目录
一.引言
二.atomic.LongAccumulator
1.构造方法
2.使用方法
3.创建并使用
三.Spark.util.LongAccumulator
1.构造方法
2.使用方法
一.引言
使用 Spark 进行大数据分析或相关操作时,经常需要统计某个步骤或多个步骤的相对耗时或数量,java.util 与 spark.util 都提供了原子计数器。如果是 spark on Local ,可以直接初始化 object 构建 java.util.concurrent.atomic.LongAccumulator 实现原子计数,如果是 spark on Yarn,则可以通过 org.apache.spark.util.LongAccumulator 实现累计计数。
二.atomic.LongAccumulator
1.构造方法
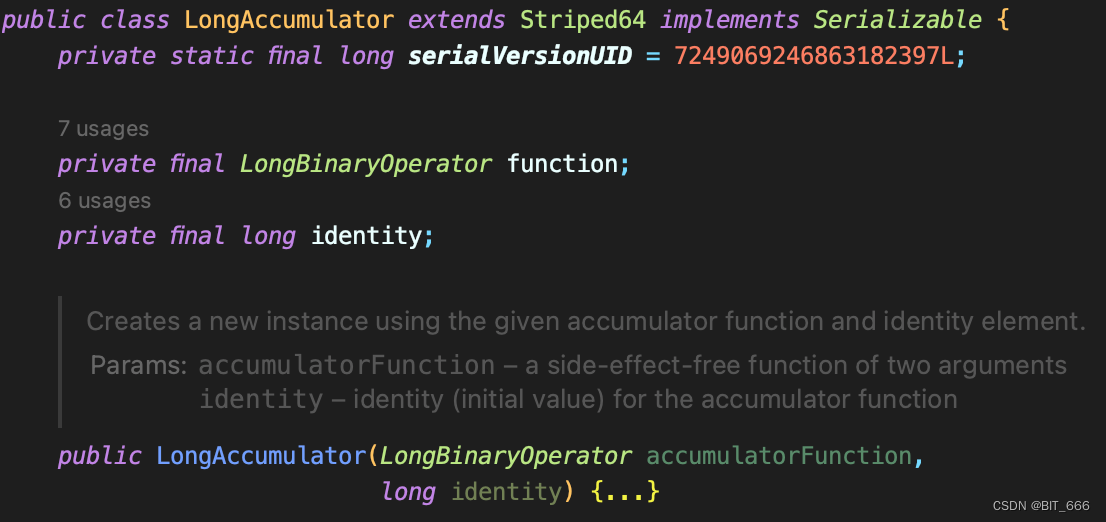
构造一个 java.util.concurrent.atomic.LongAccumulator 需要两个参数:
- LongBinaryOperator
function 为对应的累加器函数,其接受两个参数 left 与 right,用户在函数内定义累加逻辑,其中 left 为当前值,right 为更新的值。官方提示该累加器函数应该是无副作用的,因为当由于线程之间的争用而导致尝试更新失败时,可以重新应用它。
- long
identify 为当前值的默认值。
例入求取当前计算值的最大值,则 function 可以使用 max 函数,identify 使用 Long.MIN_VALUE。
2.使用方法
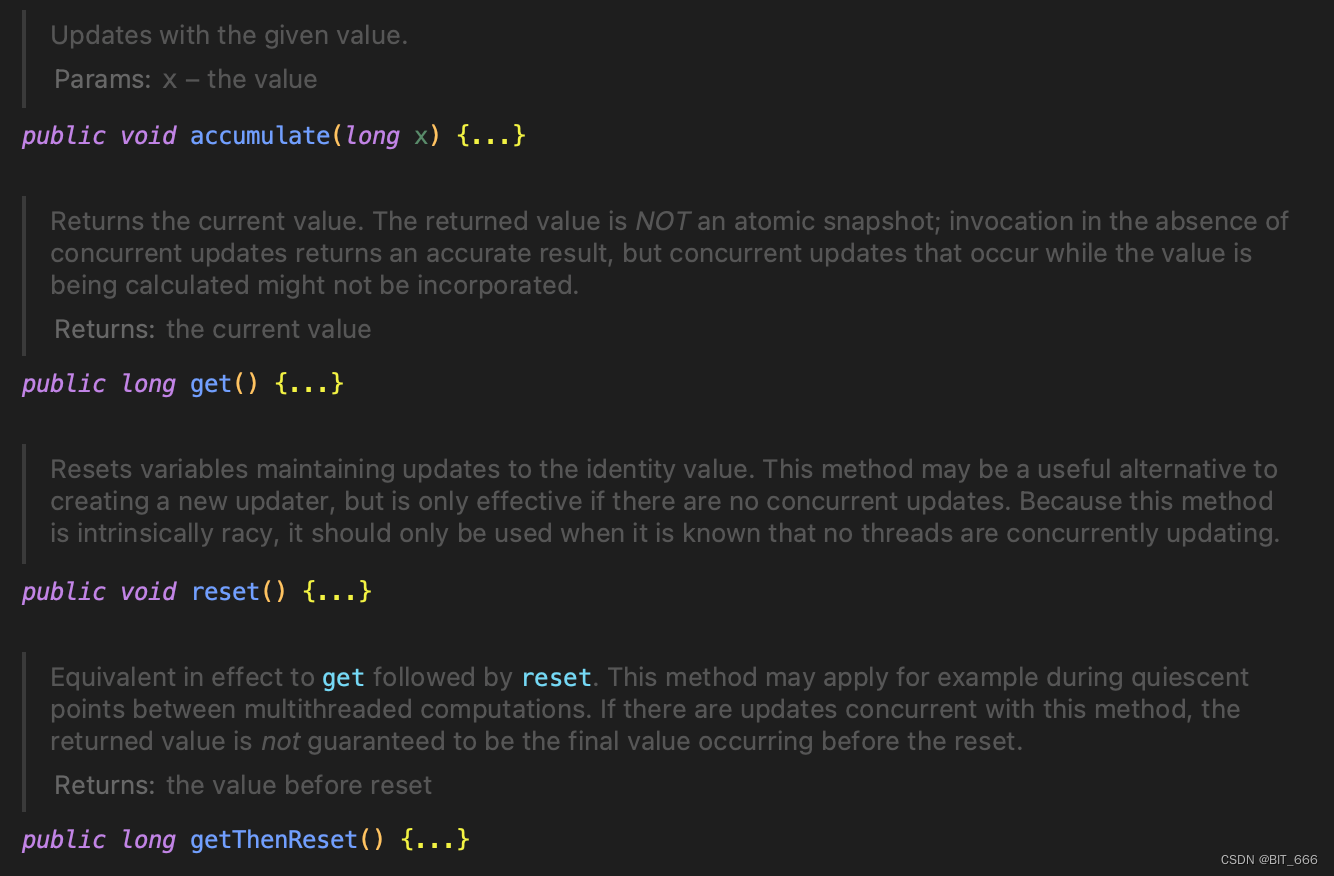
类内提供了4种方法:
- accumulate
根据 function 与当前值更新
- get
返回当前值。返回的值不是原子快照;在没有并发更新的情况下调用会返回准确的结果,但在计算值时发生的并发更新可能不会被合并。
- reset
重置保持更新为标识值的变量。此方法可能是创建新更新程序的有用替代方法,但仅在没有并发更新时有效。只有在知道没有线程正在并发更新时才应该使用它。
