-
ELFK的组成:
-
- Elasticsearch: 它是一个分布式的搜索和分析引擎,它可以用来存储和索引大量的日志数据,并提供强大的搜索和分析功能。 (java语言开发,)
- logstash: 是一个用于日志收集,处理和传输的工具,它可以从各种数据源收集日志数据,对数据进行处理和过滤,将数据发送到Elasticsearch。 java
- kibana: 是一个用于数据可视化和分析的工具,它可以与Elasticsearch集成,帮助用户通过图表、仪表盘等方式直观地展示和分析日志数据。 java
- filebeat: 轻量级日志收集工具,一般安装在客户端服务器上负责收集日志,传输到ES或logstash go
-
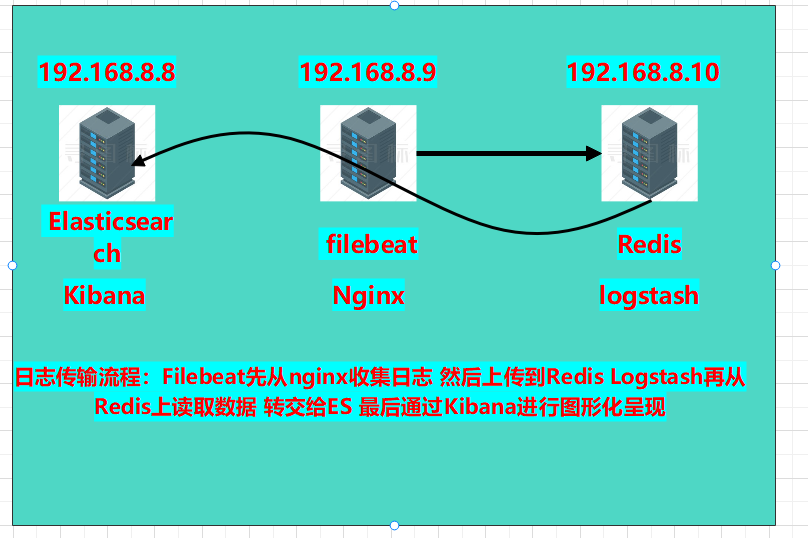
本章实验环境拓扑图:
-
- 版本介绍:
- Elasticsearch:6.6.0
- kibana:6.6.0
- filebeat:6.6.0
- nginx:1.18.0
- Redis:5.0.7
- logstash:6.6.0
- 开始部署:
- 部署8.8服务器的es和Kibna:a
- 复制软件包至服务器下安装:
- rpm -ivh elasticsearch-6.6.0.rpm
- 修改配置文件:
- vim /etc/elasticsearch/elasticsearch.yml
-
node.name: es1 path.data: /data/elasticsearch path.logs: /var/log/elasticsearch bootstrap.memory_lock: true network.host: 192.168.8.8,127.0.0.1 http.port: 9200
-
- vim /etc/elasticsearch/elasticsearch.yml
- 创建数据目录,并修改权限
-
mkdir -p /data/elasticsearch chown -R elasticsearch.elasticsearch /data/elasticsearch/
-
- 启动es:systemctl start elasticsearch
- 部署安装kibana:
- 安装kibana:rpm -ivh kibana-6.6.0-x86_64.rpm
- 修改配置文件:
- 修改项:
-
server.port: 5601 server.host: "192.168.8.8" server.name: "db01" #自己所在主机的主机名 elasticsearch.hosts: ["http://192.168.8.8:9200"] #es服务器的ip,便于接收日志数据 保存退出
-
- 修改项:
- 启动kibana:systemctl start kibana
