目录
正则
RE概念
常见的元字符
量词
贪婪&惰性
修饰符
re模块
findall
finditer
search
match
预加载正则式
内容提取
正则
RE概念

常见的元字符

量词

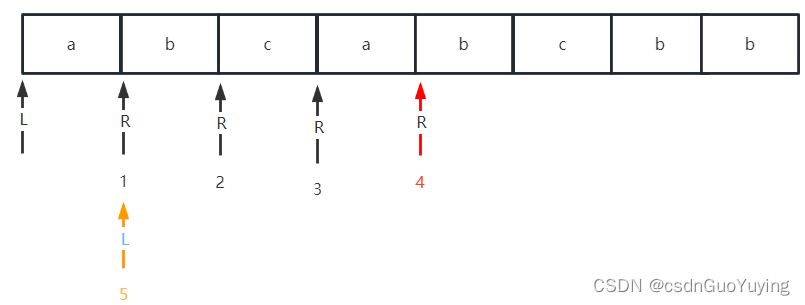
贪婪&惰性
贪婪匹配.*
惰性匹配.*?
修饰符
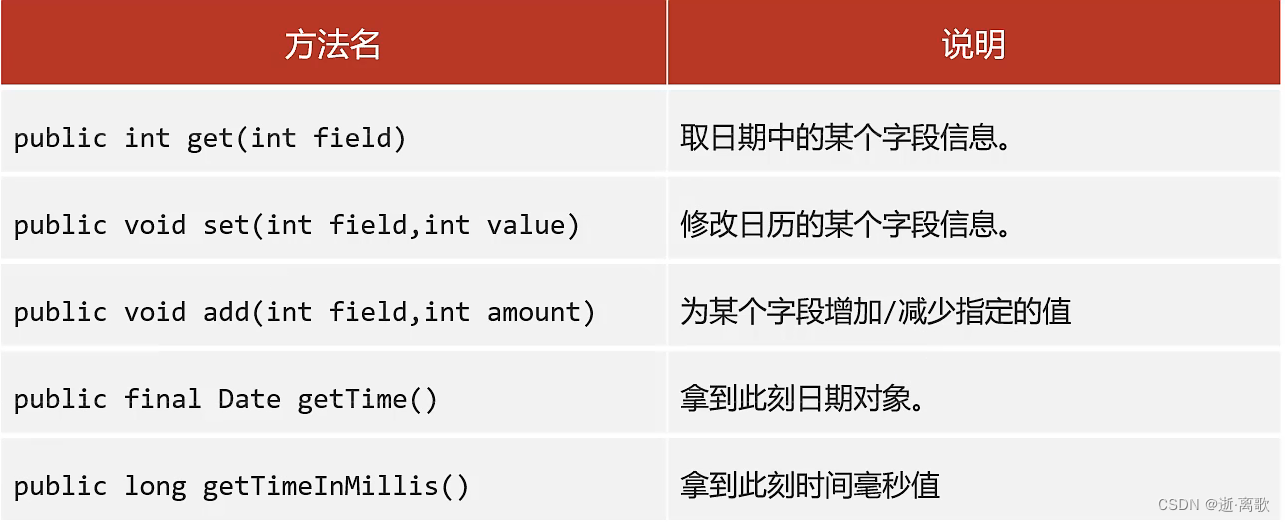
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
re模块
findall
import re
# findall:匹配所有符合正则规则的内容
my_list=re.findall(r"\d+","电话号码是:10011,我女友的电话是:10012")
print(my_list)返回一个列表(效率较低)['10011', '10012']
finditer
import re
# finditer 匹配后返回迭代器(效率高)
my_it=re.finditer(r"\d+","电话号码是:10011,我女友的电话是:10012")
print(my_it)
for i in my_it:
print(i.group())
print(i)<callable_iterator object at 0x0000011D90A33D60>
10011
<re.Match object; span=(6, 11), match='10011'>
10012
<re.Match object; span=(20, 25), match='10012'>
search
import re
# search:找到一个结果就返回
s=re.search(r"\d+","电话号码是:10011,我女友的电话是:10012")
print(s.group())返回一个match对象,通过.group读取。
10011
match
s=re.match(r"\d+","电话号码是:10011,我女友的电话是:10012")
print(s.group())报错,mathc默认为从头开始匹配,即此刻正则变为^\d+
预加载正则式
obj=re.compile(r"\d+")
ret=obj.finditer("电话号码是:10011,我女友的电话是:10012")
for i in ret:
print(i.group())10011
10012
内容提取
(?P<分组名字>正则表达式)
import re
s="""
<div class='coleak1'><span id='111'>coleaks5</span></div>
<div class='coleak2'><span id='222'>coleaks6</span></div>
<div class='coleak3'><span id='333'>coleaks7</span></div>
<div class='coleak4'><span id='444'>coleaks8</span></div>
"""
obj=re.compile(r"<div class='.*?'><span id='\d+'>(?P<xiao>.*?)</span></div>",re.S)
# re.S:让.能匹配换行符
res=obj.finditer(s)
for i in res:
print(i.group("xiao"))coleaks5
coleaks6
coleaks7
coleaks8