- getThenReset
等效于重置。例如,该方法可以应用于多线程计算之间的静态点。如果与此方法同时存在更新,则不能保证返回的值是重置之前发生的最终值。
开头提到的相对计数问题而言,主要使用的方法为 accumulate 与 get,如果存在多轮次计算或重置的情况则需要使用 reset 或者 getThenReset 方法,不过调用时尽量避免并发更新,否则可能出现结果的失真。
3.创建并使用
A.创建
这里实现了最基本的 add 操作,有点类似 LongAdder,随后将需要统计的耗时与数量对应的 key 存入 countMap,后续不同操作累计即可。
import java.util.concurrent.atomic.LongAccumulator
val accArray = Array("cost0", "num0",
"cost1", "num1",
"cost2", "num2",
"cost3", "num3",
"cost4", "num4",
"cost5", "num5",
"cost6", "num6")
val countMap = new mutable.HashMap[String, LongAccumulator]()
accArray.foreach(feat => {
val longBinaryOperator = new LongBinaryOperator() {
@Override
def applyAsLong(left: Long, right: Long): Long = {
left + right
}
}
// 第1个参数是一个双目运算器对象,第2个参数是累加器的初始值。
val longAccumulator: LongAccumulator = new LongAccumulator(longBinaryOperator, 0)
countMap(feat) = longAccumulator
})B.累加并获取
获取结果时尽量避免并发更新,否则可能出现结果的失真。
val st = System.currentTimeMillis()
... doSomeThing ...
