本专栏内容为:Linux学习专栏,分为系统和网络两部分。 通过本专栏的深入学习,你可以了解并掌握Linux。
💓博主csdn个人主页:小小unicorn
⏩专栏分类:网络
🚚代码仓库:小小unicorn的代码仓库🚚
🌹🌹🌹关注我带你学习编程知识
网络编程套接字 (一)
- 理解源IP地址和目的IP地址
- 理解源MAC地址和目的MAC地址
- 理解源端口号和目的端口号
- socket通信的本质
- 端口号
- 理解socket这个名字
- PORT VS PID
- 底层如何通过port找到对应进程的?
- 认识TCP协议和UDP协议
- TCP协议
- UDP协议
- 既然UDP协议是不可靠的,那为什么还要有UDP协议的存在?
- 网络字节序
- 网络中的大小端问题
- 为什么网络字节序采用的是大端?而不是小端?
- socket编程接口
- socket常见API
- sockaddr结构
- sockaddr结构的出现
- 为什么会有这么多本地进程间通信的方式?
- 为什么没有用``void*``代替``struct sockaddr*``类型?
理解源IP地址和目的IP地址
因特网上的每台计算机都有一个唯一的IP地址,如果一台主机上的数据要传输到另一台主机,那么对端主机的IP地址就应该作为该数据传输时的目的IP地址。但仅仅知道目的IP地址是不够的,当对端主机收到该数据后,对端主机还需要对该主机做出响应,因此对端主机也需要发送数据给该主机,此时对端主机就必须知道该主机的IP地址。因此一个传输的数据当中应该涵盖其源IP地址和目的IP地址,目的IP地址表明该数据传输的目的地,源IP地址作为对端主机响应时的目的IP地址。
在数据进行传输之前,会先自顶向下贯穿网络协议栈完成数据的封装,其中在网络层封装的IP报头当中就涵盖了源IP地址和目的IP地址。而除了源IP地址和目的IP地址之外,还有源MAC地址和目的MAC地址的概念。
理解源MAC地址和目的MAC地址
大部分数据的传输都是跨局域网的,数据在传输过程中会经过若干个路由器,最终才能到达对端主机。
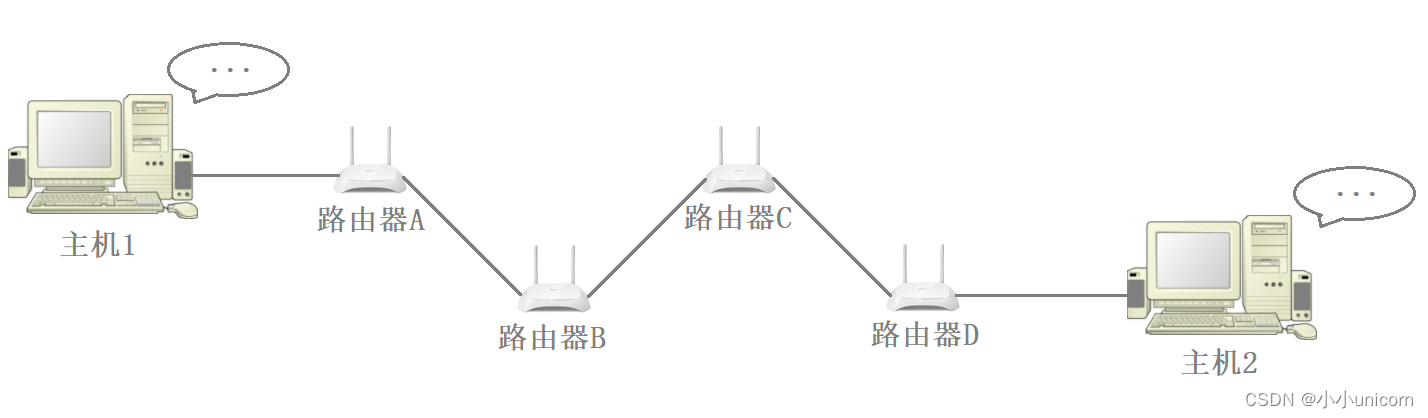
源MAC地址和目的MAC地址是包含在链路层的报头当中的,而MAC地址实际只在当前局域网内有效,因此当数据跨网络到达另一个局域网时,其源MAC地址和目的MAC地址就需要发生变化,因此当数据达到路由器时,路由器会将该数据当中链路层的报头去掉,然后再重新封装一个报头,此时该数据的源MAC地址和目的MAC地址就发生了变化。
