首先说明下,PDF需要是电子版本的,不能是图片或者无法选中的那种。
需求1:假如我有一批数量比较多的同样格式的PDF电子文档,需要把特定多个区域的数字或者文字提取出来
需求2:我有一批PDF文档,但是文件的名称都是一些乱码,我需要根据PDF文件里面第一页内容的标题来批量重命名这些文件
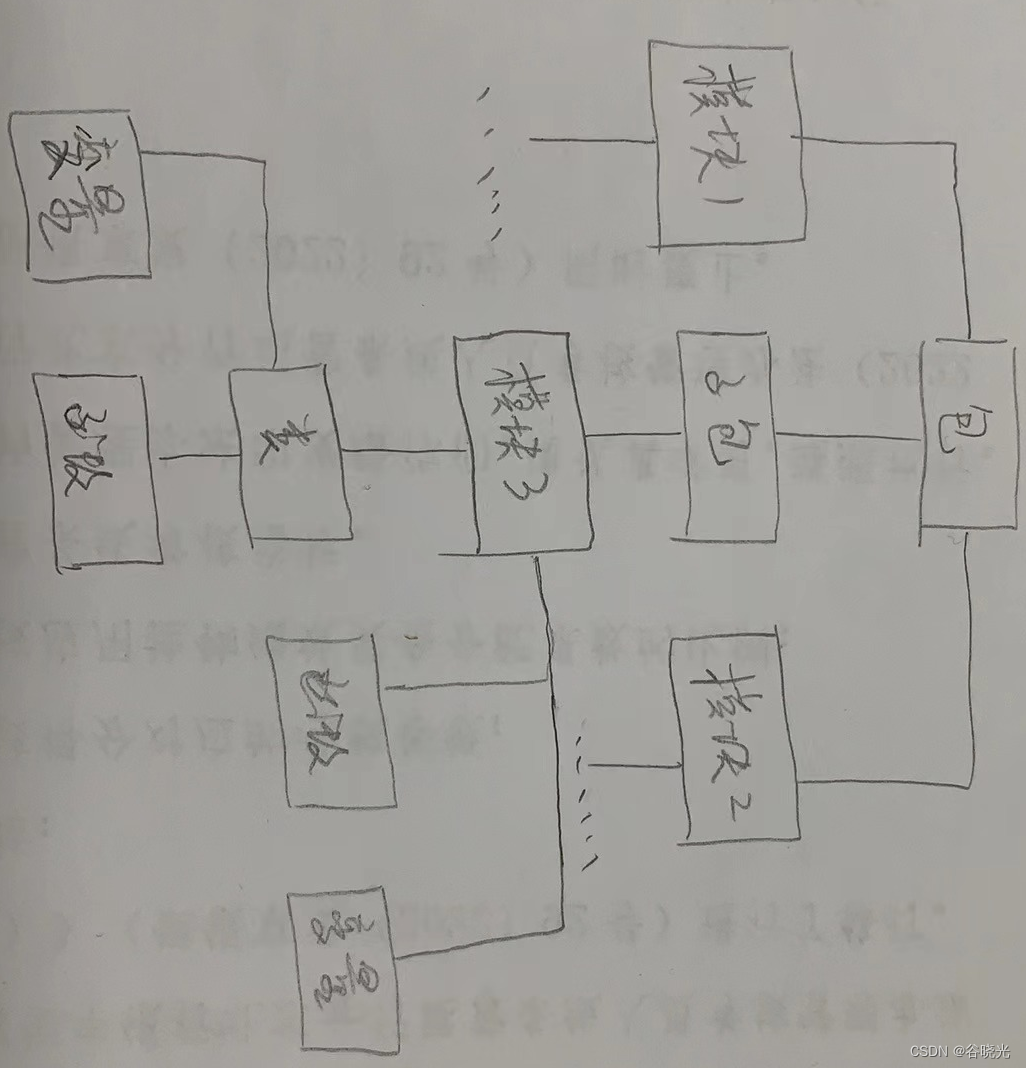
需求1思路:我们任意选一个PDF文件作为样本,然后用代码把要提取的区域用方框标注出来,再然后把这些区域的坐标保存下来,后续批量处理每个PDF的时候,就根据保存的这些区域坐标来提取对应位置的文字或者数字
思路示意图:

最后的结果示意图:

这种思路的缺陷和需要注意的点:
1 需要每个批量处理的文件要提取的数据的位置都是一样的,比如第一个PDF文件需要提取的数字位于【100,100】这个坐标,那么后续每个文件需要提取的数字都要位于这个位置,如有变动,就会导致提取不到需要的数据
2 如果提取的文字不齐全,说明可能框选的方框略微小了一点,我代码里面设置了一个单独增大某个区域的功能
需求2思路:一批PDF文档的名称都是一些乱码,我需要根据PDF文件里面第一页内容的标题来批量重命名这些文件,实际上很简单,就是解析PDF文件,然后获取第一行的内容,然后重命名该文件即可,这个代码不复杂,就没放在本页了。
欢迎试用~
下载链接:https://pan.baidu.com/s/1WQQ8kaDilaagjoK5IrYZzA
提取码:1111