- 查看两个服务的端口是否存在:
- netstat -anpt | grep 5601
- netstat -anpt | grep 9200
- 复制软件包至服务器下安装:
- 部署8.9服务器山的nginx和filebeat:
- 安装filebeat:
- rpm -ivh filebeat-6.6.0-x86_64.rpm
- 修改配置文件:
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
filebeat.inputs: (日志来源) - type: log (日志格式) enabled: true (开机自启) paths: (日志路径) - /var/log/nginx/access.log output.elasticsearch: (日志传送到那) hosts: ["192.168.8.8:9200"]
-
-
启动filebeat服务:
-
systemctl start filebeat
-
- vim /etc/filebeat/filebeat.yml (清空源内容,直接覆盖)
-
安装nginx:
-
yum -y install nginx
-
启动nginx:nginx
-
- 安装filebeat:
-
在8.8服务器上安装网站压力测试工具:
-
yum -y install httpd-tools
-
-
2.使用ab压力测试工具测试访问
-
ab -c 1000 -n 20000 http://192.168.8.9/
-c(并发数) -n(请求数)
-
- 部署8.8服务器的es和Kibna:a
-
使用浏览器扩展程序登录es查看索引是否有访问数:
-
-
修改nginx的日志个数为json:
-
vim /etc/nginx/nginx.conf
-
添加在http{}内:
-
log_format log_json '{ "@timestamp": "$time_local", ' '"remote_addr": "$remote_addr", ' '"referer": "$http_referer", ' '"request": "$request", ' '"status": $status, ' '"bytes": $body_bytes_sent, ' '"agent": "$http_user_agent", ' '"x_forwarded": "$http_x_forwarded_for", ' '"up_addr": "$upstream_addr",' '"up_host": "$upstream_http_host",' '"up_resp_time": "$upstream_response_time",' '"request_time": "$request_time"' ' }'; access_log /var/log/nginx/access.log log_json;
