目录
一、消息中间件介绍
1.1 消息中间件的作用
二、RabbitMQ
2.1 核心概念
2.2 生产者发送消息过程
2.3 消费者接收消息过程
2.4 RabbitMQ 为何要引入信道(channel)
2.5 消费模式
一、消息中间件介绍
消息队列中间件(message queue middleWare, MQ)指利用高效可靠消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程通信。
一般有两种传递模式:点对点模式和发布订阅模式。点对点的模式是基于队列的,消息生产者发送消息到队列,消费者从队列中接收消息,队列的存在使得消息的异步传输成为可能。发布订阅模式定义了如何向一个内容节点发布和订阅,这个内容节点称为主题(topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,消息订阅者从主题中订阅消息。
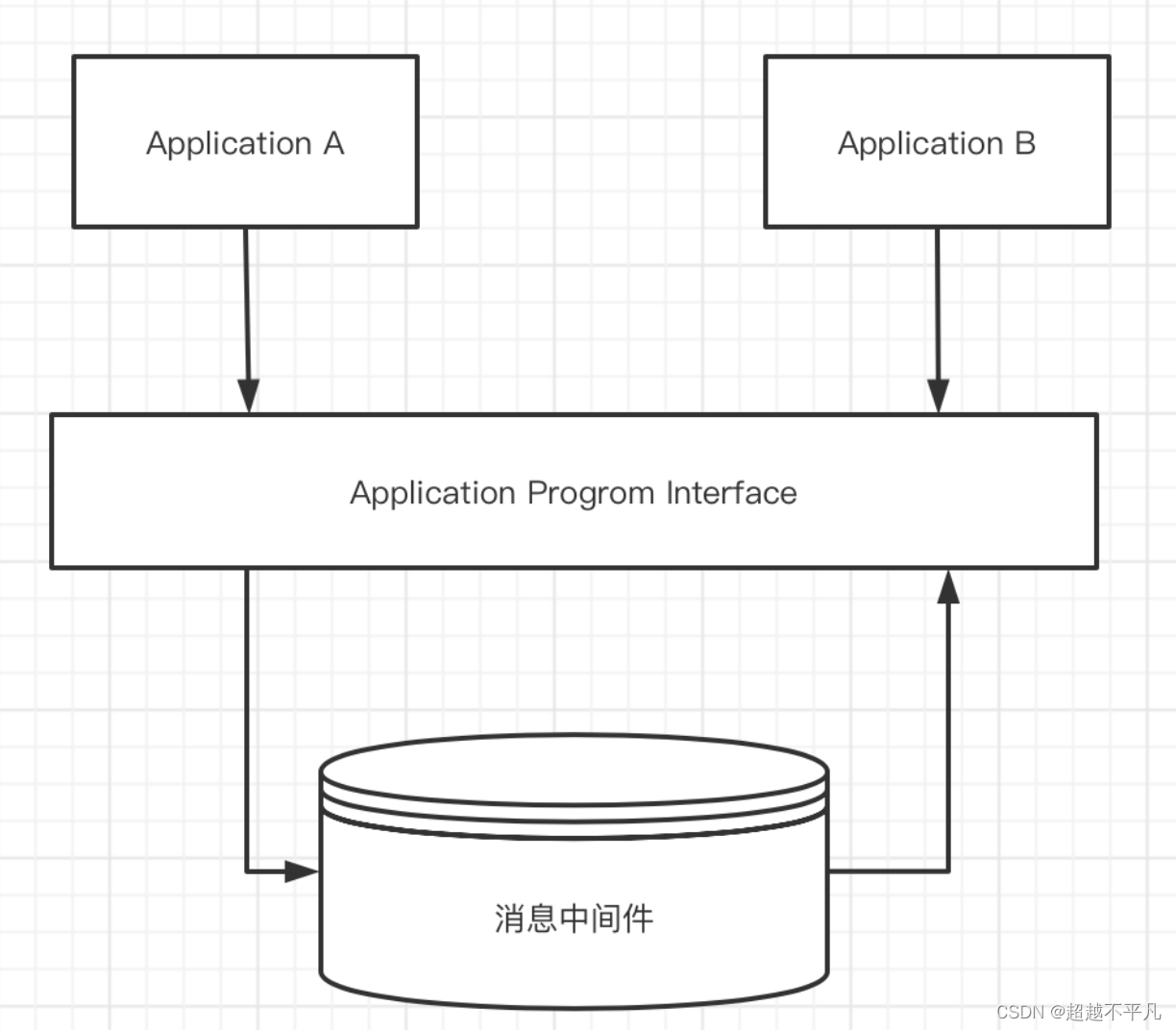
消息中间件将消息路由给应用程序B,这样消息可以完全存在于两台不同的计算机上。消息中间件负责网络通信,如果网络不可用,消息中间件会存储消息直到连接可用。
1.1 消息中间件的作用
解耦:生产者和消费者完全解耦,双方都感知不到对方的存在。
冗余(存储):有些情况数据处理会失败,消息中间件可以把数据进行持久化,直到他们已经被完全处理。通过这种方式规避数据丢失的风险。
扩展性:因为消息中间件解藕了应用的处理过程,所以提高消息入队和处理的效率很容易。
削峰:在访问剧增的情况下,应用仍然需要继续发挥作用,但这种突发的流量并不常见,如果以处理峰值的标准来投入资源,无疑是巨大的浪费,使用消息中间件支撑突发的流量,不会因为超负荷请求而完全奔溃。
可恢复性:当系统的一部分组件失效时不影响整个系统。降低了应用间的耦合性,系统恢复后还能继续处理消息。
顺序保证:大多数场景下,顺序处理数据很重要,大部分消息中间件支持一定程度上的顺序性。
缓冲:在任何重要的系统中,都会存在需要不同处理时间的元素,消息中间件通过一个缓冲层来帮助任务最高效率的执行,写入消息中间件的处理尽可能的快。该缓冲层有助于控制和优化数据流经过系统的速度。
异步通信:很多时候不需要立即处理消息,消息中间件提供了异步处理机制。
二、RabbitMQ
RabbitMQ 是一个开源的消息中间件(Message Broker),遵循 Advanced Message Queuing Protocol (AMQP) 标准协议。它允许应用程序通过发送和接收消息来进行异步通信,从而实现系统之间的松耦合和解耦合。RabbitMQ 支持多种操作系统,广泛应用于分布式系统架构中,尤其是在微服务、异步处理、负载均衡、峰值负载处理、消息队列、事件驱动架构等领域。
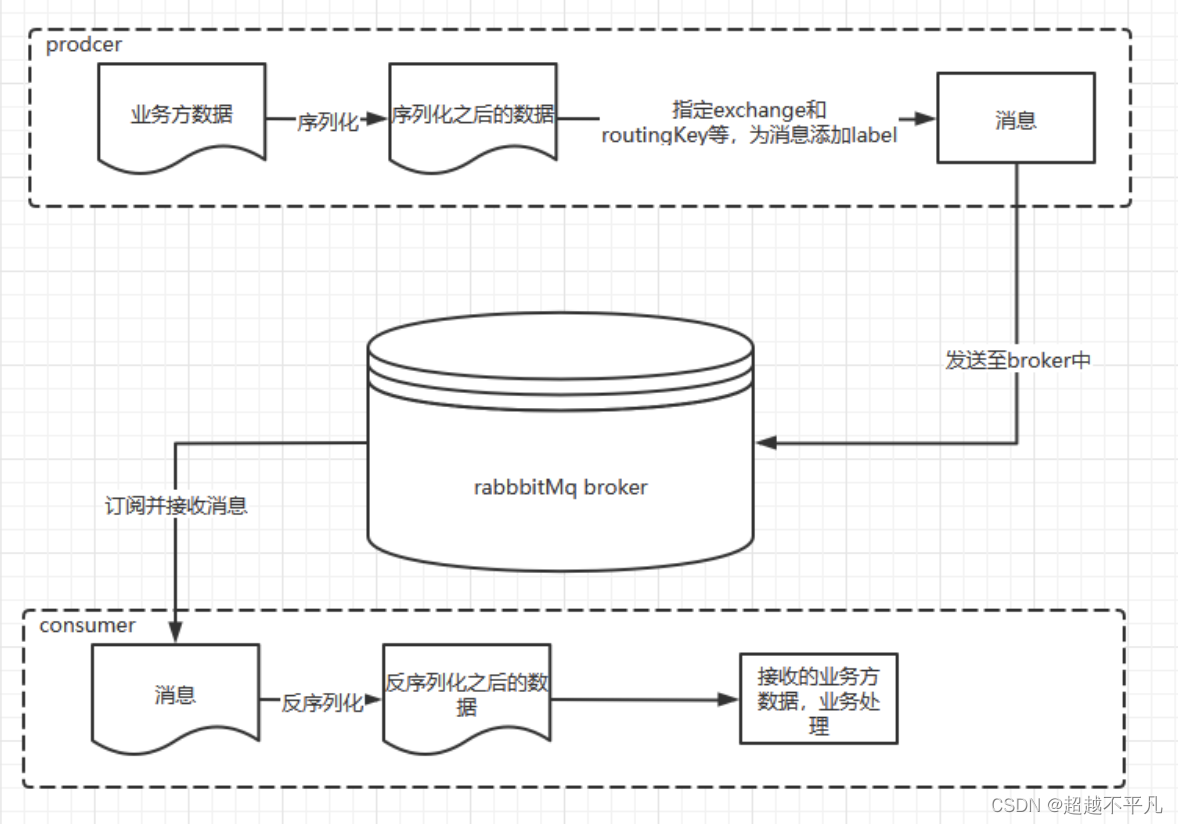
rabbitMQ整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。整体结构架构图如下:
生产者:投递消息的一方。创建消息,然后投递到 RabbitMQ 中。消息一般包含两部分:消息体和标签(label)。消息体称为 payload,标签用来表述这条消息,比如一个交换器的名称和一个路由键。生产者把消息给 RabbitMQ,RabbitMQ 根据标签把消息发送给感兴趣的消费者。
消费者:接收消息的一方。消费者消费一条消息的时候,只是消费消息的消息体(payload)。在消息路由的过程中,消息的标签会丢弃,存入到队列中的消息只有消息体,消费者也只会消费消息体。
Broker:消息中间件的服务节点。一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。
2.1 核心概念
队列:用来存储消息,RabbitMQ 中消息只能存储在队列中。多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(轮询)。
交换器:生产者将消息发送给交换器,由交换器将消息路由到一个或者多个队列中。如果路由不到,会返给消费者,或者直接丢弃。
RoutingKey:路由键,生产者将消息发送给交换器的时候,一般会指定一个 RoutingKey,用来指定这个消息的路由规则,而这个 RoutingKey 需要与交换器类型和绑定键(bindingKey)联合使用才能生效。RoutingKey 与 bindingKey 的值其实是同一个,但代表的意义不同
BindingKey:通过绑定将交换器和队列关联起来,在绑定的时候一般会指定一个绑定键(BindingKey),这样 RabbitMQ 就知道如何正确将消息路由到队列了。
RabbitMQ 中常用的交换器有四种,fanout、direct、topic、headers 这四种。AMQP 协议中还提到另外两种:system 和自定义。四种常用交换器如下:
fanout交换器:把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中。
direct交换器:把消息路由到那些 BindingKey 和 RoutingKey 完全匹配的队列中。
topic交换器:与 direct 相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同。有. * # 三个符号。
headers交换器:交换器不依赖于路由键的匹配规则,而是根据发送的消息内容中的 headers 属性进行匹配。性能较差,应用不多。
2.2 生产者发送消息过程
RabbitMQ 中生产者(Producer)发送消息的过程可以概括为以下几个步骤:
- 生产者连接到 broker,建立一个连接(connection),开启一个信道(channel)
- 生产者声明一个交换器,并设置相关属性,如交换器类型、是否持久化。
- 生产者声明一个队列并设置相关属性
- 生产者通过路由键将交换器和队列绑定起来
