文章目录
- 一. 什么是Hudi
- 二. 发展历史
- 三. Hudi 功能和特性
- 四. Hudi 基础架构
- 五. 使用公司
- 六. 小结
- 参考:
一. 什么是Hudi
Apache Hudi(发音“hoodie”)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接带到数据湖中。Hudi提供了表,事务,高效upserts /删除,高级索引,流式摄取服务,数据群集/压缩优化以及并发,同时保持数据以开源文件格式保留。
Apache Hudi不仅用于流媒体工作负载,还允许创建有效的增量批量流水线。包括 Uber, Amazon, ByteDance, Robinhood等以及更多的公司都在使用Hudi改造他们的生产数据湖泊。
Apache Hudi可以轻松使用在任何云存储平台上。Hudi的高级性能优化,使用任何流行的查询引擎进行分析工作负载,包括Apache Spark,Flink,Presto,Trino,Hive等。
- Hudi(Hadoop Upserts and Incrementals缩写):用于管理分布式文件系统DFS上大型分析数据集存储。
- 一言以蔽之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
- 官网地址:https://hudi.apache.org/

二. 发展历史
2015 年:发表了增量处理的核心思想/原则(O’reilly 文章)
2016 年:由 Uber 创建并为所有数据库/关键业务提供支持
2017 年:由 Uber 开源,并支撑 100PB 数据湖
2018 年:吸引大量使用者,并因云计算普及
2019 年:成为 ASF 孵化项目,并增加更多平台组件
2020 年:毕业成为 Apache 顶级项目,社区、下载量、采用率增长超过 10 倍
2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
三. Hudi 功能和特性
- 快速upsert,可插入索引
- 以原子方式操作数据并具有回滚功能
- 写入器之和查询之间的快照隔离
- savepoint用户数据恢复的保存点
- 管理文件大小,使用统计数据布局
- 异步压缩行列数据
- 具有时间线来追踪元数据血统
- 通过聚类优化数据集

四. Hudi 基础架构
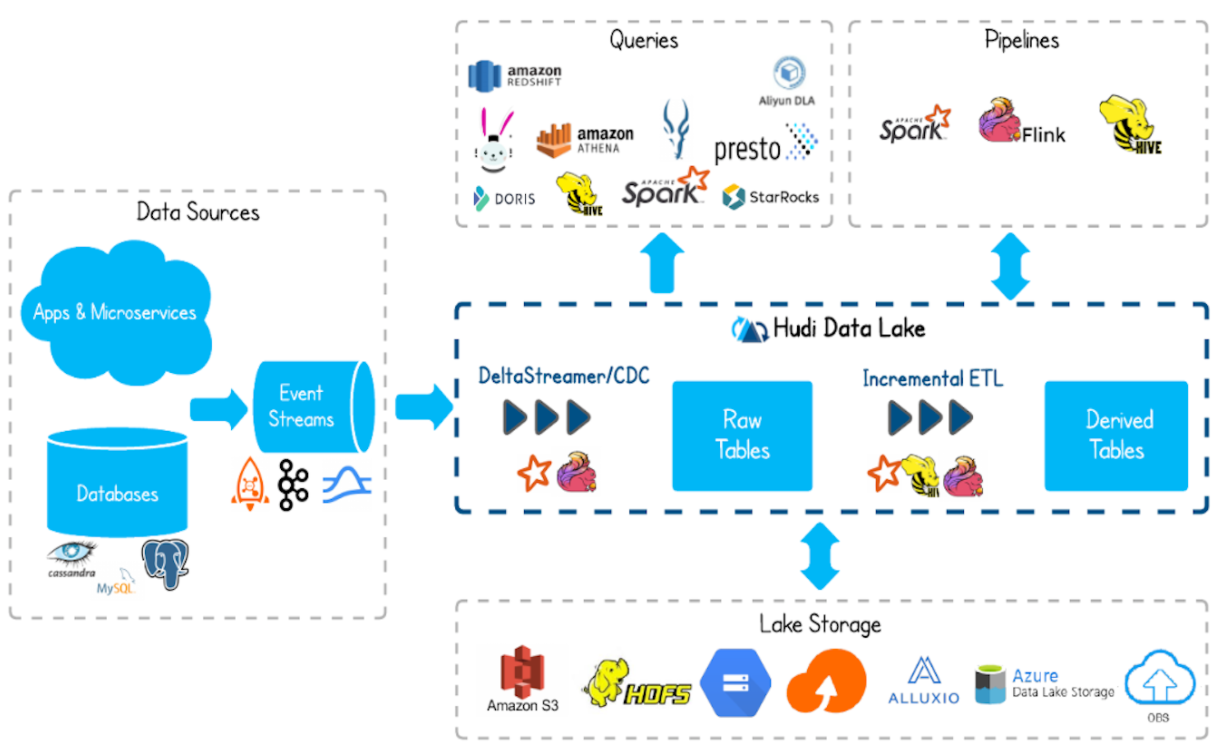
-
通过DeltaStreammer、Flink、Spark等工具,将数据摄取到数据湖存储。
-
支持 HDFS、S3、Azure、云等等作为数据湖的数据存储。
-
支持不同查询引擎,如:Spark、Flink、Presto、Hive、Impala、Aliyun DLA。
-
支持 spark、flink、map-reduce 等计算引擎对 hudi 的数据进行读写操作。
五. 使用公司

六. 小结
-
Apache Hudi 本身不存储数据,仅仅管理数据,借助外部存储引擎存储数据,比如HDFS、S3;
-
此外,Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如Spark或Flink
参考:
- https://hudi.apache.org/docs/overview/
- https://www.bilibili.com/video/BV1ue4y1i7na/
- https://blog.csdn.net/yang_shibiao/article/details/122910318
- https://blog.csdn.net/NC_NE/article/details/124789211