-
-
重启服务:systemctl restart nginx
-
-
修改filebeat.yml文件,区分nginx的访问日志和错误日志
-
vim /etc/filebeat/filebeat.yml
-
修改为: filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true tags: ["access"] - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["error"] output.elasticsearch: hosts: ["192.168.8.8:9200"] indices: - index: "nginx-access-%{+yyyy.MM.dd}" when.contains: tags: "access" - index: "nginx-error-%{+yyyy.MM.dd}" when.contains: tags: "error" setup.template.name: "nginx" setup.template.patten: "nginx-*" setup.template.enabled: false setup.template.overwrite: true
-
-
重启服务:systemctl restart filebeat
-
-
使用ab工具压力测试一下网站:
-
测试访问数据:ab -c 1000 -n 20000 http://192.168.8.9/
-
测试错误数据:ab -c 1000 -n 20000 http://192.168.8.9/444.html
-
可以看到es收集到了两个索引:
-
-
-
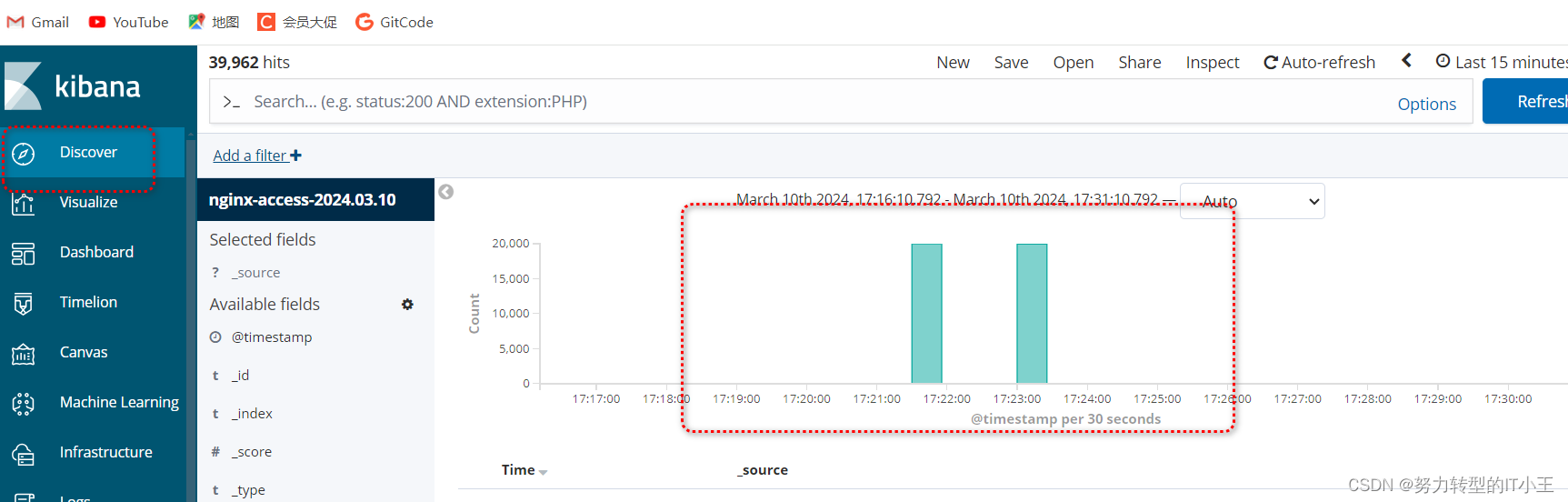
使用kibana图形化展示日志访问数据:
-
http://192.168.8.8:5601/
-
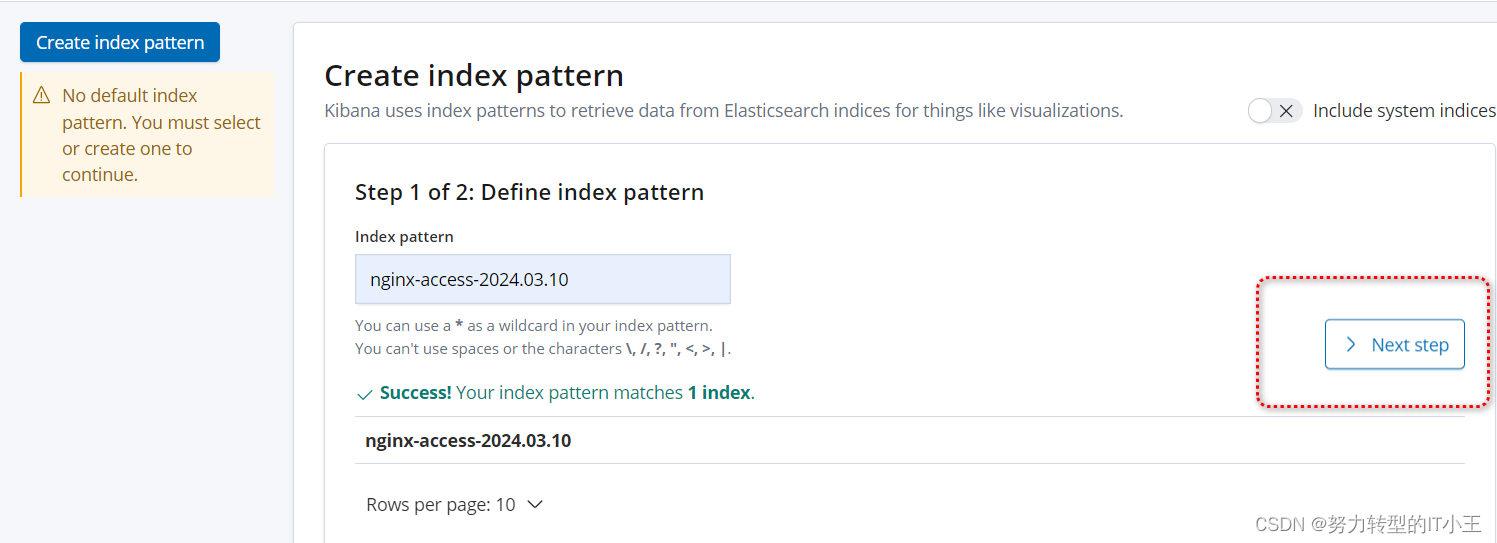
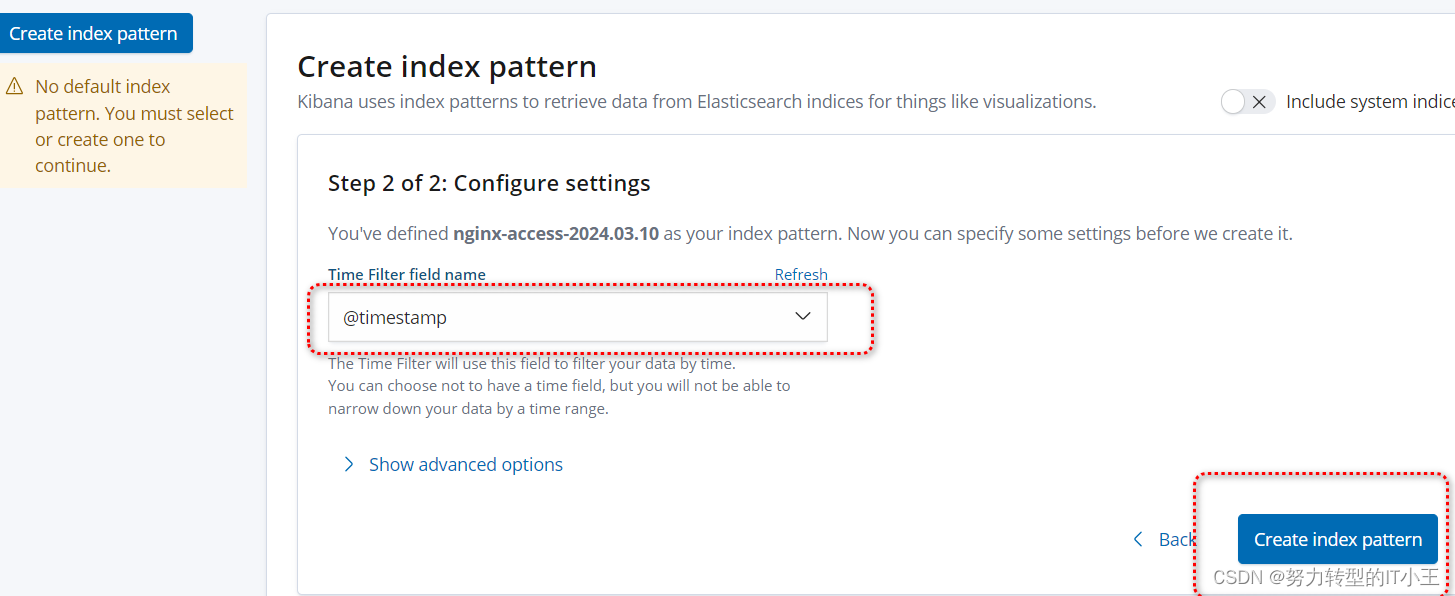
创建索引,图形化展示:
-
-
按照此步骤 将error错误索引页创建一下即可
-
-
虽然以上环境也可以进行日志收集,但只适用于中小型公司,以下再多增加一台服务器,安装redis实现消息队列,和logstash日志采集,增加吞吐量。
-
在8.10服务器上部署redis和logstash:
-
准备安装目录和数据目录:
-
mkdir -p /data/soft mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
