疑问
在之前的学习中,只提到BIO是阻塞IO,在建立连接和读写事件时会阻塞线程。NIO是非阻塞IO,基于事件注册,通过Selector进行切换Channel,不会阻塞线程。对于这种解释,还是带有一些疑问的。Selector进行Channel的切换,是不阻塞线程了,但是Channel与操作系统之间的数据交换,是否阻塞线程呢?带着这种疑问,进一步理解了NIO知识,下面记录一下。
BIO的阻塞
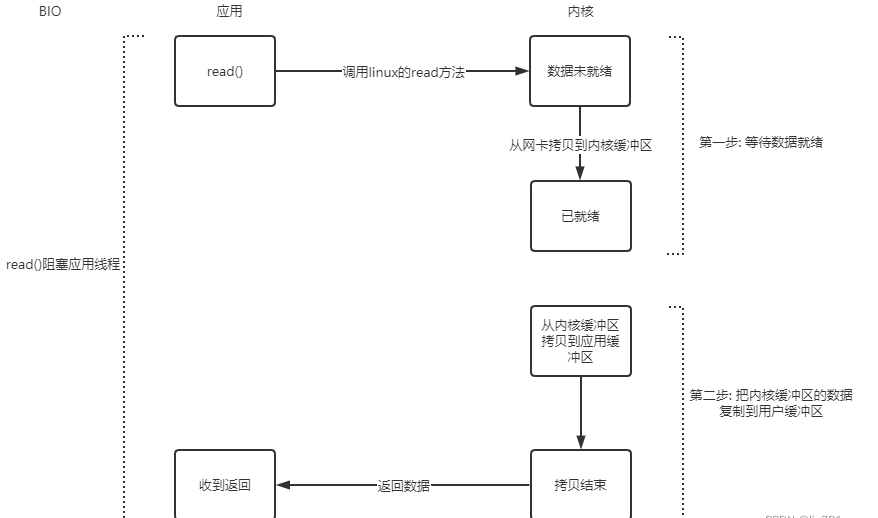
应用程序采用BIO方式调用read()方法后,底层调用Linux系统的read方法,从内核缓冲区读取数据,如果内核缓冲区没有数据,那么该线程就一直阻塞,等到有数据,执行第二步,从内核缓冲区复制到用户缓冲区,然后返回数据。这两步全程阻塞。因此,使用BIO后,每个线程只要调用了read()方法,就会阻塞。这就是BIO的阻塞原理。
NIO的非阻塞
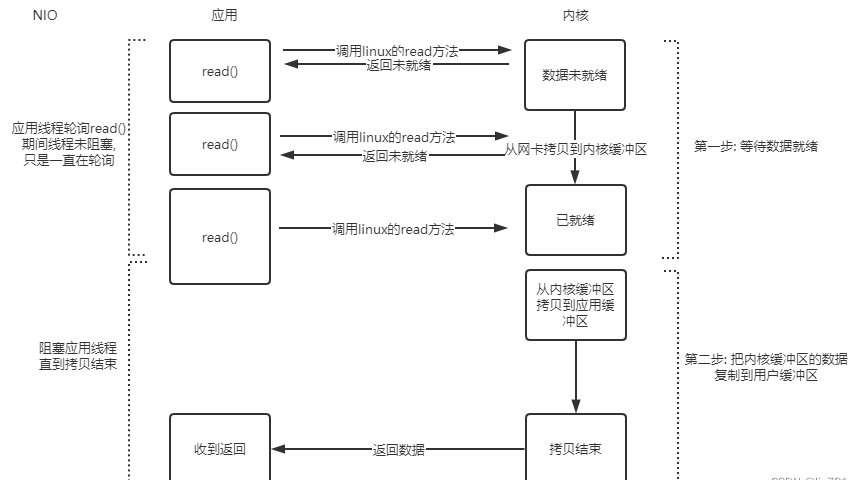
Linux系统提供了非阻塞的read()方法,NIO就是调用了这个方法,当内核缓冲区没有数据时,read()方法立即返回未就绪,不会阻塞线程。因此,应用程序需要轮询调用read()方法,直到有数据返回。所以,此步骤是非阻塞的。当内核缓冲区有数据时,调用read()方法,则从内核缓冲区复制数据到用户缓冲区,此步骤是阻塞执行的。这就是NIO的非阻塞原理。
那么NIO的非阻塞有何好处呢?好处就是当我们调用read()方法时,如果还没有数据,那么立即返回,不会阻塞线程,我们可以做一下其他的逻辑操作,然后过一段时间后,再调用read()方法,去获取数据,不至于一直在read()方法那里阻塞着,浪费了这个线程,什么都做不了。
NIO+IO多路复用
上面的NIO中,我们用轮询来多次调用read()方法,直到获取到读取的数据。而轮询带来的弊端就是CPU占用过高。因为提出了使用Linux系统提供的IO多路复用,来解决轮询带来的问题。
IO多路复用是一种同步IO模型, 是操作系统提供的能力, 使用少量线程监听Linux的多个IO文件描述符, 也就是线程复用于多个IO请求.
