Kafka 生产者
生产者就是负责向 Kafka 发送消息的。
生产者业务逻辑
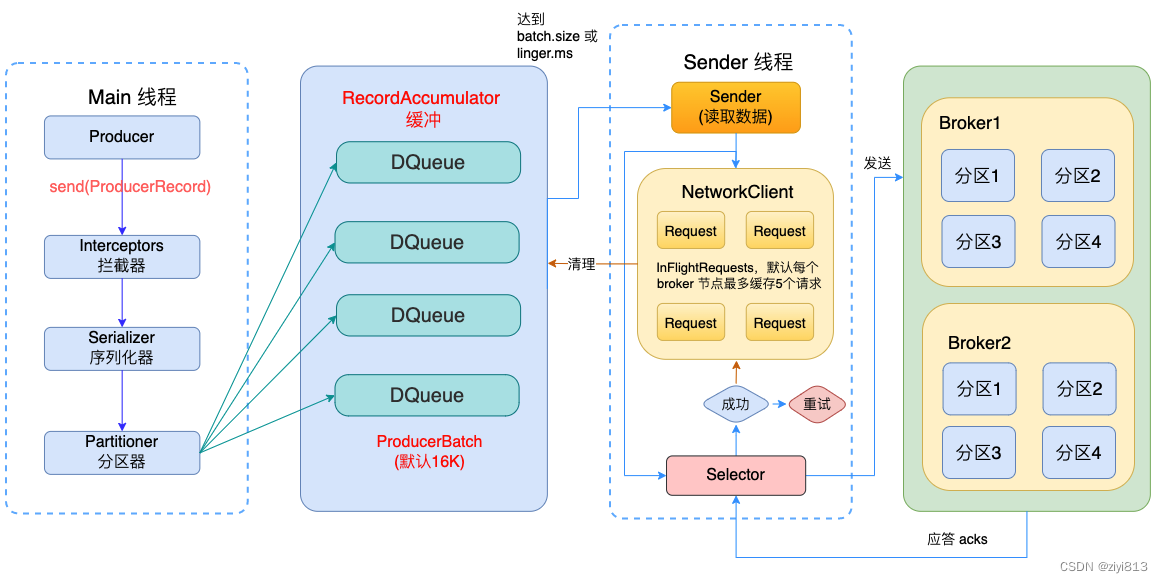
(生产者业务逻辑流程)
生产者开发示例
一个正常的生产逻辑流程如下:
-
- 配置生产者客户端参数及创建相应的生产者实例
-
- 构建待发送的消息
-
- 发送消息
-
- 关闭生产者实例
生产者客户端示例代码
pom文件
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.2</version>
<type>jar</type>
</dependency>
</dependencies>
简单的java代码示例:
package cn.litchicloud.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducer {
public static final String brokerList = "192.168.142.129:9092";
public static final String topic = "topic-demo";
public static Properties initConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
for(int i =0 ; i<5; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello kafka java-" + i);
producer.send(record);
}
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
开启消息者终端调试:

发送消息主要有三种模式
- 发后即忘(fire-and-forget),异步无回调
- 同步(sync)
- 异步有回调(async)
KafkaProducer的send()方法并非是void类型,而是Future类型,send()方法有两个重载方法,如下:
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return this.send(record, (Callback)null);
}
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return this.doSend(interceptedRecord, callback);
}
同步发送
实现同步的发送方式,使用返回的Future对象实现。
示例:
public static final String brokerList = "192.168.142.129:9092";
public static final String topic = "topic-demo";
public static Properties initConfig() {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello kafka ");
producer.send(record).get();
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
producer.close();
}
实际上send()方法本身就是异步的,send()方法返回的Future对象可以使用调用稍后获得的发送结果。
示例中调用了get()方法来阻塞等待Kafka的响应,直接消息发送成功或者发送异常。如果发送异常就捕获异常交给外层的逻辑处理。
Futer表示一个任务的生命周期,并提供了相应的方法来判断任务是否已经完成或取消,以及获取任务的结果和取消任务等。
KafkaProducer.send()方法的返回值是一个Future类型的对象,可以使用Future中的get(ling timeout, timeUnit unit)方法实现可超时的阻塞。
异步发送
一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。使用Callback的方式非常简单,Kafka有响应时就会回调 ,要么发送成功,要么抛出异常。
代码示例:
package cn.litchicloud.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerCallback {
public static final String brokerList = "192.168.142.129:9092";
public static final String topic = "topic-demo";
public static Properties initConfig() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
for(int i =0 ; i<5; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello kafka java-" + i);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
// 打印recordMatadata数据
System.out.println("partition:" + recordMetadata.partition()+",offset:" + recordMetadata.offset());
} else {
// 抛出异常
e.printStackTrace();
}
}
});
}
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
onCompletion()方法的两个参数是互斥的,消息发送成功时,metadata不为null而exception为null;消息发送异常时,metadata为null而exception不为null。
回调函数也保证分区有序(同一个分区,消息1在消息2之前发送,KafkaProducer就能保证对应的回调 1在回调 2之前调用)。
发后即忘(fire-and-forget)
如果不使用get()阻塞,即默认就是异步发送,可以不带回调。
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello kafka java-" + i);
producer.send(record);
序列化
系统序列化框架
自定义序列化
package cn.litchicloud.kafka;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Person {
private String name;
private String address;
}
package cn.litchicloud.kafka;
import org.apache.kafka.common.serialization.Serializer;
import java.nio.ByteBuffer;
import java.util.Map;
public class PersonSerializer implements Serializer<Person> {
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String s, Person person) {
if(person == null) {
return null;
}
byte[] name, address;
try {
if(person.getName() != null) {
name = person.getName().getBytes("UTF-8");
} else {
name = new byte[0];
}
if(person.getAddress() != null) {
address = person.getAddress().getBytes("UTF-8");
} else {
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate( 4+4+name.length + address.length );
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (Exception e) {
e.printStackTrace();
}
return new byte[0];
}
@Override
public void close() {
}
}
使用:
ProducerConfig配置我们自己创建的序列号器即可。
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, PersonSerializer.class.getName());
分区
Kafka分区的好处
- 便于合理的使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块的数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- 提高并行度,生产者可以以分区为单位发送数据,消费者可以以分区为单位进行消费数据。
生产者发送消息的分区策略
默认的分区器DefaultPartition
默认分区采用以下三种分区策略:
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略(2.4.0版本开始),关于粘性分区请参阅 KIP-480。
什么是粘性分区Sticky Partitioner:
首先,我们指定,Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 这个Batch可能包含多条消息,然后再将Batch打包发送
随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次的分区不同)
例如:
第一次随机选择了0号分区,等0号分区当前批次满了
自定义分区器策略
package cn.litchicloud.kafka;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class CustomPartition implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// todo 关键代码这里根据业务逻辑自定义义分区器逻辑
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
使用自定义分区器
在ProducerConfig中添加ProducerConfig.PARTITIONER_CLASS_CONFIG
// 自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartition.class.getName());



![LeetCode[692]前K个高频单词](https://img-blog.csdnimg.cn/img_convert/d971335fe8094c4889e0695687ec6ae3.png)




![【洛谷】P1966 [NOIP2013 提高组] 火柴排队](https://img-blog.csdnimg.cn/img_convert/f14414d796c4d0c61648612e0aebf3e6.png)