-
-
下载redis安装包:
-
cd /data/soft wget http://download.redis.io/releases/redis-5.0.7.tar.gz
-
-
将软件包解压到/opt/redis_cluster文件夹中:
-
tar xf redis-5.0.7.tar.gz -C /opt/redis_cluster/ ln -s /opt/redis_cluster/redis-5.0.7 /opt/redis_cluster/redis
-
-
切换目录编译安装redis:
-
cd /opt/redis_cluster/redis make && make install
-
-
编写redis配置文件:
-
vim /opt/redis_cluster/redis_6379/conf/6379.conf
-
bind 127.0.0.1 192.168.8.10 port 6379 daemonize yes pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log databases 16 dbfilename redis.rdb dir /opt/redis_cluster/redis_6379
-
-
启动redis服务:redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
-
-
修改8.9的filebeat文件(将filebeat收集的日志转发给redis):
-
vim /etc/filebeat/filebeat.yml
-
filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/access.log json.keys_under_root: true json.overwrite_keys: true tags: ["access"] - type: log enabled: true paths: - /var/log/nginx/error.log tags: ["error"] setup.template.settings: index.number_of_shards: 3 setup.kibana: output.redis: hosts: ["192.168.8.10"] key: "filebeat" db: 0 timeout: 5
-
- 重启服务:systemctl restart filebeat
- 再次在8.8上使用压力测试工具访问网站:ab -c 1000 -n 20000 http://192.168.8.9/
- 登录redis数据库:redis-cli
- 查看是否有以filebeat命名的键:
- filebeat与redis关联成功!
