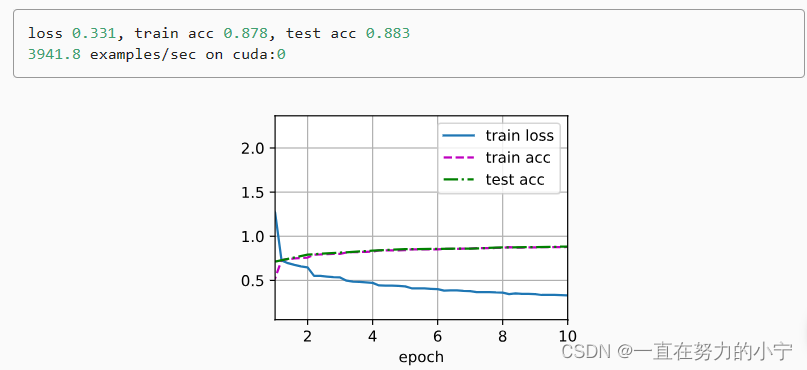
欢迎来到文思源想的ai空间,这是技术老兵重学ai以及成长思考的第15篇分享!
最近在学习prompt提示词技巧,一番研究发现其实提示词的技巧并不是限定死的,所谓技巧和心法更像是教导我们如何更清晰、更结构化的大模型聊天工具进行沟通,如何更加清晰、完整、有效地说出我们的需求!今天先就官方的提示词工程做一个系统解读和重述,后续再给出我的一些学习总结和实践心得。
备注:官方文章并没有结构化比较差,看得挺费劲的,示例和说明对应的有点散乱。本次总结是对官方文档的一个结构化整理并配上一些图文,希望读者可以更为方便的进行理解!
0 取得更好结果的策略
本指南分享了从 GPT-4 等大型语言模型(有时称为 GPT 模型)中获得更好结果的策略和策略。此处描述的方法有时可以组合部署以获得更大的效果。我们鼓励您进行实验,以找到最适合您的方法。
此处演示的一些示例目前仅适用于我们功能最强大的模型。 gpt-4通常,如果发现某个模型在任务中失败,并且有功能更强大的模型可用,则通常值得使用功能更强的模型再次尝试。
您还可以浏览示例提示,这些提示展示了我们的模型的功能:

策略1:编写清晰的说明
这些模型无法读懂你的心思。如果输出太长,请要求简短的答复。如果输出太简单,请要求专家级写作。如果您不喜欢这种格式,请演示您希望看到的格式。模型越少猜测你想要什么,你就越有可能得到它。具体清晰说明的策略总结如下图所示:

1.1 查询中包含更多详细信息

1.2 采用指定角色
系统信息可以用于指定模型在回复中使用的角色。
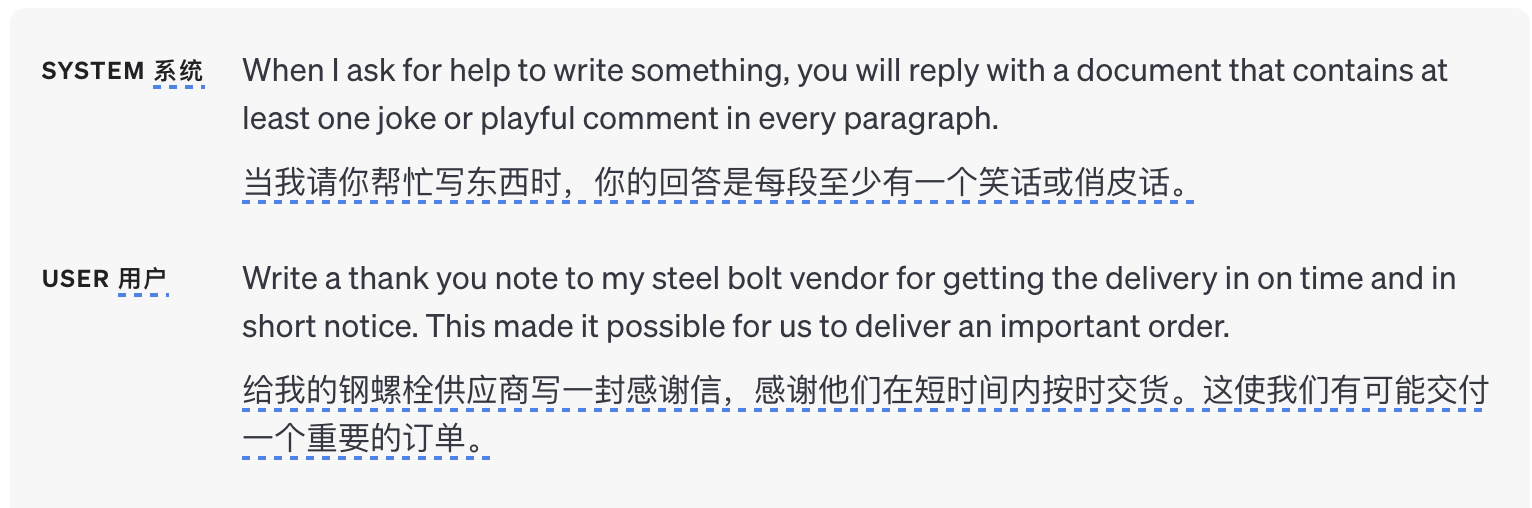
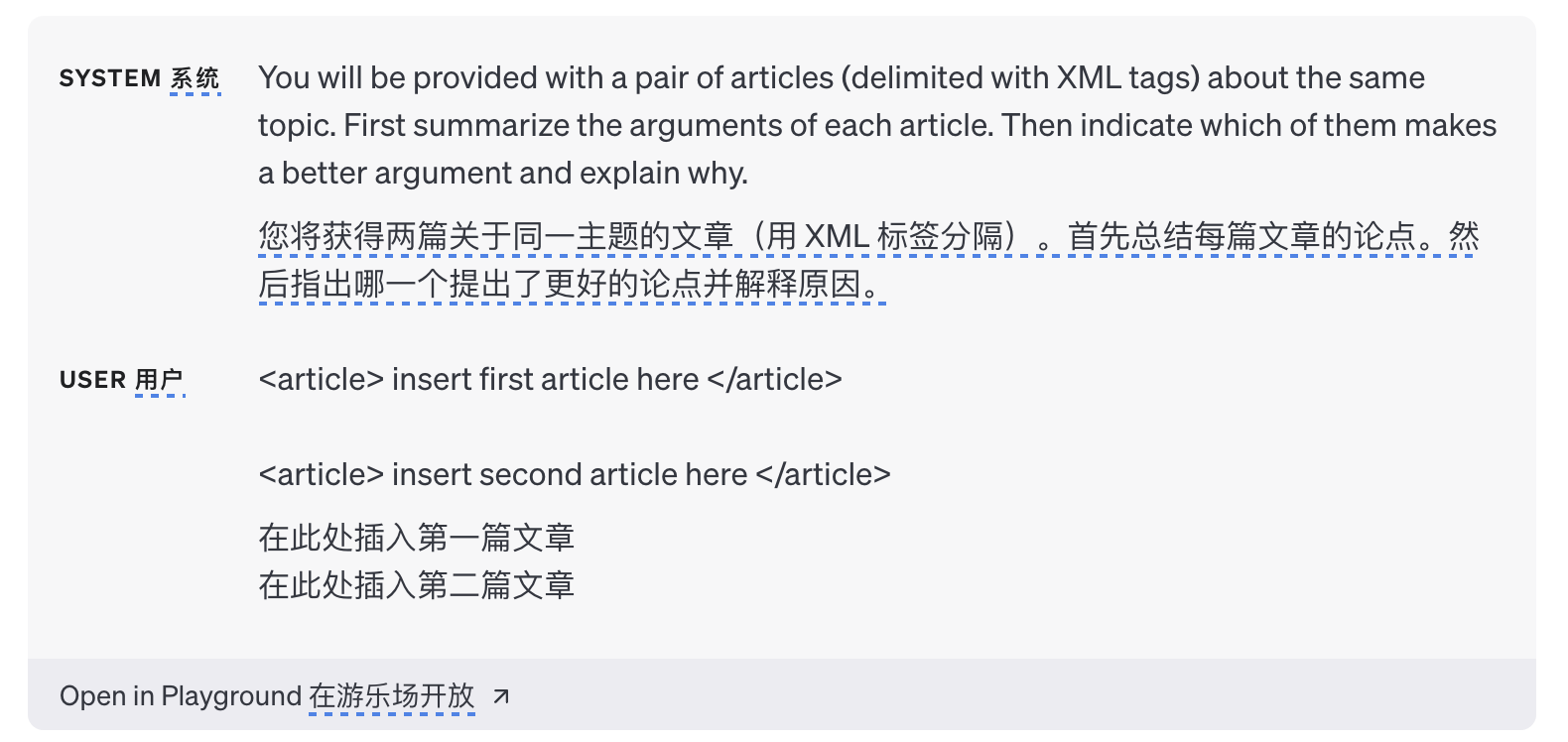
1.3 使用分隔符清楚地指示输入的不同部分

