近年来,3D动捕、数字虚拟人等技术受到越来越多关注,它不仅可以应用于电影场景,游戏、社交等领域也开始采用。相比于过去高成本、高门槛的全身动捕技术,现在制作基于动捕的虚拟人越来越容易,不需要过高的成本或是专业技术知识,一些简易、自动化的动捕方案就足够普通创作者使用。

近期,索尼也公布了一项基于机器学习的3D虚拟人和动捕方案,该方案可逼真模拟人类面部表情和行为的3D建模技术,通过忠实重现人类特征,来推动虚拟社交。
索尼指出,数字人是基于真人特征的3D模型,它在虚拟场景中可模拟人的自然外观和行为。近年来,越来越多的企业开始接触数字人技术,并将它用于广告、客服、游戏等场景。当然,并不是所有数字人都能完全还原人的特征,它们的还原程度取决于用途,比如在CG电影中,对于数字人的逼真度会要求更高。索尼认为,随着CG渲染技术不断提升,虚拟化身的质量越来越好,因此恐怖谷问题正在得到解决。

索尼的目标,是开发一种仿佛真实存在的数字人,这种数字人具有存在感,让人感觉它仿佛就在身边。换句话说,就是利用数字技术来复制真人。结合AI算法后,它可以和真人互动,甚至和真人难以区分。其研发重点是突出数字人的个性表达,比如重现人脸皱纹和表情的特征变化,抓住人独一无二的特点。从自然交互的角度来看,索尼也注重数字人的眼神与用户的互动,数字人不会盯着用户,而是模仿人眼和头部自然动作。
数字人核心技术
构成数字人的核心技术包括:面部动捕、面部肌肉模拟、面部肌肉动作和身体协调性。基于人脸绑定的面部动画也需要这些步骤,模拟人脸表情变化是一个复杂的过程,要想忠实重现、绑定人脸面部动作,需要高端的面部动捕技术。而且,复杂的面部动捕难以控制,在制作动画时将需要高超的技术。为了简化基于动捕的人脸表情模拟过程,索尼研发了一种更加智能的工作流程,特点是无需传统的面部绑定方案,并降低了制作动画的工作量。

据了解,面部动捕技术可准确追踪表演者脸部各部分运动,并驱动CG模型去模拟这种运动。捕捉面部变形数据需要详细的三位信息,才能准确呈现肌肉伸展、收缩,以及由此产生的皱纹等细微运动。
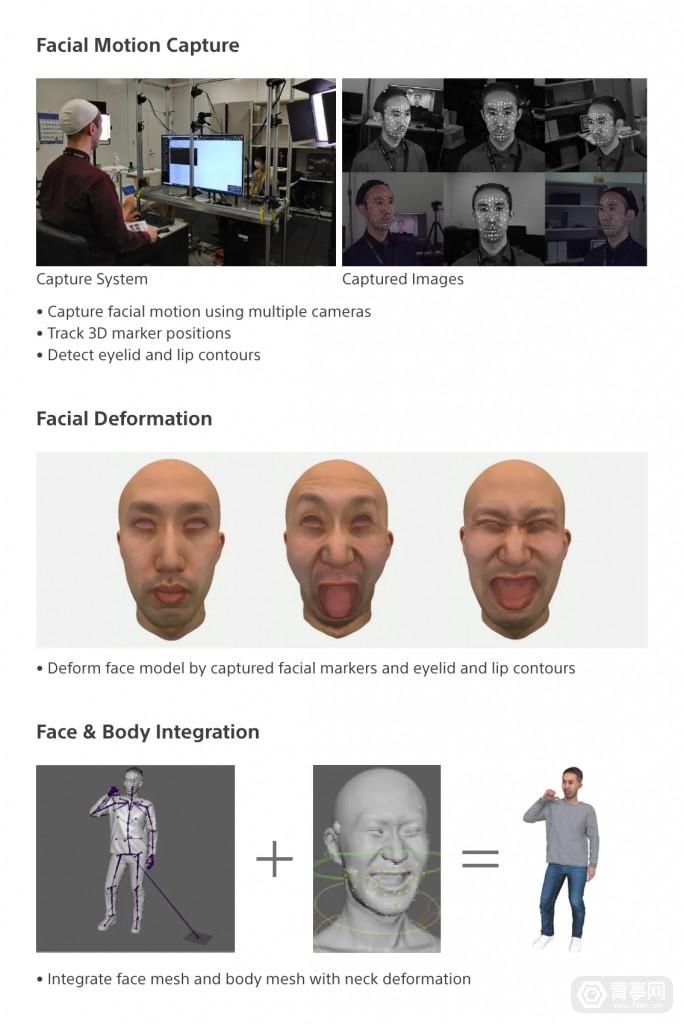
而索尼的方案,简单来讲就是用动捕技术捕捉真人演员的表情,并根据捕捉到的数据生成人脸CG模型,以及面部动态变形效果。此外,还分析了各种面部表情模式,并提取了重现这些表情需要运动的面部区域。这些区域大约有100个,包括眼睛和嘴唇轮廓部位,在捕捉这些区域的3D信息后,索尼对它们的位置进行了标记。