例如,在图中主机1向主机2发送数据的过程中,数据的源MAC地址和目的MAC地址的变化过程如下:
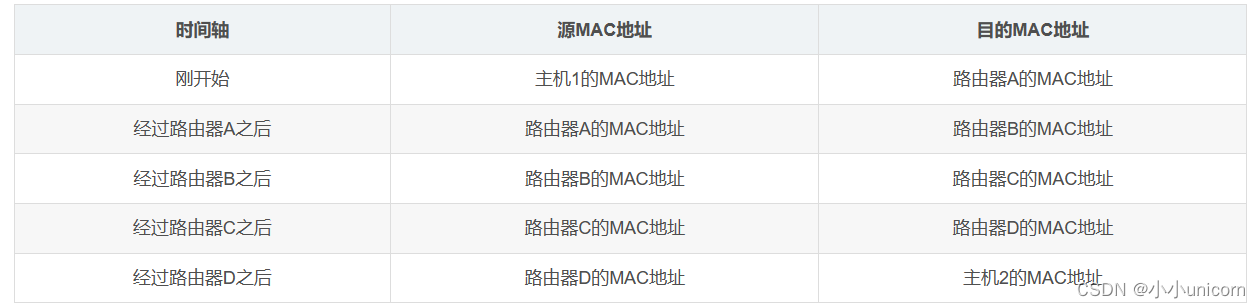
因此数据在传输的过程中是有两套地址:
1. 一套是源IP地址和目的IP地址,这两个地址在数据传输过程中基本是不会发生变化的(存在一些特殊情况,比如在数据传输过程中使用NET技术,其源IP地址会发生变化,但至少目的IP地址是不会变化的)。
2. 另一套就是源MAC地址和目的MAC地址,这两个地址是一直在发生变化的,因为在数据传输的过程中路由器不断在进行解包和重新封装。
理解源端口号和目的端口号
首先我们需要明确的是,两台主机之间通信的目的不仅仅是为了将数据发送给对端主机,而是为了访问对端主机上的某个服务。比如我们在用百度搜索引擎进行搜索时,不仅仅是想将我们的请求发送给对端服务器,而是想访问对端服务器上部署的百度相关的搜索服务。
socket通信的本质
现在通过IP地址和MAC地址已经能够将数据发送到对端主机了,但实际我们是想将数据发送给对端主机上的某个服务进程,此外,数据的发送者也不是主机,而是主机上的某个进程,比如当我们用浏览器访问数据时,实际就是浏览器进程向对端服务进程发起的请求。
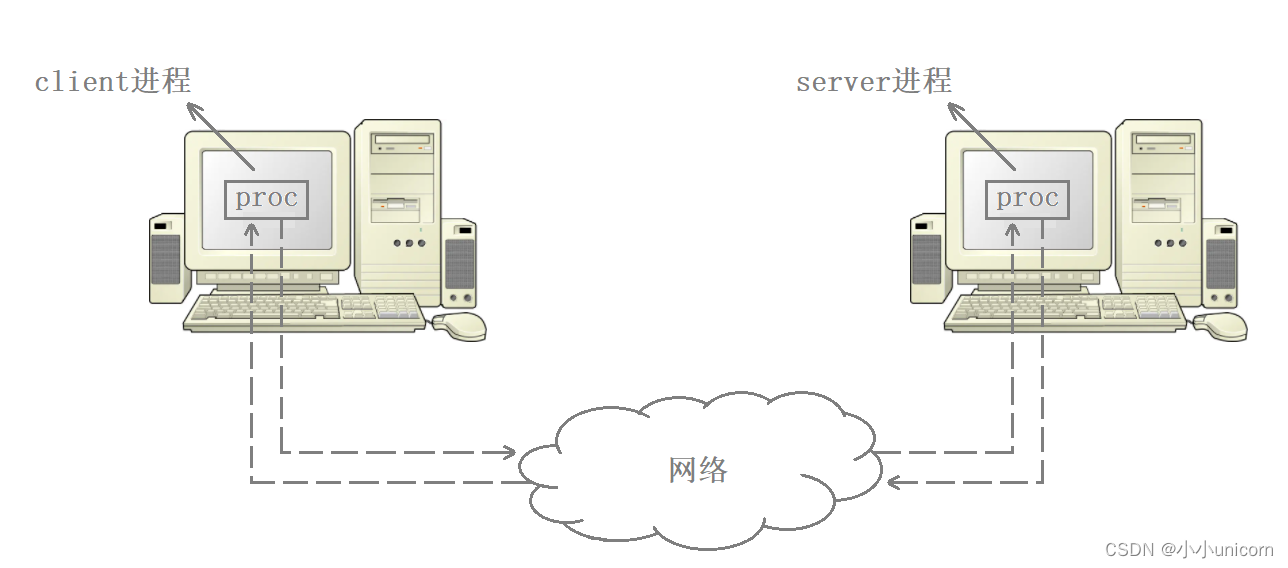
也就是说,socket通信本质上就是两个进程之间在进行通信,只不过这里是跨网络的进程间通信。比如逛淘宝和刷抖音的动作,实际就是手机上的淘宝进程和抖音进程在和对端服务器主机上的淘宝服务进程和抖音服务进程之间在进行通信。
因此进程间通信的方式除了管道、消息队列、信号量、共享内存等方式外,还有套接字,只不过前者是不跨网络的,而后者是跨网络的。
端口号
实际在两台主机上,可能会同时存在多个正在进行跨网络通信的进程,因此当数据到达对端主机后,必须要通过某种方法找到该主机上对应的服务进程,然后将数据交给该进程处理。而当该进程处理完数据后还要对发送端进行响应,因此对端主机也需要知道,是发送端上的哪一个进程向它发送的数据请求。
端口号(port)的作用实际就是标识一台主机上的一个进程。
1. 端口号是传输层协议的内容。
2. 端口号是一个2字节16位的整数。
3. 端口号用来标识一个进程,告诉操作系统,当前的这个数据要交给哪一个进程来处理。
4. 一个端口号只能被一个进程占用。
