YOLOv1 to YOLOv10: The fastest and most accurate real-time object detection systems
YOLOv1到YOLOv10:最快速、最精准的实时目标检测系统

论文链接
0.论文摘要
摘要——本文是对YOLO系列系统的全面综述。与以往文献调查不同,本综述文章从最新技术视角重新审视了YOLO系列的特性。同时,我们还分析了YOLO系列如何持续影响并推动实时计算机视觉相关研究,以及如何引领后续计算机视觉与语言模型的发展。我们深入探讨了过去十年间YOLO系列提出的方法如何影响后续技术演进,并展示了YOLO在各领域的应用场景。希望本文能为后续实时计算机视觉的发展起到良好的指导作用。
索引关键词—YOLO,计算机视觉,实时目标检测。
1.引言
目标检测是一项基础的计算机视觉任务,能够支撑众多下游任务。例如,它可用于辅助实例分割、多目标跟踪、行为分析与识别、人脸识别等,因此在过去几十年里一直是热门研究方向。近年来,随着移动设备的普及,在边缘端实现实时目标检测的能力已成为各类实际应用的必要组成部分。这类应用场景包括自动驾驶、工业机器人、身份认证、智慧医疗、视觉监控等。在众多实时目标检测算法中,近年来发展的YOLO(You Only Look Once)系列(从v1到v10)[1]、[10]表现尤为突出,对计算机视觉领域的各项研究产生了广泛而深远的影响。本文将系统回顾YOLO技术家族及其对当代实时计算机视觉系统发展的影响。
首个在目标检测领域取得突破性成功的深度学习方法是由RCNN[11]提出的。R-CNN是一种两阶段目标检测方法,将检测流程划分为候选区域生成和候选区域分类两个阶段。其核心思路是首先采用图像处理中常用的选择性搜索算法[12]提取候选区域,该阶段仅将CNN作为特征提取器获取候选区域特征,识别部分则采用支持向量机[13]。后续发展的Fast R-CNN[14]和Faster R-CNN[15]分别通过引入空间金字塔池化网络[16]加速特征提取,以及提出区域提议网络,逐步将目标检测推向端到端范式。Joseph Redmon于2015年提出的YOLO[1]采用网格预测机制一步完成检测,这种开创性方法将实时目标检测提升至全新高度。此后发展的经典单阶段检测系统还包括SSD[17]、RetinaNet[18]、FCOS[19]等。
尽管单阶段目标检测方法能够实时检测物体,但其精度仍与两阶段目标检测方法存在差距。RetinaNet[18]和YOLOv3[3]等单阶段检测系统在该问题上取得了显著进展,均实现了足够的精度。YOLO系列已成为工业界及所有需要实时目标分析的学术研究机构的首选方法。2020年,scaled-YOLOv4[20]进一步设计出高效的检测模型缩放方法,首次使单阶段目标检测在通用目标检测领域的精度超越同期所有两阶段检测方法,这一成果也催生了大量基于YOLO系列方法的后续相关研究。
除了目标检测,YOLO系列还被用作开发实时系统的基础,应用于其他计算机视觉领域。目前在实例分割、姿态估计、图像分割、3D目标检测、开放词汇目标检测等任务中,YOLO仍在实时系统中发挥着关键作用。
在这篇综述文章中,我们将按顺序介绍以下内容:
• YOLO系列方法概述及相关重要文献
• YOLO系列方法对当代计算机视觉领域的影响
• 不同计算机视觉领域中应用YOLO的重要方法
2.YOLO系列
YOLO是当代最先进实时目标检测器的代名词。与传统目标检测系统最大的区别在于,YOLO摒弃了以往需要先在图像中找到可能包含物体的位置、再逐一分析这些位置内容的两阶段检测方法,提出了一种统一的一阶段目标检测方法。这种方案流程精简且高效,使得YOLO在各种边缘设备和实时应用中得到广泛使用。接下来我们将介绍几个具有代表性的YOLO版本,本文献综述与以往不同,我们将聚焦最前沿的目标检测方法,并评述这些方法的优势与不足。
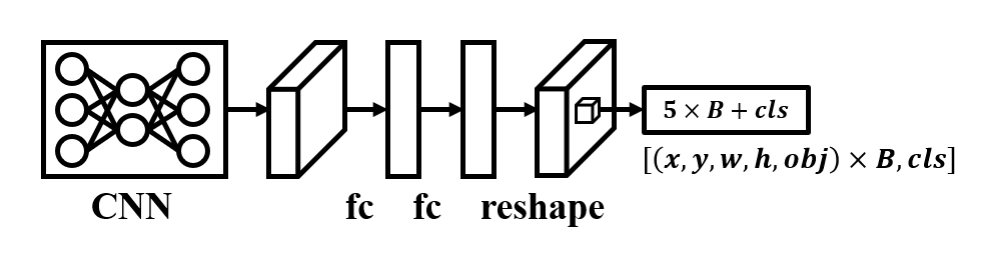
图1. YOLOv1架构。
A. YOLO(YOLOv1)
YOLOv1:Redmon等人[1]于2015年首次提出单阶段目标检测器,其架构如图1所示。如图所示,输入图像首先通过CNN进行特征提取,随后经过两个全连接层获取全局特征。这些全局特征会被重新整形回二维空间,用于每个网格的预测。YOLOv1具有以下重要特性:
单阶段目标检测器。如图1所示,YOLOv1直接对特征图的每个网格进行分类,并预测 B B B个边界框。每个边界框分别预测目标中心 ( b x , b y ) (b_x, b_y) (bx,by)、目标尺寸 ( b w , b h ) (b_w, b_h) (bw,bh)和目标分数 ( b o b j ) (b_{obj}) (bobj)。这种单阶段预测方法无需依赖目标候选框生成阶段必须执行的选择性搜索,可避免因人工设计线索不足导致的漏检。此外,单阶段方法能规避第二阶段全连接层产生的大量参数与计算量,同时避免连接两阶段RoI操作时所需的不规则运算。因此,YOLO的设计能更及时高效地捕获特征并完成预测。下文将详细解析YOLOv1的核心概念:无锚框边界框回归、IoU感知的目标性以及全局上下文特征。
无锚框边界框回归。在公式1中,YOLOv1直接预测物体长宽相对于整张图像的占比。虽然无锚框方法需要优化较大动态范围的长宽值,导致收敛难度增加,但其优势在于不受锚框限制,因而能更准确地预测某些特殊样本。
b x = t x + c x , b y = t y + c y , ( 1 ) b w = t w 2 , b h = t h 2 \begin{aligned}&b_{x}=t_{x}+c_{x},\\&b_y=t_y+c_y,\\&&\mathrm{(1)}\\&b_{\boldsymbol{w}}=t_{\boldsymbol{w}}{}^{2},\\&b_{h}={t_{h}}^{2}\end{aligned} bx=tx+cx,by=ty+cy,bw=tw2,bh=th2(1)
IoU感知的目标性度量。为了更精准衡量边界框预测质量,YOLOv1提出的方法是预测某边界框与所分配真实标注框之间的IoU值,并将其作为IoU感知分支预测目标性的软标签。最终边界框的置信度得分由目标性得分与分类概率的乘积决定。
全局上下文特征。为确保网格不仅关注局部特征而导致预测错误,YOLOv1采用全连接层来获取全局上下文特征。在此设计中,无论底层CNN架构如何,每个网格在预测时都能观察到足够范围的特征以定位目标物体。与fast R-CNN相比,该设计将背景错误率有效降低了一半以上。
