文章目录
- XXL-JOB 介绍
- 分布式任务调度
- XXL-JOB 概述
- 快速入门
- 下载源码
- 初始化调度数据库
- 编译源码
- 调度中心
- 调度中心介绍
- 配置调度中心
- 部署调度中心
- 集群部署调度中心(可选)
- Docker 镜像方式搭建调度中心(可选)
- 执行器
- 执行器介绍
- 添加依赖
- 配置执行器
- 配置 XxlJobSpringExecutor
- 创建任务
- 简单任务(Bean 模式)
- 任务配置项
- Cron 表达式
- GLUE 模式(Java)
- 分片广播
- 任务参数接收
- 项目集成
XXL-JOB 介绍
分布式任务调度
在数字化转型的浪潮中,企业面临着需求的多样化和业务流程的复杂化。自动化任务调度能有效提升工作效率,确保业务流程的稳定性与准确性。以下三个业务场景将揭示任务调度在现代企业操作中的必要性:
- 一个电子商务平台需定时在一天中的三个固定时段发放优惠券,以吸引并保持顾客的购买兴趣。
- 银行系统必须提前三天通过短信提醒客户即将到期的信用卡账单,以避免逾期带来的不良影响。
- 财务系统需要在午夜时分快速准确地结算并总结前一天的财务数据,以保持财务流的及时性。
任务调度就是自动化执行这些重复且周期性任务的技术手段,它能够确保任务能够在预定的时间准确执行。
然而,使用 Spring 框架的 @Scheduled 注解来实现任务调度虽然简便,但在任务规模扩大后,它的局限性也逐渐显露。
来看下面的一段示例代码:
@Scheduled(cron = "0/20 * * * * ?")
public void doWork() {
// 执行任务的代码
}
这段代码能够实现简单的调度功能,但随着业务扩展,面对以下挑战,我们需要更为强大的分布式任务调度系统:
- 高可用性:当我们依赖单台机器执行所有任务时,一旦发生故障,整个系统的任务调度将完全瘫痪。分布式调度能够在多台机器间分配任务,即便某台机器出现问题,其他机器仍可继续执行任务,从而保障业务的持续运行。
- 避免任务重复执行:在多机部署环境中,如果不加控制,多台机器上的定时任务可能会同时执行同一任务,导致数据处理错误或资源浪费。分布式调度能够确保在任何时间点,一个任务只在一个节点上执行。
- 处理能力的提升:随着业务量的激增,单台机器可能无法在规定时间内完成任务处理,比如订单处理量的急剧增加或业务要求缩短数据处理时间。尽管通过增强单机的并发处理能力可以在一定程度上提高效率,但是机器的物理限制(如 CPU、内存和磁盘的容量)终究会成为瓶颈。分布式调度通过在多台机器间分配任务,可以显著提升整个系统的处理能力。
可见,随着企业业务量的增长和高效运作的需求,传统的单机任务调度方式已无法满足需求。而分布式任务调度系统,以其可扩展性、高可用性和高效处理能力,成为了实现自动化、高效业务流程的关键技术手段。
XXL-JOB 概述
官方文档:https://www.xuxueli.com/xxl-job/
XXL-JOB 作为一款轻量级的分布式任务调度平台,凭借其高效、易用、可扩展的特性,已经在众多知名企业中获得了广泛的应用和认可。
它的设计理念主要体现在以下几个方面:
- 调度与任务执行的解耦:通过将调度中心设计为一个独立的平台,它不直接参与任务的具体执行逻辑,而是专注于任务的调度。具体的任务执行则由分散的 JobHandler 完成,这些 JobHandler 由执行器统一管理。这种设计有效地实现了调度逻辑与业务逻辑的分离,增强了系统的灵活性和稳定性。
- 轻量级与易于扩展:XXL-JOB 的设计目标之一就是保持轻量级,这意味着它在实现功能的同时,尽量减少对系统资源的占用,保持高效运行。同时,它也强调易于扩展,无论是在增加新的任务类型、扩展执行器数量,还是在集成新的服务时,XXL-JOB 都能够提供便捷的支持。
- 高效的调度策略:XXL-JOB 支持多种调度策略,如 CRON 表达式调度、动态参数调度等,这些灵活的调度策略使得它能够满足不同场景下对任务调度的需求。此外,它还支持失败重试、执行器心跳检测等机制,确保任务调度的高效与稳定性。
- 方便的任务管理与监控:通过提供直观的 Web 界面,XXL-JOB 使得任务的管理和监控变得非常方便。用户可以在界面上轻松地添加、修改任务配置,监控任务执行情况,以及查看执行日志等,大大提升了任务管理的效率。
- 广泛的适用性:正如大众点评、京东等众多知名公司的采用所示,XXL-JOB 的设计适用于各种规模的企业,无论是中小企业的简单任务调度,还是大型企业复杂业务流程的管理,XXL-JOB 都能提供有效的解决方案。
在 XXL-JOB 官方文档中,也罗列了几十个特性,感兴趣的可以理解一下:

除此之外,一个优秀的开源框架必定有着活跃的社区,XXL-JOB 自然也有:(社区交流)
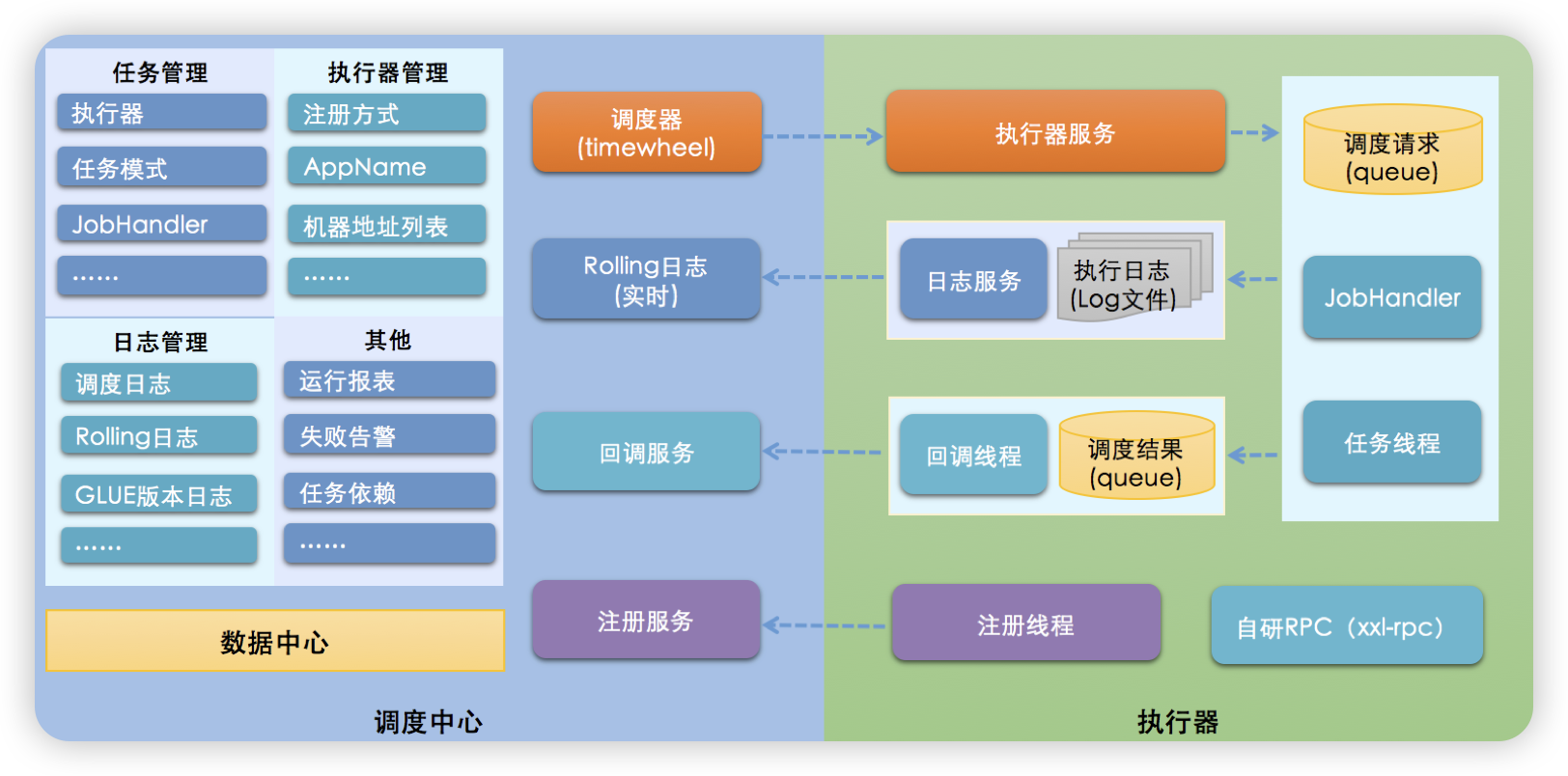
XXL-系统架构图如下:
快速入门
下载源码
源码下载地址:
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-job | Download |
| http://gitee.com/xuxueli0323/xxl-job | Download |
我们以目前最新的版本为例:

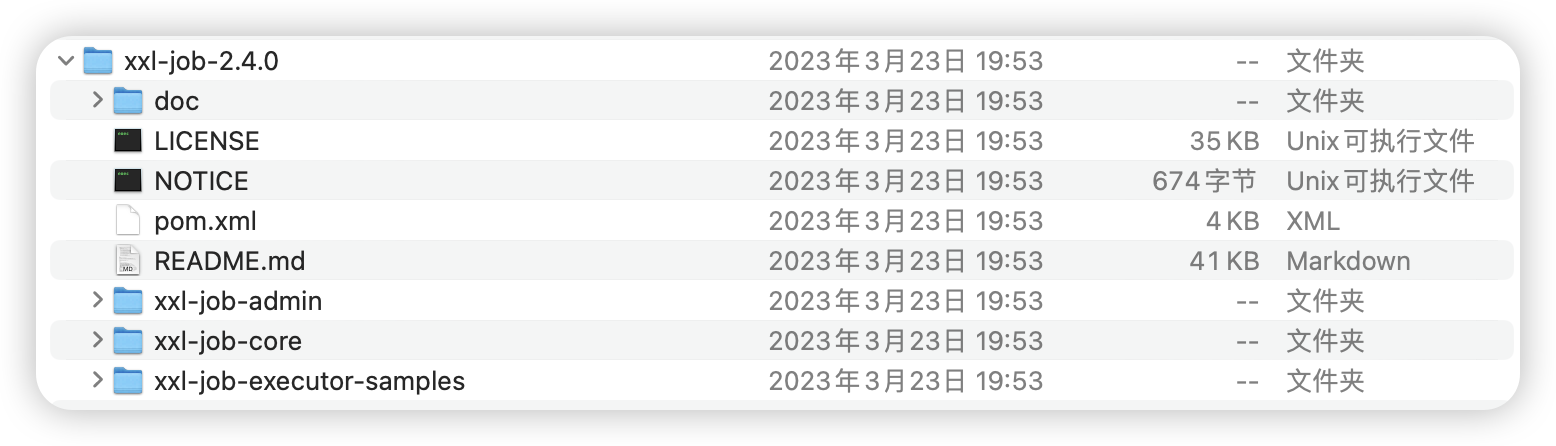
下载后解压到自定义目录即可:
初始化调度数据库
调度数据库初始化 SQL 脚本的位置在上面下载的 /xxl-job/doc/db 目录下:

新建一个数据库,这里就叫 xxl-job:

然后通过 【运行 SQL 文件…】执行上面的 SQL 脚本加载对应的数据库表即可:(也可以直接拖进去)
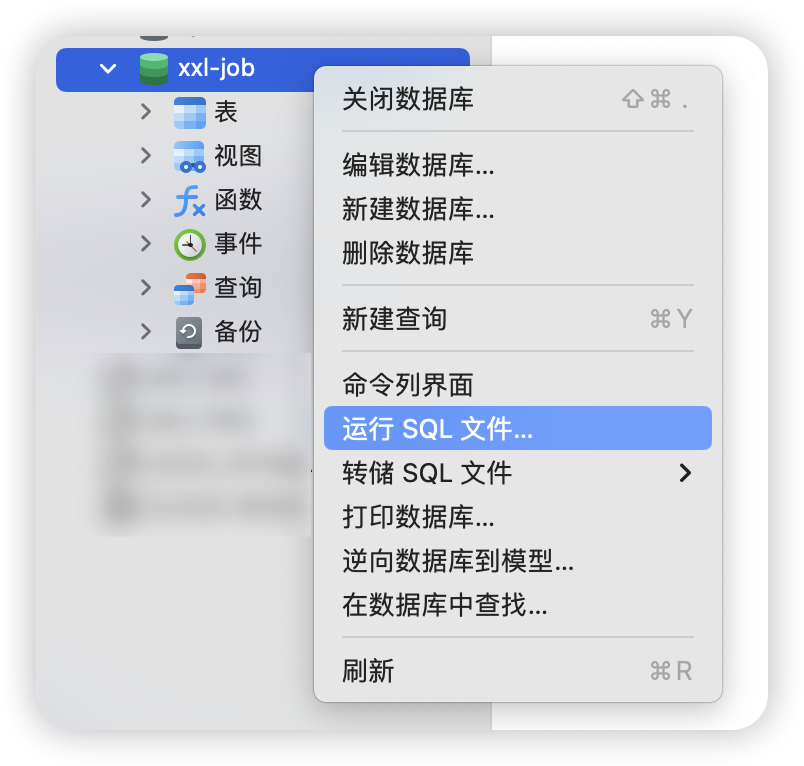
执行完成后我们就得到了下面的数据库表了:

⚠️ 注意:调度中心支持集群部署,集群情况下各节点务必连接同一个 MySQL 实例,如果 MySQL 做了主从架构,则调度中心集群节点务必强制走主库。
这里简单介绍一下上面的表:
xxl_job_info: 存储任务的基本信息,如任务描述、调度类型、执行器路由策略、任务参数等。xxl_job_log: 存储任务的执行日志,包括执行时间、执行结果、执行参数等信息。xxl_job_log_report: 存储任务执行的统计报告,如每天的运行次数、成功次数、失败次数等。xxl_job_logglue: 存储任务的 GLUE 代码历史版本,用于记录任务代码的变更历史。xxl_job_registry: 存储执行器的注册信息,用于执行器的自动发现和注册。xxl_job_group: 存储执行器的分组信息,一个执行器分组可以包含多个执行器实例。xxl_job_user: 存储系统的用户信息,用于系统的登录认证和权限控制。xxl_job_lock: 存储系统的锁信息,用于实现分布式锁,防止任务的重复执行。
编译源码
使用 IDEA 打开项目,进行编译即可:

项目整体结构如下:
(base) ➜ xxl-job-2.4.0 tree
.
├── LICENSE 声明文件
├── NOTICE 许可证
├── README.md 项目的简介、使用说明等信息
├── doc 文档目录,包含了项目的相关文档
│ ├── ...
│ ├── db
│ │ └── tables_xxl_job.sql 数据库初始化脚本,包含了创建数据库表的SQL语句
│ └── images 文档中使用的图片
│ ├── ...
├── pom.xml 项目的配置文件,定义了项目的构建、依赖等信息
├── xxl-job-admin XXL-JOB 的管理后台模块(调度中心)
│ ├── Dockerfile Docker 构建文件
│ ├── pom.xml
│ └── src 源代码目录
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── xxl
│ │ │ └── job
│ │ │ └── admin
│ │ │ ├── XxlJobAdminApplication.java Spring Boot 应用的入口类
│ │ │ ├── controller 存放控制器类,处理Web请求
│ │ │ │ ├── ...
│ │ │ ├── core 核心业务逻辑
│ │ │ │ ├── ...
│ │ │ ├── dao 数据访问对象,与数据库交互
│ │ │ │ ├── ...
│ │ │ └── service 服务层,封装业务逻辑
│ │ │ ├── ...
│ │ └── resources 资源目录,包含配置文件、静态资源等
│ │ ├── ...
├── xxl-job-core XXL-JOB 的核心模块,定义了任务执行器的相关接口和实现
│ ├── ...
└── xxl-job-executor-samples 包含了几个执行器的示例
├── pom.xml
├── xxl-job-executor-sample-frameless 无框架执行器示例
│ ├── ...
└── xxl-job-executor-sample-springboot Spring Boot 执行器示例
├── ...
调度中心
调度中心介绍
XXL-JOB 的调度中心是整个分布式任务调度系统的核心部分,它负责管理和调度所有的任务执行器(Executor)和任务(Job)。调度中心主要由 XXL-JOB-Admin 模块实现,提供了任务的管理、调度、监控等功能。
下面是调度中心的主要作用:
- 任务管理:调度中心提供了一个管理界面,允许用户添加、修改、删除任务,以及配置任务的执行参数、调度策略等信息。
- 任务调度:调度中心根据任务的调度策略(如 CRON 表达式)定时触发任务的执行。它会向执行器发送执行指令,让执行器执行相应的任务。
- 执行器管理:调度中心负责管理所有的执行器实例,包括执行器的注册、发现和状态监控。执行器会向调度中心注册自己的地址和能力信息,调度中心根据这些信息调度任务。
- 任务路由:调度中心支持多种执行器路由策略,如轮询、最少执行、故障转移等,以实现任务的负载均衡和高可用。
- 任务执行监控:调度中心记录任务的执行日志和结果,提供任务执行的实时监控和历史查询功能。用户可以通过管理界面查看任务的执行情况。
- 告警处理:当任务执行失败或出现异常时,调度中心可以根据配置的告警策略发送告警通知,如邮件、短信等,及时通知管理员处理问题。
- 依赖处理:调度中心支持任务的依赖配置,可以实现任务的串行或并行执行,以满足复杂的业务逻辑。
简单理解,XXL-JOB 的调度中心就是整个分布式任务调度系统的大脑和指挥中心,它通过管理和调度执行器和任务,实现了任务的自动化、分布式、高效的执行。
配置调度中心
打开 xxl-job-admin 的项目配置文件:

如果没有特殊要求,只需要配置上面创建的 xxl-job 数据库的连接信息即可,其他信息根据实际情况结合注释进行配置:
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource(调度中心 JDBC 链接,根据实际情况修改)
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000
### xxl-job, email (报警邮箱)
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.from=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token (调度中心通讯 TOKEN [选填]:非空时启用)
xxl.job.accessToken=default_token
### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 还可选 "zh_TC"/中文繁体 and "en"/英文;
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size(调度线程池最大线程配置【必填】)
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days(调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于 7 时生效,否则如- 1 则关闭自动清理功能)
xxl.job.logretentiondays=30
部署调度中心
完成上述配置之后,启动 com.xxl.job.admin.XxlJobAdminApplication 即可,默认登录账号为(admin/123456)。这里默认的调度中心运行端口为 8080,访问上下文为 /xxl-job-admin,如果有需要可根据实际情况修改:(这里就保持默认了)