- 查看是否有以filebeat命名的键:
-
-
- 继续在8.10服务器上部署logstash:
- rpm -ivh logstash-6.6.0.rpm
- 修改logstash配置文件,实现access和error日志分离
- vim /etc/logstash/conf.d/redis.conf
-
input { redis { host => "192.168.8.10" port => "6379" db => "0" key => "filebeat" data_type => "list" } } filter { mutate { convert => ["upstream_time","float"] convert => ["request_time","float"] } } output { stdout {} if "access" in [tags] { elasticsearch { hosts => ["http://192.168.8.8:9200"] index => "nginx_access-%{+YYYY.MM.dd}" manage_template => false } } if "error" in [tags] { elasticsearch { hosts => ["http://192.168.8.8:9200"] index => "nginx_error-%{+YYYY.MM.dd}" manage_template => false } } }
-
- 最后重启logstash:
-
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis.conf
-
-
过程需等待,启动较慢(大约2-3分钟)
- vim /etc/logstash/conf.d/redis.conf
-
最后通过kibana图形化界面,可以看到nginx的access日志和error错误日志即可,最终效果和仅部署elk效果一致,只不过添加了redis数据库和filebeat日志收集工具,有了redis可以实现了消息队列为es服务器减轻了压力。
-
ELFK 分布式日志收集系统
news2026/3/16 3:34:29