B. YOLO9000(YOLOv2)
除了提出许多富有洞察力的新方法外,Redmon和Farhadi[2]还整合了多种现有技术。他们设计了一个兼具高精度与速度的目标检测器,如图2所示。该研究将整个目标检测架构转换为全卷积网络,同时融合了高分辨率和低分辨率特征,最终采用基于锚框的预测方式。由于输入输出格式简洁,YOLOv2至今仍是许多工业场景(特别是计算资源极其有限的低端设备)在维护开发中普遍采用的主流目标检测方法之一。下文我们将分别从维度聚类、直接位置预测、细粒度特征、分辨率校准以及与WordTree联合训练等核心环节,详细讨论YOLOv2最关键的技术要点。
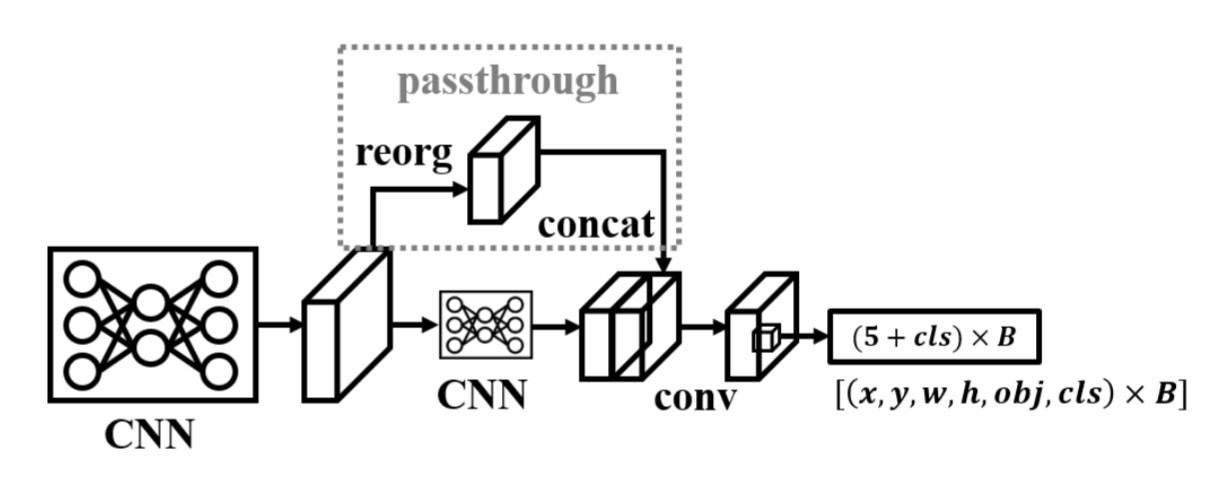
图2. YOLOv2架构。
维度聚类。YOLOv2提出利用IoU距离作为基础,通过对真实标注框进行k均值聚类来获取锚框。一方面,采用维度聚类得到的锚框能够避免原始人工设置宽高比例时难以学习目标边界框预测的问题;另一方面,相比无锚框方法的边界框回归,这种方式也更容易收敛。
直接位置预测。Faster R-CNN以锚点中心为基准,预测目标中心与锚点中心之间的偏移量。上述方法在训练初期非常不稳定。YOLOv2沿用YOLOv1的目标中心回归方法,直接基于负责预测目标的网格左上角坐标来预测目标中心的真实位置。
细粒度特征。直通层通过将高分辨率特征无损重组为空间到深度的形式,并与低分辨率特征相结合进行预测。这种方法能在兼顾速度的同时,通过高分辨率特征增强细粒度小目标检测能力。
分辨率校准。由于骨干CNN在图像分类预训练时通常使用的图像分辨率低于目标检测训练时的分辨率,预训练模型从未见过较大尺寸物体的状态。YOLOv2采用相同训练尺寸的图像进行图像分类预训练,使得目标检测训练过程无需额外学习新尺寸的物体信息。
基于WordTree的联合训练。YOLOv2采用与WordTree相似的层级结构设计ImageNet分组softmax训练,随后通过WordTree整合了COCO和ImageNet的类别体系。最终该技术需要联合训练ImageNet的图像分类任务与COCO的目标检测任务。得益于上述设计,YOLOv2获得了检测9000类目标的能力。
C. YOLOv3
YOLOv3 [3]由Redmon和Farhadi于2018年提出。他们整合了现有目标检测的先进技术,并对单阶段目标检测器进行了相应优化。如图3所示,在架构方面,YOLOv3主要结合了FPN[21]以实现多尺度预测,同时引入残差网络架构并设计了DarkNet53。此外,YOLOv3还对标签分配任务做出了重大调整:首次规定每个真实框仅分配给一个锚框,其次将IoU感知的目标置信度从软标签改为硬标签。时至今日,YOLOv3仍是YOLO系列中最受欢迎的版本。接下来我们将详细阐述YOLOv3的三个特殊设计:跨尺度预测、高GPU利用率以及空间金字塔池化(SPP)。
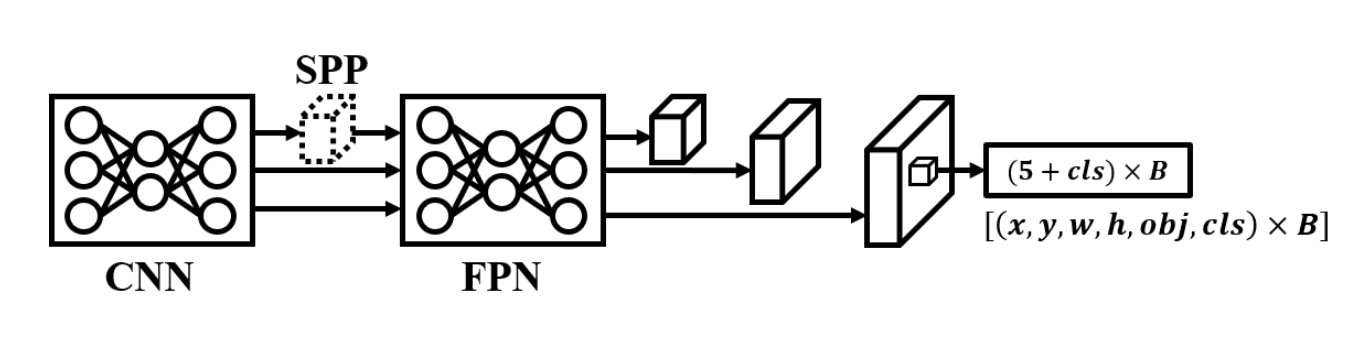
图3. YOLOv3、YOLOv5和PP-YOLO的架构。
跨尺度预测。YOLOv3结合特征金字塔网络(FPN)实现跨尺度预测,可大幅提升小目标检测能力。
高GPU利用率。2018年时,主流网络架构设计侧重于减少计算量和参数量。Darknet53的设计相比其他架构具有更高的GPU硬件利用率,因此在相同计算量下能实现更快的推理速度。这种设计也促使后续架构研究开始关注实际硬件推理速度。
SPP模块。YOLOv1使用全连接层获取全局上下文特征,YOLOv2采用passthrough层融合多分辨率特征。YOLOv3设计了多个步长为1、核尺寸从局部到全局的最大池化层,这种设计使每个网格都能获取从局部到全局的多分辨率特征。SPP已被证明是一种能显著提升精度的简单高效方法。
D. Gaussian YOLOv3
高斯YOLOv3[22]提出了一种显著降低目标检测过程中误检率的有效方法。该方法主要改进了预测头的解码方式,将边界框数值回归问题转化为预测其分布。其架构如图4所示。

图4. 高斯YOLOv3架构。
基于分布的边界框回归。图中所示的基于分布的边界框回归模块,是通过高斯分布来预测边界框(x, y, w, h)的不确定性。这种预测方法能够显著降低目标检测的误检率。
E. YOLOv4
由于约瑟夫·雷德蒙因故退出计算机视觉研究,YOLO的后续版本主要在开源平台GitHub上发布。至于论文的发表时间则晚于开源时间。2020年4月初,阿列克谢·博奇科夫斯基将YOLOv4[4]作为草案提交给约瑟夫·雷德蒙,并于同年4月23日正式发布。YOLOv4主要整合了近年来计算机视觉不同领域的多项技术,以提升实时目标检测器的学习效果。其架构变革在于用PAN[23]替代FPN,并引入CSPNet[24]作为主干网络。后续多数同类YOLO架构都沿用了这一设计。鉴于深度学习技术的快速迭代,YOLOv4不仅基于DarkNet[25]、[26]开发,还在当时最成功的PyTorch版YOLOv3[27]上实现。YOLOv4成功展示了如何用单块GPU训练出精度媲美128块GPU训练的目标检测器,同时推理速度提升三倍以上。其卓越性能也催生了大量后续目标检测研究。以下是YOLOv4开发的新特性列表:
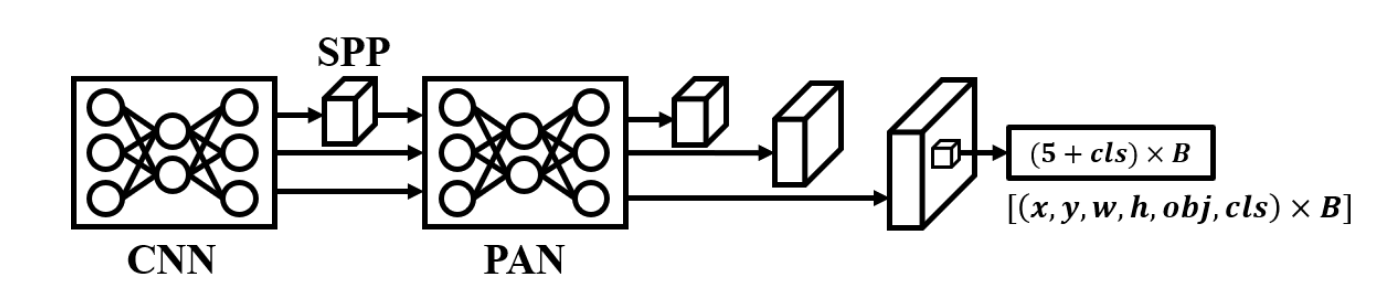
图5. YOLOv4、Scaled-YOLOv4、YOLOv5 r1–r7及PPYOLOv2的架构。
Bag of Freebies。该方案引入了仅增加训练时间但不影响推理时长的训练技术,主要包括损失函数、正则化方法、数据增强方法和标签分配策略。
特殊模块包。YOLOv4还引入了一些仅轻微影响推理时间但能显著提升精度的方法,主要包括感受野模块、注意力机制、激活函数和归一化层,并通过筛选有效组合来增强系统性能。
网格敏感解码器。开源平台用户发现,当目标中心靠近网格边界时难以准确预测。YOLOv4分析原因后发现,Sigmoid函数在极值处的梯度会趋近于零。为此YOLOv4开发者设计了如公式2所示的解码方法,使预测目标值落在有效梯度范围内。
b
x
=
(
1
+
s
x
)
σ
(
t
x
)
−
0.5
s
x
+
c
x
,
b
y
=
(
1
+
s
y
)
σ
(
t
y
)
−
0.5
s
y
+
c
y
,
(
2
)
b
w
=
p
w
e
t
w
,
b
h
=
p
h
e
t
h