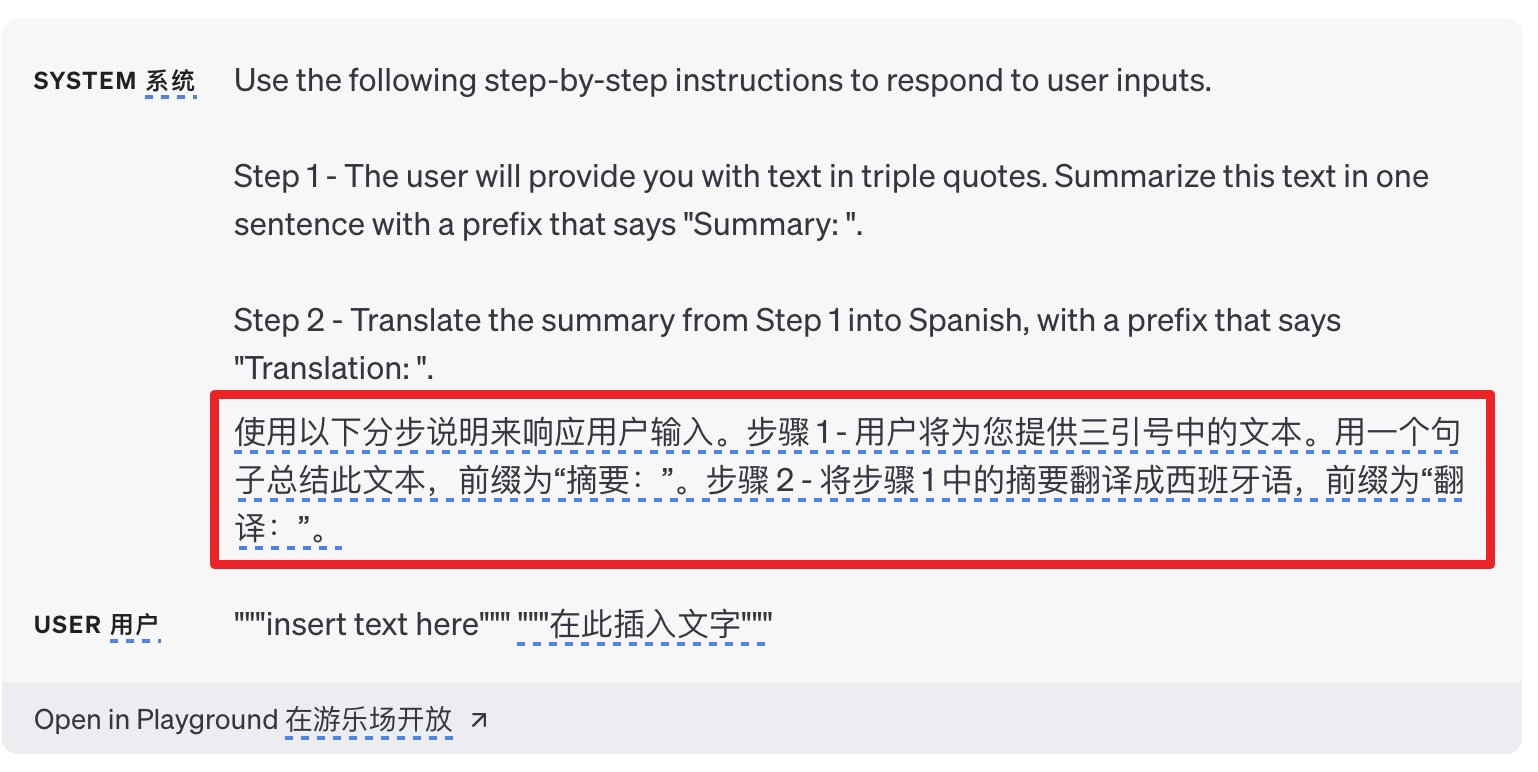
1.4 制定完成任务所需的步骤
有些任务最好指定为一系列步骤。明确地写出这些步骤可以使模型更容易遵循它们。
1.5 提供例子
提供适用于所有示例的一般说明通常比通过示例演示任务的所有排列更有效,但在某些情况下,提供示例可能更容易。例如,如果您打算让模型复制响应用户查询的特定风格,而这种风格很难明确描述。这称为“几次”提示。
1.6 指定所需的输出长度
您可以要求模型生成给定目标长度的输出。目标输出长度可以根据单词、句子、段落、要点等的计数来指定。但请注意,指示模型生成特定数量的单词并不能高精度工作。该模型可以更可靠地生成具有特定数量的段落或要点的输出。

