目录
一、概述
二、赛题及解读
1.赛题详情
2.赛题解读
三、解题方法
1.第一问
第一问部分代码
2.第二问
第二问部分代码
3.第三问:
第三问部分代码
4.第四问
三、总结
一、概述
这次比赛是我们队伍第一次参加金融数学建模,尽管在比赛前用2020年大湾区杯A题做过相关练习,但是对于金融数学类的建模题型我们在做的时候还是有些吃力。不过幸运的是,通过7天的努力,我们还是将四题全部完成,上个月官方已经公开了比赛结果,我们队拿了三等,对于我个人来说,已经是很好的结果了(因为原本对于拿奖并不抱希望 hhhhh)。
那么就让我们来看看这四题吧 :)
二、赛题及解读
1.赛题详情
本次比赛的B题难度并不算高,总赛题为《基于宏观经济周期的大类资产配置策略构建》。
共有四题,详情如下图所示:

另外出题方也给出了解题所需的相关数据集,数据集文件大致如下:
(附件1:宏观经济指标数据(1、2问))

(附件2:大类资产指数行情数据(3、4问))

2.赛题解读
如题可将四题分为三部分:
第一部分为针对宏观经济数据的分析归类及未来经济状况预测(第1、2问)。
第二部分为根据所给出的相关可以进行投资的大类资产指数数据进行相关性分析(第3问)。
第三部分是第一部分与第二部分的结合应用,应用第一部分中所得出的未来5年中国宏观经济状况结论以及第二部分中对于大类资产指数数据相关性的分析结果运用美林时钟框架判断需要如何组合大类资产进行投资。
其中需要注意的是,出题方所给出的数据并不是需要全部使用的,而是应该根据个人所使用的数学建模方法进行筛选再使用。
三、解题方法
1.第一问
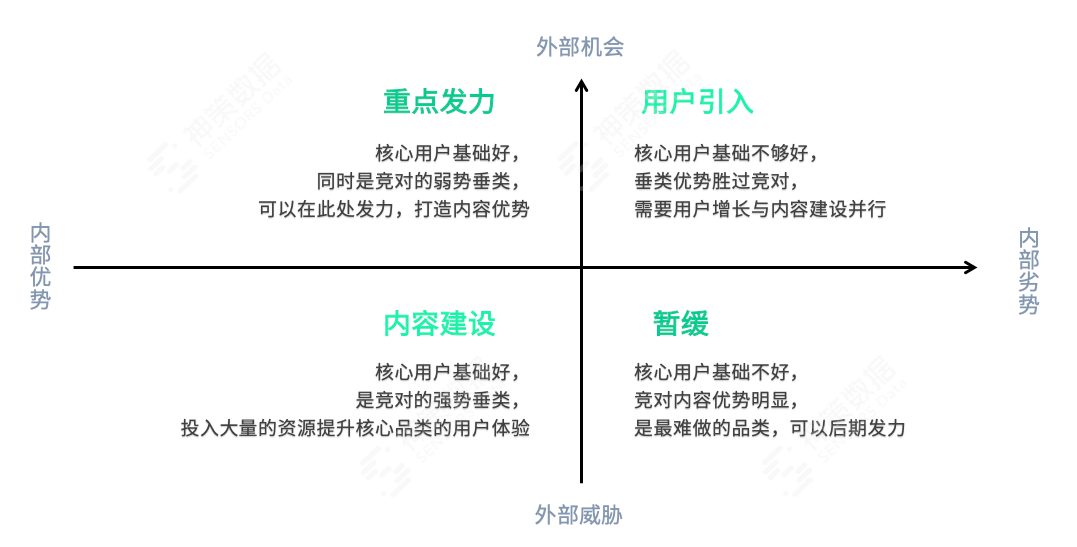
题目分析:针对第 1 问,首先确定时间限制范围为 2001 年~2021 年这二十年间,从宏观经济指标数据中选出国民经济核算中的国内生产总值 GDP 与银行与货币中的货币供应量 M2 指数来作为划分经济状态的指标,计算 GDP 增长率和通胀率,通过美林时钟框架划分的四个经济状态可以运用以上两个指标来衡量。

(图:美林时钟框架理论)
应用数据及算法公式:基于附件 1 中的国内生产总值 GDP、M2(广义货币供应量)、实际通货膨胀率(年)等现成数据计算出国内生产总值 GDP 的增长率、货币供应量 M2 指数的增长率。由于题目限制条件,仅选取 2001 年~2021 年二十年间的宏观经济运行状况相关数据作为划分指标。


又有GDP 增长率大于 10% 即判断为高增长,反之则 为低增长;通胀率大于 6% 即判断为高通胀,反之则为低通胀。
所以计算后我们可以得到GDP 增长率和通胀率,通过这两个指标,我们写一个python程序将过去20年按照美林时钟框架进行分类,结果如下图所示:
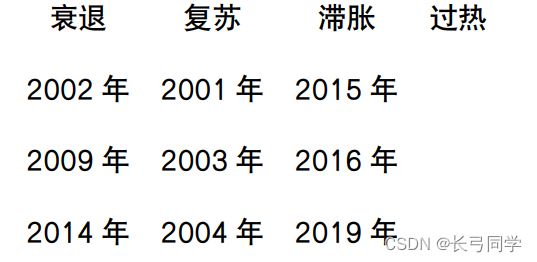
由所有年份分类后结果总结来看,2001 年~2021 年间处于衰退阶段的年份有:2002 年、2009 年、2014 年、2017 年;处于复苏阶段的年份有:2001 年、2003 年、2004 年、2005 年、 2006 年、2007 年、2008 年、2010 年、2011 年、2012 年、2013 年、2018 年、2021 年; 处于滞涨阶段的年份有:2015 年、2016 年、2019 年、2020 年;没有处于过热阶段的年份。
第一问部分代码:
def classify(GDP,CPI):
data1 = pd.DataFrame(GDP)
data2 = pd.DataFrame(CPI)
#print(data1.iloc[0,0])
GDP_speed_up = []
M_tongbi = []
tongzhanglv = []
drop = []
recover = []
overheat = []
stagflation =[]
for i in range(21):
then_year = data1.iloc[i+1,1]
ago_year = data1.iloc[i,1]
zhengzhang = ((then_year - ago_year)/ago_year)*100
GDP_speed_up.append(zhengzhang)
for j in range(11,253,12):
M_tb = data2.iloc[j,6]
