Flume
Sink
HDFS Sink
-
将数据写到HDFS上。数据以文件形式落地到HDFS上,文件名默认是以
FlumeData开头,可以通过hdfs.filePrefix来修改 -
HDFS Sink默认每隔30s会滚动一次生成一个文件,因此会导致在HDFS上生成大量的小文件,实际过程中,需要通过
hdfs.rollInterval来修改,一般设置为3600s或者86400s。如果设置为0,那么表示不滚动,只生成1个文件 。 -
HDFS Sink默认每1024B会滚动一次生成一个文件,同样会导致产生更多的小文件,实际过程中,需要通过
hdfs.rollSize来修改,一般设置为134217728B。如果设置为0,那么表示不滚动,只生成1个文件 -
HDFS Sink默认每10条数据会滚动一次生成一个文件,同样会导致产生更多的小文件。实际过程中,需要通过
hdfs.rollCount来修改。如果设置为0,那么表示不滚动,只生成1个文件//不是每次生成文件才一次全部写入。每次启动,就会先创建文件,然后一条一条的写入Event,当达到设置的任一条件时,产生新的文件,并向新的文件写入。
-
HDFS Sink支持三种文件类型:
SequenceFile(序列文件,不能直接cat查看),DataStream(文本文件) orCompressedStream(压缩文件),默认使用的是SequenceFile。如果将文件类型设置为CompressedStream,那么还需要指定属性hdfs.codeC,支持gzip, bzip2, lzo, lzop, snappy -
案例
-
格式文件
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8090 a1.channels.c1.type = memory # 配置HDFS Sink # 类型必须是 a1.sinks.k1.type = hdfs # 数据在HDFS上的存储路径。路径不存在会自动创建 a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flume_data # 文件滚动间隔时间 a1.sinks.k1.hdfs.rollInterval = 3600 # 文件滚动大小 a1.sinks.k1.hdfs.rollSize = 134217728 # 文件滚动条数 a1.sinks.k1.hdfs.rollCount = 1000000000 # 文件类型 a1.sinks.k1.hdfs.fileType = DataStream a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1- 启动
flume-ng agent -n a1 -c $FLUME_HOME/conf -f hdfssink.properties -Dflume.root.logger=INFO,console- 在新的窗口中通过
nc来发送数据
nc hadoop01 8090
-
Logger Sink
- 将数据以日志写入到指定目的地,支持
console和file。实际开发过程中,使用的比较少,一般是教学阶段使用较多 - Logger Sink默认要求Event的body部分不能超过16个字节,可以通过
maxBytesToLog来调节 - Logger Sink对中文支持不好
File Roll Sink
-
将数据以文本文件形式存储到本地的磁盘上。可以通过属性
sink.serializer来修改,支持TEXT和avro_event -
类似于HDFS Sink,File Roll Sink默认也是每隔30s滚动一次生成一个文件,可以通过属性
sink.rollInterval来修改 -
案例
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8090 a1.channels.c1.type = memory # 配置File Roll Sink # 类型必须是file_roll a1.sinks.k1.type = file_roll # 数据在本地的存储路径 a1.sinks.k1.sink.directory = /opt/flume_data # 文件滚动间隔时间 a1.sinks.k1.sink.rollInterval = 3600 a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
AVRO Sink
-
将数据经过AVRO序列化之后来写出,结合AVRO Source来实现流动模型
-
多级流动

-
第一个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = exec //监控这个文件内容的变化 a1.sources.s1.command = tail -F /opt/software/flume-1.11.0/data/a.txt a1.sources.s1.shell = /bin/sh -c a1.channels.c1.type = memory //数据发送到hadoop02的7000端口 a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop02 a1.sinks.k1.port = 7000 a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1 -
第二个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 //监听本机7000端口的数据 a1.sources.s1.type = avro a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 7000 a1.channels.c1.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop03 a1.sinks.k1.port = 7000 a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1 -