调度中心访问地址: http://localhost:8080/xxl-job-admin
⚠️ 注意:如果你修改了上面的配置文件,则端口号和上下文路径也要跟着一起变。
首次访问你回来到登录注册页面,使用默认账号登录即可,如果启动报错,提示无法创建配置文件:
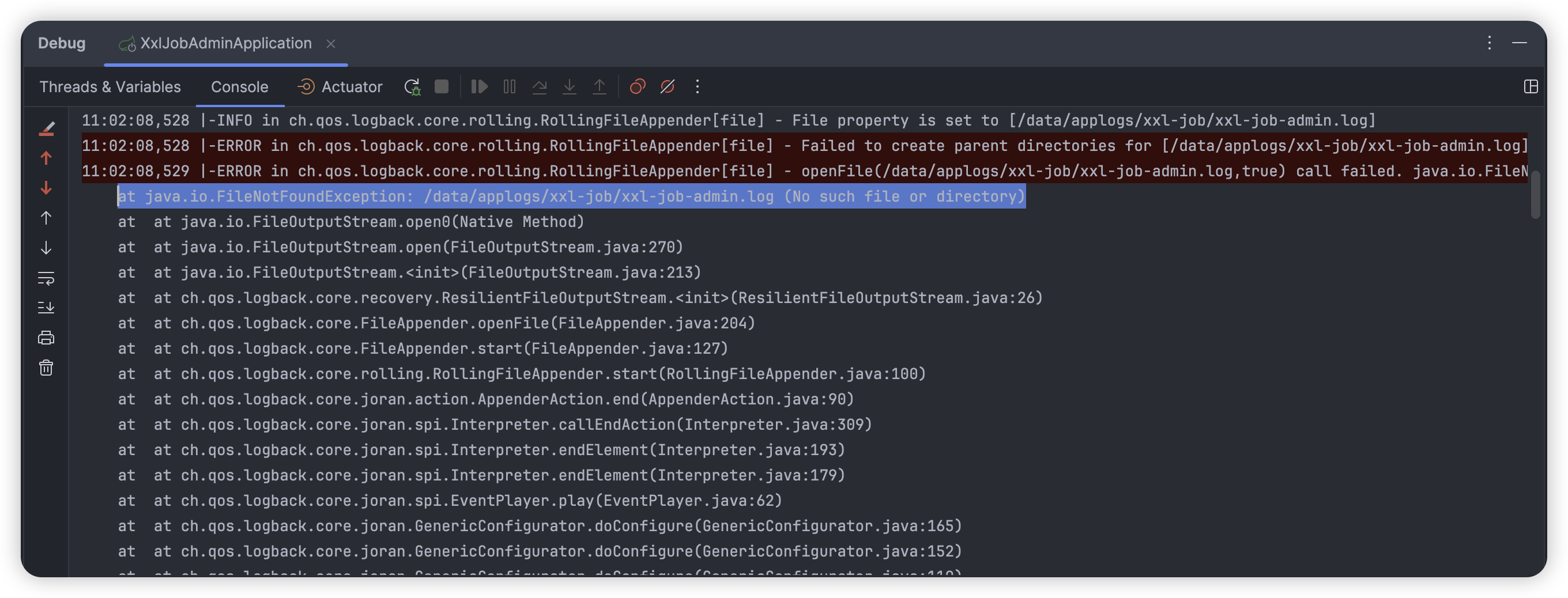
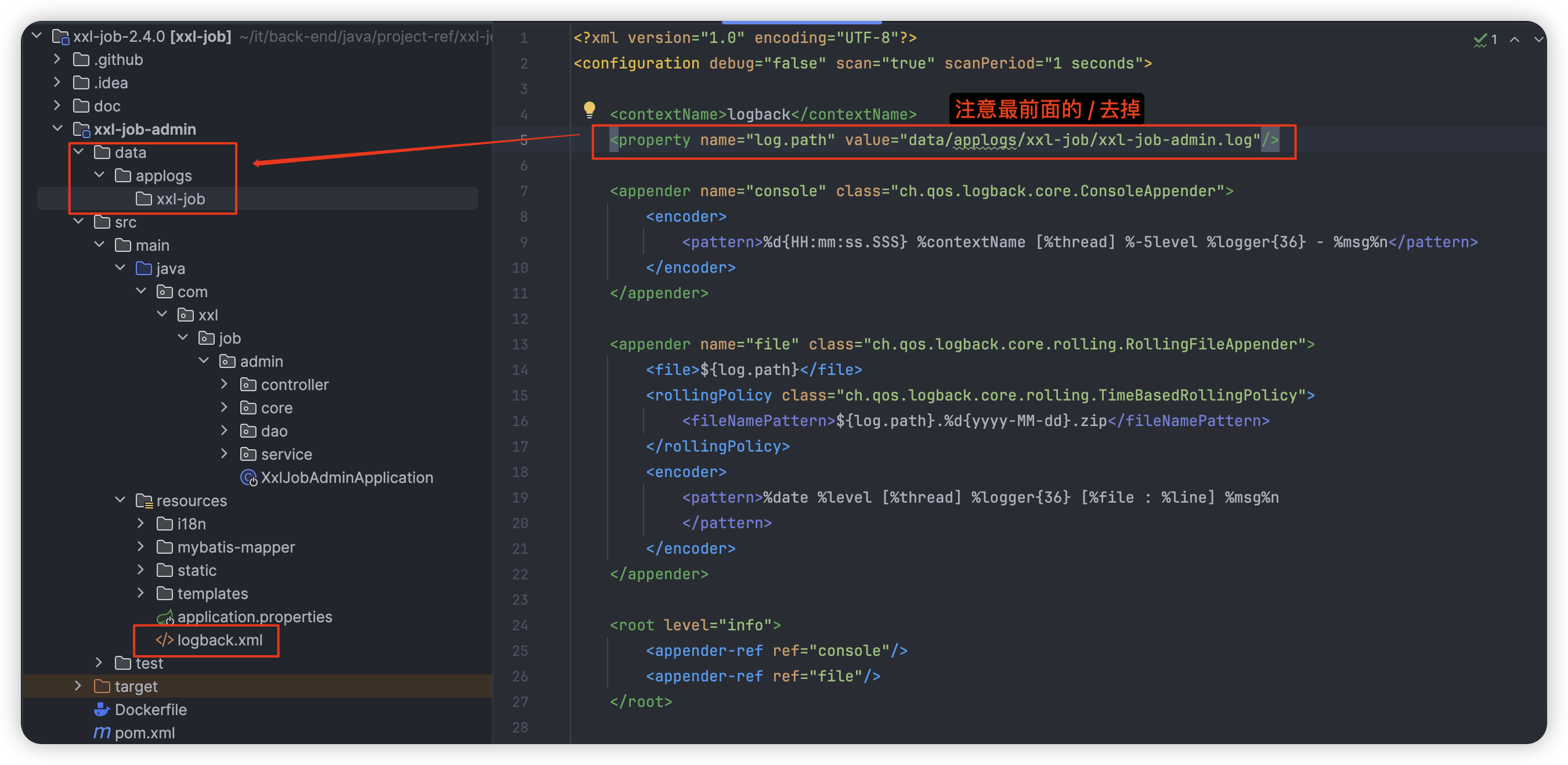
我们只需要修改对应的 src/main/resources/logback.xml 日志文件,调整日志保存路径即可,这里我在调度中心项目的跟路径下创建对应的日志文件:
再次启动项目即可:
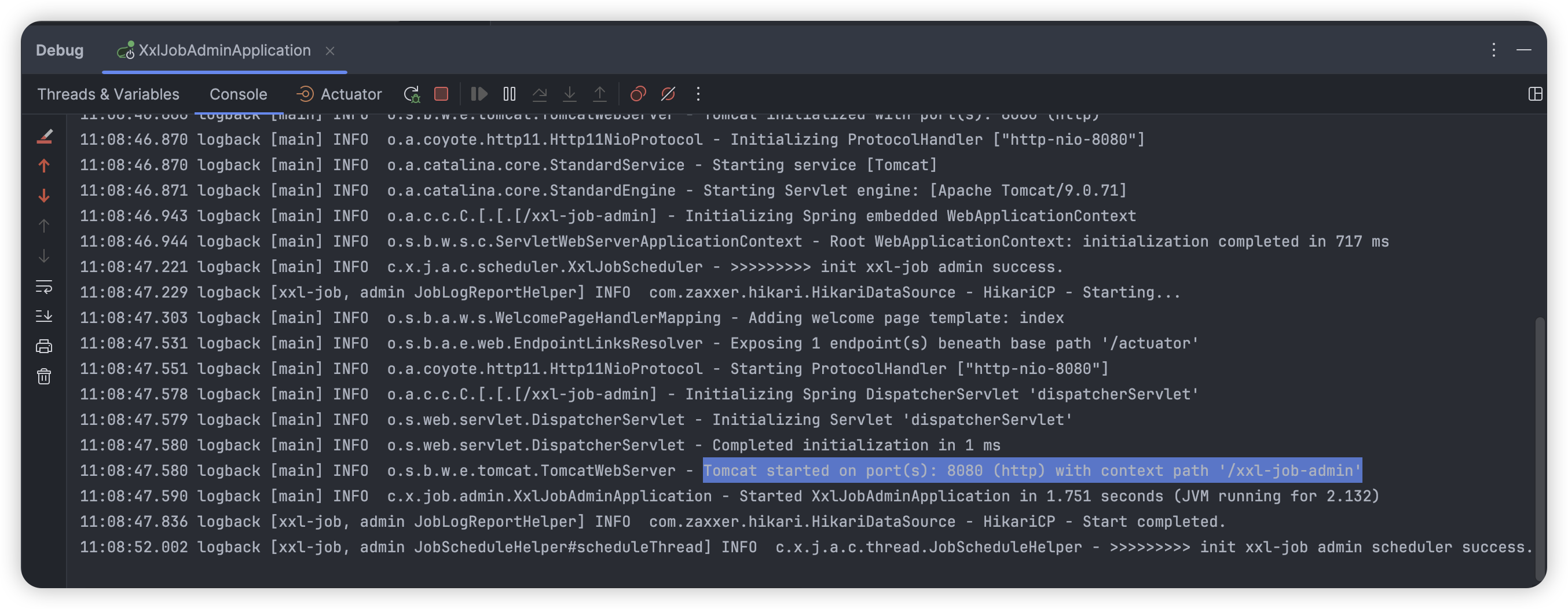
访问调度中心:
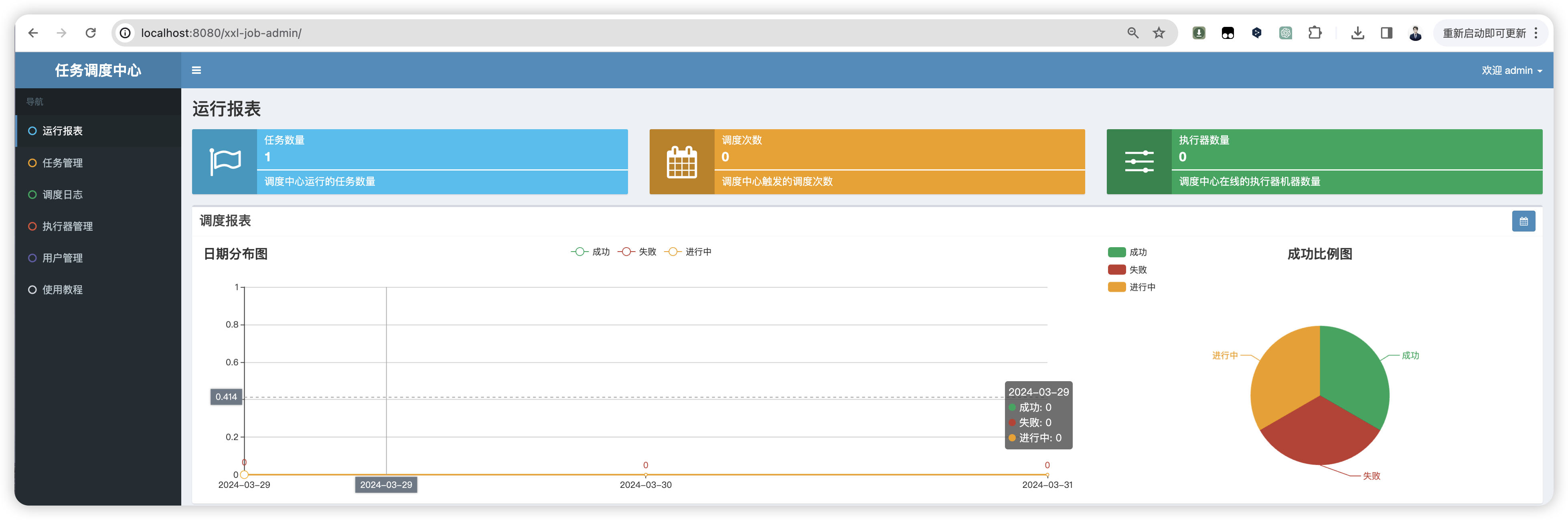
至此 “调度中心” 项目部署成功。
集群部署调度中心(可选)
调度中心也支持集群部署,提升调度系统容灾和可用性。调度中心集群部署时,几点要求和建议:
- DB 配置保持一致;
- 集群机器时钟保持一致(单机集群忽视);
💡 TIP:推荐通过 Nginx 为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用 API 服务等操作均通过该域名进行。
Docker 镜像方式搭建调度中心(可选)
下载镜像:
# Docker 地址:https://hub.docker.com/r/xuxueli/xxl-job-admin/ (建议指定版本号)
docker pull xuxueli/xxl-job-admin
创建容器并运行:
docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
- 如需自定义 MySQL 等配置,可通过 “-e PARAMS” 指定,参数格式 PARAMS=“–key=value --key2=value2” ;
- 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties;
- 如需自定义 JVM 内存参数等配置,可通过 “-e JAVA_OPTS” 指定,参数格式 JAVA_OPTS=“-Xmx512m” ;
下面是一个示例:
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
执行器
执行器介绍
XXL-JOB 的执行器(Executor)是分布式任务调度系统的另一个重要组成部分,它负责实际执行调度中心分配的任务。执行器可以是一个独立的服务,也可以集成到现有的业务项目中。
以下是执行器的主要概念和作用:
- 任务执行:执行器的核心作用是接收调度中心的调度指令,并执行指定的任务。任务的具体执行逻辑由开发者在执行器中实现。
- 任务注册:执行器在启动时会向调度中心注册自己的地址和能力信息(如支持的任务类型),以便调度中心知道向哪些执行器分配任务。
- 心跳维护:执行器会定期向调度中心发送心跳,报告自己的状态。调度中心根据心跳信息判断执行器的健康状态,对异常的执行器进行下线处理。
- 任务结果反馈:任务执行完成后,执行器会将执行结果(成功或失败)和日志反馈给调度中心,供用户在调度中心查看和监控。
- 任务路由:执行器支持多种路由策略,调度中心会根据路由策略选择合适的执行器实例执行任务。
- 任务分片:对于分片任务,执行器会接收到分片参数,根据参数执行相应的任务分片。
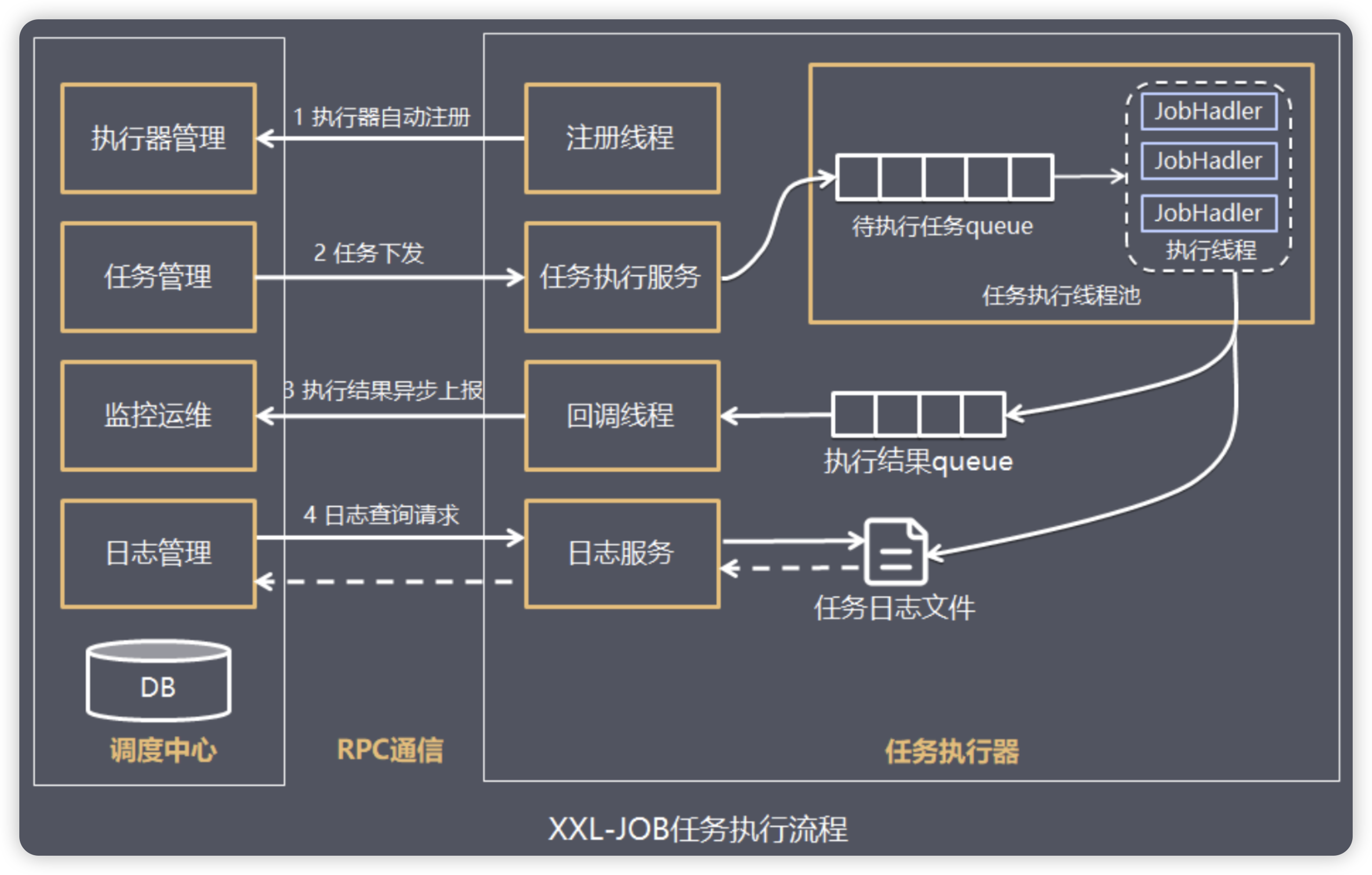
执行器与调度中心之间的交互逻辑主要包括:
- 注册和心跳:执行器启动时向调度中心注册,并定期发送心跳维护自己的在线状态。
- 任务调度:调度中心根据任务的调度策略和路由策略,向执行器发送执行指令。
- 任务执行:执行器接收到执行指令后,执行任务并将执行结果反馈给调度中心。
- 结果反馈:执行器将任务的执行结果和日志发送给调度中心,供用户查询和监控。
简单理解就是,执行器是 XXL-JOB 系统中负责具体任务执行的组件,它与调度中心协同工作,实现了任务的分布式执行和管理。
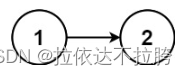
结合下图理解二者之间的关系:(图源)
添加依赖
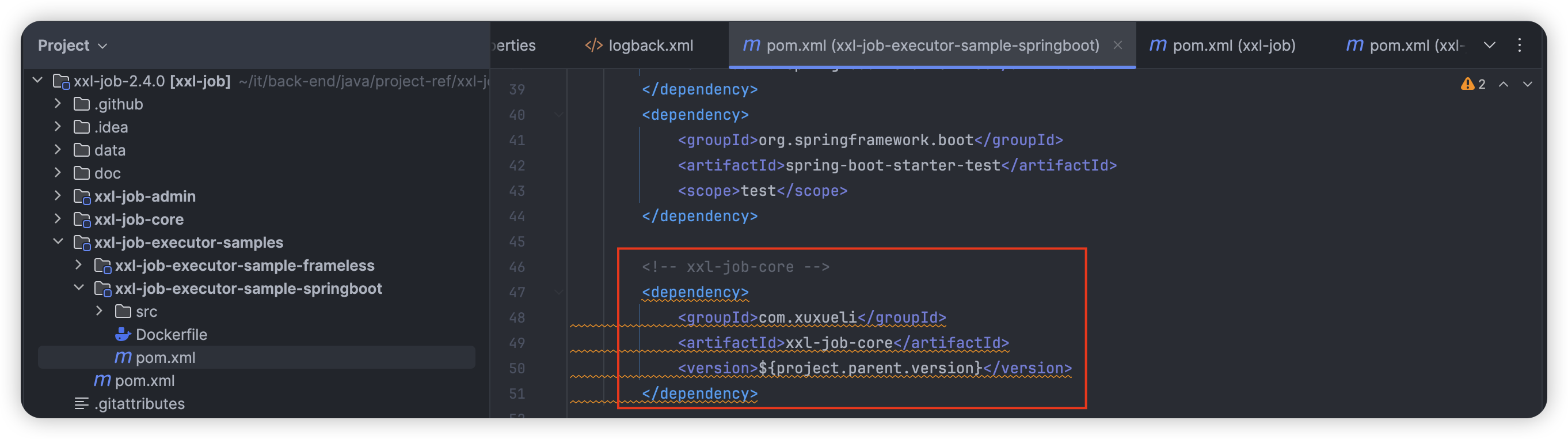
创建 SpringBoot 项目并且添加如下依赖:
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.0</version>
</dependency>
这里我们直接以 xxl-job-executor-sample-springboot 作为示例即可:
配置执行器
在 xxl-job-executor-sample-springboot 执行器示例项目的配置文件中进行如下配置:
# 执行器应用端口
server.port=8081
# 非 web 模式
#spring.main.web-environment=false
# 指定日志配置文件位置
logging.config=classpath:logback.xml
# 调度中心(xxl-job-admin)的地址,多个地址用逗号分隔
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
# 执行器与调度中心通信的访问令牌,需要与调度中心(xxl-job-admin)配置的 accessToken 保持一致
xxl.job.accessToken=default_token
# 执行器的名称,用于执行器的心跳注册和任务结果回调
xxl.job.executor.appname=xxl-job-executor-sample
# 执行器的注册地址,优先使用此配置作为注册地址,为空时使用 ip:port 作为注册地址
xxl.job.executor.address=
# 执行器的 IP 地址,为空表示自动获取 IP,多网卡时可手动设置指定 IP
xxl.job.executor.ip=
# 执行器的端口号,小于等于 0 则自动获取;默认端口为 9999
xxl.job.executor.port=9999
# 执行器日志文件的存储路径,需要对该路径拥有读写权限;为空则使用默认路径
xxl.job.executor.logpath=data/applogs/xxl-job/jobhandler
# 执行器日志文件的保存天数,过期日志将自动清理;值大于等于 3 时生效,否则关闭自动清理功能
xxl.job.executor.logretentiondays=30
简单解释一下其中几个配置项:
xxl.job.admin.addresses: 这个配置项用于指定 XXL-JOB 调度中心(xxl-job-admin)的地址。如果有多个调度中心,可以用逗号分隔它们的地址。执行器会使用这个地址来进行 “执行器心跳注册” 和“ 任务结果回调”。例如,如果你的调度中心部署在本地的 8080 端口,那么这个配置项应该设置为http://127.0.0.1:8080/xxl-job-admin。xxl.job.executor.address: 这个配置项用于指定执行器的注册地址,它是执行器向调度中心注册自己时使用的地址。如果这个配置项为空,执行器会使用自己的 IP 地址和端口号作为注册地址。在某些特殊情况下,比如执行器部署在容器中,可能需要手动指定这个地址来解决动态 IP 或端口映射的问题。xxl.job.executor.ip: 这个配置项用于指定执行器的 IP 地址。默认情况下,执行器会自动获取自己的 IP 地址。但是在多网卡的环境中,可能需要手动指定一个确切的 IP 地址,以确保执行器能够正确地与调度中心通信。xxl.job.executor.port: 这个配置项用于指定执行器的端口号。如果设置为小于等于 0 的值,执行器会自动获取一个可用的端口号。默认情况下,执行器的端口号是 9999。如果你在同一台机器上部署了多个执行器,需要确保它们使用不同的端口号。
简单理解就是,xxl.job.executor.address 是用来填写执行器应用服务的完整地址(包括 IP 和端口),而 xxl.job.executor.ip 和 xxl.job.executor.port 分别用来指定执行器服务的 IP 地址和端口号。如果 xxl.job.executor.address 为空,执行器会使用 xxl.job.executor.ip 和 xxl.job.executor.port 拼接成的地址来注册。
配置中的日志文件存放路径,我们同样在当前项目的根路径创建对应的文件夹即可:
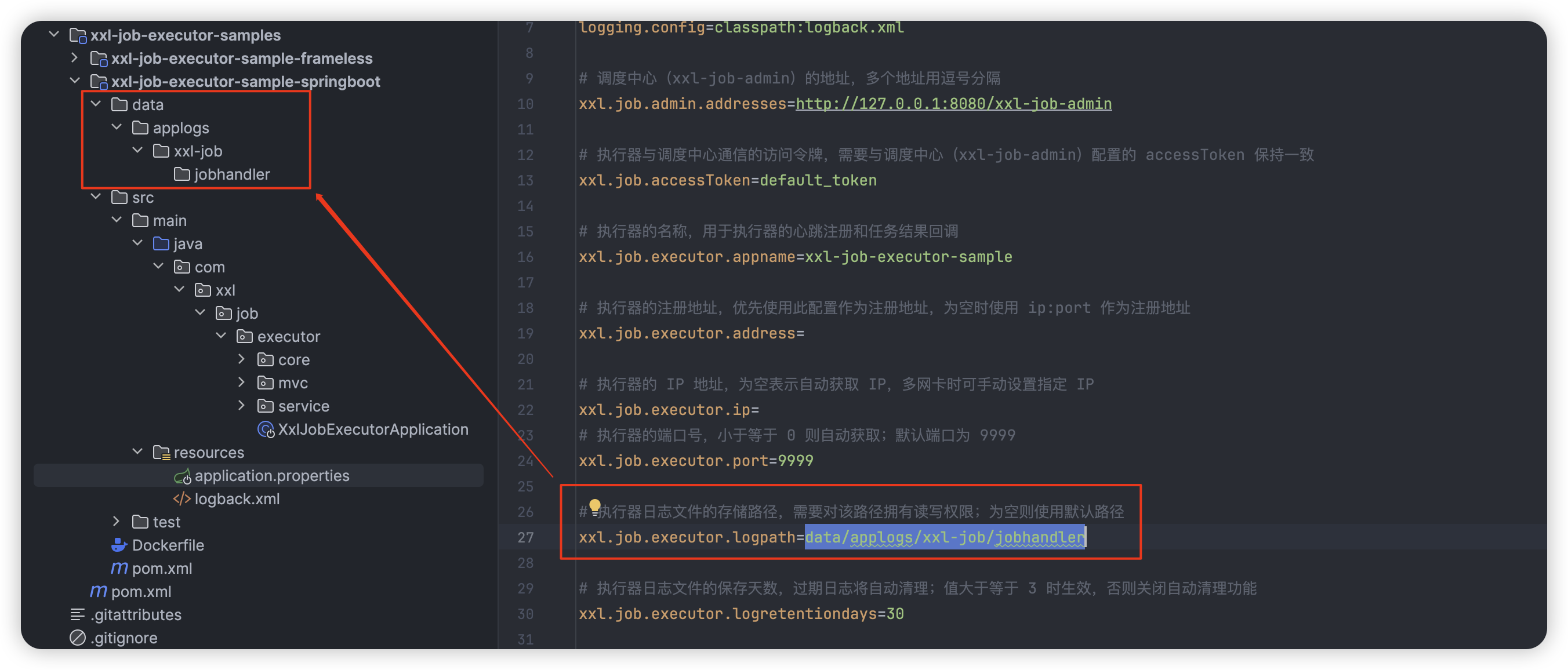
同样,src/main/resources/logback.xml 中也配置了对应的路径,进行同样的操作避免启动时出现 java.io.FileNotFoundException: /data/applogs/xxl-job/xxl-job-executor-sample-springboot.log (No such file or directory) 异常:
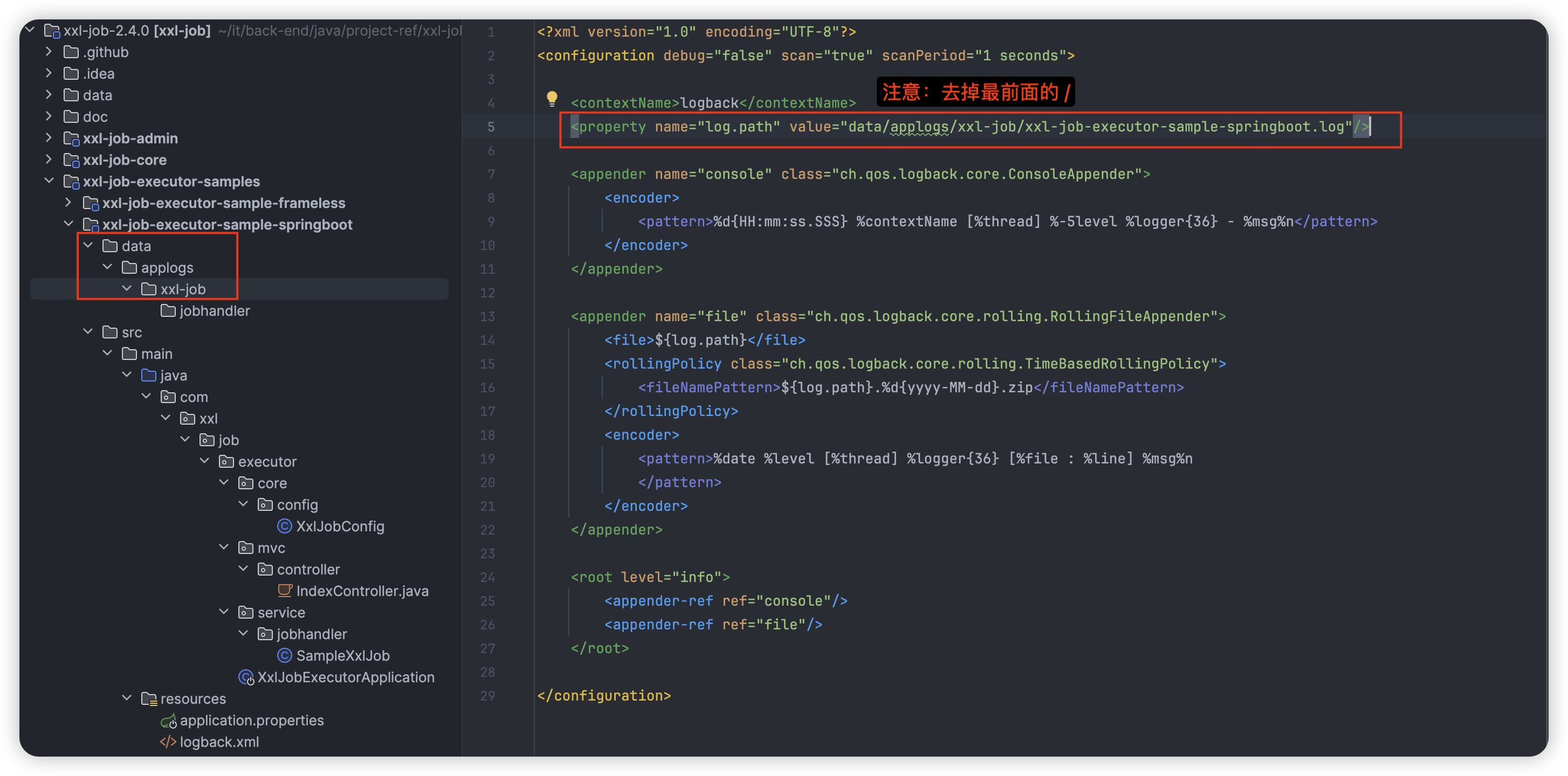
配置 XxlJobSpringExecutor
在 XXL-JOB 中,XxlJobSpringExecutor 是执行器组件的核心类,它负责初始化执行器、注册执行器到调度中心、执行任务等。在 Spring Boot 项目中,我们通常通过配置一个 Bean 来初始化 XxlJobSpringExecutor。
下面是示例配置:(com.xxl.job.executor.core.config.XxlJobConfig)
package com.xxl.job.executor.core.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job 配置
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
/**
* 调度中心地址
*/
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
/**
* 执行器与调度中心通信的访问令牌
*/
@Value("${xxl.job.accessToken}")
private String accessToken;
/**
* 执行器名称,用于在调度中心区分不同的执行器
*/
@Value("${xxl.job.executor.appname}")
private String appname;
/**
* 执行器的注册地址,优先使用此配置作为注册地址,为空时使用 ip:port 作为注册地址
*/
@Value("${xxl.job.executor.address}")
private String address;
/**
* 执行器的 IP 地址,为空表示自动获取 IP,多网卡时可手动设置指定 IP
*/
@Value("${xxl.job.executor.ip}")
private String ip;
/**
* 执行器的端口号,小于等于 0 则自动获取;默认端口为 9999
*/
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
/**
* 执行器日志文件的存储路径
*/
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
/**
* 执行器核心组件:负责注册、调度、执行、日志等功能
*/
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
// 创建 XxlJobSpringExecutor 对象
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
// 设置执行器注册到调度中心地址列表
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
// 设置执行器应用名称
xxlJobSpringExecutor.setAppname(appname);
// 设置执行器注册到调度中心的地址
xxlJobSpringExecutor.setAddress(address);
// 设置执行器所在IP
xxlJobSpringExecutor.setIp(ip);
// 设置执行器端口号
xxlJobSpringExecutor.setPort(port);
// 设置访问令牌
xxlJobSpringExecutor.setAccessToken(accessToken);
// 设置执行器日志存储路径
xxlJobSpringExecutor.setLogPath(logPath);
// 设置执行器日志保留天数
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
// 返回 XxlJobSpringExecutor 对象
return xxlJobSpringExecutor;
}
}
在多网卡的环境或容器中部署执行器时,自动获取的 IP 地址可能不是我们期望的那个。为了解决这个问题,我们可以使用 Spring Cloud Commons 提供的 InetUtils 组件来灵活地定制注册 IP 地址。
首先,需要在项目的 pom.xml 文件中添加 spring-cloud-commons 依赖。这个依赖包含了 InetUtils 组件,它可以帮助我们获取正确的 IP 地址:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-commons</artifactId>
<version>${version}</version>
</dependency>
接下来,需要在配置文件(如 application.properties 或 application.yml)中设置 spring.cloud.inetutils.preferred-networks 属性。这个属性的值应该是你希望使用的网络的 IP 地址段。
例如,如果你的目标 IP 地址是 192.168.1.x,那么可以配置为:
spring.cloud.inetutils.preferred-networks: '192.168.1.'
然后在你的配置类或其他合适的地方,使用 InetUtils 获取正确的 IP 地址。
首先注入 InetUtils 实例:
@Autowired
private InetUtils inetUtils;
然后,使用 findFirstNonLoopbackHostInfo() 方法获取非回环(非本地)的主机信息,并通过 getIpAddress() 方法获取 IP 地址:
String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
这样得到的 ip_ 就是根据 preferred-networks 配置筛选出的正确的 IP 地址。你可以将这个 IP 地址用于执行器的注册。
创建任务
在 XXL-JOB 中,任务(Job)是需要定时执行的业务逻辑,而创建任务的方式之一就是通过在 Spring Bean 中定义 Job 方法,并使用 @XxlJob 注解来标注。
创建任务的步骤如下:
- 任务开发:在 Spring Bean 中开发 Job 方法,实现具体的业务逻辑。
- 注解配置:为 Job 方法添加
@XxlJob注解。注解的value属性对应调度中心新建任务的 JobHandler 属性的值,用于标识不同的任务。 - 执行日志:在 Job 方法中,需要通过
XxlJobHelper.log方法打印执行日志,以便在调度中心查看任务执行情况。 - 任务结果:默认情况下,任务执行成功不需要主动设置。如果需要设置任务执行失败,可以通过
XxlJobHelper.handleFail方法自主设置任务结果。
💡 下面的任务示例代码参考自:com.xxl.job.executor.service.jobhandler.SampleXxlJob
简单任务(Bean 模式)
下面是一个简单的任务示例,每隔 2 秒打印一次日志,共打印 5 次:
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
// 通过 XxlJobHelper 提供的 api,操作日志,以便在调度中心中展示任务日志,查看任务执行情况
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobHelper.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
// XXL-JOB 的任务默认都是执行成功
}
编写好任务后,启动当前执行器服务(com.xxl.job.executor.XxlJobExecutorApplication),如果你正确配置了相关信息,当执行器启动成功就会在调度中心进行注册,这时你就可以在调度中心的【执行器管理】看到注册的执行器了,点击【查看】即可看到执行器的基本信息,也就是前面说的自动获取的 IP 地址和端口号。