\begin{aligned}&b_x=(1+s_x)\sigma(t_x)-0.5s_x+c_x,\\&\begin{aligned}b_y=(1+s_y)\sigma(t_y)-0.5s_y+c_y,\end{aligned}\\&&\mathrm{(2)}\\&b_w=p_we^{t_w},\\&b_h=p_he^{t_h}\end{aligned}
bx=(1+sx)σ(tx)−0.5sx+cx,by=(1+sy)σ(ty)−0.5sy+cy,bw=pwetw,bh=pheth(2)
自对抗训练。YOLOv4还引入了自对抗样本生成训练,以增强目标检测系统的鲁棒性。
内存共享训练。YOLOv4还设计了GPU与CPU共享内存的机制,用于存储梯度更新所需的信息。这一设计使得训练批次大小不再受限于GPU显存容量。
F. Scaled-YOLOv4
2020年,Wang等人[20]延续YOLOv4的成功经验,进一步开发出可同时应用于边缘设备与云端的scaled-YOLOv4。得益于DarkNet和PyTorch YOLOv3社区的活跃贡献,该模型摒弃了ImageNet预训练步骤,直接采用从头训练(train-from-scratch)方法即可获得高质量目标检测结果。在架构层面,scaled-YOLOv4将CSPNet引入PAN模块,全面提升了速度、精度、参数量与计算量等性能指标。该模型还针对各类边缘设备设计了模型缩放方法,提供P5、P6、P7三种模型规格。训练阶段采用了YOLOv5初始版本提出的解码器与标签分配策略。基于上述多项改进,scaled-YOLOv4在所有目标检测器中实现了最高精度与最快推理速度。以下列举该模型的若干独特设计:
复合模型缩放。以往的模型缩放方法仅考虑给定架构的整数超参数。Scaled-YOLOv4提出了一种同时考虑输入图像分辨率和感受野匹配的模型缩放方法,通过利用缩放模型阶段的数量来设计更高效的架构,使其能够适用于高分辨率图像。
硬件友好型架构。参考ShuffleNetv2[28]和HardNet[29]对硬件性能的分析,我们设计了高效的CSPDark模块和CSPOSA模块。
朴素的一次性通用模型。由于scaled-YOLOv4采用从头训练模式,预训练模型与检测模型之间分辨率不一致的问题已不复存在。然而用户输入图像与训练数据之间的不一致性问题仍然存在。scaled-YOLOv4提出的模型缩放方法使用户无需在推理阶段重新训练,只需移除对应阶段的输出即可获得最佳精度。
G. YOLOv5
YOLOv5 [5]延续了PyTorch YOLOv3的设计理念,对整体架构定义方式进行了简化和修订。截至目前已衍生约10个不同版本。初始版本采用与YOLOv3相似的架构设计,同时遵循EfficientDet[30]的模型缩放模式,提供不同规格的模型。PyTorch YOLOv3基于Erik的开源代码[31]开发,因此采用GPL3许可证,后续版本则调整为更严格的AGPL3许可证。YOLOv5继承了PyTorch YOLOv3的诸多功能,例如使用进化算法进行自动锚框和超参数搜索。YOLOv5[5]开源时性能略逊于YOLOv3-SPP,在先后融合YOLOv4采用的CSPNet和scaled-YOLOv4采用的CSPPAN后,首个正式版本YOLOv5 r1.0[32]于2020年6月发布。随后开发者对CSP融合层的速度-精度权衡与激活函数进行优化,引用基于YOLOR的训练超参数,于2021年4月推出YOLOv5 r5.0[33]。最新版本为Glenn于2022年11月发布的YOLOv5 r7.0[34]。由于企业的持续维护与版本更新,YOLOv5目前已成为最受欢迎的YOLO开发平台。以下指出YOLOv5的若干显著特性:
基于幂运算的解码器。YOLOv3的宽高回归系统采用指数函数估算偏移量,该方法在某些数据集上会导致训练不稳定。YOLOv5提出公式3所示的基于幂运算的解码器以提升训练稳定性。由于该解码器输出值被限制在锚框的特定缩放范围内,理论上可获得有界召回率。
b x = 2 σ ( t x ) − 0.5 + c x , b y = 2 σ ( t y ) − 0.5 + c y , ( 3 ) b w = p w ( 2 σ ( t w ) ) 2 , b h = p h ( 2 σ ( t h ) ) 2 \begin{aligned}&b_x=2\sigma(t_x)-0.5+c_x,\\&b_y=2\sigma(t_y)-0.5+c_y,\\&&\mathrm{(3)}\\&b_w=p_w(2\sigma(t_w))^2,\\&b_h=p_h(2\sigma(t_h))^2\end{aligned} bx=2σ(tx)−0.5+cx,by=2σ(ty)−0.5+cy,bw=pw(2σ(tw))2,bh=ph(2σ(th))2(3)
邻域正样本。为了弥补召回率不足的问题,YOLOv5提出增加更多相邻网格作为正样本。同时,为了让这些相邻网格能够正确预测中心点,他们还放大了YOLOv4中心点解码器的sigmoid缩放系数。
H. PP-YOLO
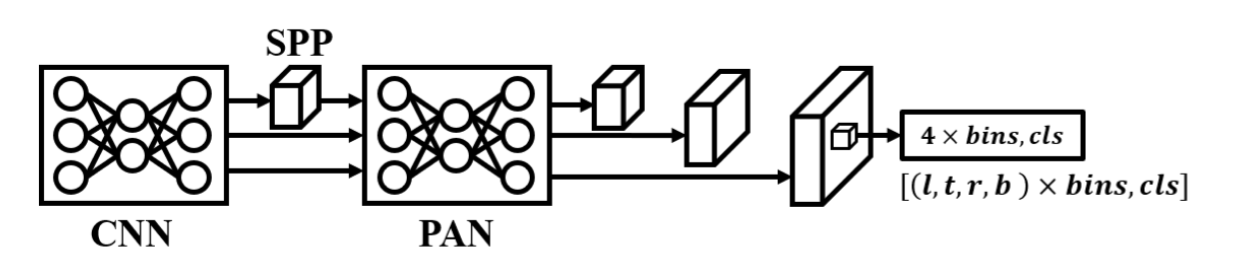
图6. PP-YOLOE、YOLOv6 2.0、YOLOv8、YOLO-NAS的架构。
PP-YOLO系列共有四个版本,分别为PP-YOLO[35]、PP-YOLOv2[36]、PP-PicoDet[37]和PPYOLOE[38]。其中PP-YOLO基于YOLOv3改进,除采用多种YOLOv4训练技巧外,还通过添加CoordConv[39]、Matrix NMS[40]以及更优的ImageNet预训练模型等方法进行优化;PP-YOLOv2则进一步引入scaledYOLOv4的CSPPAN等机制。PP-PicoDet以神经架构搜索为基础设计主干网络,并采用YOLOX的anchor-free解码器[41]。至于PPYOLOE则作出重大改动:修改RepVGG结构设计出CSPRepResStage,并采用TOOD中基于分布的边界框回归方法[42]。YOLOv6之后的YOLO系列几乎都遵循上述格式。以下是PP-YOLO系列部分设计特点:
神经架构搜索:PP-PicoDet为移动端设计的架构,结合ShuffleNetv2[28]与GhostNet[43]进行一次性神经架构搜索。
重参数化模块:PPYOLOE将RepVGG[44]应用于CSPNet,但在训练阶段移除了恒等连接。
