目 录
- 一.认识 Redis
- 二.浅谈分布式
- 单机架构
- 分布式是什么
- 数据库分离和负载均衡
- 理解负载均衡
- 数据库读写分离
- 引入缓存
- 数据库分库分表
- 引入微服务
- 三.概念补充
- 四.分布式小结
一.认识 Redis
在 Redis 官网我们可以看到介绍
翻译过来就是:数以百万计的开发人员用作缓存、矢量数据库、文档数据库、流引擎和消息代理的内存数据存储。
- 存储数据:在内存中存储。那我们可以想到 定义变量也是在内存中存储数据的,但是 Redis 是在分布式系统中才能发挥力量的,如果只是单机程序,直接通过变量存储数据的方式,是比使用 Redis 更优的选择。我们知道进程之间有隔离性,进程之间通过网络进行通信,Redis 就是基于网络,可以把自己内存中的变量给别的进程,甚至别的主机的进程进行使用。
- 数据库:一谈及数据库我们可以想到 MySQL,MySQL 最大的问题在于,访问速度比较慢,很多互联网产品中,对于性能要求是很高。Redis 也可以作为数据库使用,访问速度快!!定性的角度,可以知道 Redis 快很多,但是很难定量衡量。Redis 和 MySQL 相比,最大的劣势,存储空间是有限的。虽然有不少的互联网产品,对于性能要求比较高的,但是也有很多互联网产品对于性能要求没那么高。那如何内存又大访问速度又快呢??典型的方案,可以把 Redis 和 MySQL 结合起来使用。"二八原则”,20%的热点数据,能满足 80% 的访问需求,于是把 20% 的数据存储到 Redis 中,80% 的数据存储到MySQL 中,但是系统的复杂程度大大提升了,而且,如果数据发生修改,还涉及到 Redis 和 MySQL 之间的数据同步问题。
二.浅谈分布式
单机架构
只有一台服务器,这个服务器负责所有的工作
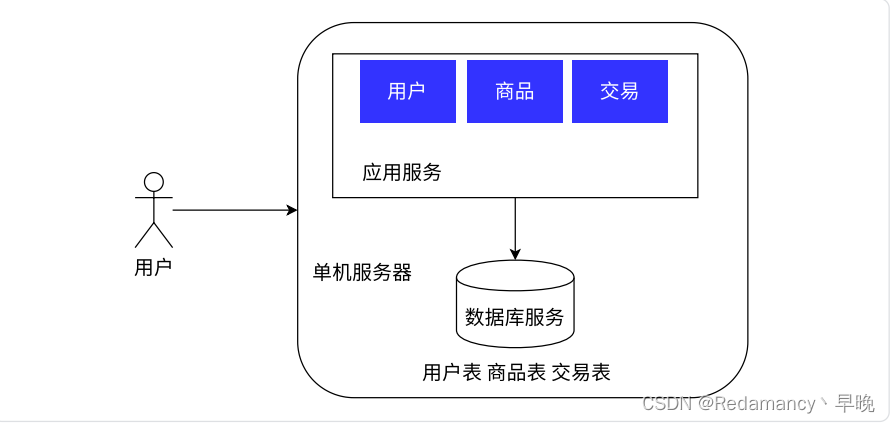
应用程序中保存了我们个人编辑的代码写的那些 HTTP 服务器,数据库服务就是我们的数据库,例如 MySQL等,MySQL 是一个客户端服务器结构的程序!!本体是 MySQL 服务器(存储和组织数据的部分)。当我们用户发送一个请求之后,经过应用服务发送HTTP 请求,HTTP 请求转成增删改查等动作转发给数据库,数据库再进行操作。
单机程序中,能不能把数据库服务器也去掉,光一个应用服务器又负责业务,又负责数据存储?(也不是不可以,但是就是会比较麻烦)
千万不要瞧不上这个东西,绝大部分的公司的产品都是这种单机架构!!现在计算机硬件,发展速度非常之快,哪怕只有一台主机,这一台主机的性能也是很高的,可以支持非常高的并发&非常大的数据存储
如果业务进一步增长,用户量和数据量都水涨船高,一台主机难以应付的时候,就需要引入更多的主机引入更多的硬件资源
分布式是什么
一台主机的硬件资源是有上限的
包括不限于以下几种
- CPU
- 内存
- 硬盘
- 网络
- …
服务器每次收到一个请求,都是需要消耗上述的一些资源的
如果同一时刻,处理的请求多了,此时就可能会导致某个硬件资源,不够用了!!无论是哪个方面不够用了,都可能会导致服务器处理请求的时间变长甚至于处理出错
如果我们真的遇到了这样的服务器不够用的场景,怎么处理呢?