接下来我们需要在【任务管理】页面配置上面编写的 demoJobHandler 任务,默认已经为我们创建好了 demoJobHandler 任务了,为了体验创建过程你可先将其删除:
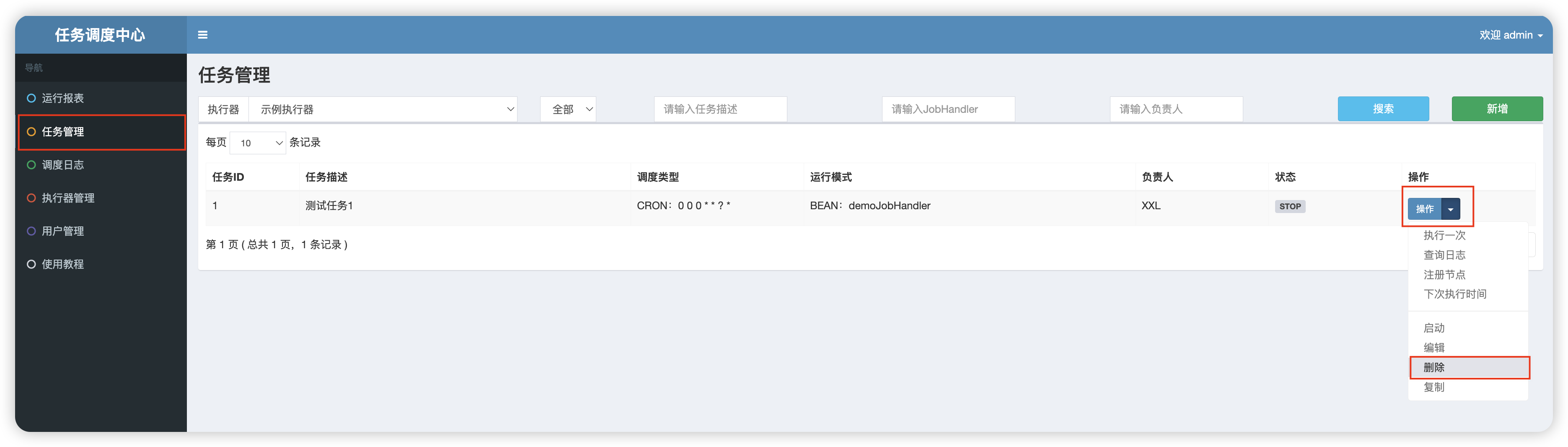
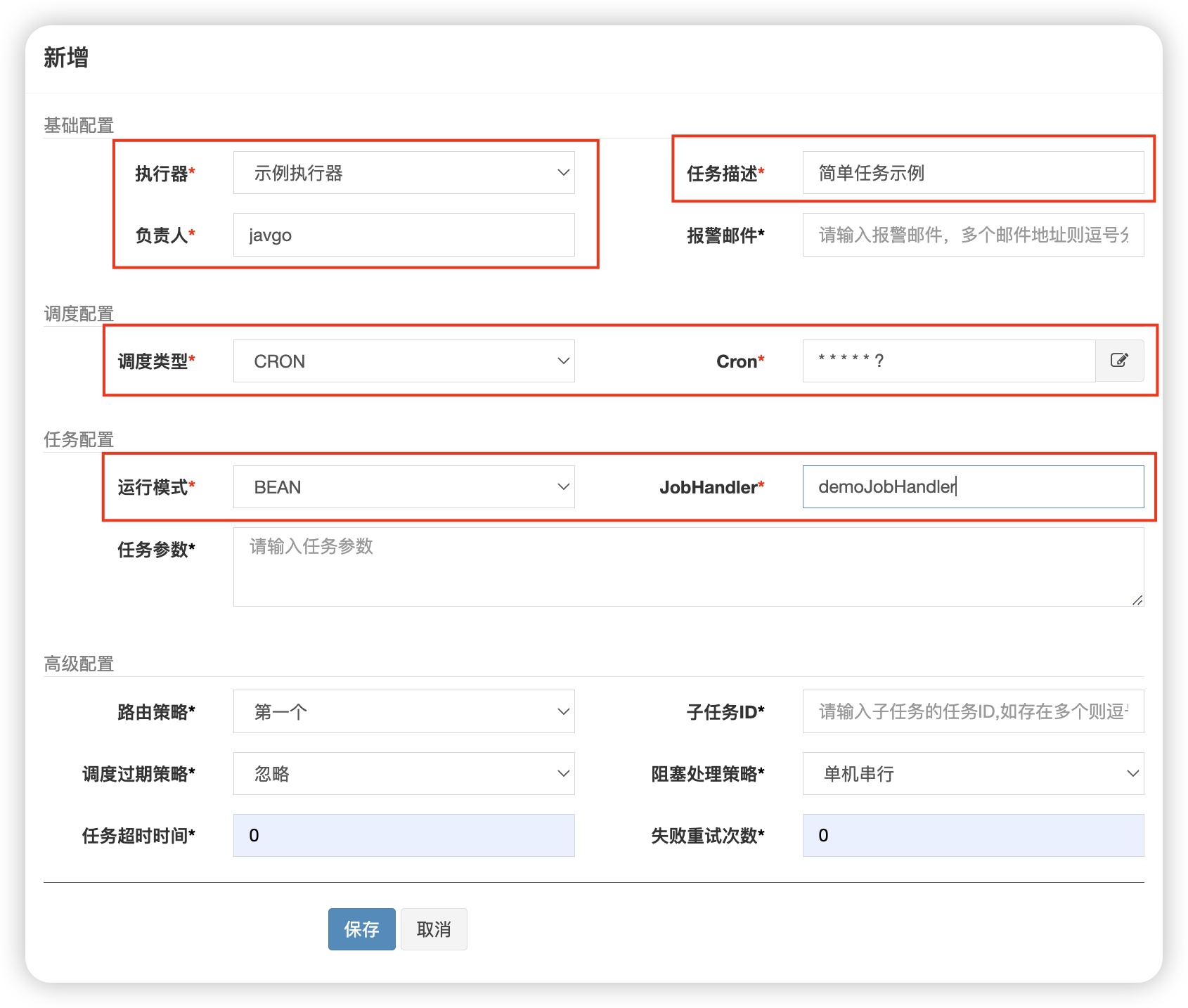
然后点击右上角的【新增】按钮进行任务添加:

新增页面如下,暂时只需要关注红色框的几个必填项:
点击【保存】即可在任务列表看到我们配置的任务了:

💡 在开始执行之前,我们需要了解一下上述各个配置项的意义以及作用【见下一节:任务配置项】和 Cron 表达式的基本使用【见下下节:Cron 表达式】。
上面我们配置了 Cron 表达式为每秒执行一次,这里我们可以通过【操作 - 执行一次】来查看执行效果:

点击【执行一次】会提示输入任务参数,由于简单示例没有涉及,直接点击【保存】即可:
由于我们是通过 XxlJobHelper.log 打印的日志,该日志不会出现在 IDEA 的控制台,如果有需要也可以使用 Lombok 的 log,进行打印到控制台。我们之前说过,通过 XxlJobHelper 提供的 api 操作日志,可以在调度中心中展示任务日志,查看任务执行情况。
我们可以打开调度中心的【调度日志】页面的【操作 - 执行日志】,查看本次调度日志:

通过日志即可清楚的看到本次执行的结果了:
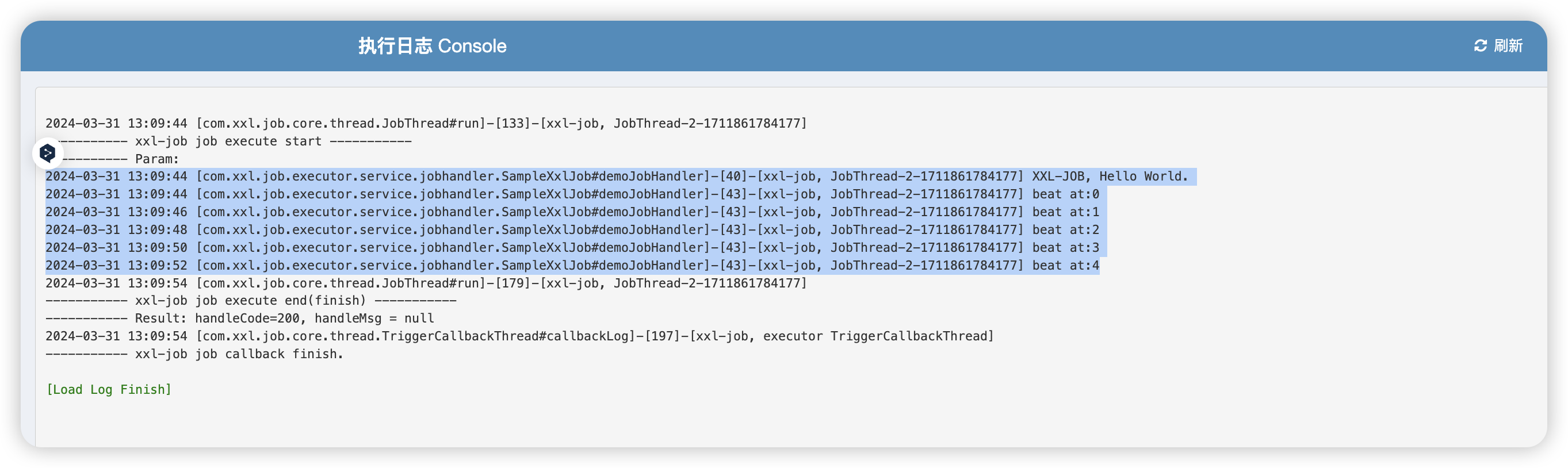
这时候我们也可以在对应的数据库表中看到记录下来的各种信息:
xxl_job_info: 存储任务的基本信息,如任务描述、调度类型、执行器路由策略、任务参数等。

xxl_job_log: 存储任务的执行日志,包括执行时间、执行结果、执行参数等信息。

xxl_job_log_report: 存储任务执行的统计报告,如每天的运行次数、成功次数、失败次数等。

xxl_job_logglue: 存储任务的 GLUE 代码历史版本,用于记录任务代码的变更历史。这里暂时没有涉及。
xxl_job_registry: 存储执行器的注册信息,用于执行器的自动发现和注册。

xxl_job_group: 存储执行器的分组信息,一个执行器分组可以包含多个执行器实例。

xxl_job_user: 存储系统的用户信息,用于系统的登录认证和权限控制。

xxl_job_lock: 存储系统的锁信息,用于实现分布式锁,防止任务的重复执行。

任务配置项
在 XXL-JOB 新增任务时,需要填写以下配置项:
- 执行器:选择要执行任务的执行器(名称)。执行器是任务执行的环境,通常一个执行器对应一个微服务或应用。这里只有在【执行器管理】中注册的 “示例执行器” 我们直接选择即可。
- 任务描述:简要描述任务的功能和目的,便于理解和管理。
- 负责人:任务的负责人,一般填写任务的开发或维护人员,用于任务出现问题时的联系。
- 报警邮件:任务执行失败时的报警邮件地址,支持多个邮件地址用逗号分隔。
- 调度类型:
- 无:不进行调度,需要手动触发任务。
- Cron:使用 Cron 表达式进行任务调度,可以实现复杂的调度逻辑,一般都是使用 Cron 类型。(下面会介绍 Cron 表达式)
- 固定速度:固定频率执行任务,需要指定任务间隔时间。
- Cron:当调度类型选择 Cron 时,需要填写 Cron 表达式,如
0/5 * * * * ?表示每隔 5 秒执行一次。(下面会介绍 Cron 表达式) - 任务参数:执行任务时需要传递的参数,任务代码中可以通过
XxlJobHelper.getJobParam()方法获取这些参数。(目前还没有涉及,后续会进行展开说明,这里先了解即可) - 路由策略:
- 第一个:总是使用第一个可用的执行器执行任务。
- 最后一个:总是使用最后一个可用的执行器执行任务。
- 轮询:依次轮流使用每个可用的执行器执行任务。
- 随机:随机选择一个可用的执行器执行任务。
- 一致性HASH:根据任务参数的哈希值选择执行器,保证相同参数的任务总是由同一个执行器执行。
- 最不经常使用:选择使用次数最少的执行器执行任务。
- 最近最久未使用:选择最近最长时间未使用的执行器执行任务。
- 故障转移:如果选中的执行器执行失败,自动选择其他执行器重试。
- 忙碌转移:如果选中的执行器繁忙,自动选择其他执行器执行。
- 分片广播:任务分成多个片,每个执行器执行一个片,适用于大数据量的并行处理。(后面会进行展开说明)
- 子任务ID:如果任务执行完成后需要触发其他任务,可以在这里填写其他任务的ID,多个ID用逗号分隔。
- 调度过期策略:
- 忽略:如果任务调度时间已过,不再执行该任务。
- 立即执行一次:如果任务调度时间已过,立即执行一次该任务。
- 阻塞处理策略:
- 单机串行:同一执行器上的任务依次串行执行,后一个任务必须等前一个任务完成后才能开始执行。
- 丢弃后续调度:如果前一个任务尚未完成,后续的调度将被丢弃,不会执行。
- 覆盖之前调度:如果前一个任务尚未完成,后续的调度将覆盖前一个任务,即取消前一个任务的执行。
- 任务超时时间:任务执行的最长时间,单位为秒。如果任务执行时间超过这个值,将被强制终止。
- 失败重试次数:如果任务执行失败,可以自动重试的次数。
在后续的任务配置时,也可以参考上面的配置项进行个性化的配置,以满足实际的业务需要。
Cron 表达式
TIP:以下内容来自阿里云服务器 ECS - Cron 表达式文档。(链接)
Cron 表达式是一种用于指定定时任务的时间表达式,常用来指定任务的执行时间、执行频率和执行间隔。它由6~7个字段组成,分别表示秒、分、时、日期、月份、星期、年份(可省略)。
Cron 表达式的基本语法如下:
秒 分 时 日期 月份 星期 [年份]
- [年份]:可省略。
- 关于单个字段:
- 单个字段可以是一个具体的值、一个范围、一个递增步长,或者具有逻辑意义的特殊字符。
- 单个字段若有多个取值时,使用半角逗号
,隔开取值。 - 每个字段最多支持一个前导零。即可以使用 01、02 等表示,但不能使用 001、002 等表示。
字段的取值范围和支持的特殊字符,请参见字段取值和示例。
下表为 Cron 表达式中七个字段的取值范围和支持的特殊字符:
| 字段 | 是否必需 | 取值范围 | 特殊字符 |
|---|---|---|---|
| 秒 | 是 | [0, 59] | * , - / |
| 分钟 | 是 | [0, 59] | * , - / |
| 小时 | 是 | [0, 23] | * , - / |
| 日期 | 是 | [1, 31] | * , - / ? L W |
| 月份 | 是 | [1, 12]或[JAN, DEC] | * , - / |
| 星期 | 是 | [1, 7]或[MON, SUN]。在云助手命令中,若您使用[1, 7]表达方式,1代表星期一,7代表星期日。 | * , - / ? L # |
| 年 | 否 | [当前年份,2099] | * , - / |
⚠️ 注意:Cron 表达式的使用方法和含义可能会根据不同的系统、框架或工具有所差异。若您在其他地方使用 Cron 表达式,1可能表示星期日,7表示星期六,具体以实际情况为准。
Cron 表达式中的每个字段都支持特殊字符,每个特殊字符都有其特殊含义:
| 特殊字符 | 含义 | 示例 |
|---|---|---|
* | 匹配任意值。 | 在字段月中,*表示每个月。 |
, | 列出枚举值。 | 在字段分钟中,5,20表示分别在5分钟和20分钟触发一次。 |
- | 指定范围。 | 在字段分钟中,5-20表示从5分钟到20分钟之间每隔一分钟触发一次。 |
/ | 指定数值的增量。 | 在字段分钟中,0/15表示从第0分钟开始,每15分钟。在字段分钟中3/20表示从第3分钟开始,每20分钟。 |
? | 不指定值,仅用于日期和星期。 | 当字段日期或星期其中之一被指定了值以后,为了避免冲突,需要将另一个字段的值设为?。 |
L | 单词Last的首字母,表示最后一天,仅字段日期和星期支持该字符。(⚠️ 指定L字符时,避免指定列表或范围,否则会导致逻辑问题。) | 在字段日期中,L表示某个月的最后一天。在字段日期中,L表示一个星期的最后一天,也就是星期日(SUN)。如果在L前有具体的内容,例如,在字段星期中的6L表示这个月的最后一个星期六。 |
W | 除周末以外的有效工作日,在离指定日期的最近的有效工作日触发事件。W字符寻找最近有效工作日时不会跨过当前月份,连用字符LW时表示为指定月份的最后一个工作日。 | 在字段日期中5W,如果5日是星期六,则将在最近的工作日星期五,即4日触发。如果5日是星期天,则将在最近的工作日星期一,即6日触发;如果5日在星期一到星期五中的一天,则就在5日触发。 |
# | 确定每个月的第几个星期几。(⚠️ 仅字段星期支持该字符。) | 在字段星期中,4#2表示某月的第二个星期四。 |
下面是一些表达式示例:
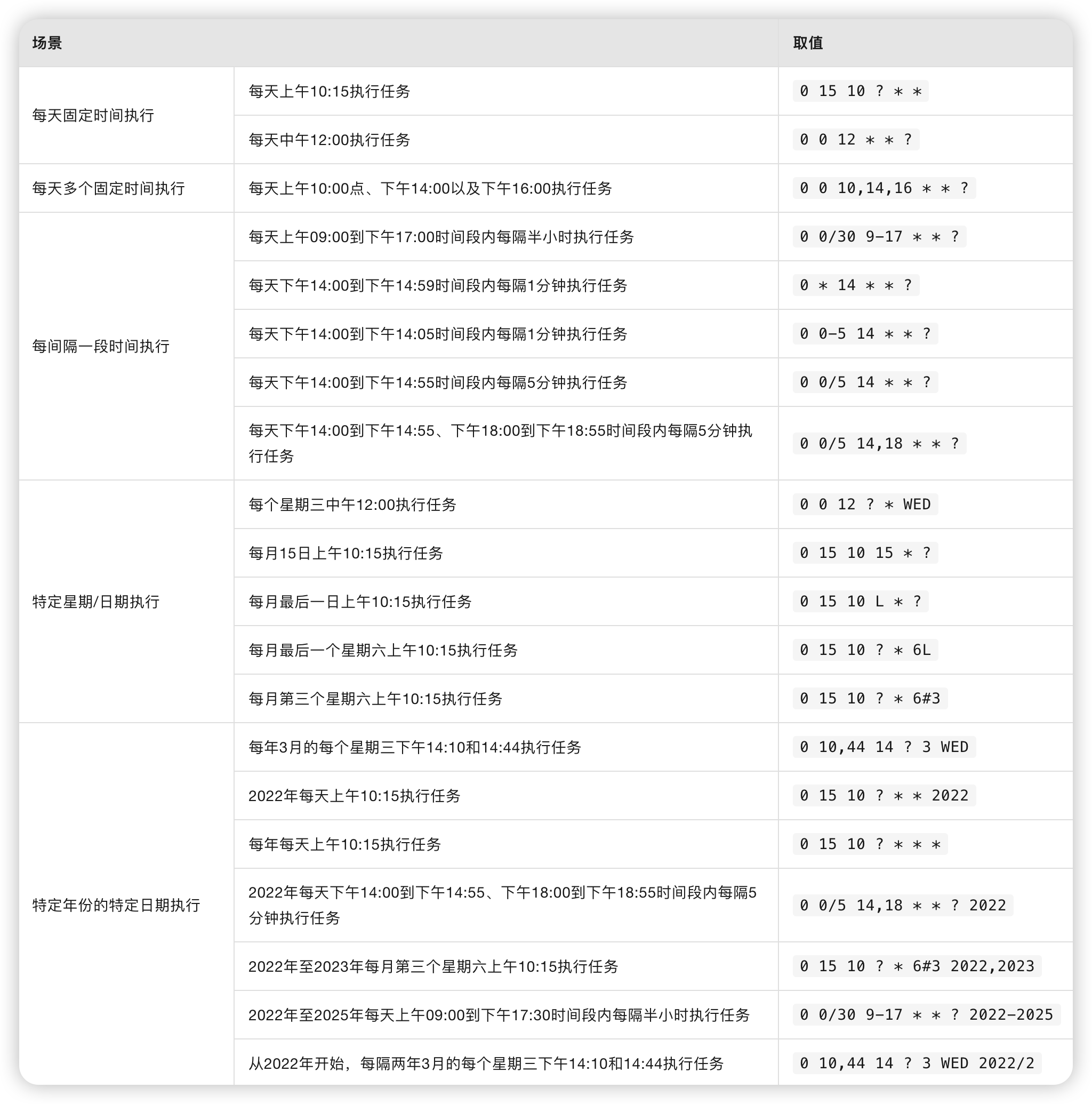
💡 TIP:更多 Cron 表达式说明,请参见 Cron 官方文档。
当然,如果你不想去理解和记忆上面的表达式,也有一些网站让你通过可视化的界面进行配置:(地址)
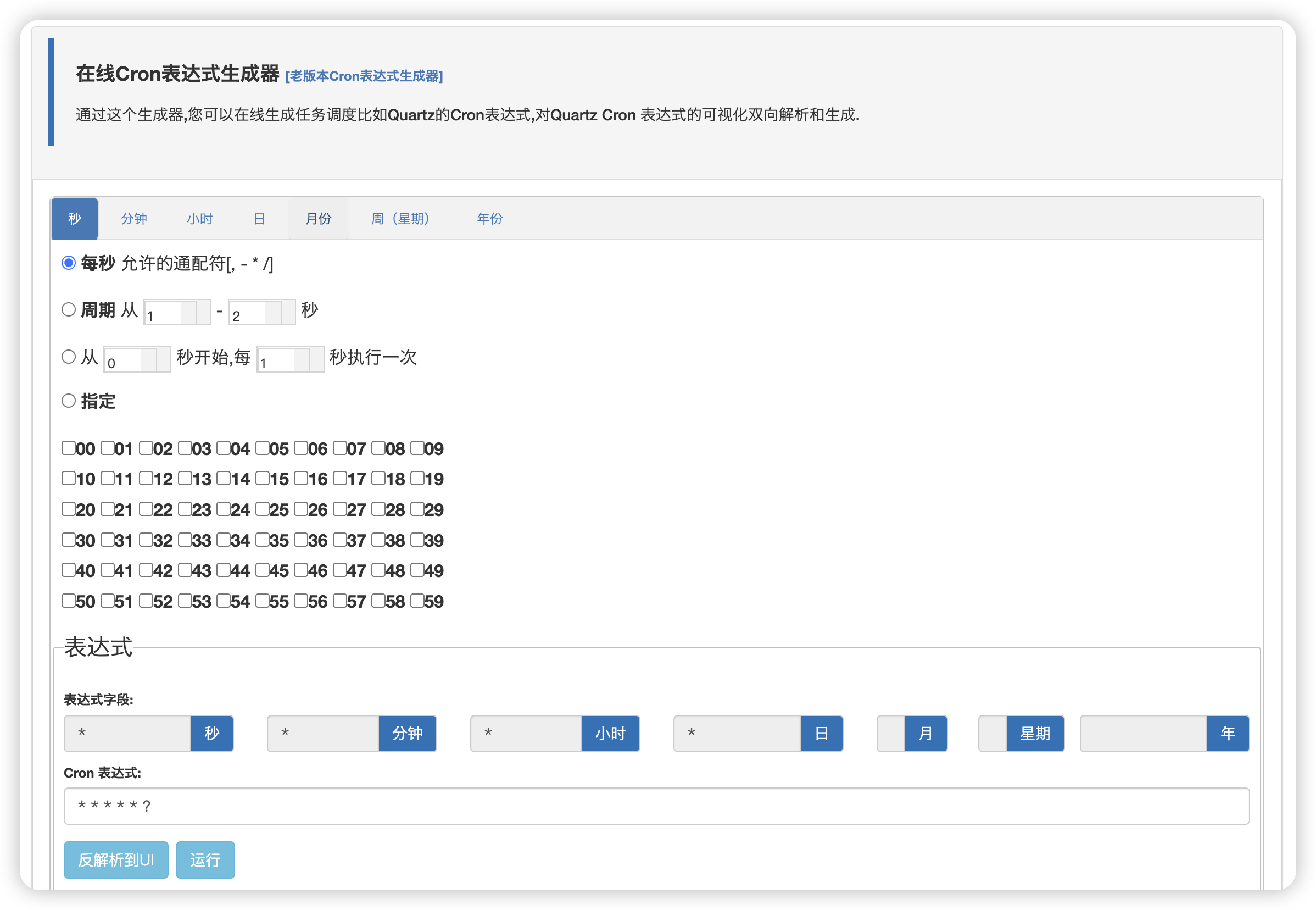
例如我们前面配置的简单示例任务的表达式 * * * * * ? 也可以通过该网站进行反解析来理解其执行周期,通过上图可以看出来这是一个每秒执行一次的任务。
GLUE 模式(Java)
GLUE 模式(Java)是 XXL-JOB 提供的另一种灵活的任务开发模式,允许你直接在调度中心的 Web 界面编写和维护任务代码,实现实时编译和生效,而不需要像上面的 Bean 模式一样在执行器项目中编写 Job。
在调度中心,点击【任务管理】菜单,然后点击 【新增】 按钮来创建一个新的调度任务,运行模式选择 CLUE(Java):