在捕捉人脸3D信息时,索尼使用了多台同步的摄像机从多角度拍摄,并推算3D运动信息。不过,部分面部表情变化可能会导致标记检测失败或遮挡,因此该系统还利用光流,以及不同的摄像头角度来提升信息获取的稳定性。
接下来,索尼使用真人表演视频作为训练数据,培训了可精准检测眼睛、嘴唇运动的系统。索尼指出,每一帧动捕的准确性都决定了下一帧的准确性,因此该系统还需要不断完善,提高整体水平。

索尼开始使用头戴式摄像头(HMC)来拍摄演员的面部表情,相比于传统的固定机位拍摄,HMC的好处是可以追随演员,演员无需寻找摄像头,可以更加自由、灵活的运动。索尼表示:捕捉到自然运动的人体姿态后,才能渲染出完整的数字人,因此HMC是捕捉自然运动数据不可缺少的工具。
不过,演员可戴在头上的HMC摄像头数量有限,面部捕捉的角度、覆盖面积比固定机位更少。因此,准确捕捉3D面部数据、识别3D标记则尤为重要。为了训练良好的3D预测算法,索尼使用固定机位和HMC预先捕捉人脸数据,其中包括面部表情、3D标记等等。算法通过这些数据去学习表情和面部运动之间的相关性,后续只需要HMC的数据就可预测3D面部运动,准确性足够接近传统的固定机位方案。
模拟面部变形
在捕捉人脸3D标记信息后,索尼的动捕系统根据眼睑、嘴唇轮廓信息来模拟面部变形,并动态渲染在3D模型上。渲染面部变形的流程是:根据几何函数模拟面部表情、用机器学习模型将面部表情个性化、细节微调、叠加纹理。首先第一步,3D面部动作、眼睑轮廓需要准确定位,才能确保后续面部变形合理。因此,索尼设定了一个具有几何约束的能量函数,可根据3D面部数据来调整面部模型的整体形态。
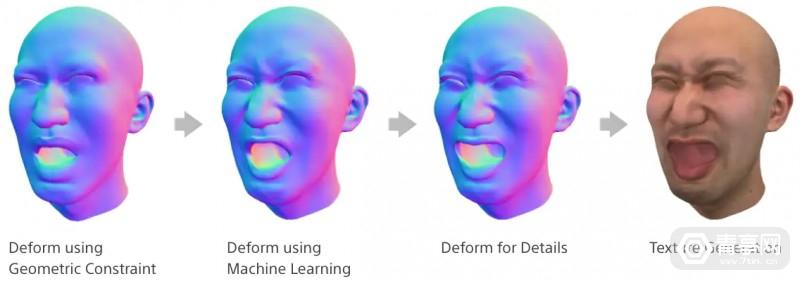
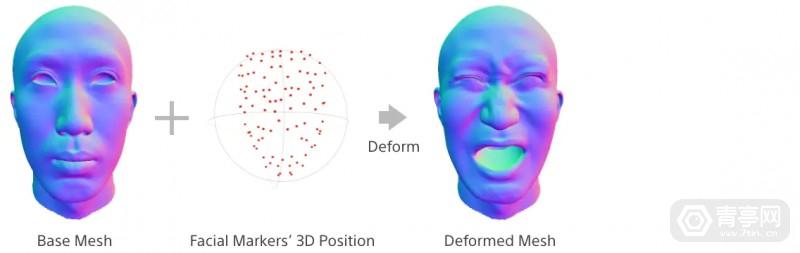