-
开源:简单粗暴,增加更多的硬件资源
-
节流:软件上优化(各凭本事了,需要通过性能测试,找到是哪个环节出现了瓶颈,再去对症下药)
一个主机上面能增加的硬件资源也是有限的,取决于主板的扩展能力。一台主机扩展到极限了,但是还不够就只能引入多台主机了。不是说新的机器买来就直接可以解决问题了,也需要软件上做出对应的调整和适配,一旦引入多台主机了,咱们的系统就可以称为是 “分布式系统”。引入分布式,这是万不得已,系统的复杂程度会大大提高,出现bug的概率也越高。
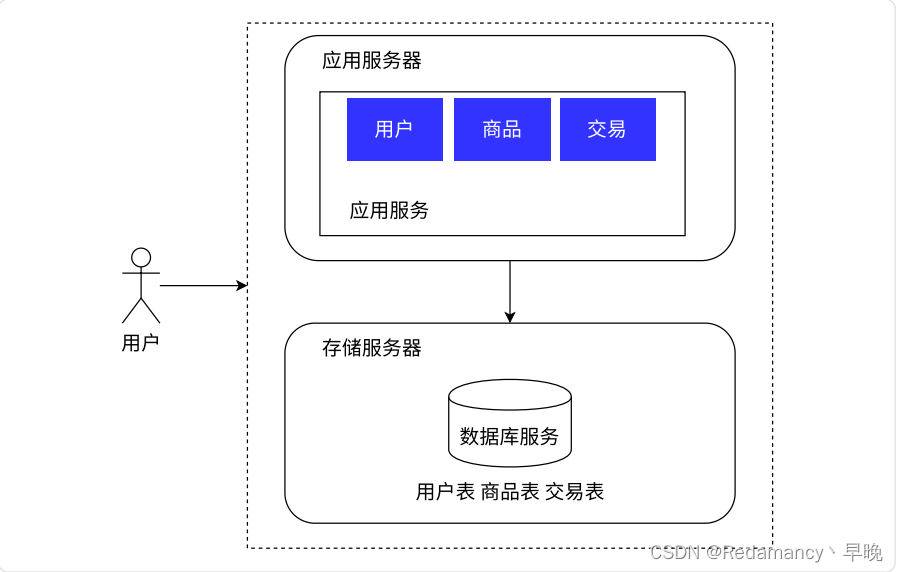
数据库分离和负载均衡
-
应用服务器,里面可能会包含很多的业务逻辑,可能会吃 CPU 和内存.