由于IP地址能够唯一标识公网内的一台主机,而端口号能够唯一标识一台主机上的一个进程,因此用IP地址+端口号就能够唯一标识网络上的某一台主机的某一个进程。
当数据在传输层进行封装时,就会添加上对应源端口号和目的端口号的信息。这时通过源IP地址+源端口号就能够在网络上唯一标识发送数据的进程,通过目的IP地址+目的端口号就能够在网络上唯一标识接收数据的进程,此时就实现了跨网络的进程间通信。
注意: 因为端口号是隶属于某台主机的,所以端口号可以在两台不同的主机当中重复,但是在同一台主机上进行网络通信的进程的端口号不能重复。此外,一个进程可以绑定多个端口号,但是一个端口号不能被多个进程同时绑定。
理解socket这个名字
socket在英文上有“插座”的意思,插座上有不同规格的插孔,我们将插头插入到对应的插孔当中就能够实现电流的传输。
在进行网络通信时,客户端就相当于插头,服务端就相当于一个插座,但服务端上可能会有多个不同的服务进程(多个插孔),因此当我们在访问服务时需要指明服务进程的端口号(对应规格的插孔),才能享受对应服务进程的服务。
PORT VS PID
端口号(port)的作用唯一标识一台主机上的某个进程,进程ID(PID)的作用也是唯一标识一台主机上的某个进程,那在进行网络通信时为什么不直接用PID来代替port呢?
进程ID(PID)是用来标识系统内所有进程的唯一性的,它是属于系统级的概念;而端口号(port)是用来标识需要对外进行网络数据请求的进程的唯一性的,它是属于网络的概念。
一台机器上可能会有大量的进程,但并不是所有的进程都要进行网络通信,可能有很大一部分的进程是不需要进行网络通信的本地进程,此时PID虽然也可以标识这些网络进程的唯一性,但在该场景下就不太合适了。
比如每个人都有自己的身份证号,身份证号已经可以标识我们的唯一性了,但是当我们到了学校还是会有学号,到了公司还是会有工号。这是为什么呢?为什么不直接用身份证号来代替学号和工号呢?
因为身份证号是国家用于行政管理时用的编号,而学号是学校用于管理学生时用的编号,工号是公司用于管理员工时用的编号。但并不是全中国人都在某所学校或某家公司,因此在学校或公司当中,没必要用身份证号来标识每个人的唯一性。此时就出现了学号和工号,在学号和工号当中还可以包含一些便于管理的信息,比如入学(入职)年份、性别等信息。
也就是说,在不同的场景下可能需要不同的编号来标识某种事物的唯一性,因为这些编号更适合用于该场景。
底层如何通过port找到对应进程的?