val cost = System.currentTimeMillis() - st
// 存储
Uobject.countMap("cost").accumulate(cost)
Uobject.countMap("num").accumulate(1L)
// 获取
Uobject.countMap("cost").get()
Uobject.countMap("num").get()三.Spark.util.LongAccumulator
atomic.LongAccumulator 适合 Local 模式或者非 Spark 类型作业统计平均数,如果在分布式集群情况下想要获取全局的计数可以使用 Spark.util.LongAccumulator
1.构造方法
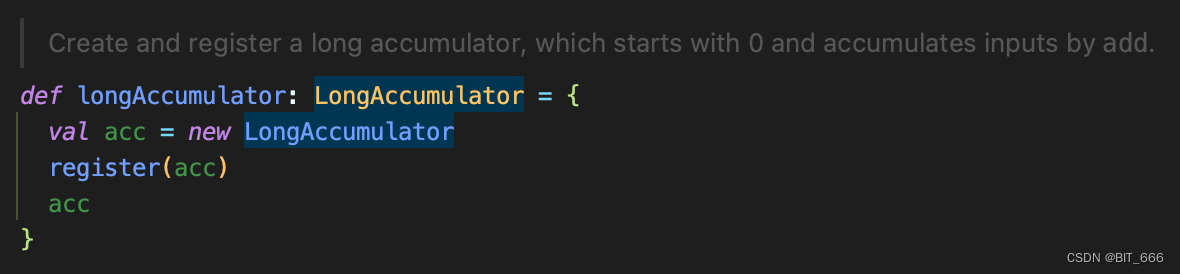
构造时只需要通过 SparkContext 即可:
val spark = SparkSession
.builder
.appName(AppName)
.getOrCreate()
val sc = spark.sparkContext
// 初始化
val cost = sc.longAccumulator
// 累加值,类型为 Long
cost.add(1L)调用该方法会初始化并注册当前计数器:
2.使用方法
相比前面的 atomic.LongAccumulator,Spark.util.LongAccumulator 的 add 累加方法会同时记录 count +1,所以相比上面同时初始化 cost 和 num 的两个计数器相比,这里可以节省一倍操作量。
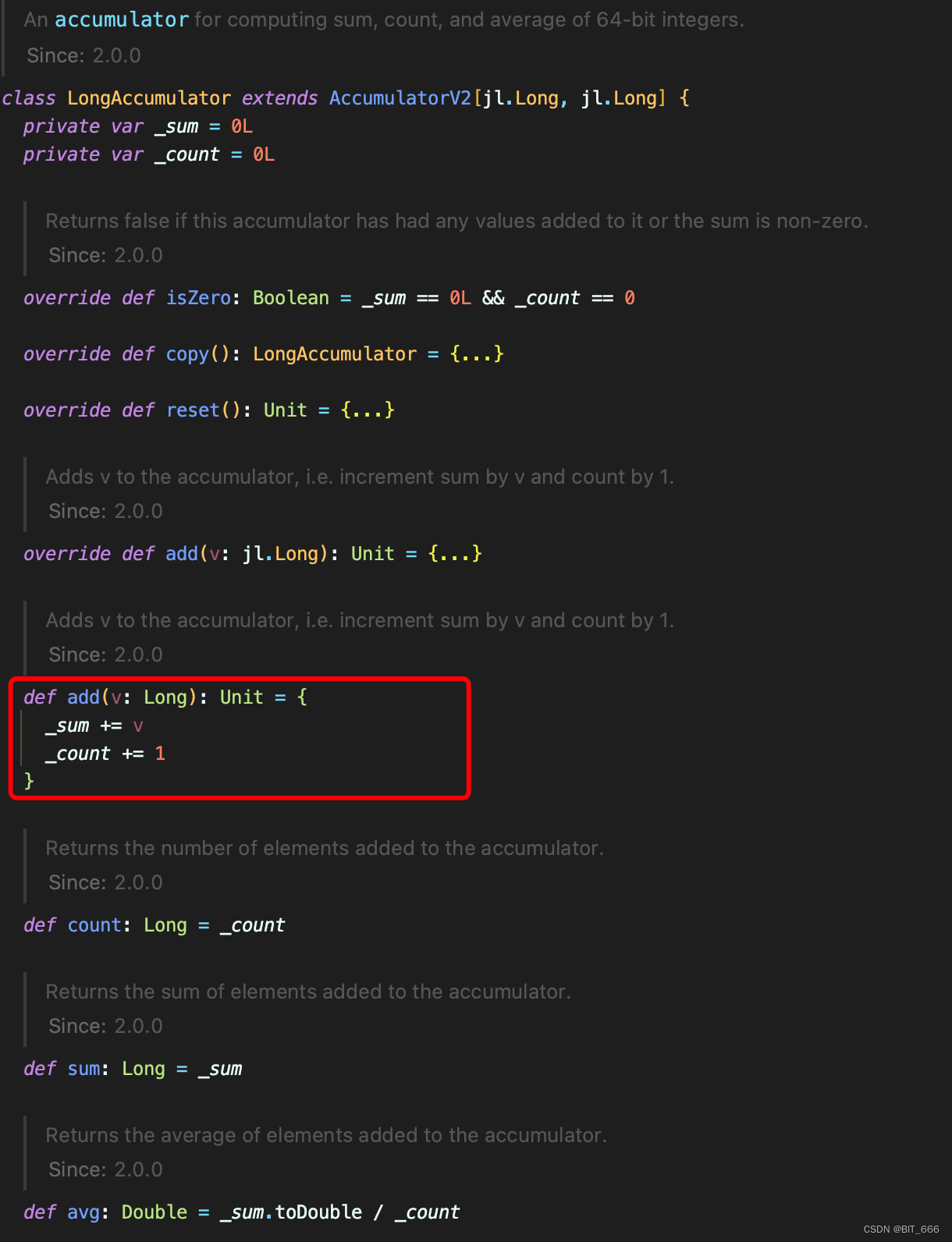
add 后我们可以通过 .value 方法获取其计数器的值,也可以通过 avg 方法获取当前统计量的均值。如果需要同时统计多个分类的计数器,可以通过 HashMap 构造多个 KV 组合,根据不同 key 累加即可。