-
数据库服务器,需要更大的硬盘空间,更快的数据访问速度,可以配置更大硬盘的服务器,甚至还可以上 SSD(固态) 硬盘
1.机械硬盘,便宜,慢;2.固态硬盘,贵,快
通过上面的操作就达到更高的性价比了
应用服务器可能会比较吃 CPU 和内存,如果把 CPU 或者内存吃没了,此时应用服务器就顶不住了
引入更多的应用服务器,就可以有效解决上述问题
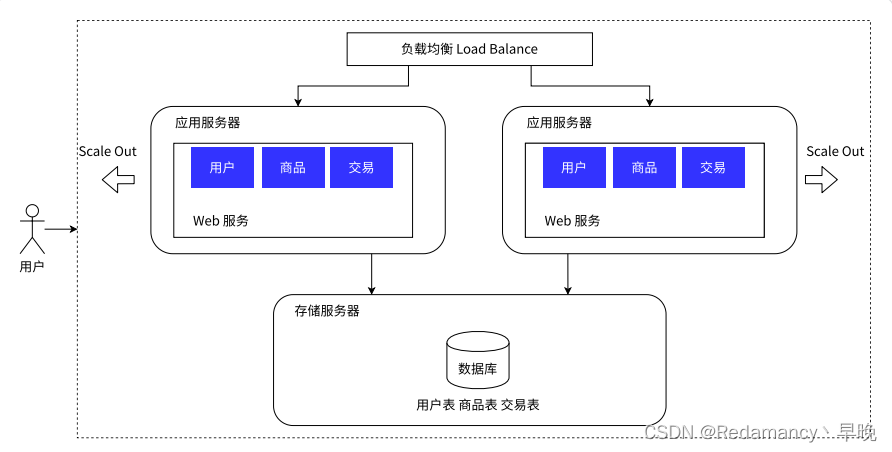
看起来是两个应用服务器,实际上可能是多个。
用户的请求,先到达 负载均衡器/网关服务器(单独的服务器)
假设有 1w 个用户请求,有 2 个应用服务器:此时按照负载均衡的方式,就可以让每个应用服务器承担 5k 的访问量
负载均衡:就像公司的一个组的领导一样,要负责管理,要负责把任务分配给每个组员(对于负载均衡器来说,有很多的负载均衡具体的算法)
理解负载均衡
负载均衡器,看起来不是承担了所有的请求嘛?这个东西能顶住嘛??
负载均衡器,对于请求量的承担能力,要远超过应用服务器的.
- 负载均衡器,是领导,分配工作.
- 应用服务器,是组员,执行任务.
是否可能会出现,请求量大到负载均衡器也扛不住了呢??也是有可能的!!
于是就可以引入更多的负载均衡器(引入多个机房)
数据库读写分离
如上面讨论,增加应用服务器,确实能够处理更高的请求量,但是随之存储服务器,要承担的请求量也就更多了!!
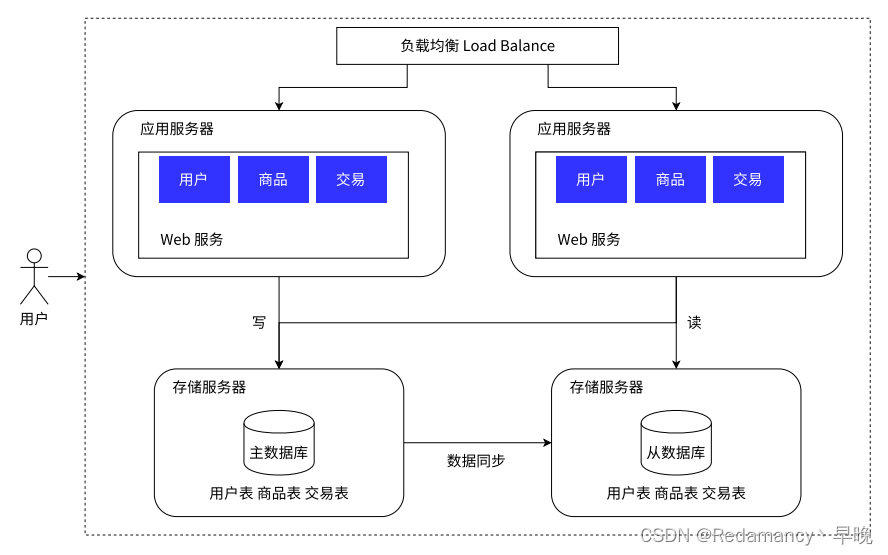
对数据库进行读写分离
在实际的应用场景中,读的频率是比写要高的
所以主服务器一般是一个,从服务器可以有多个(一主多从)
同时从数据库通过负载均衡的方式,让应用服务器进行访问
引入缓存
数据库天然有个问题,响应速度是更慢的
把数据区分"冷热",热点数据放到缓存中,缓存的访问速度往往比数据库要快很多了