本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1506932.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

04hive数仓内外部表复杂数据类型与分区分桶
hive内部表和外部表
默认为内部表,外部表的关键字 :external内部表:对应的文件夹就在默认路径下 /user/hive/warehouse/库名.db/外部表:数据文件在哪里都行,无须移动数据
# students.txt
1,Lucy,girl,23
2,Tom,boy,2…

2023年终总结——跌跌撞撞不断修正
目录 一、回顾1.一月,鼓足信心的开始2.二月,焦躁不安3.三月,路还是要一步一步的走4.四月,平平淡淡的前行5.五月,轰轰烈烈的前行6.六月,看事情更底层透彻了7.七月,设计模式升华月8.八月ÿ…

加速 Webpack 构建:提升效率的秘诀
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…
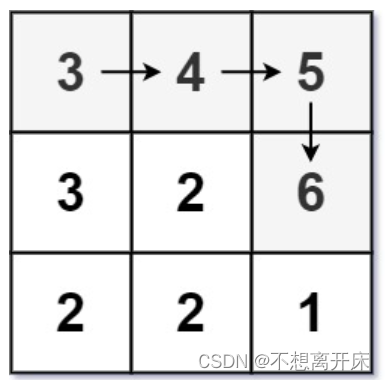
LCR 112. 矩阵中的最长递增路径【leetcode】/dfs+记忆化搜索
LCR 112. 矩阵中的最长递增路径
给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 不能 在 对角线 方向上移动或移动到 边界外(即不允…

【C语言基础】:深入理解指针(终篇)
文章目录 深入理解指针一、函数指针变量4.1 函数指针变量的创建4.2 函数指针变量的使用4.3 typedef关键字 二、函数指针数组三、转移表四、回调函数4.1 什么是回调函数4.2 qsort使用举例4.2.1 使用qsort函数排序整形数据4.2.2 使用qsort排序结构数据4.2.3 qsort函数的模拟实现 …

贝叶斯优化的门控循环神经网络BO-GRU(时序预测)的Matlab实现
贝叶斯优化的门控循环神经网络(BO-GRU)是一种结合了贝叶斯优化(Bayesian Optimization, BO)和门控循环单元(Gated Recurrent Unit, GRU)的模型,旨在进行时序预测。这种模型特别适用于时间序列数…
python文件组织:包(package)、模块(module)、文件(file)