策略2:提供参考文本
语言模型可以自信地发明虚假答案,尤其是在被问及深奥的主题或引文和 URL 时。就像一张笔记可以帮助学生在考试中做得更好一样,为这些模型提供参考文本可以帮助以更少的捏造来回答问题。

2.1 指示模型使用参考文本中的引用来回答
如果我们可以为模型提供与当前查询相关的可信信息,那么我们可以指示模型使用提供的信息来撰写其答案。

鉴于所有模型的上下文窗口有限,我们需要某种方法来动态查找与所提问题相关的信息。嵌入可用于实现高效的知识检索。有关如何实现此功能的更多详细信息,请参阅策略“使用基于嵌入的搜索来实现有效的知识检索”。
2.2 指示模型使用参考文本中的引文进行回答
如果输入已补充相关知识,则通过引用所提供文档中的段落来请求模型在其答案中添加引文是很简单的。请注意,输出中的引文可以通过提供的文档中的字符串匹配以编程方式进行验证。

策略3 将复杂的任务拆分为更简单的子任务
正如在软件工程中将复杂系统分解为一组模块化组件是很好的做法一样,提交给语言模型的任务也是如此。复杂任务的错误率往往高于简单的任务。此外,复杂任务通常可以被重新定义为简单任务的工作流,其中早期任务的输出用于构建后续任务的输入。