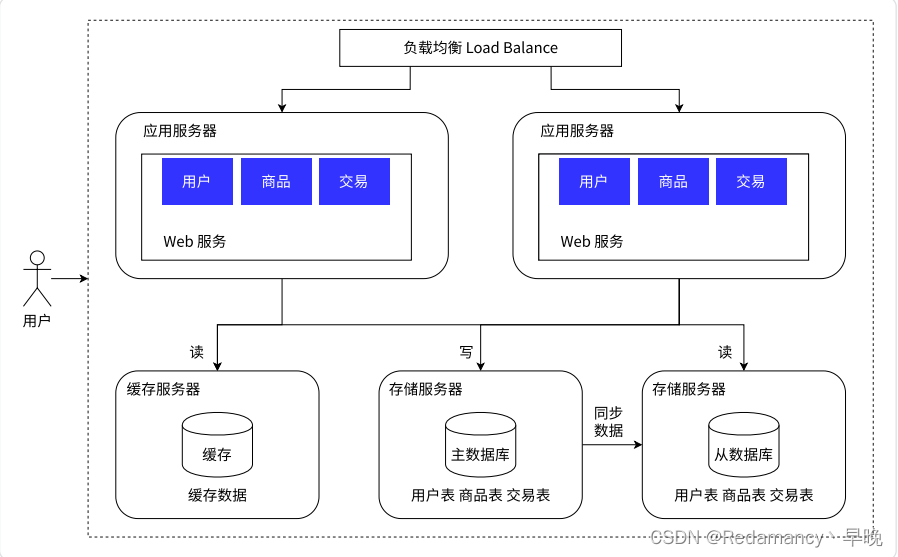
缓存只是放一小部分热点数据.(会频繁被访问到的数据),根据二八原则:20% 的数据能够支持 80% 的访问量
此时我们右边存储服务器存储的仍然是完整的全量数据
缓存要想快就要付出代价 => 小 => Redis
此时,缓存服务器就帮助数据库服务器负重前行!!
数据库分库分表
引入分布式系统,不光要能够去应对更高的请求量(并发量),同时也要能应对更大的数据量
是否可能会出现,一台服务器已经存不下数据了呢??当然会存在
虽然一个服务器,存储的数据量可以达到几十个TB,即使如此也可能会存不下
一台主机存不下,就需要多台主机来存储
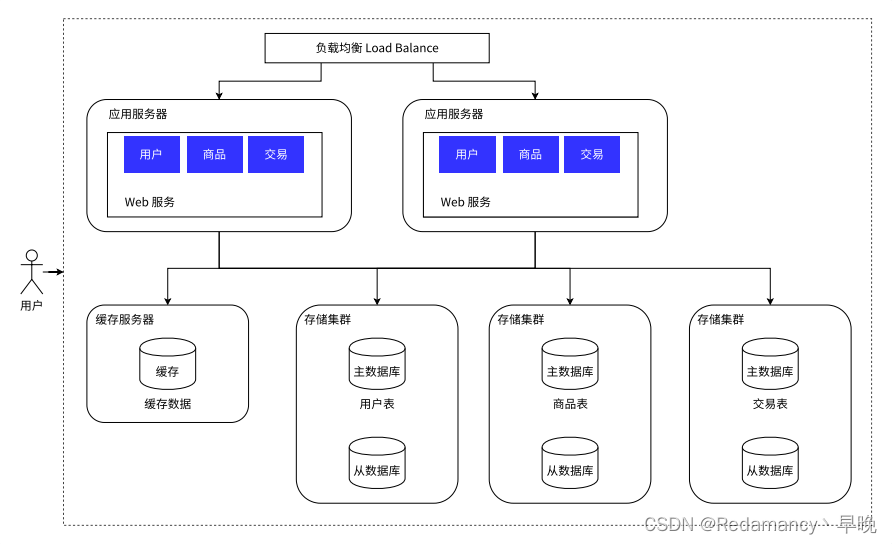
针对数据库进行进一步的拆分,分库分表
本来一个数据库服务器,这个数据库服务器上有多个数据库(指的是逻辑上的数据集合, create database 创建的那个东西)
现在就可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分数据库
如果某个表特别大,大到一台主机存不下,也可以针对表进行拆分
具体分库分表如何实践?还是要结合实际的业务场景来展开
引入微服务
微服务架构:

之前应用服务器,一个服务器程序里面做了很多的业务,这就可能会导致这一个服务器的代码变的越来越复杂
为了更方便于代码的维护,就可以把这样的一个复杂的服务器,拆分成更多的,功能更单一,但是更小的服务器 —> 微服务
因此服务器的种类和数量就增加了
当应用服务器复杂了,势必就需要更多的人来维护了,当人多了,就需要配套的管理,把这些人组织好,划分组织结构,分成多个组,每个组分别配备领导进行管理
注意,微服务本质上是在解决 "人” 的问题
按照功能,拆分成多组微服务,就可以有利于上述人员的组织结构的分配了
引入微服务,解决了人的问题,付出的代价?