第三个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = avro a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 7000 a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
启动顺序:hadoop03 hadoop02 hadoop01
-
-
扇入流动
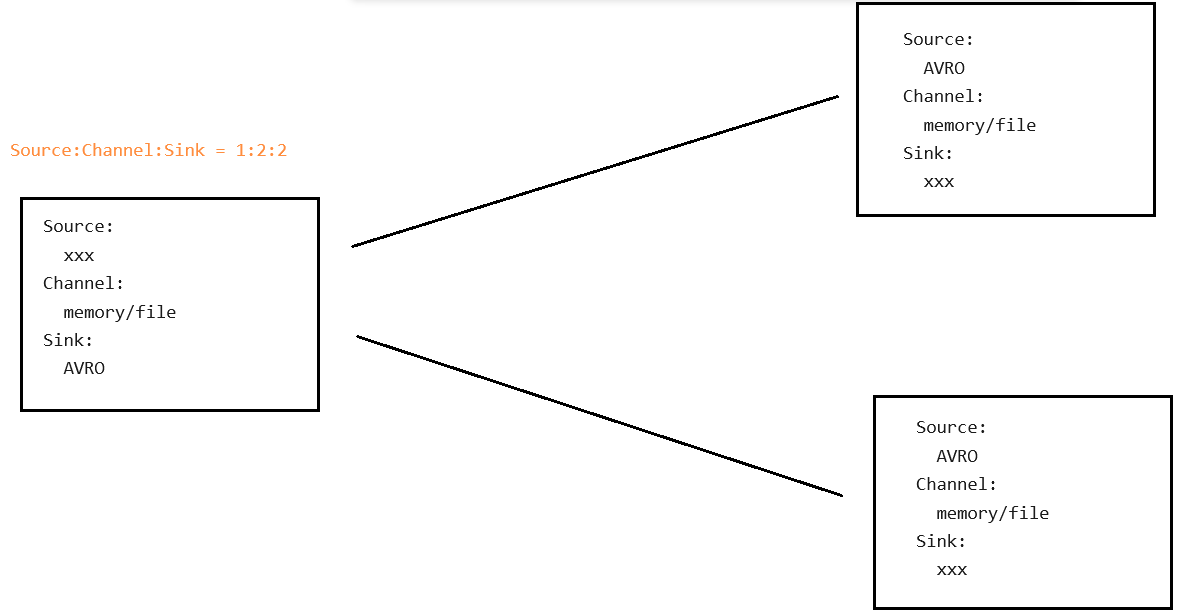
-
第一个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /opt/software/flume-1.11.0/data/a.txt a1.sources.s1.shell = /bin/sh -c a1.channels.c1.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop03 a1.sinks.k1.port = 6666 a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1 -
第二个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8000 a1.channels.c1.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop03 a1.sinks.k1.port = 6666 a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1 -
第三个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = avro a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 6666 a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
-
-
扇出流动

-
注意:在Flume中,可以从同一个数据源采集数据,放到不同的仓库(Channel)存储,但是每一个Sink只能对应1个Channel。一个Channel可对应多个Sink
-
第一个节点
a1.sources = s1 a1.channels = c1 c2 a1.sinks = k1 k2 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8000 a1.channels.c1.type = memory a1.channels.c2.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop02 a1.sinks.k1.port = 7000 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop03 a1.sinks.k2.port = 7000 a1.sources.s1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 -
第二个和第三个节点
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = avro a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 7000 a1.channels.c1.type = memory a1.sinks.k1.type = logger a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
-
自定义Sink
-
自定义Sink的时候,需要定义一个类继承
AbstractSink,实现Sink接口,最好还要实现Configurable接口来获取配置。注意,自定义Sink的过程中,需要关注事务问题。依赖和笔记1中用的一样。 -
public class AuthSinks extends AbstractSink implements Sink , Configurable { String path ; //打印流,打印到文件或者Flume的窗口。sout调用的就是这个类中的方法 PrintStream ps; @Override public void configure(Context context) { //从flume中的格式文件中获取路径信息 path = context.getString("path"); if(path == null || "".equals(path) || !path.startsWith("/")) throw new IllegalArgumentException(); } @Override public synchronized void start() { if(!path.endsWith("/")) path = path + "/"; path += String.valueOf(System.currentTimeMillis()); try { ps = new PrintStream(path); }catch (Exception e){ e.printStackTrace(); } } @Override public Status process() throws EventDeliveryException { Channel channel = this.getChannel(); Transaction ts = channel.getTransaction(); ts.begin(); Event