M_tongbi.append(M_tb)
for k in GDP_speed_up:
for z in M_tongbi:
tongzhang = z - k
tongzhanglv.append(tongzhang)
break
print(GDP_speed_up)
print(tongzhanglv)
year = [2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015,2016,2017,2018,2019,2020,2021]
for a in range(0,len(GDP_speed_up)):
if (GDP_speed_up[a]<15 and tongzhanglv[a]<6):
drop.append(year[a])
elif (GDP_speed_up[a]>15 and tongzhanglv[a]<6):
recover.append(year[a])
elif (GDP_speed_up[a]>15 and tongzhanglv[a]>6):
overheat.append(year[a])
else :
stagflation.append(year[a])
return drop,recover,overheat,stagflation
def divide(drop_1,recover_1,overhead_1,staflation_1):
index = pd.date_range('2001','2021')
print(index)
2.第二问
题目分析:根据第 1 问计算出来的 GDP 增长率,加以使用居民消费价格指数 CPI 计算货币商品的通胀率、活期存款利率(月)计算利率来模拟预测中国未来五年的宏观经济发展状况,运用 LSTM 算法进行以年为一个时间切片的时间序列滑窗预测未来五年的经济增长、通胀和利率。
由于第二问要求我们预测未来数据,所以我们需要采用LSTM算法进行建模,与CNN等机器学习方法相似,我们需要进行数据预处理、模型训练、数据预测这三步来构建我们的数学模型并编写代码。
数据预处理:由于这些数据都是时间序列数据,故需要统一其时间戳,通过观察发现所有数据从 1988 年开始往后数据趋于稳定(无缺失值),故选取 1988 年~2021 年的数据。另外, 由于 GDP 及通胀率是每年 12 月的数据,故我们将 M2 货币供应量数据与人民币活期存 款利率进行切片,提取其每年 12 月的数据,以达到时间上的统一。 将 Dataframe 存为二维数组,然后进行对此差分转换,将时间序列形式数据转换为 监督学习集,同时将数据集分为训练集和测试集,使用 MinMaxScaler 将数据缩放到[-1,1] 之间加快收敛。
模型训练(方法选取):需要采用具有记忆性的算法来进行模型的训练,RNN(Recurrent Neural Network, RNN)可实现有序数据的模型训练,但是使 用其进行模型训练,会出现梯度消失问题,故只能实现短期的记忆,为了解决这一问题, 我们采用 RNN 的衍生算法 LSTM(Long Short Term, LSTM),该算法可以学习长期依赖信息,对于解决我们的目标问题非常合适。
预测:在预测方面,我们采用滑动窗口预测。
运算结果:
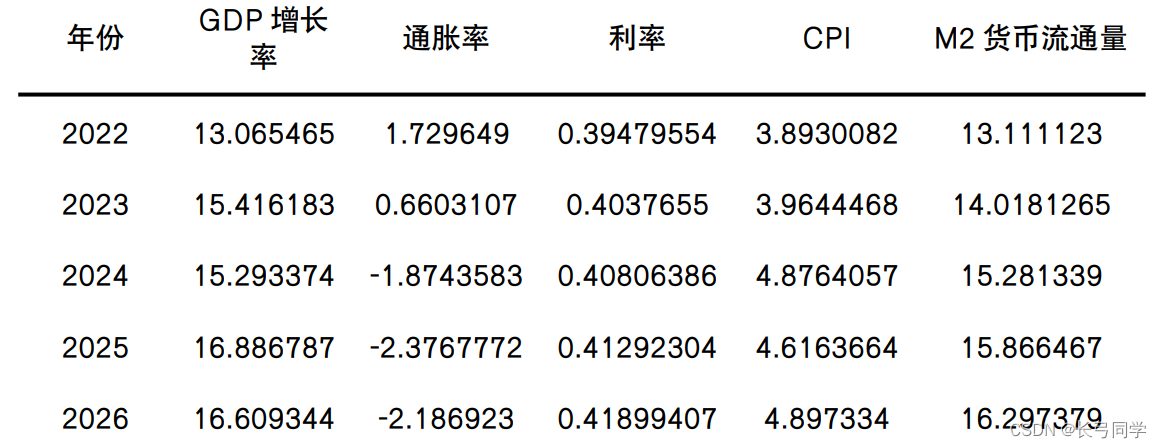
根据计算出来的结果结合美林时钟可知:中国未来五年的经济增长处于高增长,而通胀与利率处于低通胀、低通胀的状况,因此,判断未来五年中国处于复苏阶段。
第二问部分代码:
#设置随机种子
numpy.random.seed(7)
df = pd.read_excel('./data/GDP_TZ.xlsx')
df.drop(['tongzhanglv'],axis=1,inplace=True)
df['Date']=pd.to_datetime(df['Date'],format='%Y')
# print(data.head())
df = df.set_index(['Date'], drop=True)
dataframe = pd.DataFrame(df)
# print(dataframe)
dataset = dataframe.values
dataset = dataset.astype("float64")