包:
模块所在的包,创建一个包用于组织多个模块,包文件夹中必须创建一个名为’__init__.py’的文件,以将其识别为包,否则只能算作是一个普通的目录。在使用该包时,init自动执行。
包可以多层嵌套ÿ…
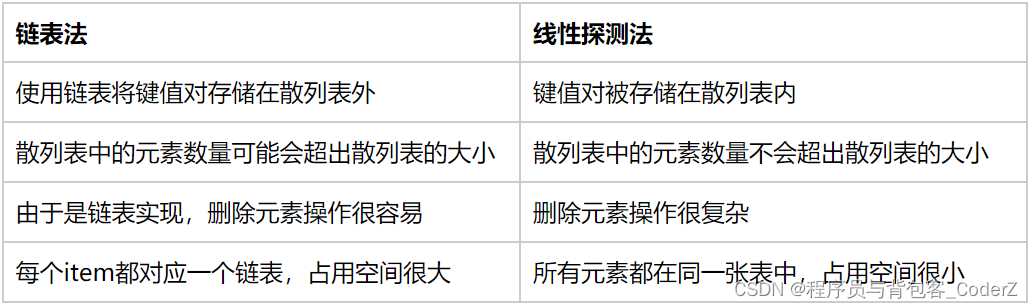
数据结构小记【Python/C++版】——散列表篇
一,基础概念
散列表,英文名是hash table,又叫哈希表。
散列表通常使用顺序表来存储集合元素,集合元素以一种很分散的分布方式存储在顺序表中。
散列表是一个键值对(key-item)的组合,由键(key)和元素值(item)组成。键…
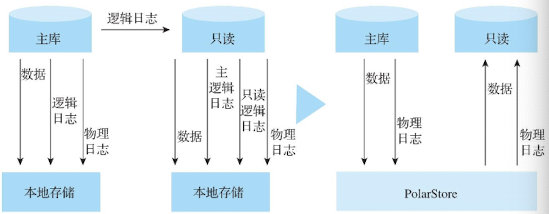
探索云原生数据库技术:构建高效可靠的云原生应用
数据库是应用开发中非常重要的组成部分,可以进行数据的存储和管理。随着企业业务向数字化、在线化和智能化的演进过程中,面对指数级递增的海量存储需求和挑战以及业务带来的更多的热点事件、突发流量的挑战,传统的数据库已经很难满足和响应快…
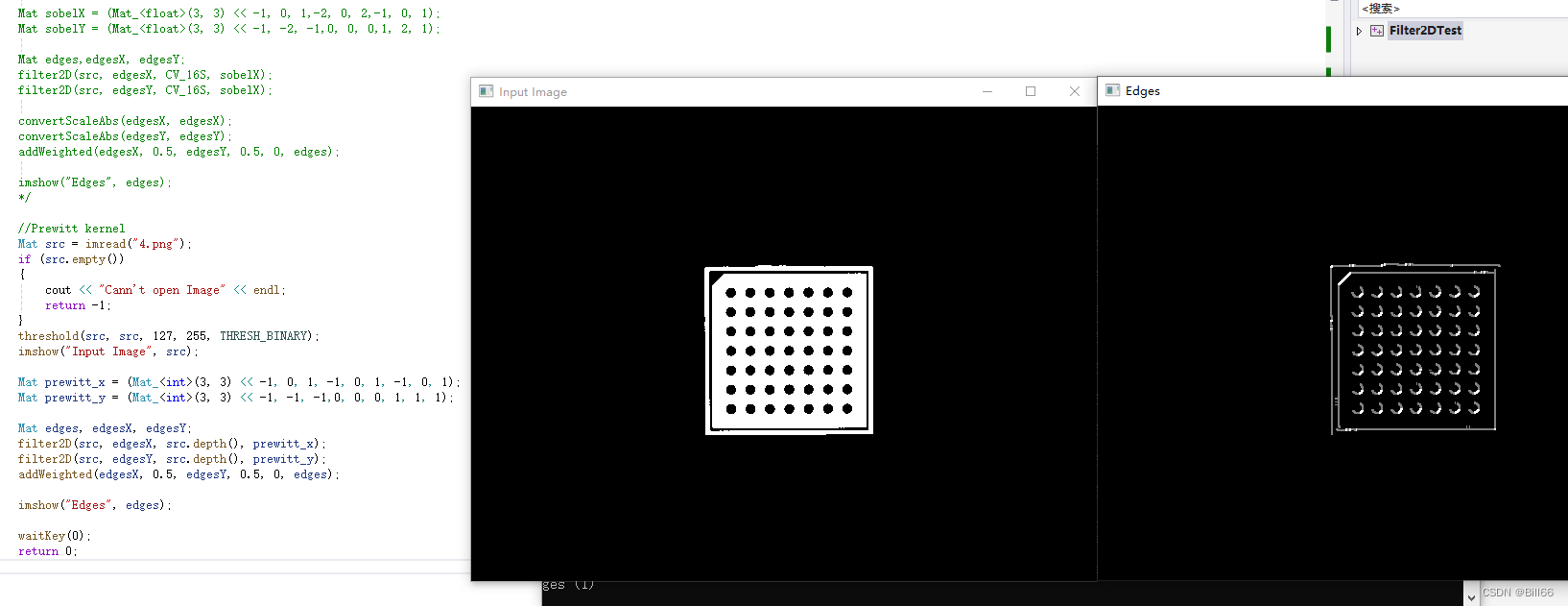
OpenCV filter2D函数详解
OpenCV filter2D函数简介 OpenCV filter2D将图像与内核进行卷积,将任意线性滤波器应用于图像。支持就地操作。当孔径部分位于图像之外时,该函数根据指定的边界模式插值异常像素值。 该函数实际上计算相关性,而不是卷积: filter…
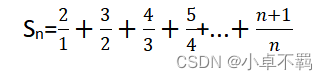
【Spark编程基础】实验一Spark编程初级实践(附源代码)
文章目录 一、实验目的二、实验平台三、实验内容和要求1. 计算级数2. 模拟图形绘制3.统计学生成绩 一、实验目的
1.掌握 Scala 语言的基本语法、数据结构和控制结构; 2.掌握面向对象编程的基础知识,能够编写自定义类和特质; 3.掌握函数式编程…


Windows电脑安装Linux(Ubuntu 22.04)系统(图文并茂)
Windows电脑安装Ubuntu 22.04系统,其它版本的Ubuntu安装方法相同
Ubuntu 16.04、Ubuntu 18.04安装方法相同,制作U盘启动项的镜像文件下载你需要的版本即可! Ubuntu的中文官网网址:https://cn.ubuntu.com/,聪明的你一定…

