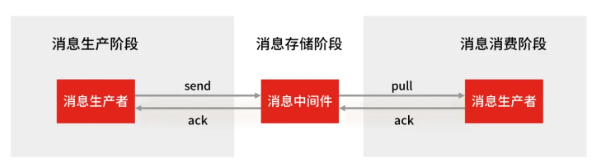
批标准化(Batch Normalization,BN)是为了克服神经网络
层数加深导致难以训练而诞生的。
随着神经网络的深度加深,训练会越来越困难,收敛速度会很慢,常常会导致梯度消失问题。梯度消失问题是在神经网络中,当前隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降,这种现象叫梯度消失问题。
传统机器学习中有一个ICS理论,这是一个经典假设:源域(Source Domain)和目标域(Target Domain)的数据分布是一致的,也就是说,训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
协变量转移(Covariate Shift)是指当训练集的样本数据和目标集样本分布不一致时,训练得到的模型无法很好地泛化。它是分布不一致假设之下的分支,也就是之源域和目标域的条件概率是一致的,但是边缘概率不同。
对于神经网络的各层输出,在经过层内操作之后,各层输出分布就会与对应的输入信号分布不同,而且差异会随着网络深度增大而增大,但是每一层所指向的样本标记仍然是不变的。
解决思路:根据训练样本的比例对训练样本做一个矫正,因此,通过引入批标准化来规范某些层或者所有层的输入,从而固定每层输入信号的均值与方差。
批标准化一般用在非线性映射(激活函数)之前,对于
x
=
W
u
+
b
x=Wu+b
x=Wu+b做规范化,使结果(输出信号各个维度)的均值为0,方差为1。让每一层的输入有一个稳定的分布会有利于网络的训练。批标准化通过规范化让激活函数分布在线性区间,结果就是加大了梯度,让模型更加大胆地进行梯度下降。
批标准化具有以下几个优点:
- 加大探索的
步长,从而加快收敛的速度。 - 更容易跳出局部最小值。
破坏原来的数据分布,在一定程度上缓解过拟合。
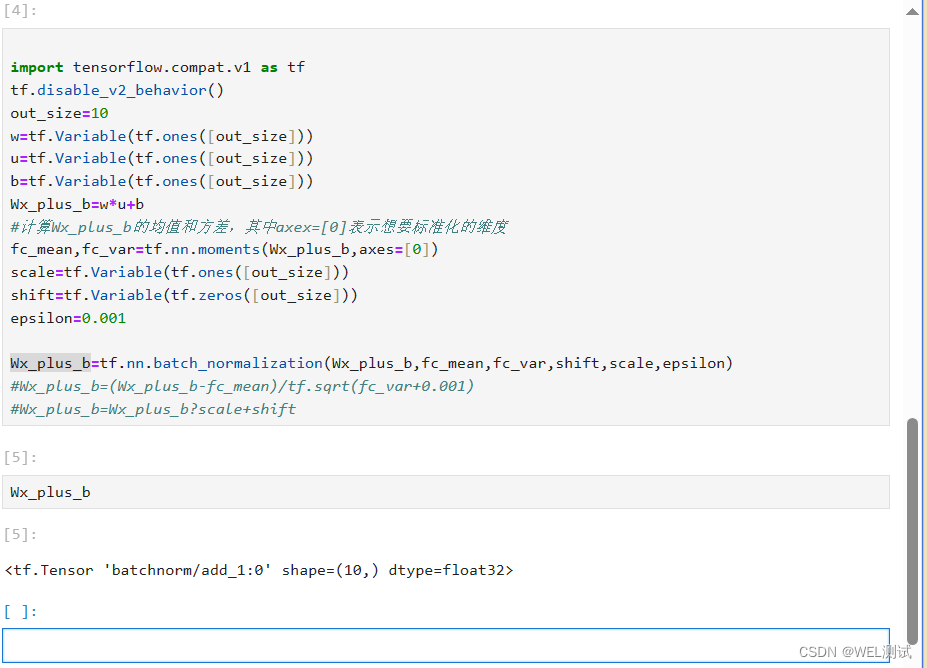
对每一次的Wx_plus_b 进行批标准化,这个步骤放在激活函数之前,示例片段如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
out_size=10
w=tf.Variable(tf.ones([out_size]))
u=tf.Variable(tf.ones([out_size]))
b=tf.Variable(tf.ones([out_size]))
Wx_plus_b=w*u+b
#计算Wx_plus_b的均值和方差,其中axex=[0]表示想要标准化的维度
fc_mean,fc_var=tf.nn.moments(Wx_plus_b,axes=[0])
scale=tf.Variable(tf.ones([out_size]))
shift=tf.Variable(tf.zeros([out_size]))
epsilon=0.001
Wx_plus_b=tf.nn.batch_normalization(Wx_plus_b,fc_mean,fc_var,shift,scale,epsilon)
#下面两步等同用于上面一步
#Wx_plus_b=(Wx_plus_b-fc_mean)/tf.sqrt(fc_var+0.001)
#Wx_plus_b=Wx_plus_b?scale+shift