- 生产者发送消息至 broker,其中包括路由键交换器等信息
- 相应的交换器根据接收到的路由键查找匹配的队列
- 如果找到,则将从生产者发来的消息存入相应的队列中。
- 如果没找到,则根据生产者的配置选择丢弃还是回退给生产者
- 关闭信道
- 关闭连接
2.3 消费者接收消息过程
消费者消费消息的过程如下:
- 消费者连接到 broker,建立一个连接(connection),开启一个信道(channel)
- 消费者向 broker 请求消费相应的队列中的消息,可能会设置相应的回调函数及一些准备工作。
- 等待 broker 回应并投递相应队列中的消息,消费者接收消息
- 消费者确认(ack)接收到的消息。
- RabbitMQ 从队列中删除相应已经被确认的消息
- 关闭信道,关闭连接。
2.4 RabbitMQ 为何要引入信道(channel)
客户端和 broker 建立的连接是 TCP 连接,一旦连接建立起来,客户端紧接着可以创建一个AMQP 信道,RabbitMQ 处理的每条 AMQP 指令都是通过信道完成的。
我们可以完全通过 connection 来完成工作,为什么要引入信道呢?一个应用程序中有很多线程需要从 RabbitMQ 中消费,或者生产消息,那么必然需要建立很多连接。然而对于操作系统而言,建立和销毁 TCP 连接是非常昂贵的开销,如果遇到业务高峰,性能随之显现。RabbitMQ采用类似 NIO 的做法,选择 TCP 复用,不仅可以减少性能开销,同时也便于管理。
每个线程把持一个信道,所以信道复用 connection 的 TCP 连接。同时 RabbitMQ 可以确保每个线程的私密性。就像拥有独立的连接一样。当每个信道流量不是很大时,复用单一的connection 可以在产生性能瓶颈情况下有效节省 TCP 资源。但是当信道本身的流量很大时,这时多个信道复用一个 connection 就会产生性能瓶颈,进而使整体的流量被限制。此时就需要开辟多个 connection,将这些信道均摊到这些 connection 中。
2.5 消费模式
RabbitMQ 的消费方式分为两种:推模式和拉模式。
在推模式中,可以通过持续订阅的方式来消费消息。在投递模期间,RabbitMQ 会不断的推送消息给消费者,当然推送的个数还是会受到 Basic.Qos 的限制。如果只是想从队列获得单条消息而不是持续订阅可以选择拉模式。如果要实现高吞吐量,消费者应使用推模式。
关于 RabbitMQ 的基础支持就介绍到这里,下篇文章将带你了解其高阶应用,欢迎关注。
往期经典推荐
走进 Mybatis 内核世界:理解原理,释放更多生产力-CSDN博客
一文掌握Java动态代理的奥秘与应用场景-CSDN博客
领航分布式消息系统:一起探索Apache Kafka的核心术语及其应用场景-CSDN博客
深入剖析Kafka生产者:揭秘消息从发送到落地的全过程-CSDN博客
Kafka消息流转的挑战与对策:消息丢失与重复消费问题_kafka发送消息生产者关闭了-CSDN博客