然后点击【操作 - GLUE IDE】即可进行代码编辑页面:
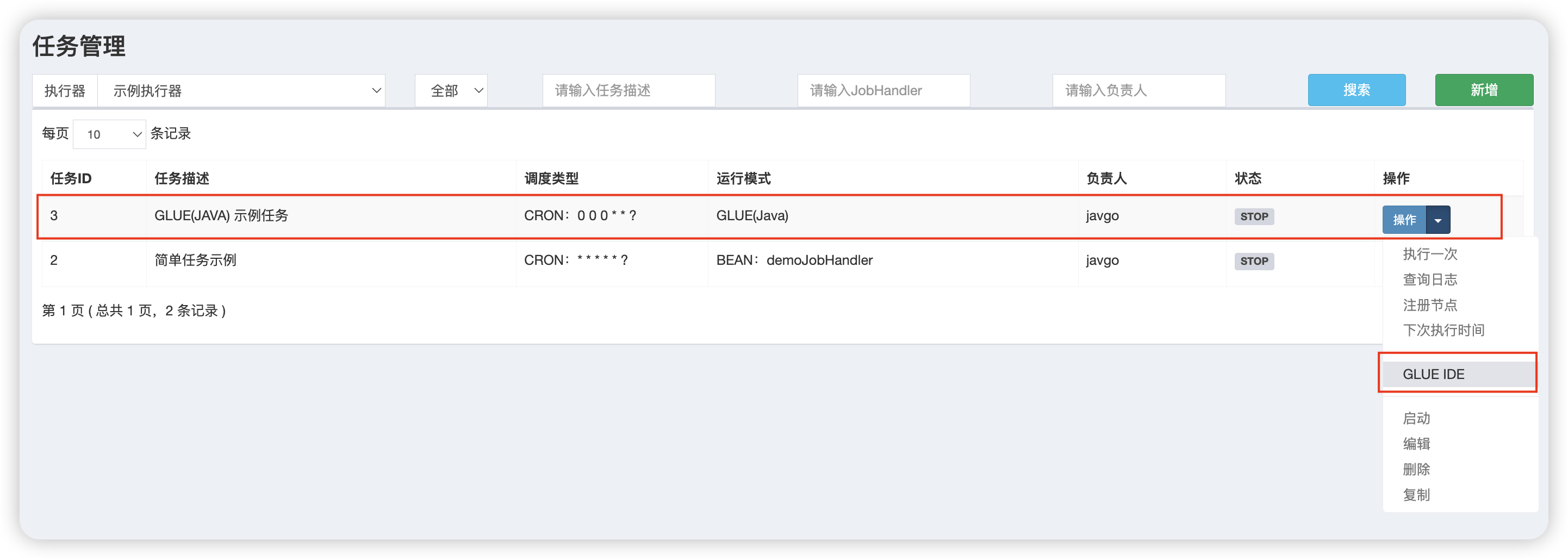
初次进入的页面如下:

在上面的 Web IDE 中,我们可以直接编写 Java 代码来实现任务的逻辑。代码的入口方法是 execute,在其中编写业务逻辑后,点击【保存】按钮,代码会立即编译并生效。如果编译失败,需要根据错误提示进行修改。
除此之外,在 GLUE 任务的 Web IDE 界面,右上角有一个【版本回溯】下拉框,点击它会列出该 GLUE 任务的更新历史,最多支持回溯 30 个版本。选择你想要回退到的某个历史版本,界面会显示该版本的代码。如果确定要回退到这个版本,点击【保存】按钮,GLUE 代码即回退到对应的历史版本。
通过 GLUE 模式,你可以方便地在 Web 界面上管理和更新任务代码,无需重新部署执行器,非常适合快速开发和测试任务。
上面的方法是一个无返回值也不能接收任务参数的执行器入口,如果你需要返回数据,则重写 execute(String... params) 方法即可:
package com.xxl.job.service.handler;
// 注意:Web IDE 不会自动导入相关类路径,因此需要进行手动导入
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.IJobHandler;
public class DemoGlueJobHandler extends IJobHandler {
private static transient Logger logger = LoggerFactory.getLogger(DemoGlueJobHandler.class);
// 无返回值
@Override
public void execute() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
}
// 有返回值(param:任务参数,ReturnT<String>:执行结果)
@Override
public ReturnT<String> execute(String... params) throws Exception {
logger.info("XXL-JOB, Hello World!");
return ReturnT.SUCCESS;
}
}
这里我们以默认的方法为例,点击保存,然后执行一次该任务,观察日志输出,就可以看到预期结果了:
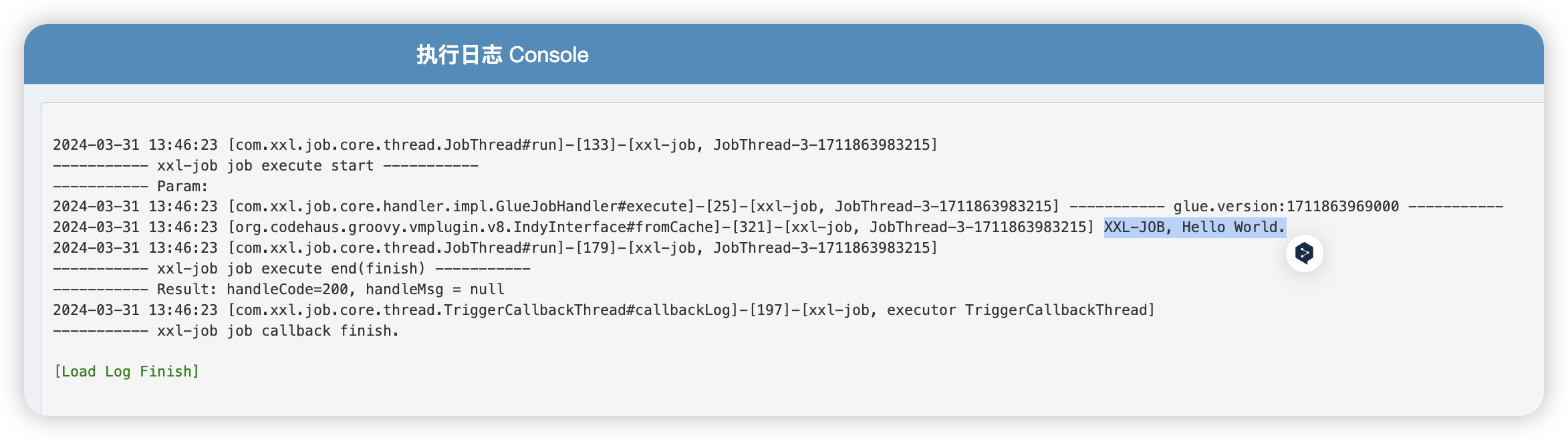
那么,我们通过 Web IDE 如何与执行器端服务进行交互呢?否则这个功能显得会很鸡肋。
在 XXL-JOB 中,使用 GLUE 模式编写的代码是作为任务的一部分存储在调度中心的数据库中的。当调度中心触发一个任务时,它会将任务的信息和 GLUE 代码发送给执行器端服务。执行器端服务接收到这些信息后,会根据 GLUE 代码的类型动态编译和执行这段代码。
与执行器端服务的交互:
-
任务触发:当调度中心根据任务的调度配置触发一个任务时,它会查询数据库中对应任务的 GLUE 代码。具体信息记录在 xxl_job_logglue 表中。