基于分布的回归:PPYOLOE沿用TOOD的DFL[45]进行边界框回归。与Gaussian YOLOv3不同,DFL无需限定数据服从高斯分布,可直接学习真实数据分布。
I. YOLOR
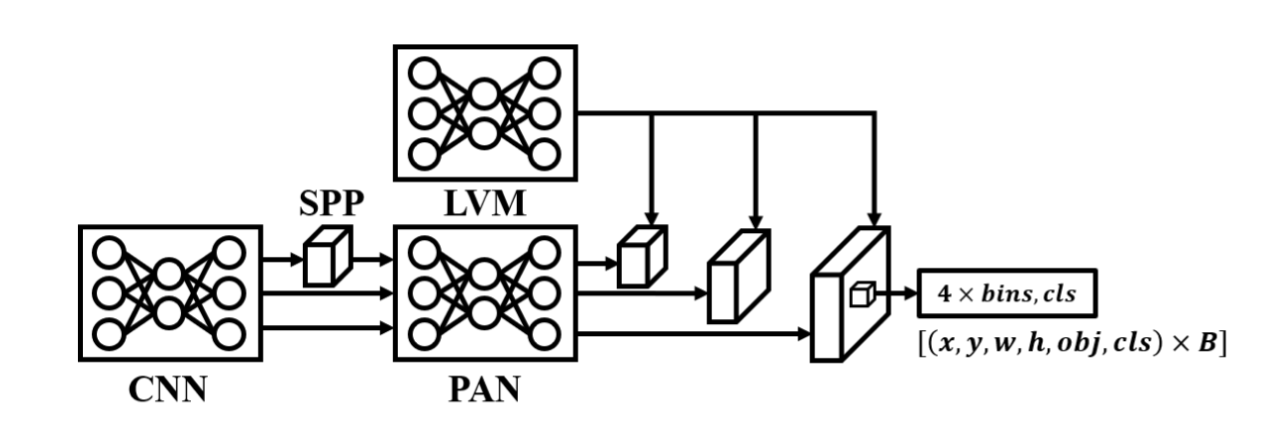
图7. YOLOR的架构。
YOLOR[46]并非YOLO系列的官方版本,但其采用潜在变量模型(LVM)作为隐式知识编码器的设计,能显著提升所有YOLO系列模型的检测效果。YOLOR提出的多任务模型在后续YOLO版本中得到广泛应用,其开创的高级训练技术也被所有后续版本延续推广。以下是YOLOR的专项设计特性:
隐式知识建模:YOLOR提出三种LVM进行隐式知识编码,包括基于向量的、基于神经网络的和基于矩阵分解的编码方式。这三种方法能有效增强深度神经网络的特征对齐能力、预测优化能力和多任务学习能力。
多任务模型:YOLOR提供可同时执行目标检测、图像分类、多目标追踪的复合模型,还推出了基于YOLO-Pose[47]的姿态估计模型。
高级训练技术:YOLOR研发了先进的AutoML技术[48],其超参数训练方案持续应用于YOLO系列最新版本。该模型还采用大数据集预训练、知识蒸馏、自监督学习与自蒸馏技术。截至目前,采用上述方案训练的YOLOR仍是整个YOLO系列中精度最高的模型。
J. YOLOX
YOLOX[41]整合了当时最实用的技术方案,主要基于CSPNet架构[24]和FCOS的无锚点头部设计[19],改进了OTA[49]并提出SimOTA动态标签分配方法,取代了容易产生混淆的人工标签分配方式。后续YOLO系列版本也开始采用或设计不同的动态标签分配方法。下文重点阐述YOLOX的两大核心特性:
解耦头部设计。YOLOX采用FCOS的解耦头部结构,这种设计使得分类任务与边界框回归任务更易于学习。
无锚点机制的重返。基于IoU损失函数的发展,无锚点头部不再受物体长宽比例导致的损失失衡影响。在现代技术支持下,无锚点头部同样能够获得良好训练效果。就YOLOX而言,其通过采用FCOS的无锚点头部设计实现了既定目标。
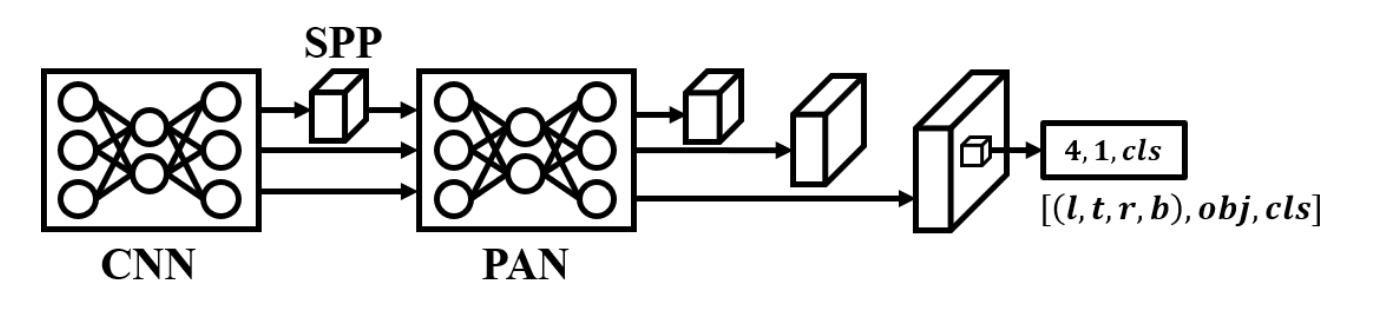
图8. YOLOX架构图。
K. YOLOv6
YOLOv6的初始版本[50]采用RepVGG[44]作为主干架构。在2.0之后的版本中,如Li等人(2022)[6]和Li等人(2023)[51]的研究,引入了CSPNet[24]。YOLOv6是专为工业应用设计的系统,因此在量化问题上投入了大量精力。其贡献包括:使用RepOPT[52]提升量化模型的稳定性,通过量化感知训练(QAT)和知识蒸馏技术提高量化模型的精度。YOLOv6 3.0版本[51]提出了如图9所示的锚框辅助训练(anchor-aid training)概念以提升系统精度。后续的4.0版本[53]则面向低端计算设备,提出了基于深度可分离卷积的轻量架构YOLOv6-lite。以下是YOLOv6提出的部分独特特性:
重参数化优化器。YOLOv6 2.0版本采用RepOPT技术减缓模型量化后的精度损失。
量化感知训练。YOLOv6 2.0版本通过QAT提升量化模型的精度。
知识蒸馏。YOLOv6 2.0版本分别采用自蒸馏和通道蒸馏提升模型精度,同时结合QAT降低模型量化后的精度损失。
锚框辅助训练。YOLOv6 3.0版本提出如图9所示,通过基于锚框的检测头辅助无锚框检测头学习,以提升模型精度。
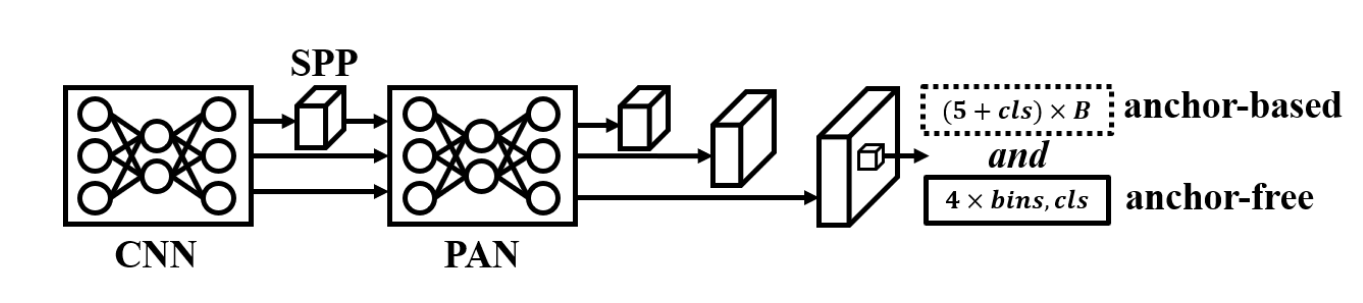
图9. YOLOv6 3.0与YOLOv6 4.0的架构。
L. YOLOv7
YOLOv7 [7]引入了可训练的辅助架构,这些架构可在推理阶段被移除或整合,包括YOLOR [46]、近期流行的RepVGG [44]以及额外的辅助损失。在架构设计上,YOLOv7采用ELAN [54]替代YOLOv4使用的CSPNet,并提出E-ELAN用于大型模型设计。该框架还提供多种计算机视觉任务相关模型,支持基于锚点和无锚点的架构。其核心特性如下:
让RepVGG重焕光彩。RepVGG [44]提出的重参数化方法使简单网络架构在加深时能够收敛,但无法有效应用于现代主流深度网络架构。YOLOv7提出的规划化RepConv技术,使重参数化方法能为各类基于残差和拼接的架构带来有效增益。
一致性标签分配。传统辅助损失方法会导致不同分支的输出目标不一致,引发训练混乱与不稳定。针对动态标签分配方法的成熟普及,YOLOv7提出一致性标签分配机制,保持各分支目标与特征学习方向的一致性。
由粗到精的标签分配。过去的多阶段优化架构(如Cascade R-CNN [55]和HTC [56])需额外理论架构逐步细化预测。YOLOv7提出的粗粒度到细粒度标签分配机制,可直接利用辅助损失引导特征空间的粗细粒度特性,在不改变架构的情况下实现预测优化效果。
部分辅助损失。YOLOv7允许部分特征接收辅助信息更新,其余部分仍专注于目标任务学习。开发者发现该设计对主要任务有显著提升效果。
多样化视觉任务。YOLOv7提供包括目标检测、实例分割和姿态估计在内的模型,在这些任务中均实现了实时最先进性能。
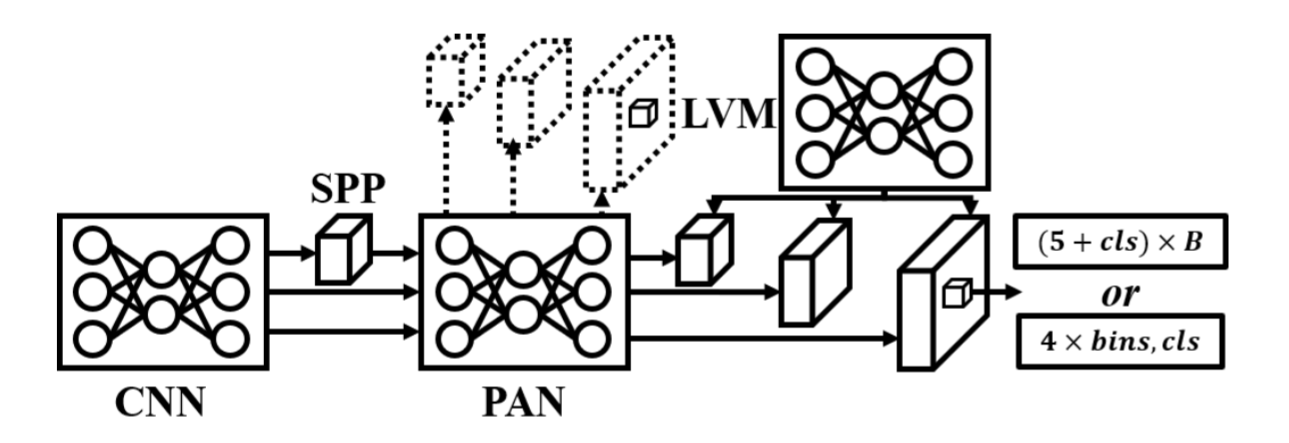
图10. YOLOv7架构。
M. DAMO-YOLO
DAMO-YOLO [57]在骨干网络架构、特征融合、预测头和标签分配等方面提出了改进方法。图11展示了DAMO-YOLO的模块框图,其核心
特性可概括如下:
MAE-NAS架构搜索。DAMO-YOLO采用MAE-NAS[58]技术搜索CSPNet与ELAN结构,以获得更高效的网络架构。
高效GFPN。通过解构GFPN[59]的级联融合,保留为平衡速度与精度设计的融合层,结合ELAN结构设计了RepGFPN。
ZeroHead简化设计。将复杂的解耦头简化为特征投影层。
对齐OTA。提出AlignedOTA方法以解决分类预测、回归预测与动态标签分配间的错位问题。
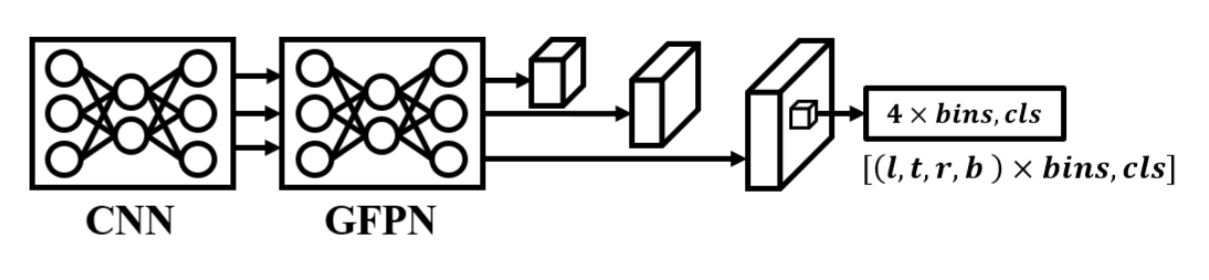
图11. DAMO-YOLO的架构。
N. YOLOv8
YOLOv8 [8] 是YOLOv5 [5] 的重构版本,它更新了整体API的使用方式,并进行了大量底层代码优化。在架构上,它改进了YOLOv7的ELAN模块,增加了额外的残差连接,同时其解码器与YOLOv6 2.0相同。与其说它是一个新的YOLO版本,不如说它是一个技术集成平台,它基本整合了多个下游任务的API并将其串联起来。其最新版本Glenn [8]集成了YOLOv9和YOLO World [60]等最新技术。由于程序修改和API使用不够直观,许多开发者尚未迁移至该平台。但对于专业用户而言,底层程序代码优化带来的性能提升也吸引了许多研发团队采用。以下是YOLOv8的两大特性:
代码优化。YOLOv8发布的底层程序代码优化使训练性能提升了约30%。
下游应用API。YOLOv8还提供了简洁的API,将检测模型与各类下游任务连接,例如通用分割、实例分割、姿态估计、多目标跟踪等。
O. YOLO-NAS
YOLO-NAS [61] 未透露过多技术细节。其核心是采用自研的AutoNAC神经网络架构搜索技术,设计量化友好型架构,并通过多阶段训练流程实现优化,包括在Object365数据集上的预训练、COCO伪标签数据训练、知识蒸馏(KD)以及分布焦点损失(DFL)的应用。
P. Gold-YOLO
Gold-YOLO [62]的整体架构与YOLOv6 3.0类似,其核心设计在于用"收集-分发机制"取代了原架构中的PAN结构,并在训练过程中加入了掩码图像建模预训练。
收集-分发机制的主体架构如图12所示,主要通过两个收集-分发模块从各层级汇聚特征,并利用transformer将其整合为全局特征。整合后的全局特征将分别向低层级和高层级进行分发,分发过程采用信息注入模块将全局特征与已分发至各层级的特征进行融合。
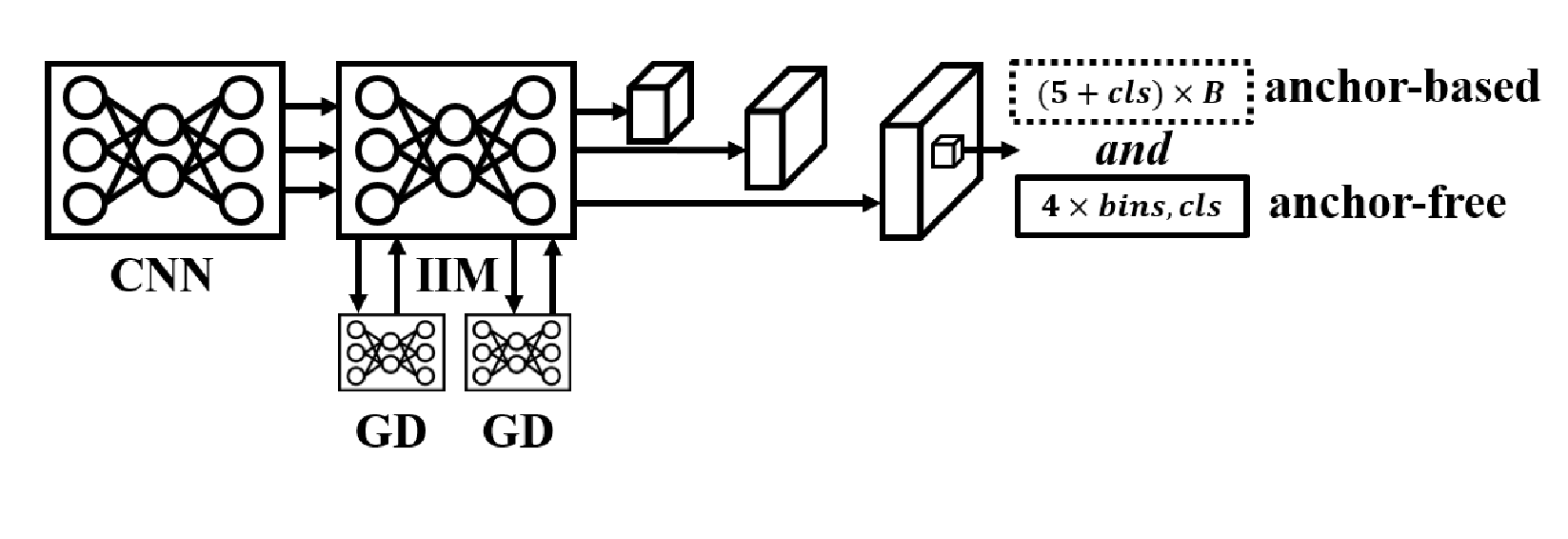
图12. Gold-YOLO的架构。
Q. YOLOv9
YOLOv9[9]提出了一项重要的可信技术——可编程梯度信息(PGI),其架构如图13所示。图中设计架构能够增强模型的可解释性、鲁棒性和通用性。PGI的设计采用可逆架构和多层级信息概念,旨在最大化模型可保留的原始数据及完成目标任务所需的信息。YOLOv9将ELAN扩展为G-ELAN,并通过其展示了PGI如何在低参数量模型上实现优异的精度、稳定性和推理速度。下文将阐述YOLOv9的若干突出特性:
辅助可逆分支。PGI利用可逆架构的特性来解决深度神经网络中的信息瓶颈问题,这与通用可逆架构单纯追求信息保留最大化的思路截然不同。PGI通过将可逆架构保留的信息以辅助信息形式共享给主分支,在保留目标任务所需信息的前提下,尽可能留存原始数据的完整信息。
多层次辅助信息。PGI提出多层次辅助信息概念,使主分支每一层特征都尽可能保留所有任务目标所需信息。这解决了传统方法在浅层易丢失重要信息,导致深层无法获取足够信息的问题。
下游任务泛化能力。由于PGI能最大化保留原始数据信息,其训练的模型在小样本数据集、迁移学习、多任务学习及适应新下游任务时均表现出更鲁棒的性能。
架构普适性。PGI可应用于常规CNN、深度可分离卷积CNN、Transformer等架构,兼容基于锚点、无锚点、免后处理等各类计算机视觉方法,具有绝对优势的通用性。
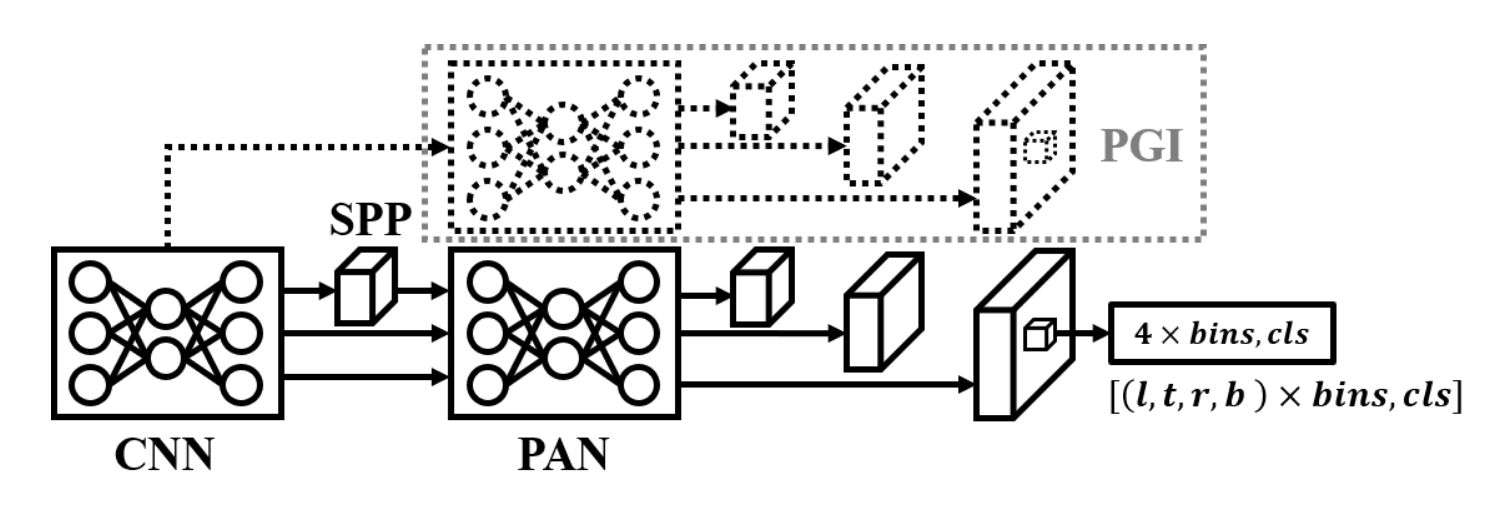
图13. YOLOv9架构。
R. YOLOv10
YOLOv10的整体架构[10]与YOLOv6 3.0相似,但增加了基于Transformer的模块以增强全局特征提取能力。该模型将双检测头分别改为一对多匹配和一对一匹配机制,这一改进使YOLO无需依赖类似DETR的后处理方法,即可直接获得端到端的目标检测结果。以下重点介绍YOLOv10的几项核心特性:
双重标签分配:采用类似DATE[63]的标签分配策略,并对一对一分支添加梯度停止操作。
无NMS目标检测:通过一对一匹配机制的设计,预测过程无需依赖非极大值抑制进行后处理。
秩引导模块设计:提出根据秩值确定各阶段使用常规卷积还是深度可分离卷积。
局部自注意力机制:将CSPNet与Transformer结合,创新性地提出自注意力模块。
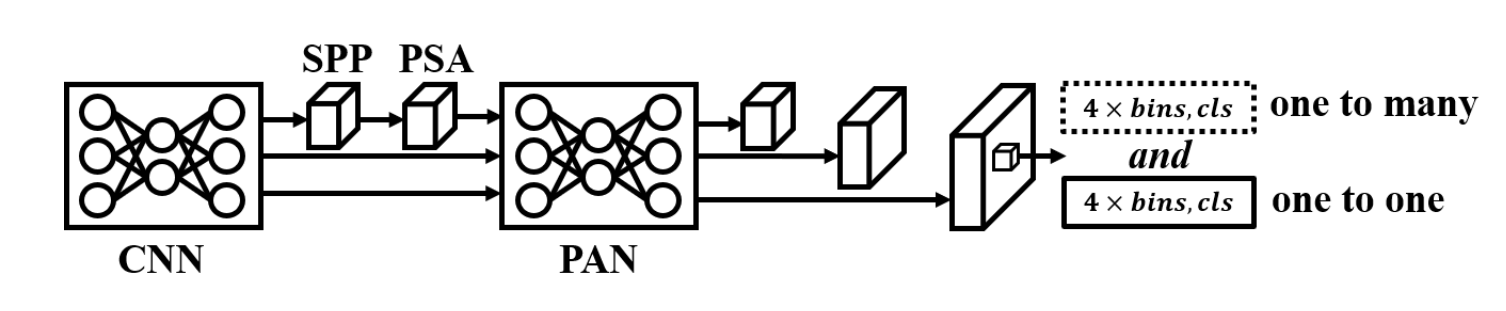
图14. YOLOv10架构。
3.YOLO系列的影响
YOLO系列算法具有两大特征:(1) 框架相对简单;(2) 部署相对容易。下文我们将详细阐述这些特性。
A.更简单
更简洁的框架。基于DeepMultiBox[64]和OverFeat[65]最具前瞻性的研究,YOLO提出了一种全新的单阶段目标检测方法,这一新思路深刻影响了后续众多计算机视觉研究。在YOLO系列提出前,原本需要深度学习进行密集预测的任务主要包括语义分割、光流估计等像素级任务。而对于目标检测、姿态估计等实例级任务,大多被拆分为多个子任务以级联方式预测。YOLO问世后,许多原本需要采用多阶段、自下而上方法的算法,突然转向了端到端、自上而下的单阶段范式。这类例子包括直接预测边界框及框内锚点相对位置的姿态估计与面部关键点检测,以及同时完成检测与重识别特征提取的多目标跟踪。
更简单的部署方式。YOLO无需依赖特殊结构的模块,因此能轻松部署于各类计算设备。然而诸如感受野模块、注意力机制等特殊设计虽能显著提升目标检测精度,却难以被整合为通用且简洁的模块。YOLO通过巧妙设计将这些特殊模块转化为结构简单的形式:例如YOLOv3采用多分辨率最大池化以步长1扫描特征图,改进了原本受限于固定输入尺寸的SPP层和需要空洞卷积的ASPP层,这种方法大幅增强了模型的多分辨率与全局感知能力;而YOLOv4则提出用卷积层替代注意力模块中包含多种池化层和全连接层的小型网络。YOLOv4-tiny、YOLOv6和YOLOv7的整个模型甚至被优化到仅需使用1×1卷积、3×3卷积和最大池化即可构建。此外,Joseph Redmon用C语言开发的Darknet框架使得YOLO的训练推理过程无需依赖额外软件包。上述对现有设备的友好适配特性,使得YOLO系列在各类实际系统中得到广泛应用。
B.更好
除了前文所述的轻量化和易用性特点外,YOLO系列模型还具备一些更高级的功能,例如更优的训练技术、更强的模型扩展性以及更好的模型泛化能力。下文我们将对这些功能进行详细说明。
更先进的训练技术。YOLO系列模型提出的训练技术不仅更为先进,还能与当前最先进的训练技术形成互补。过去许多研究大多在基础方法上验证所提方案,例如图像识别领域的ResNet[66]和ViT[67],或目标检测领域的Faster RCNN[15]和DETR[68]。然而多数研究忽略了所提方法是否与当前最优方法兼容并形成互补,从而推动领域整体进步。自YOLOv2起,该系列在设计时便考虑与最先进技术的兼容性,同时提出能与这些技术互补的新方法。在YOLOv3、YOLOv4和PP-YOLO等系列模型中,开发者还尝试分析无法相互兼容的技术。这种态度对后续开发者具有重要指导意义。