# print(dataframe.head())
#
#异常值检测
fig = plt.figure(1,figsize=(9,6))
ax = fig.add_subplot(111)
bp = ax.boxplot(dataset)
# print(bp['fliers'][0].get_ydata())
# plt.show()
#需要将数据标准化到0-1
scaler = MinMaxScaler(feature_range=(0,1))
dataset = scaler.fit_transform(dataset)
#分割训练集与测试集
train_size = int(len(dataset)*0.75)
test_size = len(dataset)-train_size
# print(test_size)
train,test = dataset[0:train_size,:],dataset[train_size:len(dataset),:]
trainX,trainY = create_dataset(train,look_back)
testX,testY = create_dataset(test,look_back)
print(trainX)
print(trainY)
#创建一个LSTM模型
model = Sequential()
model.add(LSTM(4,input_shape=(1,look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error',optimizer='adam')
trainX= trainX.reshape(trainX.shape[0],1,trainX.shape[1])
# trainY= trainY.reshape(trainY.shape[0],1,trainY.shape[0])
model.fit(trainX,trainY,epochs=100,batch_size=3,verbose=2)3.第三问:
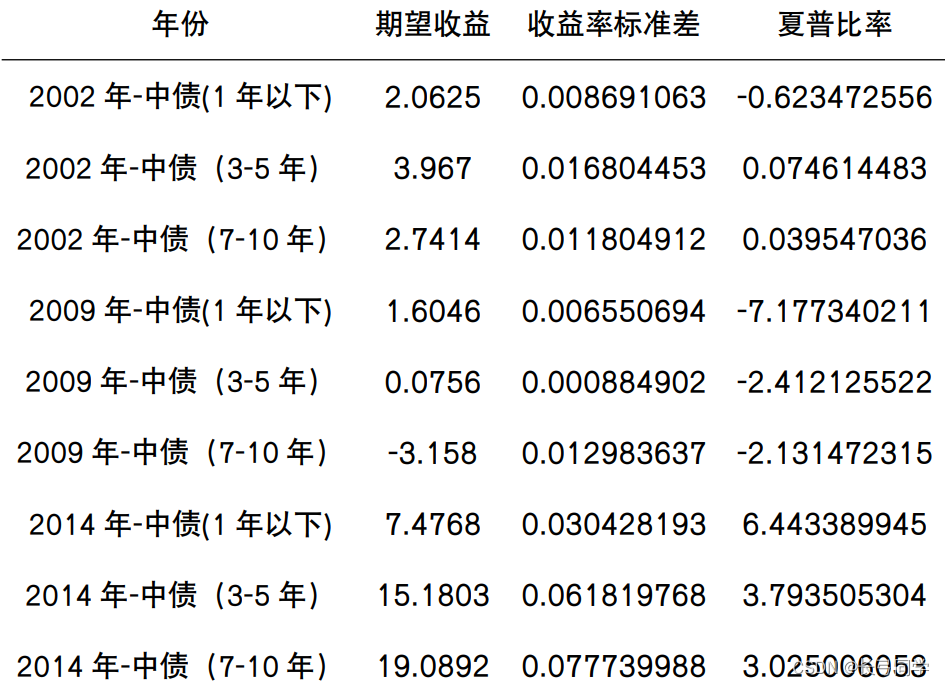
问题分析:需要用到第 1 问中根据美林时钟框架划分出来的四种经济状态划分条 件,计算附件 2 大类资产指数在各种经济状态下的风险收益特征(期望收益,收益率标准差,夏普比率)。运用 Pearson 系数计算各大类资产指数之间的相关性系数,并用热力图来表示各大类资产指数之间的显著性。
Pearson 系数:
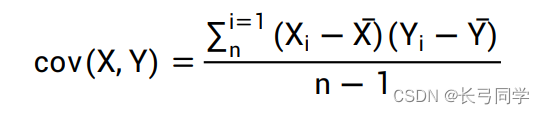
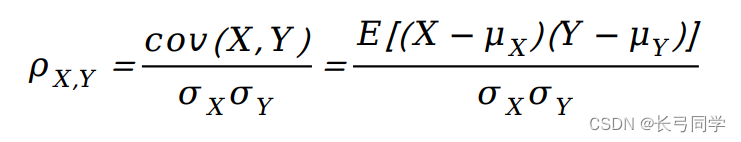
计算结果,并绘制热力图:
(eg.衰退经济状态下的风险收益特征)
(热力图)

计算得出中债-综合财富(3-5 年)与中债-综合 财富(7-10 年)的相关性系数最高,由计算结果可知,相同大类之间的大类资产指数相关性系数高于不同类别之间指数的相关性系数。
第三问部分代码:
def divide():
data1 = pd.read_excel(path3)
data_dalei = pd.DataFrame(data1)
data_dalei.set_index('time',inplace=True)
stats = ['stock1','stock2','stock3','stock4','goods1','goods2','bond1','bond2','bond3','cash1']
data_dalei.reindex(columns=stats)
return data_dalei
def drop(drop_1):
xiapu = []
expect_profit = []
biaozhun = []
data_dalei = divide()
for x1 in drop_1:
data_x_1 = []
for i in range(6,9):
data_dalei_drop_2 = data_dalei[str(x1)].iloc[:,i]
#计算期望收益
data_expect_profit = data_dalei_drop_2[-1]-data_dalei_drop_2[0]
#计算夏普比率:
for i1 in range(1,len(data_dalei_drop_2)):