如果有任意IO文件描述符就绪, 就会告知应用进行读取,
如果没有IO文件描述符就绪, 就会阻塞应用线程.
Linux中, IO多路复用的实现是select/poll/epoll
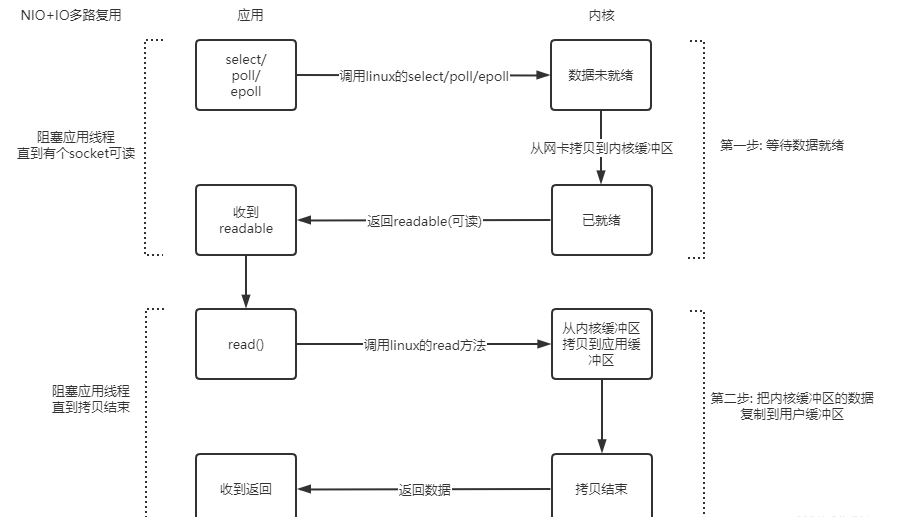
Linux提供的IO多路复用,可以用最少的线程,来处理多个IO请求。因此,在第一个阶段,使用Linux的多路复用机制,用很少的线程去监测多个IO连接。当监测的IO连接都没有发生IO事件时,监测线程也会发生阻塞。当某个连接发生IO事件后,通知应用程序有数据可读,此时应用程序才会调用read()方法。
调用read()方法后,就和上面NIO的操作一样了,从内核缓冲区复制到用户缓冲区,返回给应用程序,此过程是阻塞的。
上面提到,当被监测的请求没有发生IO事件时,也是阻塞的,那和BIO的阻塞有何区别呢?
在NIO+多路复用中,使用了Linux的多路复用机制,很少的线程就可以监测多个IO事件,而且是专门的线程去监测IO事件。即使在监测阶段发生阻塞,也是很少的线程被阻塞,且应用程序的线程不会被阻塞,不影响应用程序的运行。而BIO的阻塞是对应用程序的阻塞。这样区别就很明显了。所以NIO+IO多路复用是网络连接中提高性能的解决方案。
在之前写到的java提供的NIO的API,就是采用了NIO+IO多路复用的机制实现的。
Liunx的epoll
简单来说就是采用注册回调机制, 替代了轮询遍历,利用mmap减少了文件描述符在用户空间和内核空间的拷贝,因此性能高。具体详情另作研究。
参考文章:彻底理解非阻塞IO(NIO)