更优的模型扩展性。YOLO系列模型在进行模型缩放时无需特殊设置。ScaledYOLOv4和YOLOv7提出了模型缩放指导原则,YOLOv5则沿用EfficientDet的模型缩放方法。这些缩放方法被直接集成到框架中,此类设计使得用户无论怎样调整模型缩放超参数,都能获得稳定出色的性能表现。
更强的模型泛化能力。YOLO系列提出的方法可应用于众多领域。例如YOLOv1提出的利用预测值与真实值计算指标的概念,已被广泛应用于各类软标签生成方法;YOLOv2提出的K-means初始化锚框方法被拓展至姿态估计领域;YOLO提出的WorldTree分组softmax方法被转化为处理长尾学习中的不平衡数据分布问题;YOLOX提出的SimOTA成为各类动态标签分配的基础方法,YOLOv7提出的混合标签分配方法也得到广泛应用。
YOLO系列方法还适用于多种架构:如YOLOv4采用的CSPNet不仅在CNN上表现优异,还被证明适用于Transformer[69]、图神经网络[70]、脉冲神经网络[71]及MAMBA[72]等架构。后续YOLOv7采用的ELAN结构也快速应用于各类计算机视觉领域。
C.更快
更快的架构。YOLO系列的另一个特点是其极快的推理速度,这主要得益于其专为硬件实际推理性能设计的架构。YOLOv3的设计者发现,即便是简单的1×1卷积与3×3卷积组合架构,虽然计算量较低,却未必能在推理速度上占据优势。因此他们专门为实时目标检测设计了DarkNet。而Scaled-YOLOv4的设计团队则参考了ShuffleNetv2[28]和HarDNet[29]等研究,进一步分析了从边缘设备到云端不同级别设备实现高推理速度架构需考虑的准则。为实现相同目标,scaled-YOLOv4开发者设计了Fully CSPOSANet和CSPDarkNet。至于YOLOv6的研发团队采用了高效的RepVGG作为骨干网络,DAMOYOLO的设计者则通过NAS技术直接在CSPNet和ELAN中搜索高效架构。
D.更强大
更强的适应性。YOLO系列在开源社区取得了巨大进展和反响,Darknet与PyTorch YOLOv3集成的训练方法使该系列无需依赖ImageNet预训练模型即可训练目标检测器。基于上述优势,YOLO系列能轻松应用于不同领域的数据,而无需依赖对应领域的大量训练模型。这些特性使其得以广泛应用于各类场景。此外,该系列还能适配不同数据集——例如PyTorch YOLOv3提出使用进化算法自动搜索超参数,该方案可迁移至各类数据集。从YOLOX到PP-YOLOE的改进中,基于无锚框设计的优化使YOLO在训练时依赖更少的超参数,进一步拓宽了应用范围。
更强的性能表现。YOLO系列在多种计算机视觉任务中展现卓越性能。例如在实时目标检测领域获得广泛应用后,基于YOLO又衍生出YOLACT[73]实例分割模型、JDE[74]多目标跟踪等诸多模型。以YOLOR为例,该模型首次将多任务整合至同一模型进行预测,可同步完成图像识别、目标检测和多目标跟踪,显著提升多任务联合学习效果。对比之下,YOLOv5仍采用图像识别与目标检测模型分开训练的模式。YOLOv7则在多个计算机视觉领域均展现出顶尖性能,曾同时成为实时目标检测、实例分割和姿态估计领域最先进的方法。而YOLOv8进一步整合了旋转目标检测、姿态估计等任务。最新推出的YOLOv9融合YOLOv7与YOLOR优势,将多任务模型扩展至视觉-语言领域。
更广泛的应用场景。作为许多实际应用的必要起点,目标检测技术的核心地位使得顶级检测方法YOLO的设计天然适合与各类下游任务模型对接。其中PP-YOLO系列的设计尤为突出,该系列可为包括人脸分析、车牌识别、多目标跟踪、交通统计、行为分析等数十种下游任务提供集成化系统解决方案。
4.YOLO用于多种计算机视觉任务
YOLO系列系统已在众多领域得到广泛应用。本节将介绍YOLO在其他计算机视觉领域的代表性工作,并阐述这些工作为实现实时性能所完成的新颖架构设计或方法创新。
A.多目标跟踪
ROLO [75], JDE [74], CSTrack [76]
过去,基于深度学习的多目标跟踪相关算法(如Deep-SORT[77])在检测到目标后,需要从原始图像中裁剪出目标区域,再通过额外网络提取特征进行跟踪。ROLO[75]提出直接使用YOLO检测目标,并采用LSTM[78]进行单目标跟踪,随后通过多个LSTM设计出MOLO来实现多目标跟踪。JDE[74]则提出在检测目标的同时输出重识别(re-ID)特征用于跟踪,但其多尺度密集预测的重识别特征计算量较大,且一组re-ID特征会匹配多个锚框,容易导致ID混淆。CSTrack[76]进一步结合JDE与FairMOT[79]方案,在融合多尺度特征后仅输出单一尺度的re-ID特征,从而实现了更精准的多目标跟踪效果。
B.实例分割
YOLACT [73], YOLACT-Edge [80], YOLACT++ [81], Insta-YOLO [82], Poly YOLO [83].
过去,大多数实例分割预测都是针对每个检测到的对象单独进行的,因此需要更复杂的分割网络。YOLACT [73]和YOLACT++ [81]将实例分割过程分解为原型和系数两个步骤,只需预测系数即可利用这些原型生成最终的实例分割结果。采用上述方法能大幅减少实例分割执行时所需的运算量。随后,YOLACTEdge [80]将实例分割进一步推进到视频领域,通过引入FeatFlowNet的概念显著减少了主干网络需要提取的特征数量。
另一种降低实例分割预测计算量的方法是以其他形式表达二进制掩码,例如用多边形或极坐标形式表示掩码。虽然这种表达方式会造成一定失真,但能以极少的维度呈现物体的掩码。Insta-YOLO[82]和Poly YOLO[83]就是采用多边形形式预测实例分割结果的两个典型案例。
C.自动驾驶
YOLOP [84], YOLOPv2 [85], YOLOPv3 [86], HybridNets [87], YOLOPX [88]
YOLO系列在自动驾驶场景的视觉感知任务中也得到广泛应用。YOLOP[84]和YOLOPv2[85]分别采用CSPNet和ELAN作为目标检测主干架构,因此可同时实现区域检测与车道线预测。HybridNet[87]、YOLOPv3[86]和YOLOPX[88]也基于不同版本的YOLO进行改进,用于执行自动驾驶任务。
D.人体姿态估计
KAPAO [89], YOLO-Pose [47].