3.1 使用意向分类来识别与用户查询最相关的指令
对于需要大量独立指令集来处理不同情况的任务,首先对查询类型进行分类并使用该分类来确定需要哪些指令可能是有益的。这可以通过定义与处理给定类别中的任务相关的固定类别和硬编码指令来实现。此过程也可以递归应用,以将任务分解为一系列阶段。此方法的优点是,每个查询将仅包含执行任务下一阶段所需的指令,与使用单个查询执行整个任务相比,这可能会导致较低的错误率。这还可以降低成本,因为较大的提示运行成本更高(请参阅定价信息)。例如,假设对于客户服务应用程序,查询可以有效地分类如下:
您将获得客户服务查询。将每个查询分类为主要类别和次要类别。以 json 格式提供输出,其中包含以下键:primary 和 secondary。主要类别:计费、技术支持、帐户管理或一般查询.计费次要类别:- 取消订阅或升级- 添加付款方式- 收费说明- 对收费提出异议技术支持次要类别:- 故障排除- 设备兼容性- 软件更新帐户管理次要类别:- 密码重置- 更新个人信息- 关闭帐户- 帐户安全一般查询次要类别:- 产品信息- 定价- 反馈- 与人交谈
根据客户查询的分类,可以向模型提供一组更具体的指令,以便其处理后续步骤。例如,假设客户需要“故障排除”方面的帮助。
您将获得需要在技术支持环境中进行故障排除的客户服务查询。通过以下方式帮助用户:- 要求他们检查与路由器之间的所有电缆是否已连接。请注意,随着时间的流逝,电缆松动是很常见的.- 如果所有电缆都已连接并且问题仍然存在,请询问他们使用的是哪种路由器型号- 现在您将建议他们如何重新启动设备:-- 如果型号是 MTD-327J,建议他们按下红色按钮并按住 5 秒钟, 然后等待 5 分钟再测试连接.-- 如果型号是 MTD-327S,建议他们拔下并重新插入,然后等待 5 分钟再测试连接.- 如果客户的问题在重新启动设备并等待 5 分钟后仍然存在,请通过输出 {“IT support requested”}.- 如果用户开始询问与此主题无关的问题,请确认他们是否要结束当前聊天关于故障排除并根据以下方案对其请求进行分类:<在此处插入上面的主要/次要分类方案>请注意,已指示模型发出特殊字符串,以指示会话状态何时更改。这使我们能够将我们的系统变成一个状态机,其中状态决定了注入哪些指令。通过跟踪状态、与该状态相关的指令,以及允许从该状态进行哪些状态转换(可选),我们可以在用户体验周围设置护栏,而这些护栏很难通过结构化程度较低的方法实现。
3.2 对于需要很长的对话应用程序,总结或过滤以前的对话
由于模型具有固定的上下文长度,因此用户和助手之间的对话(其中整个对话都包含在上下文窗口中)不能无限期地继续。
这个问题有多种解决方法,其中之一是总结对话中的前几个回合。一旦输入的大小达到预定的阈值长度,这可能会触发一个查询,该查询汇总了部分会话,并且可以将先前会话的摘要作为系统消息的一部分包含在内。或者,可以在整个对话的后台异步总结先前的对话。
另一种解决方案是动态选择与当前查询最相关的对话的先前部分。请参阅策略“使用基于嵌入的搜索来实现有效的知识检索”。
3.3 分段总结长文档,递归构建完整摘要
由于模型具有固定的上下文长度,因此它们不能用于汇总长度超过上下文长度减去单个查询中生成的摘要长度的文本。
要总结一个很长的文档,比如一本书,我们可以使用一系列查询来总结文档的每个部分。章节摘要可以串联和汇总,从而产生摘要的摘要。此过程可以递归进行,直到汇总整个文档为止。如果有必要使用有关前面部分的信息来理解后面的部分,那么另一个有用的技巧是,在总结该点的内容时,在本书中任何给定点之前包含文本的运行摘要。OpenAI 在之前使用 GPT-3 变体的研究中已经研究了这种总结书籍程序的有效性。
策略4 给模型思考的时间
如果被要求将 17 乘以 28,您可能不会立即知道,但仍然可以随着时间的推移计算出来。同样,模型在试图立即回答时会犯更多的推理错误,而不是花时间找出答案。在回答之前询问“思维链”可以帮助模型更可靠地推理正确答案。
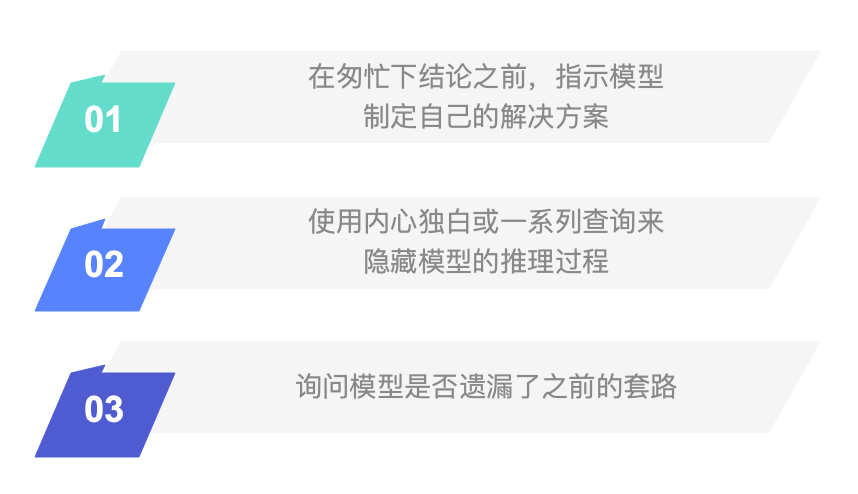
4.1 在匆忙下结论之前,指示模型制定自己的解决方案
有时,当我们明确指示模型在得出结论之前从第一性原理进行推理时,我们会得到更好的结果。例如,假设我们想要一个模型来评估学生对数学问题的解决方案。解决这个问题的最明显方法是简单地询问模型学生的解决方案是否正确。
示例如下:

但学生的解决方案其实是不正确的!我们可以通过提示模型首先生成自己的解决方案来让模型成功注意到这一点。

4.2 使用内心独白或一系列查询来隐藏模型的推理过程
前面的策略表明,在回答特定问题之前,模型有时对问题进行详细推理很重要。对于某些应用程序,模型用于得出最终答案的推理过程不适合与用户共享。例如,在辅导应用程序中,我们可能希望鼓励学生自己找出答案,但模型对学生解决方案的推理过程可能会向学生揭示答案。
内心独白是一种可以用来缓解这种情况的策略。内心独白的想法是指示模型将输出中本应对用户隐藏的部分放入结构化格式中,以便于解析它们。然后,在将输出呈现给用户之前,将对输出进行解析,并且仅显示部分输出。
或者,这可以通过一系列查询来实现,其中除最后一个查询外,所有查询的输出都对最终用户隐藏。
首先,我们可以要求模型自己解决问题。由于此初始查询不需要学生的解决方案,因此可以省略它。这提供了额外的优势,即模型的解决方案不会因学生尝试的解决方案而产生偏差。
接下来,我们可以让模型使用所有可用信息来评估学生解决方案的正确性。

最后,我们可以让模型使用自己的分析来构建一个乐于助人的导师角色的回复。

4.3 询问模型是否遗漏了之前的方法
假设我们正在使用一个模型来列出与特定问题相关的来源的摘录。列出每个摘录后,模型需要确定是否应该开始编写另一个摘录,或者是否应该停止。如果源文档很大,模型通常会过早停止并且无法列出所有相关的摘录。在这种情况下,通常可以通过提示模型进行后续查询来查找在之前传递中遗漏的任何摘录来获得更好的性能。

策略5 使用外部工具
通过向模型提供其他工具的输出来补偿模型的弱点。例如,文本检索系统(有时称为 RAG 或检索增强生成)可以告诉模型相关文档。像 OpenAI 的 Code Interpreter 这样的代码执行引擎可以帮助模型进行数学运算和运行代码。如果一项任务可以通过工具而不是语言模型更可靠或更高效地完成,请卸载它以获得两者的最佳效果。

5.1 使用基于嵌入的搜索来实现高效的知识检索
如果模型作为其输入的一部分提供,则可以利用外部信息源。这可以帮助模型生成更明智和最新的响应。例如,如果用户询问有关特定电影的问题,则将有关电影的高质量信息(例如演员、导演等)添加到模型的输入中可能很有用。嵌入可用于实现高效的知识检索,以便在运行时动态地将相关信息添加到模型输入中。
文本嵌入是可以测量文本字符串之间相关性的向量。相似或相关的字符串将比不相关的字符串更接近。这一事实,以及快速向量搜索算法的存在,意味着嵌入可用于实现有效的知识检索。特别是,文本语料库可以拆分为多个块,每个块都可以嵌入和存储。然后,可以嵌入给定的查询,并可以执行向量搜索,以从语料库中查找与查询最相关的嵌入文本块(即在嵌入空间中最接近的文本块)。
示例实现可以在 OpenAI Cookbook 中找到。有关如何使用知识检索来最大程度地减少模型编造错误事实的可能性的示例,请参阅策略“指示模型使用检索到的知识来回答查询”。
5.2 使用代码执行更准确的计算或调用外部API
不能依靠语言模型本身准确地执行算术或长计算。在需要的情况下,可以指示模型编写和运行代码,而不是进行自己的计算。具体而言,可以指示模型将要运行的代码转换为指定格式,例如三重反引号。生成输出后,可以提取并运行代码。最后,如有必要,可以将代码执行引擎(即 Python 解释器)的输出作为下一个查询的模型输入。

