Pandas操作MultiIndex合并行列的excel,写入读取以及写入多余行及Index列处理
- 1. 效果图及问题
- 2. 源码
- 参考
今天是谁写Pandas的 复合索引MultiIndex,写的糊糊涂涂,晕晕乎乎。
是我呀…
记录下,现在终于灵台清明了。
明天在记录下直接用 openpyxl 生成合并单元格,事半功倍。
跟在Java一样,可以参考之前的博客:Java Excel导出复杂excel表格样式之ExcelUtil工具类
1. 效果图及问题
可以生成MultiIndex列的excel,但是输出会多index列及第3行多一行空行,如下图所示:
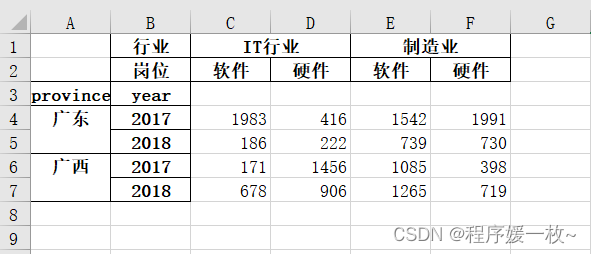
A列Index和第3行 都只是隐藏,并没有真正删除
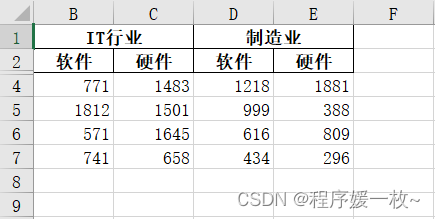
writer.sheets[sheetName].set_row(2, None, None, {‘hidden’: True}) # 删除表格第3行空白行
writer.sheets[sheetName].set_row(2, 0) # 或者设置高度为0,效果图如下:
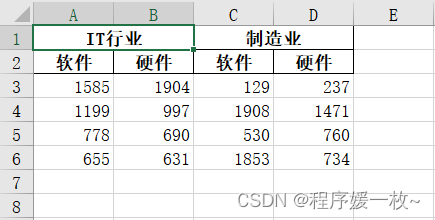
真正删除需要用openpyxl
wb._sheets[0].delete_rows(3) # 删除表格第3行空白行,效果图如下:
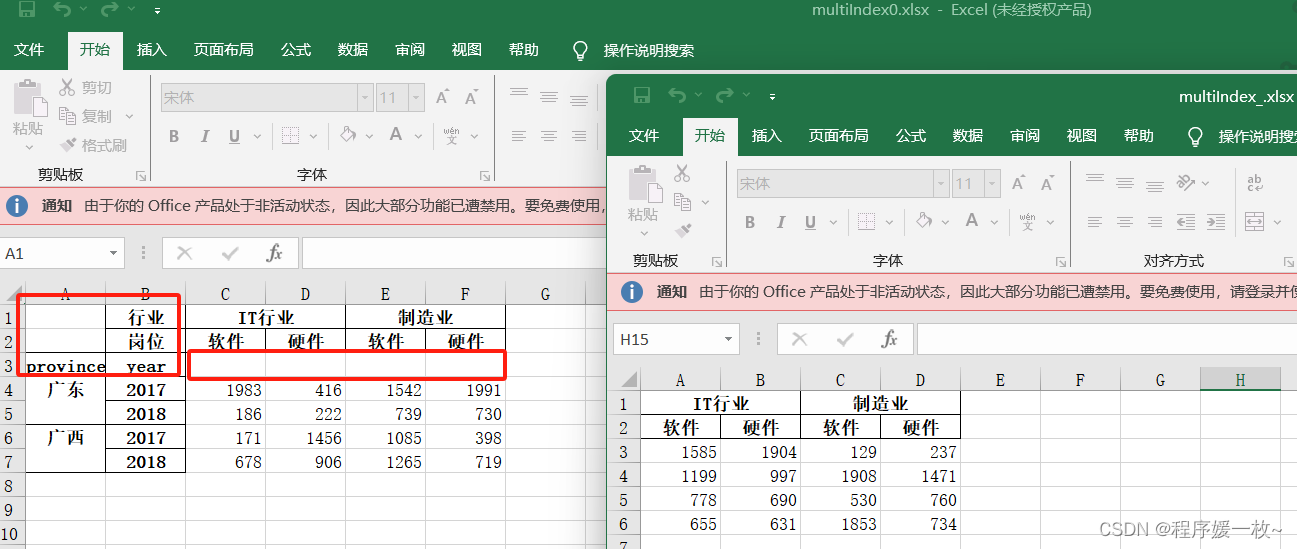
原始及openpyxl 最终效果:对比图如下:
构造一个pd Wooksheet,在第2行插入一条数据,效果图如下:
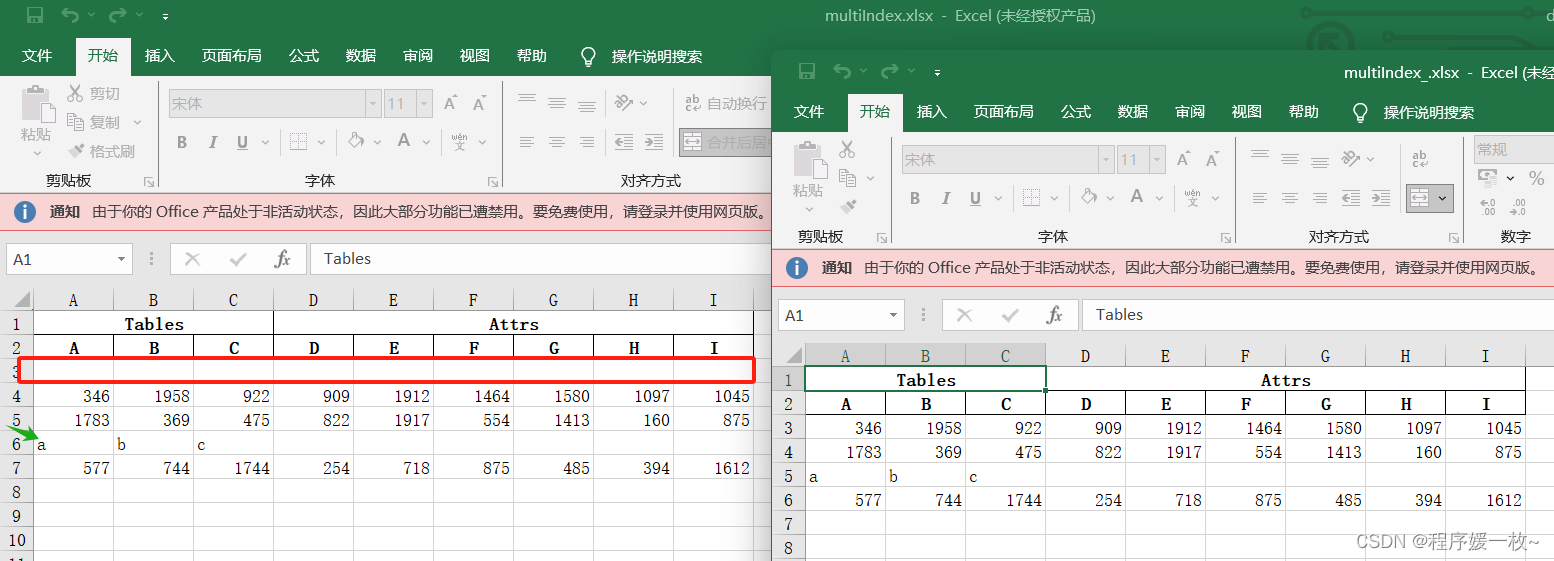
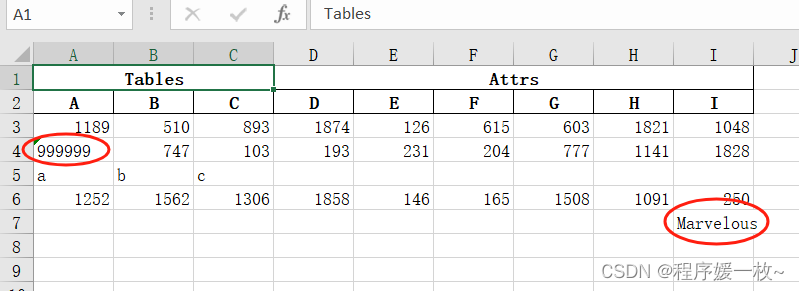
修改某个单元格的值:效果图可以看到成功修改
2. 源码
注意:openpyxl行数从1开始,pd.ExcelWriter行数从0开始
# 生成合并行列的MultiIndex数据,表格插入行
# python multiIndexPandas.py
# https://blog.csdn.net/HQ1356466973/article/details/83588993
import numpy as np
import openpyxl
import pandas as pd
# pandas 插入行
def insertRows(df, cnt, df_add):
dfStart = df[0:cnt]
dfEnd = df[cnt:]
return pd.concat([dfStart, df_add, dfEnd])