实际底层采用哈希的方式建立了端口号和进程PID或PCB之间的映射关系,当底层拿到端口号时就可以直接执行对应的哈希算法,然后就能够找到该端口号对应的进程。
认识TCP协议和UDP协议
网络协议栈是贯穿整个体系结构的,在应用层、操作系统层和驱动层各有一部分。当我们使用系统调用接口实现网络数据通信时,不得不面对的协议层就是传输层,而传输层最典型的两种协议就是TCP协议和UDP协议。
TCP协议
TCP协议叫做传输控制协议(Transmission Control Protocol),TCP协议是一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP协议是面向连接的,如果两台主机之间想要进行数据传输,那么必须要先建立连接,当连接建立成功后才能进行数据传输。其次,TCP协议是保证可靠的协议,数据在传输过程中如果出现了丢包、乱序等情况,TCP协议都有对应的解决方法。
UDP协议
UDP协议叫做用户数据报协议(User Datagram Protocol),UDP协议是一种无需建立连接的、不可靠的、面向数据报的传输层通信协议。
使用UDP协议进行通信时无需建立连接,如果两台主机之间想要进行数据传输,那么直接将数据发送给对端主机就行了,但这也就意味着UDP协议是不可靠的,数据在传输过程中如果出现了丢包、乱序等情况,UDP协议本身是不知道的。
既然UDP协议是不可靠的,那为什么还要有UDP协议的存在?
TCP协议是一种可靠的传输协议,使用TCP协议能够在一定程度上保证数据传输时的可靠性,而UDP协议是一种不可靠的传输协议,UDP协议的存在有什么意义?
首先,可靠是需要我们做更多的工作的,TCP协议虽然是一种可靠的传输协议,但这一定意味着TCP协议在底层需要做更多的工作,因此TCP协议底层的实现是比较复杂的,我们不能只看到TCP协议面向连接可靠这一个特点,我们也要能看到TCP协议对应的缺点。
同样的,UDP协议虽然是一种不可靠的传输协议,但这一定意味着UDP协议在底层不需要做过多的工作,因此UDP协议底层的实现一定比TCP协议要简单,UDP协议虽然不可靠,但是它能够快速的将数据发送给对方,虽然在数据在传输的过程中可能会出错。
编写网络通信代码时具体采用TCP协议还是UDP协议,完全取决于上层的应用场景。如果应用场景严格要求数据在传输过程中的可靠性,此时我们就必须采用TCP协议,如果应用场景允许数据在传输出现少量丢包,那么我们肯定优先选择UDP协议,因为UDP协议足够简单。