-
发送任务信息:调度中心将任务信息(包括任务参数、GLUE 代码等)封装成一个请求,发送给执行器端服务。这个请求通常是通过 HTTP 或 RPC 协议进行传输的。
-
接收任务信息:执行器端服务接收到请求后,会根据请求中的信息来确定如何执行任务。对于 GLUE 模式的任务,执行器会获取其中的 GLUE 代码。
-
动态编译执行:执行器使用 Java 的动态编译技术(如 Java Compiler API 或其他第三方库)来编译 GLUE 代码,并创建一个新的类实例。然后,执行器会调用这个实例的
execute方法来执行任务逻辑。 -
返回结果:任务执行完成后,执行器将执行结果和日志信息发送回调度中心。调度中心会根据这些信息更新任务的执行状态和日志。
交互的实现原理:
- 动态编译:Java 提供了动态编译 API(
javax.tools.JavaCompiler),允许在运行时编译 Java 代码。执行器可以利用这个 API 将 GLUE 代码编译成 Java 类。 - 类加载器:编译完成后,执行器使用自定义的类加载器(ClassLoader)来加载这个新编译的类。这样,执行器就可以创建这个类的实例并调用其方法。
- 反射调用:执行器通过反射机制调用 GLUE 代码类的
execute方法,传入任务参数,并获取执行结果。 - 网络通信:调度中心和执行器之间的通信通常是基于 HTTP 或 RPC 协议的。调度中心作为客户端,向执行器发送请求;执行器作为服务端,接收请求并返回响应。
通过这种方式,GLUE 代码可以与执行器端服务进行交互,实现任务的动态执行。这种机制可以使任务代码可以在不重新部署执行器的情况下进行更新,提高了任务开发和维护的灵活性。
理解上述交互过程之后,下面来进行一个简单的演练,在执行器端添加如下 Service 和 Impl:
public interface GlueService {
/**
* 模拟数据库操作
*/
void dbOperation();
}
@Service
public class GlueServiceImpl implements GlueService {
@Override
public void dbOperation() {
// 模拟数据库操作
System.out.println("操作成功!");
}
}
接下来在 Web IDE 编辑刚才的任务:
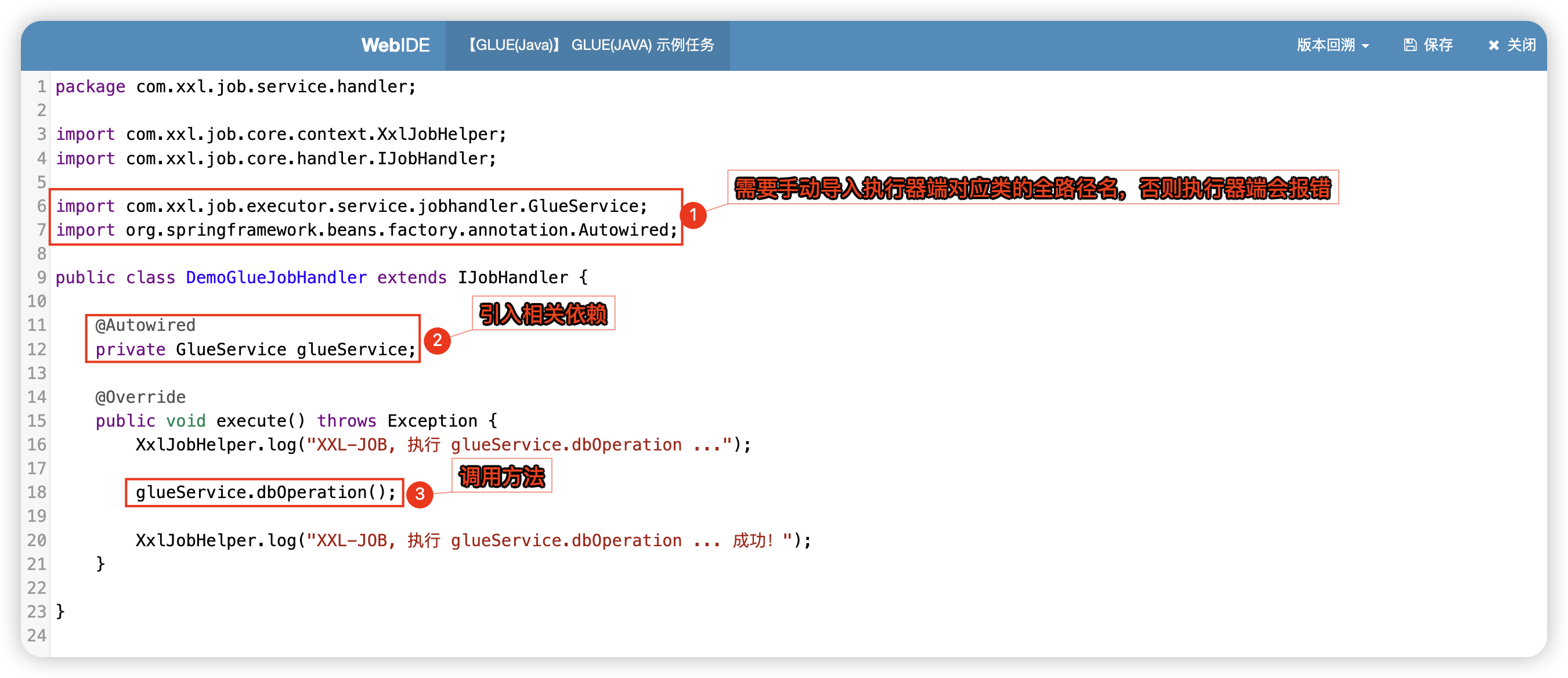
保存任务,执行一次,查看执行器端控制台输出:

分片广播
XXL-JOB 的分片广播是一种任务调度模式(前面我们有提到过),用于将一个大任务分成多个小任务(分片),并将这些小任务分发到不同的执行器实例上并行执行。每个执行器实例只负责处理一个或几个分片。这种模式适用于处理大量数据的场景,可以显著提高任务的处理效率。
分片广播适用于以下场景:
- 大数据处理:当需要处理的数据量非常大时,可以将数据分成多个分片,每个执行器实例处理一部分数据,实现并行处理。
- 资源分配:当任务需要在多台机器上平均分配资源时,可以使用分片广播,确保每台机器承担相同的工作量。
- 负载均衡:分片广播可以实现任务负载的均衡分配,避免某些执行器过载而其他执行器空闲。
假设有一个电商平台需要每天晚上定时统计每个商品的销售数据。由于商品数量庞大,如果只用一个任务处理所有商品的数据,效率会非常低。这时就可以使用分片广播将任务分成多个分片,每个执行器实例负责统计一部分商品的销售数据,最后汇总所有执行器的结果得到最终统计数据。
在执行器端创建示例任务:
package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
/**
* Description: 分片广播 Demo
*
* @author javgo
* @version 1.0
* @date 2024/3/31 14:20
*/
@Component
public class ShardingJobHandler {
@XxlJob("shardingJobHandlerDemo")
public void execute() throws Exception {
// 获取分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = " + shardIndex + ", 总分片数 = " + shardTotal);
// 根据分片参数执行相应的任务逻辑
for (int i = 0; i < shardTotal; i++) {
if (i == shardIndex) {
// 这里模拟处理当前分片的任务逻辑
XxlJobHelper.log("处理第 " + (i + 1) + " 个分片的任务");
System.out.println("处理第 " + (i + 1) + " 个分片的任务");
// TODO: 添加实际的任务处理逻辑
}
}
// 任务执行成功
XxlJobHelper.handleSuccess("分片任务执行成功");
}
}
上面我们通过 XxlJobHelper.getShardIndex() 和 XxlJobHelper.getShardTotal() 方法获取当前执行器的分片序号和总分片数,然后根据分片序号执行相应的任务逻辑。每个执行器实例只处理一个分片的任务,从而实现并行处理。
如何理解分片序号和总分片数呢?
在 XXL-JOB 的分片广播任务中,分片序号(Shard Index)和总分片数(Shard Total)用于确定每个执行器实例应该处理哪部分任务。
-
分片序号(Shard Index)
分片序号是指当前执行器实例在所有执行器实例中的序号。分片序号是从 0 开始的,所以如果有 N 个执行器实例,它们的分片序号分别是 0, 1, 2, …, N-1。分片序号用于确定每个执行器实例应该处理的任务分片。例如,如果一个任务被分成 5 个分片,那么分片序号为 0 的执行器实例将处理第 1 个分片的任务,分片序号为 1 的执行器实例将处理第 2 个分片的任务,以此类推。
-
总分片数(Shard Total)
总分片数是指任务被分成的分片总数。这个数值应该等于参与执行任务的执行器实例的数量。例如,如果一个任务被分成 5 个分片,那么总分片数就是 5。总分片数用于确定任务的分片数量,以及每个执行器实例应该处理哪个分片。每个执行器实例通过自己的分片序号来确定自己负责的分片。
假设有一个任务需要处理 100 条数据,我们将这个任务分成 5 个分片,每个分片处理 20 条数据。那么:
- 总分片数(Shard Total)为 5。
- 分片序号(Shard Index)分别为 0, 1, 2, 3, 4。
- 分片序号为 0 的执行器实例处理第 1-20 条数据。
- 分片序号为 1 的执行器实例处理第 21-40 条数据。
- 以此类推,直到分片序号为 4 的执行器实例处理第 81-100 条数据。
通过这种方式,每个执行器实例只处理一部分数据,从而实现任务的并行处理和负载均衡。
为了演示分片处理效果,我们需要将执行器进行集群部署,为了模拟效果我们需要在 IDEA 中设置一下启动参数,从而开启多个集群。这里启动两个 SpringBoot 程序,通过 VM 参数修改 Tomcat 端口和执行器端口。
编辑运行配置:

第一个执行器 Tomcat 端口 8081 程序的命令行参数如下:
-Dserver.port=8081 -Dxxl.job.executor.port=9999
点击 Modify options 添加 JVM 运行参数:
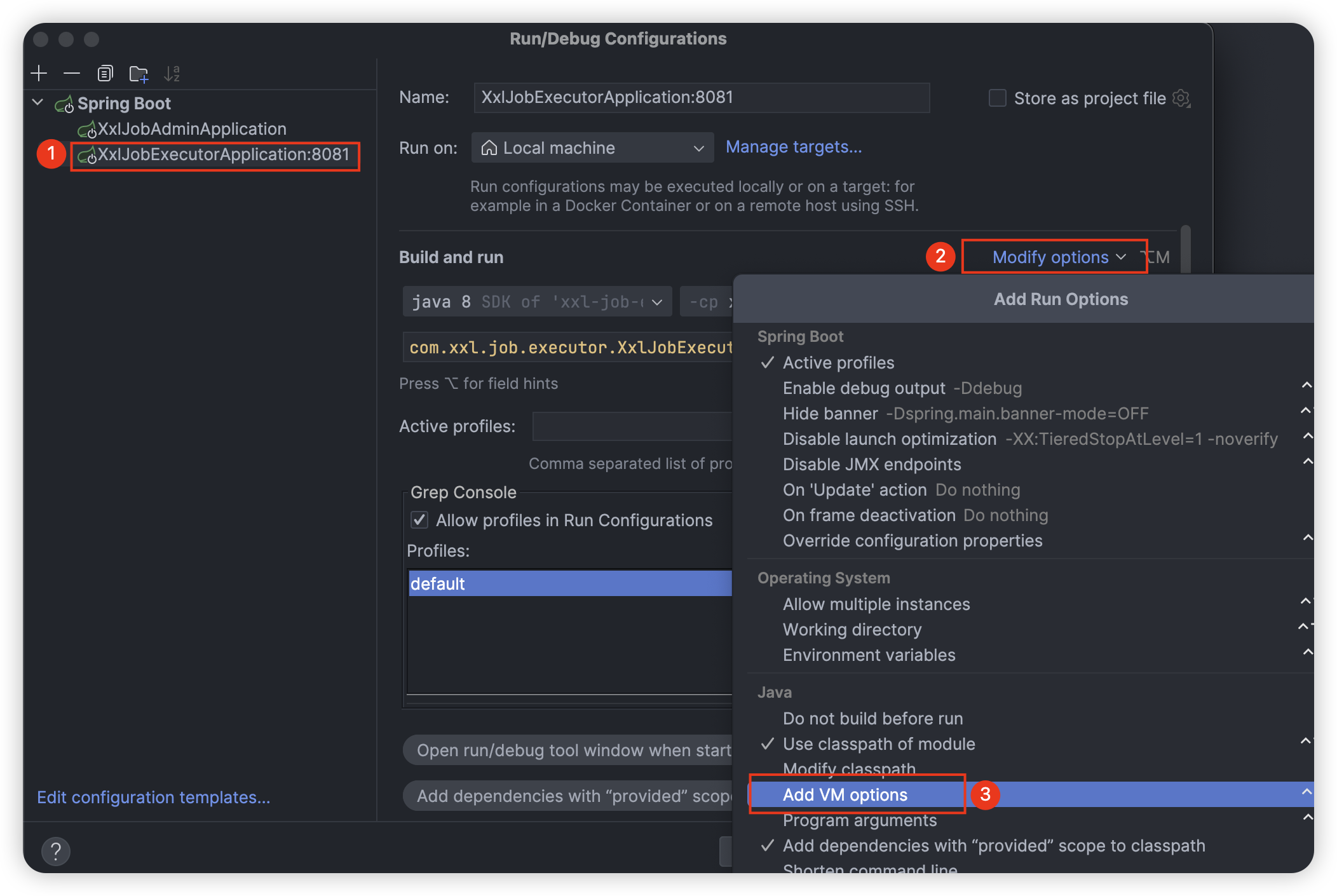
填入 -Dserver.port=8081 -Dxxl.job.executor.port=9999 即可:

第二个执行器 Tomcat 端口 8090 程序的命令行参数如下:
-Dserver.port=8082 -Dxxl.job.executor.port=9998
操作相同,这里不再赘述。最终我们会得到如下两个执行器实例:

运行这两个执行器实例,然后在调度中心就可以看到注册上去了:
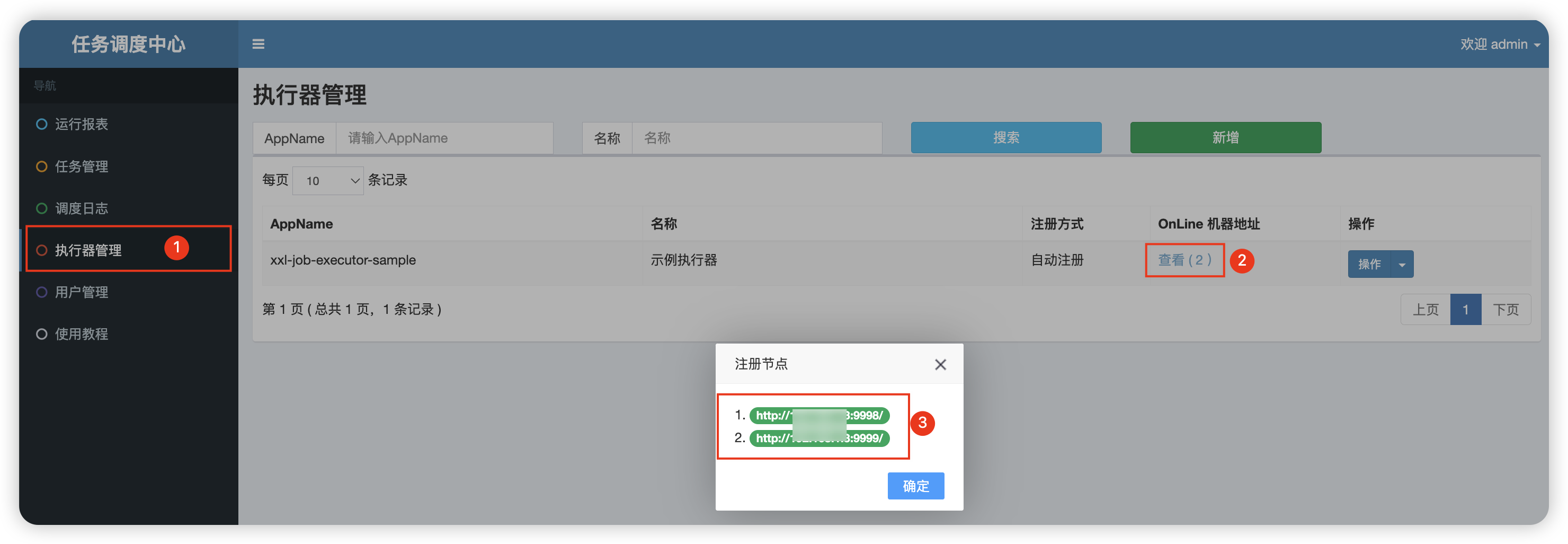
然后创建一个 shardingJobHandlerDemo 任务:
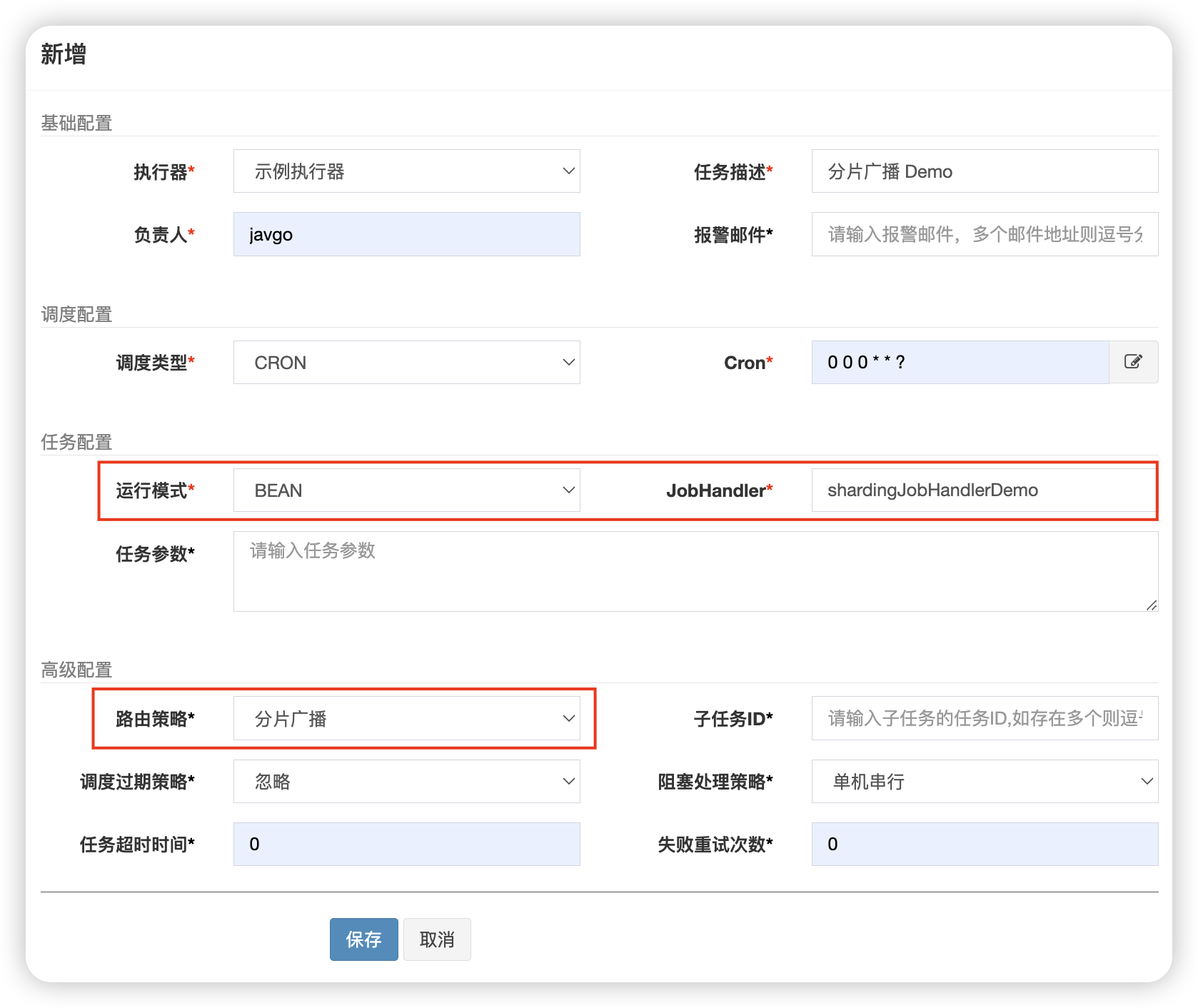
执行一次该任务,观察执行器端控制台输出:(点击【启动】就会一直周期性按照 Cron 执行,这里为了演示效果我们都采用【执行一次】):
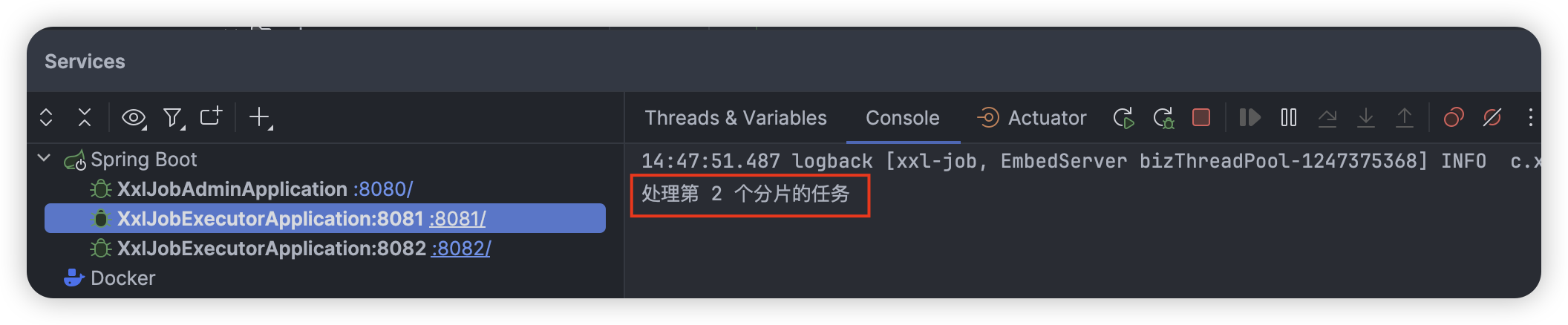

可以看到,我们的总分片数(Shard Total)为 2,分片序号(Shard Index)分别为 0,1。因此两个实例,各自会处理属于自己的分片的任务,不属于的则忽略。上面只是一个简单的案例,在实际生产中根据具体业务灵活修改即可。
任务参数接收
XXL-JOB 允许在调度任务时传递参数给任务处理器(JobHandler)。任务处理器可以通过 XxlJobHelper.getJobParam() 方法获取这些参数,并根据需要进行处理。
当你在调度中心配置一个任务时,可以在 “任务参数” 字段中填写需要传递给任务处理器的参数。这些参数会在任务执行时传递给任务处理器。
假设你有一个任务处理器,需要根据传递的参数执行不同的数据库查询操作:
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
@Component
public class DatabaseJobHandler {
@XxlJob("databaseJobHandler")
public void execute() throws Exception {
// 获取任务参数
String param = XxlJobHelper.getJobParam();
XxlJobHelper.log("Received parameter: " + param);
// 根据参数执行不同的数据库操作
if ("query1".equals(param)) {
// 执行查询操作1
XxlJobHelper.log("Executing query operation 1");
} else if ("query2".equals(param)) {
// 执行查询操作2
XxlJobHelper.log("Executing query operation 2");
} else {
XxlJobHelper.log("Unknown parameter: " + param);
}
// 任务执行成功
XxlJobHelper.handleSuccess("Database operation completed successfully");
}
}
在这个示例中,任务处理器 DatabaseJobHandler 会根据传递的参数执行不同的数据库查询操作。当你在调度中心配置任务时,可以在 “任务参数” 字段中填写 query1 或 query2 来指定需要执行的查询操作。
⚠️ 注意:
- 确保任务参数的格式和内容与任务处理器的预期相匹配。
- 对于复杂的参数,可以考虑使用 JSON 或其他格式进行编码,然后在任务处理器中解析这些参数。
- 在使用参数进行操作(如数据库查询)时,应注意参数的验证和安全处理,避免潜在的安全风险。
再看看一个 Json 参数的示例,假设你需要传递一个包含用户名和年龄的 JSON 参数给任务处理器,任务处理器根据这个参数执行相应的逻辑:
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
import com.fasterxml.jackson.databind.ObjectMapper;
@Component
public class UserJobHandler {
@XxlJob("userJobHandler")
public void execute() throws Exception {
// 获取任务参数
String param = XxlJobHelper.getJobParam();
XxlJobHelper.log("Received JSON parameter: " + param);
// 将 JSON 参数解析为 Java 对象
ObjectMapper objectMapper = new ObjectMapper();
User user = objectMapper.readValue(param, User.class);
// 根据解析出的用户信息执行相应的逻辑
XxlJobHelper.log("User name: " + user.getName());
XxlJobHelper.log("User age: " + user.getAge());
// 任务执行成功
XxlJobHelper.handleSuccess("User information processed successfully");
}
// 定义一个内部类来表示用户信息
public static class User {
private String name;
private int age;
// Getter and setter methods
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
}
在调度中心配置任务时,在 “任务参数” 字段中填写如下 JSON 参数:
{
"name": "John",
"age": 30
}
⚠️ 注意:
- 确保 JSON 参数的格式正确,且与任务处理器中定义的 Java 对象结构相匹配。
- 使用合适的 JSON 解析库(如 Jackson)来解析 JSON 参数。
- 在处理解析后的数据时,应注意数据的验证和安全处理。
这部分比较简单,就是多了参数而已,就不进行图示了,感兴趣的自己动手实操一下。
项目集成
最后简单了解一下我们应该如何将 XXL-JOB 引入现有项目。首先就是将 XXL-JOB 对应的数据库表初始化到我们的数据库中,开篇已经讲过,这里不再重复。
然后如果有需要的话,可以将 xxl-job-admin 改一个项目名作为一个单独的模块,通过 Maven 的方式导入到我们的项目中,其中的包名、任务、配置信息等根据实际项目情况进行调整即可:
导入后的示例如下:
然后在父 pom.xml 文件中引入对应模块作为子模块:
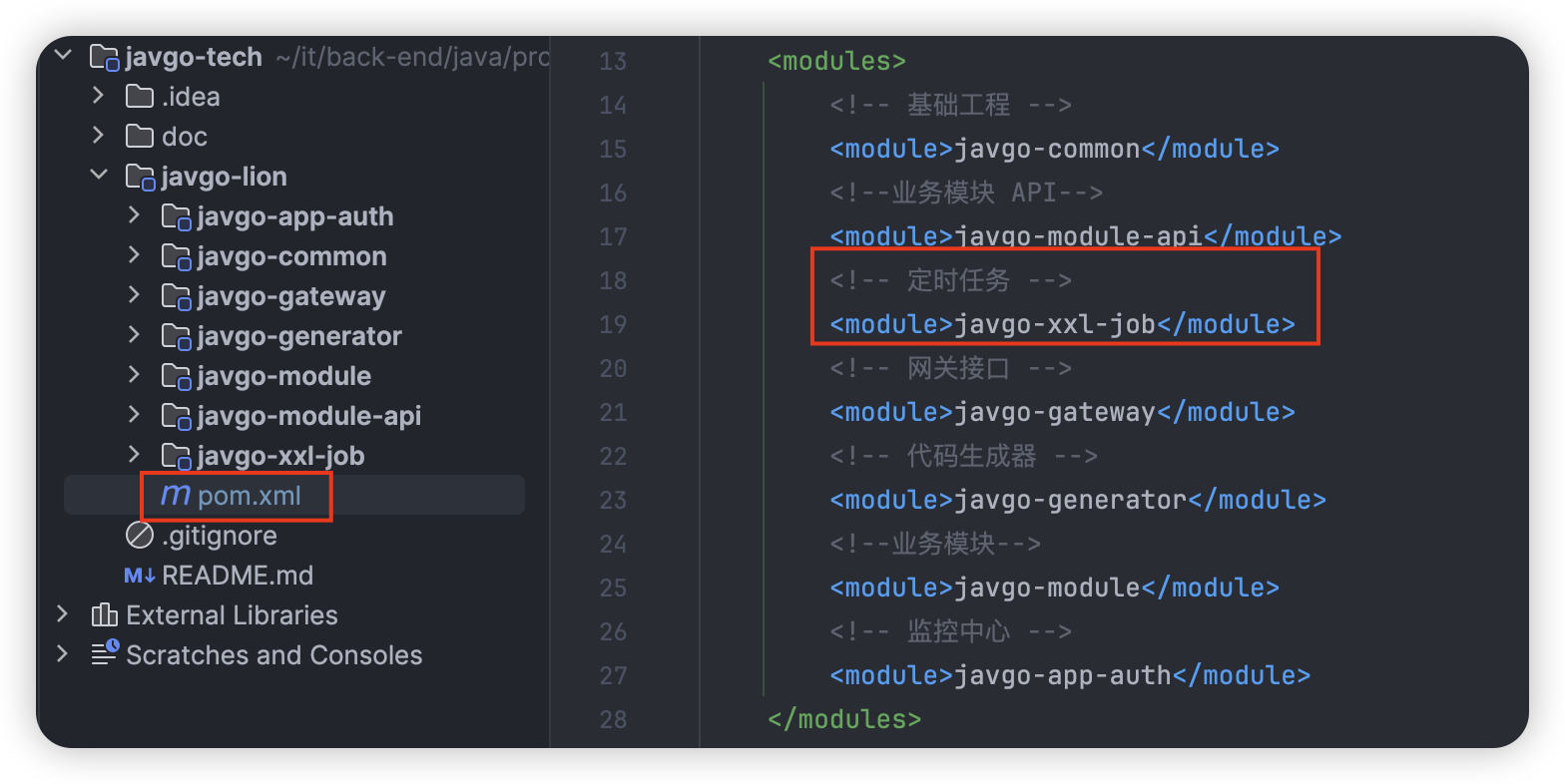
并在父 pom.xml 文件中加入 XXL-JOB 的依赖:
<!-- xxl-job -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${xxl-job.version}</version>
</dependency>
最后需要使用定时任务的模块就可以通过前面讲的内容根据实际业务需求进行开发了。
OK,本文到此结束,如果对你有帮助,记得一件三连哈!更多使用方式可以参照官方文档,相信了解了本文再去看官方文档就会更加得心应手了。
参考资料:
- https://help.aliyun.com/zh/ecs/user-guide/cron-expressions
- https://www.xuxueli.com/xxl-job/
- https://www.bilibili.com/video/BV1824y1G7vT/?p=12&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=33e83c443fa579f82f284597d474a238