# fileName 文件名称,
# argument 是否需要生成index列
def write2ExcelOrigin(fileName, argument='False'):
writer = pd.ExcelWriter(fileName, engine='xlsxwriter') # 可以实现将多个dataframe按不同sheet,保存在一个excel中。
sheetName = 'Sheet1'
if (argument == 'True'):
df_all.to_excel(writer, sheet_name=sheetName)
pd2.to_excel(writer, sheet_name='table')
elif (argument == 'False'):
df_all.to_excel(writer, sheet_name=sheetName, startcol=-2)
pd2.to_excel(writer, sheet_name='table', startcol=-1)
# # startcol=-1 可以不输出index列
# df_all.to_excel(writer, sheet_name=sheetName, startcol=-2)
# pd2.to_excel(writer, sheet_name='table', startcol=-1)
# writer.sheets[sheetName].set_column(0, 0, None, None, {'hidden': True}) # 删除表格第一列
#
# # 第3行 都只是隐藏,并没有真正删除
# writer.sheets[sheetName].set_row(2, None, None, {'hidden': True}) # 删除表格第3行空白行
# # 或者设置高度为0
# writer.sheets[sheetName].set_row(2, 0)
writer._save()
index = pd.MultiIndex.from_product([['广东', '广西'], [2017, 2018]], names=['province', 'year'])
columnMultiIndex = pd.MultiIndex.from_product([['IT行业', '制造业'], ['软件', '硬件']], names=['行业', '岗位'])
data = np.random.randint(100, 2000, size=(4, 4))
df_all = pd.DataFrame(data, index=index, columns=columnMultiIndex)