注意: 一些优秀的网站在设计网络通信算法时,会同时采用TCP协议和UDP协议,当网络流畅时就使用UDP协议进行数据传输,而当网速不好时就使用TCP协议进行数据传输,此时就可以动态的调整后台数据通信的算法。
网络字节序
网络中的大小端问题
计算机在存储数据时是有大小端的概念的:
1. 大端模式: 数据的高字节内容保存在内存的低地址处,数据的低字节内容保存在内存的高地址处。
2. 小端模式: 数据的高字节内容保存在内存的高地址处,数据的低字节内容保存在内存的低地址处。
如果编写的程序只在本地机器上运行,那么是不需要考虑大小端问题的,因为同一台机器上的数据采用的存储方式都是一样的,要么采用的都是大端存储模式,要么采用的都是小端存储模式。但如果涉及网络通信,那就必须考虑大小端的问题,否则对端主机识别出来的数据可能与发送端想要发送的数据是不一致的。
例如,现在两台主机之间在进行网络通信,其中发送端是小端机,而接收端是大端机。发送端将发送缓冲区中的数据按内存地址从低到高的顺序发出后,接收端从网络中获取数据依次保存在接收缓冲区时,也是按内存地址从低到高的顺序保存的。

但由于发送端和接收端采用的分别是小端存储和大端存储,此时对于内存地址从低到高为44332211的序列,发送端按小端的方式识别出来是0x11223344,而接收端按大端的方式识别出来是0x44332211,此时接收端识别到的数据与发送端原本想要发送的数据就不一样了,这就是由于大小端的偏差导致数据识别出现了错误。
由于我们不能保证通信双方存储数据的方式是一样的,因此网络当中传输的数据必须考虑大小端问题。因此TCP/IP协议规定,网络数据流采用大端字节序,即低地址高字节。无论是大端机还是小端机,都必须按照TCP/IP协议规定的网络字节序来发送和接收数据。
1. 如果发送端是小端,需要先将数据转成大端,然后再发送到网络当中。
2. 如果发送端是大端,则可以直接进行发送。
3. 如果接收端是小端,需要先将接收到数据转成小端后再进行数据识别。
4. 如果接收端是大端,则可以直接进行数据识别。
在这个例子中,由于发送端是小端机,因此在发送数据前需要先将数据转成大端,然后再发送到网络当中,而由于接收端是大端机,因此接收端接收到数据后可以直接进行数据识别,此时接收端识别出来的数据就与发送端原本想要发送的数据相同了。
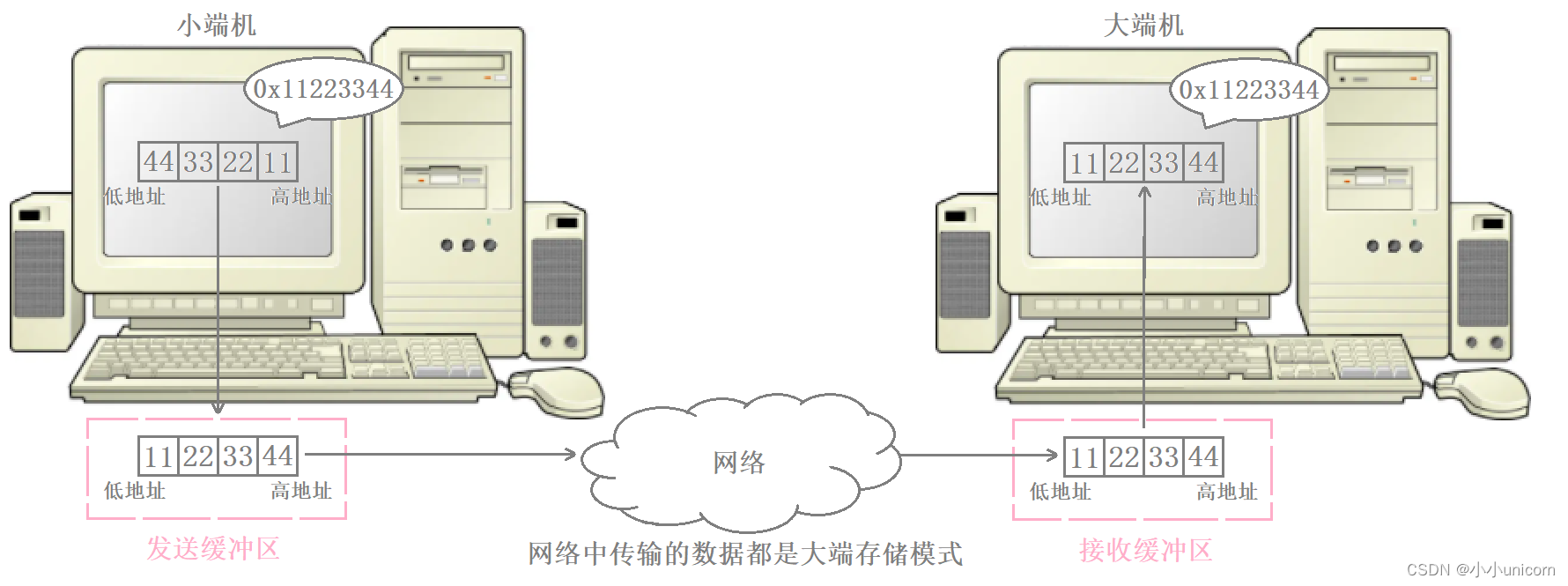
需要注意的是,所有的大小端的转化工作是由操作系统来完成的,因为该操作属于通信细节,不过也有部分的信息需要我们自行进行处理,比如端口号和IP地址。
为什么网络字节序采用的是大端?而不是小端?