e; try { while ((e = channel.take()) != null) { ps.println("headers:"); Map<String, String> map = e.getHeaders(); for (Map.Entry<String, String> header : map.entrySet()) { ps.println(header.getKey() + "-" + header.getValue()); } ps.println("bodys:"); byte[] body = e.getBody(); ps.println("\t" + new String(body)); } ts.commit(); return Status.READY; } catch (Exception e1) { ts.rollback(); return Status.BACKOFF; } finally { ts.close(); } } @Override public synchronized void stop() { if(ps != null) ps.close(); } } -
打成jar包放到lib目录下
cd /opt/software/flume-1.11.0/lib/ rz -
编辑格式文件
cd ../data/ vim authsink.properties在文件中添加
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = http a1.sources.s1.port = 8888 a1.channels.c1.type = memory # 配置自定义Sink # 类型必须是类的全路径名 a1.sinks.k1.type = com.fesco.sink.AuthSink # 存储路径 a1.sinks.k1.path = /opt/flume_data a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1 -
启动Flume
-
发送HTTP请求
curl -X POST -d '[{"headers":{"class":"big data","sinktype":"auth"},"body":"testing~~~"}]' http://hadoop01:8888
事务
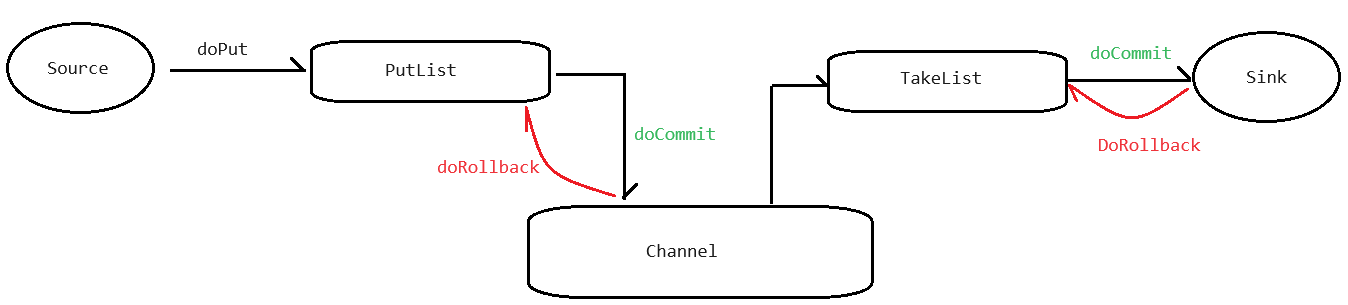
- Source会先执行doPut操作,将数据放入PutList中,PutList本质上是一个Deque
- PutList会试图将数据传输给Channel,如果成功,执行doCommit操作,如果失败,那么执行doRollback
- Channel收到数据之后,会试图将数据推送到TakeList,然后由TakeList将数据试图推送给Sink。TakeList本质上也是一个Deque
- 如果TakeList成功将数据推送给Sink,那么执行doCommit操作;反之,如果失败,那么执行doRollback操作
Channel
Memory Channel
- Memory Channel将数据临时存储到内存队列中,队列默认容量是100,即队列默认最多能存储100条数据,如果队列被放满,那么后续的操作会被阻塞。可以通过属性
capacity来调节,实际过程中一般会设置为100000~300000 transactionCapacity:事务容量。每次PutList向Channel推送的数据条数或者Channel向TakeList添加的数据条数,默认是100。实际过程中,这个值一般会调节为1000~3000- 需要注意的是,Memory Channel是将数据临时存储到内存中,所以读写速度相对较快,但是不可靠,因此适应于要求速度但是不要求可靠性的场景
File Channel
-
File Channel将数据临时存储到磁盘上,所以读写速度相对慢一些,但是可靠,因此适应于要求可靠性但不要求速度的场景
-
File Channel默认会将数据临时存储到
~/.flume/file-channel/data目录下,可以通过属性dataDirs来修改,如果指定了多个数据目录,那么目录之间用逗号隔开 -
File Channel支持断点续传,默认情况下,会将偏移量记录到
~/.flume/file-channel/checkpoint目录下,可以通过属性checkpointDir来修改 -
默认File Channel能够存储1000000条数据,可以通过属性
capacity来条件 -
File Channel最多能占用2146435071B的磁盘,可以通过
maxFileSize修改 -
File Channel的
transactionCapacity的默认值是10000 -
案例
a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8090 # 配置File Channel # 类型必须是file a1.channels.c1.type = file # 偏移量的存储位置 a1.channels.c1.checkpointDir = /opt/flume_data/checkpoint # 数据临时存储位置 a1.channels.c1.dataDirs = /opt/flume_data/data a1.sinks.k1.type = logger a1.sources.s1.channels = c1 a1.sinks.k1.channel = c1
其他Channel
- JDBC Channel:将数据临时存储到数据库,但是JDBC Channel目前只支持Derby数据库。基于Derby(微型、文件型、单连接)的特性,所以实际开发过程中,不适用这个Channel
- Spillable Memory Channel:内存溢出Channel。内存中维系一个队列,如果队列被放满,不会阻塞,而是会将数据临时存储到磁盘上,这个Channel目前还在实验阶段,不推荐在生产场景中使用