data = ((data_dalei_drop_2[i1]-data_dalei_drop_2[i1-1])/data_dalei_drop_2[i1-1])*100
data_x_1.append(data)
data_x1 = pd.Series(data_x_1)
sharp = cal_sharp(data_x1,rf = 3)
#计算收益率标准差
#平均收益:avg
qiuhe = 0
x0 = 0
for k in range(1,len(data_dalei_drop_2)):
data2 = (data_dalei_drop_2[k]-data_dalei_drop_2[k-1])
qiuhe = qiuhe + data2
avg = qiuhe/(len(data_dalei_drop_2)-1)
#当天收益:then
for k1 in range(1,len(data_dalei_drop_2)):
data3 = (data_dalei_drop_2[k1]-data_dalei_drop_2[k1-1])
x = (data3-avg)**2
x0 = x0 + x
biaozhunci = math.sqrt(x0/(len(data_dalei_drop_2)-1))
xiapu.append(sharp)
expect_profit.append(data_expect_profit)
biaozhun.append(biaozhunci)
M1 = pd.Series(expect_profit)
M2 = pd.Series(xiapu)
M3 = pd.Series(biaozhun)
M4 = pd.concat([M1,M2,M3],axis=1)
M4.to_excel('./data/dropnew.xlsx')
def recover(recover_1):
xiapu2 = []
expect_profit2 = []
biaozhun2 = []
data_dalei = divide()
for x2 in recover_1:
data_x_2 = []
data_x_3 = []
data_x= []
if int(x2) == 2001:
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,5]
for i in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[i]-data_dalei_recover[i-1])/data_dalei_recover[i-1])*100
data_x.append(data)
data_x1 = pd.Series(data_x)
sharp = cal_sharp(data_x1,rf = 3)
#计算期望收益:
data_expect_profit = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe3 = 0
x_3 = 0
for aa in range(1,len(data_dalei_recover)):
data8 = (data_dalei_recover[aa]-data_dalei_recover[aa-1])
qiuhe3 = qiuhe3 + data8
avg3 = qiuhe3/(len(data_dalei_recover)-1)
for aa1 in range(1,len(data_dalei_recover)):
data9 = (data_dalei_recover[aa1]-data_dalei_recover[aa-1])
x_33 = pow(data9-avg3,2)
x_3 = x_3 +x_33
zhuanx = x_3/(len(data_dalei_recover))
biaozhuancha3 = math.sqrt(zhuanx)
xiapu2.append(sharp)
expect_profit2.append(data_expect_profit)
biaozhun2.append(biaozhuancha3)
elif int(x2) == 2004:
for kk in range(0,2):