- 系统的性能下降:拆出来更多的服务,多个功能之间要更依赖网络通信,网络通信的速度很可能是比硬盘还慢的。(要想保证性能不下降太多,只能引入更多的机器,更多的硬件资源)(幸运的是,硬件技术的发展,网卡现在有万兆网卡,读写速度已经能过超过硬盘读写了)
- 系统复杂程度提高,可用性受到影响:服务器更多了,出现问题的概率就更大了。这就需要一系列的手段,来保证系统的可用性(更丰富的监控报警,以及配套的运维人员)
微服务的优势:
- 解决了人的问题.
- 使用微服务,可以更方便于功能的复用
- 可以给不同的服务进行不同的部署
三.概念补充
应用(Application)/ 系统(System)
一个应用,就是一个/组服务器程序
模块(Module)/ 组件(Component)
一个应用,里面有很多个功能,每个独立的功能,就可以称为是一个模块/组件
分布式(Distributed)
引入多个主机/服务器,协同配合完成一系列的工作.(物理上的多个主机)
集群(Cluster)
引入多个主机/服务器,协同配合完成一系列的工作.(逻辑上的多个主机)
主(Master)/ 从(Slave)
分布式系统中一种比较典型的结构,多个服务器节点,其中一个是主,另外的是从,从节点的数据要从主节点这里同步过来
中间件(Middleware)
和业务无关的服务(功能更通用的服务)
- 数据库
- 缓存
- 消息队列
- …
可用性(Availability)
系统整体可用的时间 / 总的时间
响应时长(Response Time RT)
衡量服务器的性能,越小越好,和具体服务器要做的业务密切相关的
吞吐(Throughput)vs 并发(Concurrent)
衡量系统的处理请求的能力.衡量性能的一种方式
四.分布式小结
- 单机架构(应用程序+数据库服务器)
- 数据库和应用分离
应用程序和数据库服务器分别放到不同主机上部署了. - 引入负载均衡,应用服务器=>集群
通过负载均衡器,把请求比较均匀的分发给集群中的每个应用服务器.(当集群中的某个主机挂了,其他的主机仍然可以承担服务提高了整个系统的可用性) - 引入读写分离,数据库主从结构
一个数据库节点作为主节点,其他N个数据库节点作为从节点,主节点负责写数据,从节点负责读数据,主节点需要把修改过的数据同步给从节点 - 引入缓存,冷热数据分离
进一步的提升了服务器针对请求的处理能力(二八原则),Redis在一个分布式系统中,通常就扮演着缓存这样的角色,引入的问题:数据库和缓存的数据一致性问题 - 引入分库分表,数据库能够进一步扩展存储空间
- 引入微服务,从业务上进一步拆分应用服务器
从业务功能的角度,把应用服务器,拆分成更多的功能更单一,更简单,更小的服务器
上述这样的几个演化的步骤,只是一个粗略的过程
实际上一个商业项目,真实的演化过程,都是和他的业务发展密切相关的,业务是更重要的,技术只是给业务提供支持的,所谓的分布式系统,就是想办法引入更多的硬件资源!!