【线程】封装 | 安全 | 互斥
线程封装(面向对象)
1.组件式的封装出一个线程类(像C11线程库那样去管理线程)
我们并不想暴露出线程创建,终止,等待,分离,获取线程id等POSIX线程库的接口,我们也想像C1…
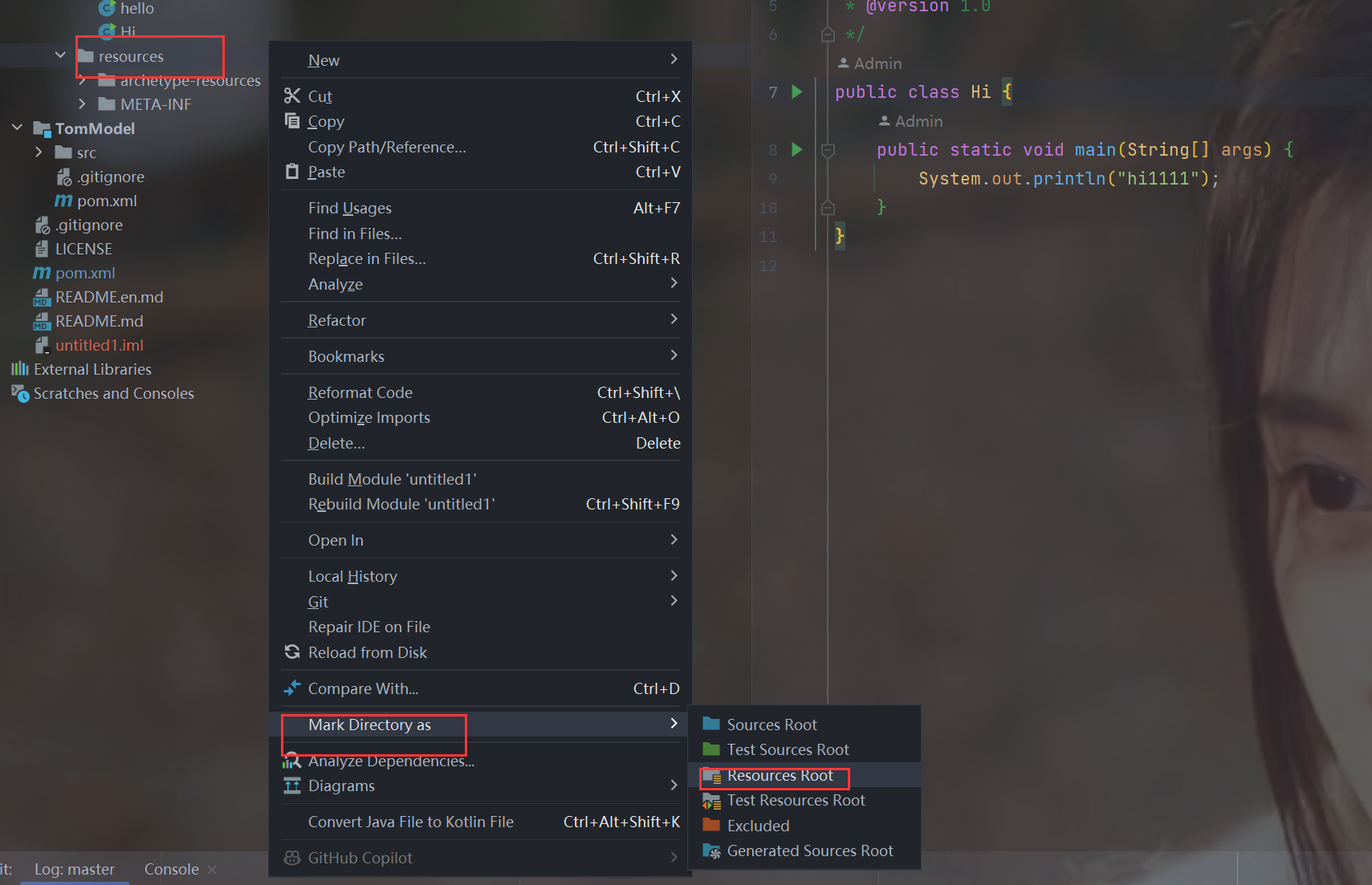
IDEA管理Git + Gitee 常用操作
文章目录 IDEA管理Git Gitee 常用操作1.Gitee创建代码仓库1.创建仓库1.点击新建仓库2.完成仓库信息填写3.创建成功4.管理菜单可以修改这个项目的设置 2.设置SSH公钥免密登录基本介绍1.找到.ssh目录2.执行指令 ssh-keygen3.将公钥信息添加到码云账户1.点击设置2.ssh公钥3.复制.…
React-配置别名@
1.概念
说明:路径解析配置(webpack),把/解析为src/;路径联想配置(VsCode),VsCode在输入/时,自动联想出来对应的src/下的子级目录。CRA本身把webpacki配置包装到了黑盒里无法直接修改,需要借助一个插件-craco。
2.实现步骤
2.1安…
docker常用操作-docker私有仓库的搭建(Harbor),并将本地镜像推送至远程仓库中。
1、docker-compose安装,下载docker-compose的最新版本
第一步:创建docker-compose空白存放文件vi /usr/local/bin/docker-compose 第二步:使用curl命令在线下载,并制定写入路径
curl -L "https://github.com/docker/compos…

npm市场发布包步骤
1.打开npm官网npm官网
2.创建自己的账号
3.查看当前npm的镜像源,
如果出现淘宝的镜像源则需要切换成官方的镜像源
npm config get registry //查看镜像源
https://registry.npm.taobao.org/ //淘宝的镜像源
https://registry.npmjs.org/ //官方的镜像源 …
![IPO[困难]](https://img-blog.csdnimg.cn/direct/92ca625923914bd6ba50614e5288e9a4.jpeg)