另外,由于人脸表情变化引起的皮肤拉伸、收缩、皱纹和肌肉隆起程度因人而异,因此索尼利用十几种面部表情模式来训练个性化的机器学习模型,这些模型可根据人脸特征,来将3D面部表情个性化,重现用户的个人特征。
细节方面,该机器学习模型将人脸区域的伸长、收缩程度作为特征值,并根据几何变形模型与真实值之间的差距回归,从而输出具有个人特征的面部变形。

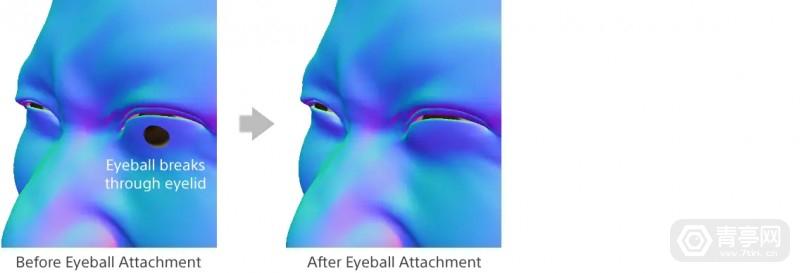
面部变形的最后一步,就是引入眼睑、嘴唇、口腔形状变形算法,对面部模型进行额外处理。这一步是为了纠正面部变形可能产生的误差,确保眼睑覆盖眼球(避免眼球和眼睑出现间隙,或眼球穿模眼皮)、自然的口腔形状变化等特征。在眼睑处理部分,该算法重点是避免眼睑接触眼球,而嘴唇处理部分,则侧重于几何约束,确保面部捕捉到的嘴唇轮廓与3D模型的嘴唇形状匹配。
面部和身体集成
完成3D面部动作模拟后,下一步便是将面部与身体姿态集成,并协调面部表情和身体动作。如果面部和身体分开运动,会显得不自然,因此索尼开发了面部和身体一体化算法,可模拟全身自然运动。
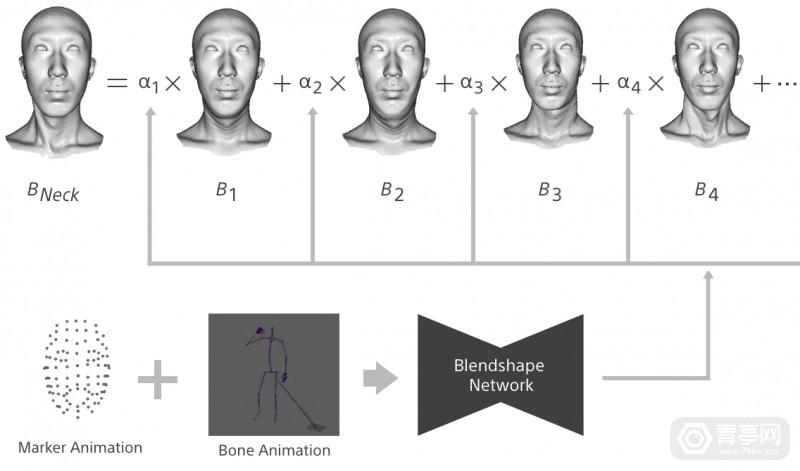
索尼指出,目前市面上的动捕方案主要用于模拟人体模型的运动和变形,人体3D信息通过光学方案捕捉,并且在颈部、腿部、手臂等处添加标记来定位骨骼姿态,生成人体网格,从而模拟人体形状。相比之下,索尼的方案侧重于模拟颈部形状,颈部的动作会同时受到面部和身体运动影响,比如颈骨运动决定面部方向,下颌运动决定嘴巴运动。
于是,索尼构建了一个全身姿态模拟系统,将HMC数据和身体动作捕捉同步,并根据这些数据来预测颈部形状。据悉,索尼预先创建了结合多种嘴型、面部方位的大量训练数据,并从中提取了潜在的颈部形状。在实际预测中,颈部模型组合了多种数据,包括下颌运动、颈部方向。
索尼表示:该颈部模拟模型可重现自然的面部和身体动作,目前训练改模型需要大量训练数据,后续将想办法减少对数据的依赖。
总之,索尼的数字人模拟方案实现了自动化的人脸表情模拟,这大大减少了前期创作工作,允许创作者交付更高质量产品。更重要的是,该方案可根据不同人的特征去模拟运动,好处是看起来非常自然。索尼表示:随着3D虚拟技术发展,数字人将会被更多人所熟知,轻松创建Avatar的需求将逐步增加。未来,希望可以将这项几乎应用于消费级市场,比如电影、游戏等领域。参考:sony