1 集群调度
2 调度简介
Scheduler是kubernetes的调度器,主要任务是把定义的pod分配到集群的节点上。听起来非常简单,但有很多要考虑的问题
¤ 公平: 如何保证每个节点都能被分配资源
¤ 资源高效利用:集群所有资源最大化被使用
¤ 效率:调度的性能要好,能够尽快地对大批量的pod完成调度工作
¤ 灵活: 允许用户根据自己的需求控制调度的逻辑
Schduler是最为单独的程序运行的,启动之后会一直坚挺API Server,获取PodSpec.NodeName为空的pod,对每个pod都会创建一个binding,表明该pod应该放到那个节点上。
这里的PodSpec.NodeName不为空的pod,说明我们手动指定了这个pod应该部署在哪个node上,所以这种情况Sheduler就不需要参与进来了
3 调度过程
(1)整体流程
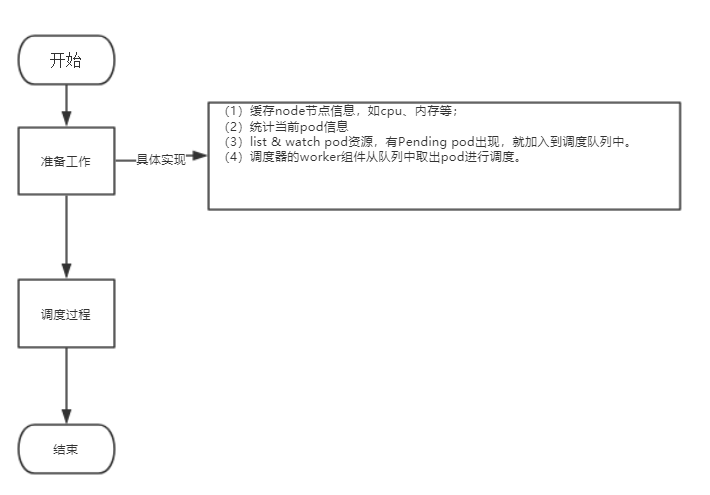
(2)调度过程

(3)抢占过程
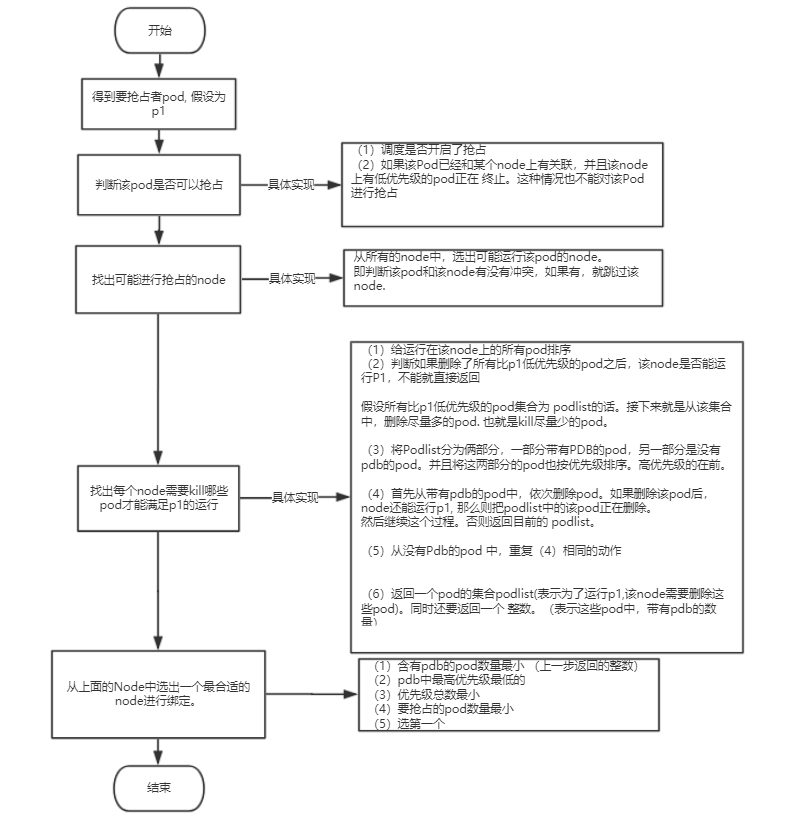
调度过程分为两部分,如果中间任何一步骤有错误,直接返回错误:
1)predicate(预选): 首先是过滤掉不满足条件的节点
2)priority(优选): 然后从中选择优先级最高的节点
Predicate(预选)有一系列的算法可以使用:
1)PodFitsResources: 节点上剩余的资源是否大于pod请求的资源
2)Podfitshost: 如果pod指定了NodeName,检查节点名称是否和NodeName相匹配
3)PodFfitsHostPorts: 节点上已经使用的port是否和 pod申请的port冲突
4)PodSelectorMatches: 过滤掉和 pod指定的label不匹配的节点
5)NoDiskConflict: 已经mount的volume和 pod指定的volume不冲突,除非它们都是只读
注意:如果在predicate过程中没有合适的节点。pod会一直在pending状态,不断重试调度,直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续priorities过程
Priorities(优选)是按照优先级大小对节点排序
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:
1)LeastRequestedPriority:通过计算CPU和 Memory的使用率来决定权重,使用率越低权重越高。换句话说,这个优先级指标倾向于资源使用比例更低的节点
2)BalancedResourceA1location:节点上CPU和Memory 使用率越接近,权重越高。这个应该和上面的一起使用,不应该单独使用
3)ImageLocalityPriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。
通过算法对所有的优先级项目和权重进行计算,得出最终的结果。上面只是常见的算法,还有很多算法可以到官网查阅。
总结:
调度分为两部分
1,预选:先过滤掉不满足条件的Node
2,优选:然后从中选择优先级最高的节点
如果有合适的就根据算法选一个优先级最高的节点,绑定pod到指定node,如果没有就进入抢占环节,如果有合适的就绑定节点,没有的话就重新加入调度队列
4 自定义调度器
除了kubernetes自带的调度器,你也可以编写自己的调度器。通过spec:schedulername参数指定调度器的名字,可以为pod选择某个调度器进行调整。比如下面的pod选择my-scheduler 进行调度,而不是默认的 default-scheduler:

![LeetCode[692]前K个高频单词](https://img-blog.csdnimg.cn/img_convert/d971335fe8094c4889e0695687ec6ae3.png)




![【洛谷】P1966 [NOIP2013 提高组] 火柴排队](https://img-blog.csdnimg.cn/img_convert/f14414d796c4d0c61648612e0aebf3e6.png)