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,kk]
for kk1 in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[kk1]-data_dalei_recover[kk1-1])/data_dalei_recover[kk1-1])*100
data_x_2.append(data)
data_x2 = pd.Series(data_x_2)
sharp1 = cal_sharp(data_x2,rf = 3)
#计算期望收益:
data_expect_profit1 = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe2 = 0
x_2 = 0
for kk3 in range(1,len(data_dalei_recover)):
datam = (data_dalei_recover[kk3]-data_dalei_recover[kk3-1])
qiuhe2 = qiuhe2 +datam
avg2 = qiuhe2/(len(data_dalei_recover)-1)
for kk4 in range(1,len(data_dalei_recover)):
datan = (data_dalei_recover[kk4]-data_dalei_recover[kk4-1])
x_22 = pow(datan - avg2,2)
x_2 = x_2 + x_22
biaozhunca = math.sqrt(x_2/len(data_dalei_recover))
xiapu2.append(sharp1)
biaozhun2.append(biaozhunca)
expect_profit2.append(data_expect_profit1)
elif int(x2) == 2003:
#计算夏普比率:
data_dalei_recover = data_dalei[str(x2)].iloc[:,1]
for kk1 in range(1,len(data_dalei_recover)):
data = ((data_dalei_recover[kk1]-data_dalei_recover[kk1-1])/data_dalei_recover[kk1-1])*100
data_x_2.append(data)
data_x2 = pd.Series(data_x_2)
sharp1 = cal_sharp(data_x2,rf = 3)
#计算期望收益:
data_expect_profit1 = data_dalei_recover[-1]-data_dalei_recover[0]
#计算收益率标准差
qiuhe2 = 0
x_2 = 0
for kk3 in range(1,len(data_dalei_recover)):
datam = (data_dalei_recover[kk3]-data_dalei_recover[kk3-1])
qiuhe2 = qiuhe2 +datam
avg2 = qiuhe2/(len(data_dalei_recover)-1)
for kk4 in range(1,len(data_dalei_recover)):
datan = (data_dalei_recover[kk4]-data_dalei_recover[kk4-1])
x_22 = pow(datan - avg2,2)
x_2 = x_2 + x_22
biaozhunca = math.sqrt(x_2/len(data_dalei_recover))
xiapu2.append(sharp1)
biaozhun2.append(biaozhunca)
expect_profit2.append(data_expect_profit1)
else:
for kk2 in range(0,4):
data_dalei_recover_2 = data_dalei[str(x2)].iloc[:,kk2]
#计算期望收益
data_expect_profit2 = data_dalei_recover_2[-1]-data_dalei_recover_2[0]
