素个数的质数作为hashtable的容量(vector的长度),其中
每个bucket所维护的linked-list长度也等于hashtable的容量。如果插入hashtable的元素个数超过了
bucket的容量,就要进行重建table操作,即找出下一个质数,创建新的buckets vector,重新计算元素
在新hashtable的位置。
map越界访问
map的下标运算符[]的作用是:将key作为下标去执行查找,并返回相应的值;如果不存在这个key,
就将一个具有该key和value的某人值插入这个map。
map中[]与find的区别?
- map的下标运算符[]的作用是:将关键码作为下标去执行查找,并返回对应的值;如果不存在这个关
键码,就将一个具有该关键码和值类型的默认值的项插入这个map。 - map的find函数:用关键码执行查找,找到了返回该位置的迭代器;如果不存在这个关键码,就返回
尾迭代器。
哈希冲突解决方案
记住前三个:
线性探测
使用hash函数计算出的位置如果已经有元素占用了,则向后依次寻找,找到表尾则回到表头,直到找到
一个空位
开链
每个表格维护一个list,如果hash函数计算出的格子相同,则按顺序存在这个list中
再散列
发生冲突时使用另一种hash函数再计算一个地址,直到不冲突
二次探测
使用hash函数计算出的位置如果已经有元素占用了,按照
1
2
1^2
12、
2
2
2^2
22、
3
2
3^2
32…的步长依次寻找,如
果步长是随机数序列,则称之为伪随机探测
公共溢出区
一旦hash函数计算的结果相同,就放入公共溢出区