print(df_all)
df2Data = np.random.randint(100, 2000, size=(3, 9))
columnName = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
pd2 = pd.DataFrame(df2Data, columns=[['Tables'] * 3 + ['Attrs'] * 6, columnName])
valList = ['a', 'b', 'c']
valList.extend(np.zeros((len(columnName) - 3), dtype=str).tolist())
print(valList)
# pandas插入一行
df_add = pd.DataFrame(columns=pd2.columns, data=[valList])
# 在第2行插入数据 ['a', 'b', 'c', '', '', '', '', '', '']
pd2 = insertRows(pd2, 2, df_add)
# pandas修改某行某个单元格的值
pd2.loc[1, pd2.columns.values[0]] = '999999'
pd2.loc[3, pd2.columns.values[-1]] = 'Marvelous'
fileName = 'excel/multiIndex.xlsx'
write2ExcelOrigin(fileName, argument='False')
write2ExcelOrigin(fileName.replace(".xlsx", "0.xlsx"))
# 需要用openpyxl删除多余的第3行
wb = openpyxl.load_workbook(fileName) # 获取表格文件
# 批量修改多个sheet
wb._sheets[0].delete_rows(3) # 删除表格第3行空白行
wb._sheets[1].delete_rows(3) # 删除表格第3行空白行
wb.save(filename=fileName.replace(".xlsx", "_.xlsx"))
参考
- 复合索引构造pandas数据:https://blog.csdn.net/HQ1356466973/article/details/83588993
- https://blog.csdn.net/m0_51212419/article/details/121681797
- https://blog.csdn.net/u011699626/article/details/135846298