print(f"期望收益{data_expect_profit2}")
#计算夏普比率:
for kk3 in range(1,len(data_dalei_recover_2)):
data = ((data_dalei_recover_2[kk3]-data_dalei_recover_2[kk3-1])/data_dalei_recover_2[kk3-1])*100
data_x_3.append(data)
data_x3 = pd.Series(data_x_3)
sharp2 = cal_sharp(data_x3,rf = 3)
print(f"夏普:{sharp2}")
#计算收益率标准差
#平均收益:avg
qiuhe1 = 0
x_1 = 0
for kk4 in range(1,len(data_dalei_recover_2)):
data4 = (data_dalei_recover_2[kk4]-data_dalei_recover_2[kk4-1])
qiuhe1 = qiuhe1 + data4
avg = qiuhe1/(len(data_dalei_recover_2)-1)
#当天收益:
for kk5 in range(1,len(data_dalei_recover_2)):
data5 = (data_dalei_recover_2[kk5] - data_dalei_recover_2[kk5-1])
x_11 = pow(data5-avg,2)
x_1 = x_1 + x_11
zhuan = x_1/len(data_dalei_recover_2)
biaozhunci2 = math.sqrt(zhuan)
print(f"标准差{biaozhunci2}\n")
qiuhe1 = 0
x_1 = 0
x_11=0
avg = 0
zhuan = 0
data5 = 0
print(f"期望收益{x2}{data_expect_profit2}")
print(f"夏普:{x2}{sharp2}")
print(f"收益率标准差{x2}{biaozhunci2}")
xiapu2.append(sharp2)
expect_profit2.append(data_expect_profit2)
biaozhun2.append(biaozhunci2)
K1 = pd.Series(expect_profit2)
K2 = pd.Series(xiapu2)
K3 = pd.Series(biaozhun2)
K4 = pd.concat([K1,K2,K3],axis=1)
K4.to_excel('./data/recovernew.xlsx')
def overhead(overhead_1):
data_dalei = divide()
for x3 in overhead_1:
data_dalei_overhear = data_dalei[str(x3)]
#没有经济过热的年份
def staflation(staflation_1):
xiapu3 = []
expect_profit3 = []
biaozhun3 = []
data_dalei = divide()
for x4 in staflation_1:
data_x_4 = []
data_dalei_stagflation = data_dalei[str(x4)].iloc[:,9]
#计算夏普比率:
for jj1 in range(1,len(data_dalei_stagflation)):
data1 = ((data_dalei_stagflation[jj1]-data_dalei_stagflation[jj1-1])/data_dalei_stagflation[jj1-1])*100
data_x_4.append(data1)
data_x4 = pd.Series(data_x_4)
sharp2 = cal_sharp(data_x4,rf = 3)
#计算收益期望:
data_expect_profit3 = data_dalei_stagflation[-1]-data_dalei_stagflation[0]
#计算收益率标准差:
qiuhe2 = 0
x_2 = 0