Selector
概述
- Selector并不是一个单独的组件,而是附属于Source的子组件
- Selector支持三种模式:
- replicating:复制/复用模式。节点收集到数据之后,会将数据复制,然后分发给每一个节点,此时每一个节点收到的数据都是相同的
- load balancing:负载均衡模式。节点收集到数据之后,会平均分发到其他的节点上。此时被扇出的节点接收到的数据条数大致相等,但是数据不相同。这种模式是Flume1.10提供的,然后不稳定
- multiplexing:路由/分发模式。节点收集到数据之后,会根据headers中的指定键和值,将数据分发给对应的节点来处理,此时每一个节点收到的数据都是不同的
- 扇出结构中,如果不指定,默认使用的是replicating模式
multiplexing
-
实际过程中,如果需要对数据进行分类处理,那么可以考虑使用路由/分发模式
-
案例
a1.sources = s1 a1.channels = c1 c2 a1.sinks = k1 k2 a1.sources.s1.type = http a1.sources.s1.port = 8000 # 指定Selector的类型 a1.sources.s1.selector.type = multiplexing # 指定监听的字段 a1.sources.s1.selector.header = kind # 根据kind字段的值分发给对应的Channel //如果请求头中的kind的值是video就传输给c1 通道 a1.sources.s1.selector.mapping.video = c1 a1.sources.s1.selector.mapping.music = c2 a1.sources.s1.selector.default = c2 a1.channels.c1.type = memory a1.channels.c2.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop02 a1.sinks.k1.port = 7000 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop03 a1.sinks.k2.port = 7000 a1.sources.s1.channels = c1 c2 a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
启动Flume之后,发送请求
```sh
curl -X POST -d '[{"headers":{"kind":"video"},"body":"video log"}]' http://hadoop01:8000
curl -X POST -d '[{"headers":{"kind":"music"},"body":"music log"}]' http://hadoop01:8000
curl -X POST -d '[{"headers":{"kind":"txt"},"body":"txt log"}]' http://hadoop01:8000
Sink Processor
概述
- Sink Processor本质上就是Sink Group,是将一个或者多个Sink绑定到一个组中来使用
- 目前,官网支持三种模式
default:默认模式。一个Sink就对应一个Sinkgroup,有几个Sink就对应了几个SinkgroupLoad Balancing:负载均衡。将多个Sink绑定到一个组中,然后将这个组接收到数据平均的发送给每一个Sink。支持round_robin(轮询)和random(随机)。同样,Flume提供的负载均衡模式并不好(能)用Failover:崩溃恢复。将多个Sink绑定到一个组中,如果现在工作的Sink宕机,同组中的其他Sink可以实现相同的功能,从而避免了单点故障
Failover
-
将多个Sink绑定到一个组中,同组的Sink需要配置优先级,数据会优先发送给优先级较高的Sink,如果高优先级的Sink宕机,那么才会发送给低优先级的Sink。当优先级高的Sink恢复后,那么数据又会重新回来。
-
案例
a1.sources = s1 a1.channels = c1 c2 a1.sinks = k1 k2 # 给Sinkgroup起名 a1.sinkgroups = g1 # 给Sinkgroup绑定Sink a1.sinkgroups.g1.sinks = k1 k2 # 指定Sinkgroup的类型 a1.sinkgroups.g1.processor.type = failover # 给Sink指定优先级 a1.sinkgroups.g1.processor.priority.k1 = 7 a1.sinkgroups.g1.processor.priority.k2 = 5 # 发送超时时间 # 默认是30000ms->30s 。这个属性的作用不是很理解 a1.sinkgroups.g1.processor.maxpenalty = 10000 a1.sources.s1.type = netcat a1.sources.s1.bind = 0.0.0.0 a1.sources.s1.port = 8000 a1.channels.c1.type = memory a1.channels.c2.type = memory a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop02 a1.sinks.k1.port = 7000 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop03 a1.sinks.k2.port = 7000 a1.sources.s1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2