网络字节序采用的是大端,而主机字节序一般采用的是小端,那为什么网络字节序不采用小端呢?如果网络字节序采用小端的话,发送端和接收端在发生和接收数据时就不用进行大小端的转换了。
该问题有很多不同说法,下面列举了两种说法:
1. TCP在Unix时代就有了,以前Unix机器都是大端机,因此网络字节序也就采用的是大端,但之后人们发现用小端能简化硬件设计,所以现在主流的都是小端机,但协议已经不好改了。
2. 大端序更符合现代人的读写习惯。
网络字节序与主机字节序之间的转换
为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序之间的转换。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
1. 函数名当中的h表示host,n表示network,l表示32位长整数,s表示16位短整数。
2. 例如htonl表示将32位长整数从主机字节序转换为网络字节序。
3. 如果主机是小端字节序,则这些函数将参数做相应的大小端转换然后返回。
4. 如果主机是大端字节序,则这些函数不做任何转换,将参数原封不动地返回。
socket编程接口
socket常见API
创建套接字:(TCP/UDP,客户端+服务器)
int socket(int domain, int type, int protocol);
绑定端口号:(TCP/UDP,服务器)
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
监听套接字:(TCP,服务器)
int listen(int sockfd, int backlog);
接收请求:(TCP,服务器)
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
建立连接:(TCP,客户端)
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockaddr结构
sockaddr结构的出现
套接字不仅支持跨网络的进程间通信,还支持本地的进程间通信(域间套接字)。在进行跨网络通信时我们需要传递的端口号和IP地址,而本地通信则不需要,因此套接字提供了sockaddr_in结构体和sockaddr_un结构体,其中sockaddr_in结构体是用于跨网络通信的,而sockaddr_un结构体是用于本地通信的。
为了让套接字的网络通信和本地通信能够使用同一套函数接口,于是就出现了sockeaddr结构体,该结构体与sockaddr_in和sockaddr_un的结构都不相同,但这三个结构体头部的16个比特位都是一样的,这个字段叫做协议家族。

此时当我们在传递在传参时,就不用传入sockeaddr_in或sockeaddr_un这样的结构体,而统一传入sockeaddr这样的结构体。在设置参数时就可以通过设置协议家族这个字段,来表明我们是要进行网络通信还是本地通信,在这些API内部就可以提取sockeaddr结构头部的16位进行识别,进而得出我们是要进行网络通信还是本地通信,然后执行对应的操作。此时我们就通过通用sockaddr结构,将套接字网络通信和本地通信的参数类型进行了统一。
注意: 实际我们在进行网络通信时,定义的还是sockaddr_in这样的结构体,只不过在传参时需要将该结构体的地址类型进行强转为sockaddr*罢了。
为什么会有这么多本地进程间通信的方式?
本地进程间通信的方式已经有管道、消息队列、共享内存、信号量等方式了,现在在套接字这里又出现了可以用于本地进程间通信的域间套接字,为什么会有这么多通信方式,并且这些通信方式好像并不相关?
实际是因为早期有很多不同的实验室都在研究通信的方式,由于是不同的实验室,因此就出现了很多不同的通信方式,比如常见的有System V标准的通信方式和POSIX标准的通信方式。
IPv4和IPv6的地址格式定义在netinet/in.h中,IPv4地址用sockaddr_in结构体表示,包括16位地址类型,16位端口号和32位IP地址。IPv4、IPv6地址类型分别定义为常数AF_INET、AF_INET6。这样,只要取得某种sockaddr结构体的首地址,不需要知道具体是哪种类型的sockaddr结构体,就可以根据地址类型字段确定结构体中的内容。socket API可以都用struct sockaddr*类型表示,在使用的时候需要强制转化成sockaddr_in;这样的好处是程序的通用性,可以接收IPv4、IPv6,以及UNIX Domain Socket各种类型的sockaddr结构体指针做为参数。
为什么没有用void*代替struct sockaddr*类型?
我们可以将这些函数的struct sockaddr*参数类型改为void*,此时在函数内部也可以直接指定提取头部的16个比特位进行识别,最终也能够判断是需要进行网络通信还是本地通信,那为什么还要设计出sockaddr这样的结构呢?
实际在设计这一套网络接口的时候C语言还不支持void*,于是就设计出了sockaddr这样的解决方案。并且在C语言支持了void*之后也没有将它改回来,因为这些接口是系统接口,系统接口是所有上层软件接口的基石,系统接口是不能轻易更改的,否则引发的后果是不可想的,这也就是为什么现在依旧保留sockaddr结构的原因。