for jj2 in range(1,len(data_dalei_stagflation)):
data6 = (data_dalei_stagflation[jj2]-data_dalei_stagflation[jj2-1])
qiuhe2 = qiuhe2 + data6
avg2 = qiuhe2/(len(data_dalei_stagflation)-1)
for jj3 in range(1,len(data_dalei_stagflation)):
data7 = (data_dalei_stagflation[jj3]-data_dalei_stagflation[jj3-1])
x_x_1 = pow(data7-avg2,2)
x_2 = x_2 + x_x_1
zhuan1 = x_2/len(data_dalei_stagflation)
boapzhuncha3 =math.sqrt(zhuan1)
xiapu3.append(sharp2)
expect_profit3.append(data_expect_profit3)
biaozhun3.append(boapzhuncha3)
# print(f"夏普比率{sharp2}")
# print(f"收益期望{data_expect_profit3}")
# print(f"收益率标准差{boapzhuncha3}\n")
L1 = pd.Series(expect_profit3)
L2 = pd.Series(xiapu3)
L3 = pd.Series(biaozhun3)
L4 = pd.concat([L1,L2,L3],axis=1)
L4.to_excel('./data/stagflationnew.xlsx')
def cal_sharp(daily_returns: np.ndarray, rf=0, period=252):
"""计算夏普比率:(投资组合期望收益率 - 无风险收益) / 投资组合波动率"""
Er = daily_returns.sum() / len(daily_returns) - rf / period # 每日的平均收益 - 每日的无风险收益
sharp = Er / daily_returns.std() * math.sqrt(period)
return sharp
def xiangguanxing():
f = pd.read_excel(path3)
s = f.corr()
print(s)
ax = plt.subplots(1,1)
ax = sns.heatmap(s,vmax = 1,square=True,annot=True)
plt.xticks()
plt.yticks()
# sns.pairplot(f)
# # sns.pairplot(s,hue='sepal_width')
# pd.plotting.scatter_matrix(f,figsize=(12,12),range_padding=0.5)
plt.show()4.第四问
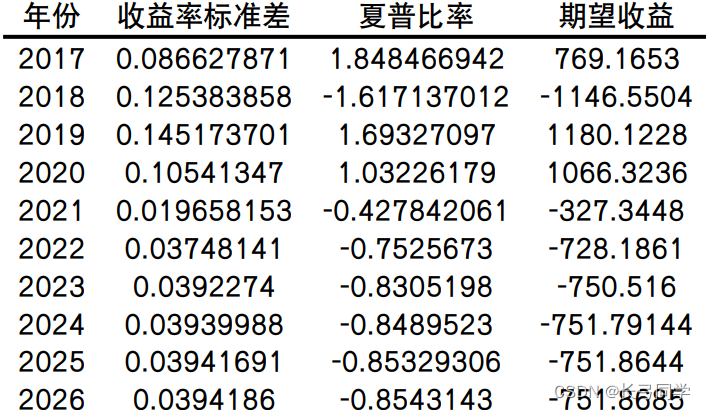
题目分析:对 4 种股票、3 种债券、2 种大宗商品指数、1 种货币基金进行排列组合,总共 24 种搭配,根据第3问得到的相关系数热力图选取近五年的风险收益特征进行预测,得到未来五年复苏阶段较为合适且收益高的投资组合为:上证 50、沪深 300、南华商品指数、 中证-综合财富(3-5 年、7-10 年)、货币基金。再使用LSTM算法预测投资组合的风险收益特征(方法借鉴第二问)。
(由于第四问是前三问的综合应用,这里不再过多赘述)
预测结果:
(eg.沪深 300 未来五年风险收益特征预测结果)
三、总结
B题主要运用的是数据挖掘与数据分析的知识,其中对于未来数据的预测使用了机器学习的LSTM算法,LSTM 作为 RNN 的一个优秀的变种模型,继承了大部分 RNN 模型的特性,同时解决了梯度反传过程由于逐步缩减而产生的梯度消失问题,可以实现长期数据的保存输入,因此,将其加入滑动窗口算法,可以很好用于预测未来较长一段时间后的数据。
这次比赛对于我来说收获颇丰,也算是一次对于金融数据建模这一陌生领域的学习,总的来说,赛题难度并不大,且比赛时长为8天时间充裕,比赛体验良好,是非常适合金融数学小白作为练习的比赛。