人体姿态估计可视为预测目标检测任务的空间属性补充。由于关键点未必落在网格内,需额外设计解码器结构。KAPAO[89]将人体姿态分解为人体姿态目标和关键点目标两种表征进行预测与融合;YOLO-Pose[47]则直接预测关键点相对于网格中心的回归值,进而完成姿态估计。上述设计均能取得较好效果。
E.3D目标检测
Complex YOLO [90], Expandable YOLO [91], YOLO 6D [92], YOLO3D [93]
也有部分研究将YOLO系列从二维推广到三维。除了结合图像与激光雷达作为输入的ComplexYOLO[90]和采用RGB-D图像作为输入的Expandable YOLO[91]之外,还有仅使用图像作为输入的YOLO 6D[92]和YOLO 3D[93]。
F.视频感知
YOLOV [94], YOLOV++ [95], Stream YOLO [96].
在图像实时目标检测中表现极佳的YOLO系列算法,自然会被应用于视频领域。其中YOLOV[94]和YOLOV++[95]可应用于视频目标检测,而流式YOLO[96]则适用于流式感知任务。
G.人脸检测
YOLO-Face [97], YOLO-Face v2 [98], YOLO5Face [99].
人脸检测是目标检测众多应用领域中最为热门的子领域之一。基于YOLO算法设计的人脸检测模型在该领域同样表现出色。
H.图像分割
Fast-SAM [100].
由于YOLO具备实时性与高性能的特点,其与多种基础模型的结合也开始应用于新兴计算机视觉任务。FastSAM[100]将YOLO与SAM[101]相结合,应用于通用图像分割任务。这种组合方式能显著提升任务模型的推理速度。
I.开放词汇检测
YOLO-World [60], Open-YOLO 3D [102].
YOLO还与视觉语言基础模型结合使用。这类应用的典型代表包括YOLOworld [60]和Open-YOLO 3D [102],它们融合了YOLO与CLIP [103]方法,可分别用于执行2D和3D开放词汇目标检测任务。
J.结合其他架构
ViT-YOLO [104], DEYO [105], DEYOv2 [106], DEYOv3 [107], [108], Mamba-YOLO [109], Spiking YOLO [110], GNN-YOLO [111], GCN-YOLO [112], KAN-YOLO [113].
YOLO还展现出与多种深度神经网络架构的兼容性。这类架构包括ViT[104]–[108]、MAMBA[109]、SNN[110]、GNN[111][112]以及KAN[113]。它们都能与YOLO有效结合。
5.结论
本文介绍了YOLO系列算法多年来的演进历程,从现代目标检测技术的视角回顾了这些技术,并指出它们在每个发展阶段做出的关键贡献。我们从易用性、精度提升、速度优化以及多领域适用性等方面,分析了YOLO对现代计算机视觉领域的影响。最后,我们介绍了各领域中与YOLO相关的衍生模型。通过这篇综述文章,我们希望读者不仅能从YOLO系列的发展中获得启发,更能深入理解如何开发各类实时计算机视觉方法。同时,我们也旨在为读者展示YOLO可应用于的不同任务场景,并探讨其未来可能的发展方向。
6.引用文献
- [1] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788.
- [2] J. Redmon and A. Farhadi, “YOLO9000: better, faster, stronger,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263–7271.
- [3] ——, “YOLOv3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [4] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “YOLOv4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [5] J. Glenn, “YOLOv5 (2020.05),” https://github.com/ultralytics/yolov5, 2020.
- [6] C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nie et al., “YOLOv6: A single-stage object detection framework for industrial applications,” arXiv preprint arXiv:2209.02976, 2022.
- [7] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 7464–7475.
- [8] J. Glenn, “YOLOv8 release v8.1.0,” https://github.com/ultralytics/ ultralytics/releases/tag/v8.1.0, 2024.
- [9] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, “YOLOv9: Learning what you want to learn using programmable gradient information,” in Proceedings of the European Conference on Computer Vision (ECCV), 2024.
- [10] A. Wang, H. Chen, L. Liu, K. Chen, Z. Lin, J. Han, and G. Ding, “YOLOv10: Real-time end-to-end object detection,” arXiv preprint arXiv:2405.14458, 2024.
- [11] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 580–587.
- [12] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” International Iournal of Computer Vision (IJCV), vol. 104, pp. 154–171, 2013.
- [13] M. A. Hearst, S. T. Dumais, E. Osuna, J. Platt, and B. Scholkopf, “Support vector machines,” IEEE Intelligent Systems and their Applications, vol. 13, no. 4, pp. 18–28, 1998.
- [14] R. Girshick, “Fast R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [15] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” Advances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015.
- [16] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 37, no. 9, pp. 1904–1916, 2015.
- [17] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 21–37.
- [18] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll ́ar, “Focal loss for dense object detection,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988.
- [19] Z. Tian, C. Shen, H. Chen, and T. He, “FCOS: A simple and strong anchor-free object detector,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 44, no. 4, pp. 1922–1933, 2020.
- [20] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “Scaled-YOLOv4: Scaling cross stage partial network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 13 029–13 038.
- [21] T.-Y. Lin, P. Doll ́ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2117–2125.
- [22] J. Choi, D. Chun, H. Kim, and H.-J. Lee, “Gaussian YOLOv3: An accurate and fast object detector using localization uncertainty for autonomous driving,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 502–511.
- [23] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 87598768.
- [24] C.-Y. Wang, H.-Y. M. Liao, Y.-H. Wu, P.-Y. Chen, J.-W. Hsieh, and I.H. Yeh, “CSPNet: A new backbone that can enhance learning capability of CNN,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020, pp. 390391.
- [25] pjreddie, “darknet,” https://github.com/pjreddie/darknet, 2018.
- [26] AlexeyAB, “darknet,” https://github.com/AlexeyAB/darknet, 2019.
- [27] J. Glenn, “YOLOv3 PyTorch,” https://github.com/ultralytics/yolov3, 2019.
- [28] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet v2: Practical guidelines for efficient cnn architecture design,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 116–131.
- [29] P. Chao, C.-Y. Kao, Y.-S. Ruan, C.-H. Huang, and Y.-L. Lin, “HarDNet: A low memory traffic network,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 3552–3561.
- [30] M. Tan, R. Pang, and Q. V. Le, “EfficientDet: Scalable and efficient object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10 78110 790.
- [31] E. Linder-Nore ́n, “YOLOv3 PyTorch,” https://github.com/ eriklindernoren/PyTorch-YOLOv3, 2018.
- [32] J. Glenn, “YOLOv5 release v1.0,” https://github.com/ultralytics/yolov5/ releases/tag/v1.0, 2020.
- [33] ——, “YOLOv5 release v5.0,” https://github.com/ultralytics/yolov5/ releases/tag/v5.0, 2021.
- [34] ——, “YOLOv5 release v7.0,” https://github.com/ultralytics/yolov5/ releases/tag/v7.0, 2022.
- [35] X. Long, K. Deng, G. Wang, Y. Zhang, Q. Dang, Y. Gao, H. Shen, J. Ren, S. Han, E. Ding et al., “PP-YOLO: An effective and efficient implementation of object detector,” arXiv preprint arXiv:2007.12099, 2020.
- [36] X. Huang, X. Wang, W. Lv, X. Bai, X. Long, K. Deng, Q. Dang, S. Han, Q. Liu, X. Hu et al., “PP-YOLOv2: A practical object detector,” arXiv preprint arXiv:2104.10419, 2021.
- [37] G. Yu, Q. Chang, W. Lv, C. Xu, C. Cui, W. Ji, Q. Dang, K. Deng, G. Wang, Y. Du et al., “PP-PicoDet: A better real-time object detector on mobile devices,” arXiv preprint arXiv:2111.00902, 2021.
- [38] S. Xu, X. Wang, W. Lv, Q. Chang, C. Cui, K. Deng, G. Wang, Q. Dang, S. Wei, Y. Du et al., “PP-YOLOE: An evolved version of YOLO,” arXiv preprint arXiv:2203.16250, 2022.
- [39] R. Liu, J. Lehman, P. Molino, F. Petroski Such, E. Frank, A. Sergeev, and J. Yosinski, “An intriguing failing of convolutional neural networks and the coordconv solution,” Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018.
- [40] X. Wang, R. Zhang, T. Kong, L. Li, and C. Shen, “SOLOv2: Dynamic and fast instance segmentation,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 17 721–17 732, 2020.
- [41] Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “YOLOX: Exceeding YOLO series in 2021,” arXiv preprint arXiv:2107.08430, 2021.
- [42] C. Feng, Y. Zhong, Y. Gao, M. R. Scott, and W. Huang, “TOOD: Taskaligned one-stage object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 34903499.
- [43] K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, and C. Xu, “GhostNet: More features from cheap operations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1580–1589.
- [44] X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, and J. Sun, “RepVGG: Making VGG-style convnets great again,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 13 733–13 742.
- [45] X. Li, W. Wang, L. Wu, S. Chen, X. Hu, J. Li, J. Tang, and J. Yang, “Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection,” Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 21 002–21 012, 2020.
- [46] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, “You only learn one representation: Unified network for multiple tasks,” Journal of Information Science and Engineering (JISE), vol. 39, no. 2, pp. 691–709, 2023.
- [47] D. Maji, S. Nagori, M. Mathew, and D. Poddar, “YOLO-Pose: Enhancing YOLO for multi person pose estimation using object keypoint similarity loss,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2022, pp. 2637–2646.
- [48] C.-Y. Wang, H.-Y. M. Liao, I.-H. Yeh, Y.-Y. Chuang, and Y.-L. Lin, “Exploring the power of lightweight YOLOv4,” in roceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 779–788.
- [49] Z. Ge, S. Liu, Z. Li, O. Yoshie, and J. Sun, “OTA: Optimal transport assignment for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 303–312.
- [50] meituan, “YOLOv6,” https://github.com/meituan/YOLOv6, 2022.
- [51] C. Li, L. Li, Y. Geng, H. Jiang, M. Cheng, B. Zhang, Z. Ke, X. Xu, and X. Chu, “YOLOv6 v3.0: A full-scale reloading,” arXiv preprint arXiv:2301.05586, 2023.
- [52] X. Ding, H. Chen, X. Zhang, K. Huang, J. Han, and G. Ding, “Re-parameterizing your optimizers rather than architectures,” in The International Conference on Learning Representations (ICLR), 2023.
- [53] C. Li, B. Zhang, L. Li, L. Li, Y. Geng, M. Cheng, X. Xiaoming, X. Chu, and X. Wei, “YOLOv6: A single-stage object detection framework for industrial applications,” 2024.
- [54] C.-Y. Wang, H.-Y. M. Liao, and I.-H. Yeh, “Designing network design strategies through gradient path analysis,” Journal of Information Science and Engineering (JISE), vol. 39, no. 4, pp. 975–995, 2023.
- [55] Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 61546162.
- [56] K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang et al., “Hybrid task cascade for instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4974–4983.
- [57] X. Xu, Y. Jiang, W. Chen, Y. Huang, Y. Zhang, and X. Sun, “DAMOYOLO: A report on real-time object detection design,” arXiv preprint arXiv:2211.15444, 2022.
- [58] Z. Sun, M. Lin, X. Sun, Z. Tan, H. Li, and R. Jin, “MAE-Det: Revisiting maximum entropy principle in zero-shot nas for efficient object detection,” in Proceedings of the International Conference on Machine Learning (ICML), 2022.
- [59] Y. Jiang, Z. Tan, J. Wang, X. Sun, M. Lin, and H. Li, “GiraffeDet: A heavy-neck paradigm for object detection,” in The International Conference on Learning Representations (ICLR), 2022.
- [60] T. Cheng, L. Song, Y. Ge, W. Liu, X. Wang, and Y. Shan, “YOLOWorld: Real-time open-vocabulary object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 16 901–16 911.
- [61] super gradients, “YOLO-NAS,” https://github.com/Deci-AI/ super-gradients/blob/master/YOLONAS.md, 2023.
- [62] C. Wang, W. He, Y. Nie, J. Guo, C. Liu, K. Han, and Y. Wang, “GoldYOLO: Efficient object detector via gather-and-distribute mechanism,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [63] Y. Chen, Q. Chen, Q. Hu, and J. Cheng, “DATE: Dual assignment for end-to-end fully convolutional object detection,” arXiv preprint arXiv:2211.13859, 2022.
- [64] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalable object detection using deep neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 2147–2154.
- [65] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, “Overfeat: Integrated recognition, localization and detection using convolutional networks,” in The International Conference on Learning Representations (ICLR), 2014.
- [66] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [67] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in The International Conference on Learning Representations (ICLR), 2021.
- [68] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Proceedings of the European conference on computer vision (ECCV), 2020, pp. 213–229.
- [69] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017.
- [70] F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini, “The graph neural network model,” IEEE Transactions on Neural Networks, vol. 20, no. 1, pp. 61–80, 2008.
- [71] A. Tavanaei, M. Ghodrati, S. R. Kheradpisheh, T. Masquelier, and A. Maida, “Deep learning in spiking neural networks,” Neural Networks, vol. 111, pp. 47–63, 2019.
- [72] A. Gu and T. Dao, “MAMBA: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023.
- [73] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT: Real-time instance segmentation,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 9157–9166.
- [74] Z. Wang, L. Zheng, Y. Liu, Y. Li, and S. Wang, “Towards real-time multi-object tracking,” in Proceedings of the European conference on computer vision (ECCV), 2020, pp. 107–122.
- [75] Guanghan, “ROLO,” https://github.com/Guanghan/ROLO, 2016.
- [76] C. Liang, Z. Zhang, X. Zhou, B. Li, S. Zhu, and W. Hu, “Rethinking the competition between detection and reid in multiobject tracking,” IEEE Transactions on Image Processing (TIP), vol. 31, pp. 3182–3196, 2022.
- [77] N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in IEEE International Conference on Image Processing (ICIP), 2017, pp. 3645–3649.
- [78] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [79] Y. Zhang, C. Wang, X. Wang, W. Zeng, and W. Liu, “FairMOT: On the fairness of detection and re-identification in multiple object tracking,” International Journal of Computer Vision (IJCV), vol. 129, pp. 30693087, 2021.
- [80] H. Liu, R. A. R. Soto, F. Xiao, and Y. J. Lee, “YOLACTEdge: Real-time instance segmentation on the edge,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 9579–9585.
- [81] C. Zhou, “YOLACT++ better real-time instance segmentation,” IEEE transactions on pattern analysis and machine intelligence, 2022.
- [82] E. Mohamed, A. Shaker, A. El-Sallab, and M. Hadhoud, “Insta-YOLO: Real-time instance segmentation,” arXiv preprint arXiv:2102.06777, 2021.
- [83] P. Hurtik, V. Molek, J. Hula, M. Vajgl, P. Vlasanek, and T. Nejezchleba, “Poly-YOLO: higher speed, more precise detection and instance segmentation for YOLOv3,” Neural Computing and Applications, vol. 34, no. 10, pp. 8275–8290, 2022.
- [84] D. Wu, M.-W. Liao, W.-T. Zhang, X.-G. Wang, X. Bai, W.-Q. Cheng, and W.-Y. Liu, “YOLOP: You only look once for panoptic driving perception,” Machine Intelligence Research, vol. 19, no. 6, pp. 550562, 2022.
- [85] C. Han, Q. Zhao, S. Zhang, Y. Chen, Z. Zhang, and J. Yuan, “YOLOPv2: Better, faster, stronger for panoptic driving perception,” arXiv preprint arXiv:2208.11434, 2022.
- [86] J. Zhan, J. Liu, Y. Wu, and C. Guo, “Multi-task visual perception for object detection and semantic segmentation in intelligent driving,” Remote Sensing, vol. 16, no. 10, p. 1774, 2024.
- [87] D. Vu, B. Ngo, and H. Phan, “HybridNets: End-to-end perception network,” arXiv preprint arXiv:2203.09035, 2022.
- [88] J. Zhan, Y. Luo, C. Guo, Y. Wu, J. Meng, and J. Liu, “YOLOPX: Anchor-free multi-task learning network for panoptic driving perception,” Pattern Recognition, vol. 148, p. 110152, 2024.
- [89] W. McNally, K. Vats, A. Wong, and J. McPhee, “Rethinking keypoint representations: Modeling keypoints and poses as objects for multiperson human pose estimation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 37–54.
- [90] M. Simony, S. Milzy, K. Amendey, and H.-M. Gross, “ComplexYOLO: An Euler-region-proposal for real-time 3D object detection on point clouds,” in Proceedings of the European Conference on Computer Vision Workshops (ECCVW), 2018.
- [91] M. Takahashi, Y. Ji, K. Umeda, and A. Moro, “Expandable YOLO: 3D object detection from RGB-D images,” in International Conference on Research and Education in Mechatronics (REM), 2020, pp. 1–5.
- [92] B. Tekin, S. N. Sinha, and P. Fua, “Real-time seamless single shot 6D object pose prediction,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 292301.
- [93] ruhyadi, “YOLO3D,” https://github.com/ruhyadi/YOLO3D, 2022.
- [94] Y. Shi, N. Wang, and X. Guo, “YOLOV: Making still image object detectors great at video object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 37, no. 2, 2023, pp. 2254–2262.
- [95] Y. Shi, T. Zhang, and X. Guo, “Practical video object detection via feature selection and aggregation,” arXiv preprint arXiv:2407.19650, 2024.
- [96] J. Yang, S. Liu, Z. Li, X. Li, and J. Sun, “Real-time object detection for streaming perception,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 53855395.
- [97] W. Chen, H. Huang, S. Peng, C. Zhou, and C. Zhang, “YOLO-Face: a real-time face detector,” The Visual Computer, vol. 37, pp. 805–813, 2021.
- [98] Z. Yu, H. Huang, W. Chen, Y. Su, Y. Liu, and X. Wang, “YOLOFacev2: A scale and occlusion aware face detector,” Pattern Recognition, vol. 155, p. 110714, 2024.
- [99] D. Qi, W. Tan, Q. Yao, and J. Liu, “YOLO5Face: Why reinventing a face detector,” in Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 228–244.
- [100] X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,” arXiv preprint arXiv:2306.12156, 2023.
- [101] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2023, pp. 4015–4026.
- [102] M. E. A. Boudjoghra, A. Dai, J. Lahoud, H. Cholakkal, R. M. Anwer, S. Khan, and F. S. Khan, “Open-YOLO 3D: Towards fast and accurate open-vocabulary 3D instance segmentation,” arXiv preprint arXiv:2406.02548, 2024.
- [103] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International Conference on Machine Learning (ICML), 2021, pp. 8748–8763.
- [104] Z. Zhang, X. Lu, G. Cao, Y. Yang, L. Jiao, and F. Liu, “ViT-YOLO: Transformer-based YOLO for object detection,” in Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 2799–2808.
- [105] H. Ouyang, “DEYO: DETR with YOLO for step-by-step object detection,” arXiv preprint arXiv:2211.06588, 2022.
- [106] ——, “DEYOv2: Rank feature with greedy matching for end-to-end object detection,” arXiv preprint arXiv:2306.09165, 2023.
- [107] ——, “DEYOv3: DETR with YOLO for real-time object detection,” arXiv preprint arXiv:2309.11851, 2023.
- [108] ——, “DEYO: DETR with YOLO for end-to-end object detection,” arXiv preprint arXiv:2402.16370, 2024.
- [109] Z. Wang, C. Li, H. Xu, and X. Zhu, “Mamba YOLO: SSMs-based YOLO for object detection,” arXiv preprint arXiv:2406.05835, 2024.
- [110] S. Kim, S. Park, B. Na, and S. Yoon, “Spiking-YOLO: spiking neural network for energy-efficient object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 34, no. 07, 2020, pp. 11 270–11 277.
- [111] M. Gong, R. Liu, and V. K. Asari, “YOLO-based GNN for multiperson pose estimation,” in Pattern Recognition and Tracking XXXV, vol. 13040, 2024, pp. 124–131.
- [112] P. Chen, Y. Wang, and H. Liu, “GCN-YOLO: YOLO based on graph convolutional network for SAR vehicle target detection,” IEEE Geoscience and Remote Sensing Letters, 2024.
- [113] danielsyahputra, “KAN-YOLO,” https://github.com/danielsyahputra/ ultralytics, 2024.