代码执行的另一个很好的用例是调用外部 API。如果指示模型正确使用 API,它就可以编写使用它的代码。通过向模型提供演示如何使用 API 的文档和/或代码示例,可以指导模型如何使用 API。
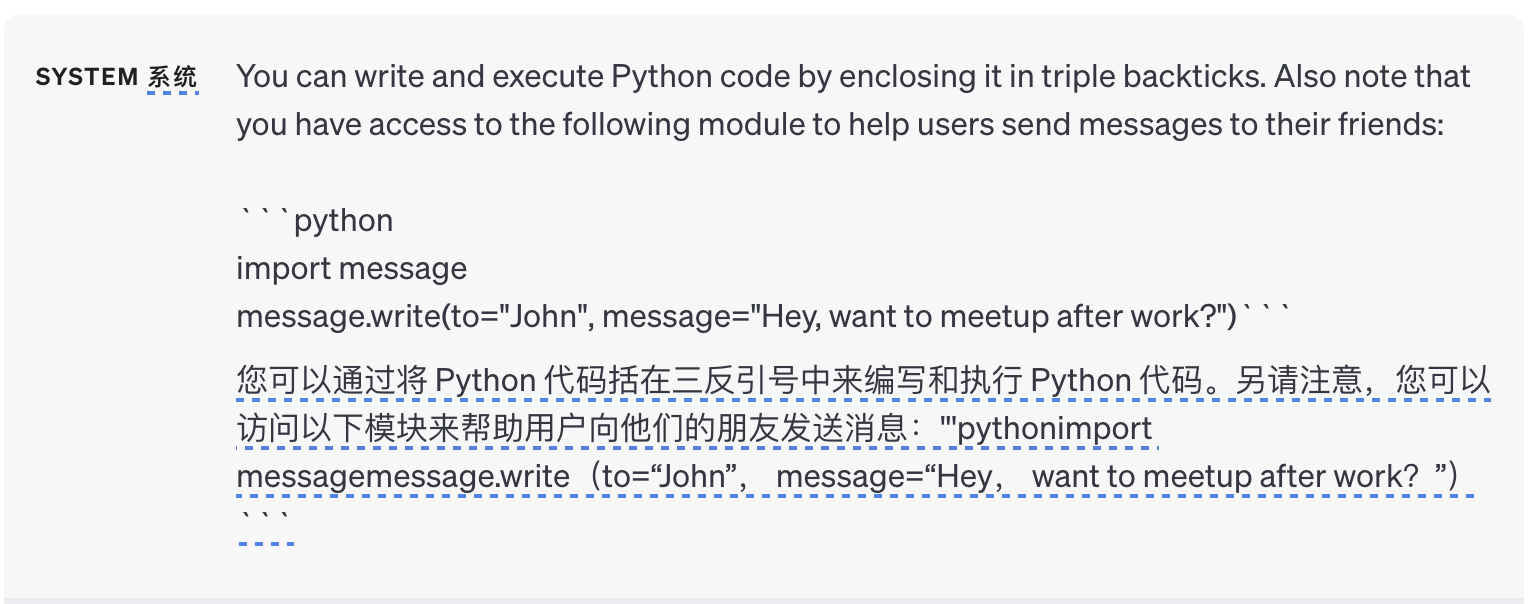
警告:执行模型生成的代码本质上并不安全,在任何试图执行此操作的应用程序中都应采取预防措施。特别是,需要一个沙盒代码执行环境来限制不受信任的代码可能造成的危害。
5.3 为模型提供对特定函数的访问权限
聊天完成 API 允许在请求中传递函数描述列表。这使模型能够根据提供的架构生成函数参数。生成的函数参数由 API 以 JSON 格式返回,可用于执行函数调用。然后,可以在以下请求中将函数调用提供的输出反馈到模型中以关闭循环。这是使用 OpenAI 模型调用外部函数的推荐方式。要了解更多信息,请参阅我们的介绍性文本生成指南中的函数调用部分以及 OpenAI Cookbook 中的更多函数调用示例。
策略6 系统地测试更改
如果可以衡量性能,则提高性能会更容易。在某些情况下,对提示的修改将在少数孤立的示例上获得更好的性能,但在更具代表性的示例集上导致整体性能较差。因此,为了确保更改对性能是净积极的,可能需要定义一个全面的测试套件(也称为“评估”)。

有时,很难判断更改(例如,新指令或新设计)是否会使您的系统变得更好或更糟。看几个例子可能会暗示哪个更好,但是由于样本量很小,很难区分真正的改进或随机运气。也许这种变化有助于提高某些输入的性能,但会损害其他输入的性能。
评估程序(或“评估”)对于优化系统设计非常有用。好的评估是:
- 代表现实世界的使用(或至少是多样化的)
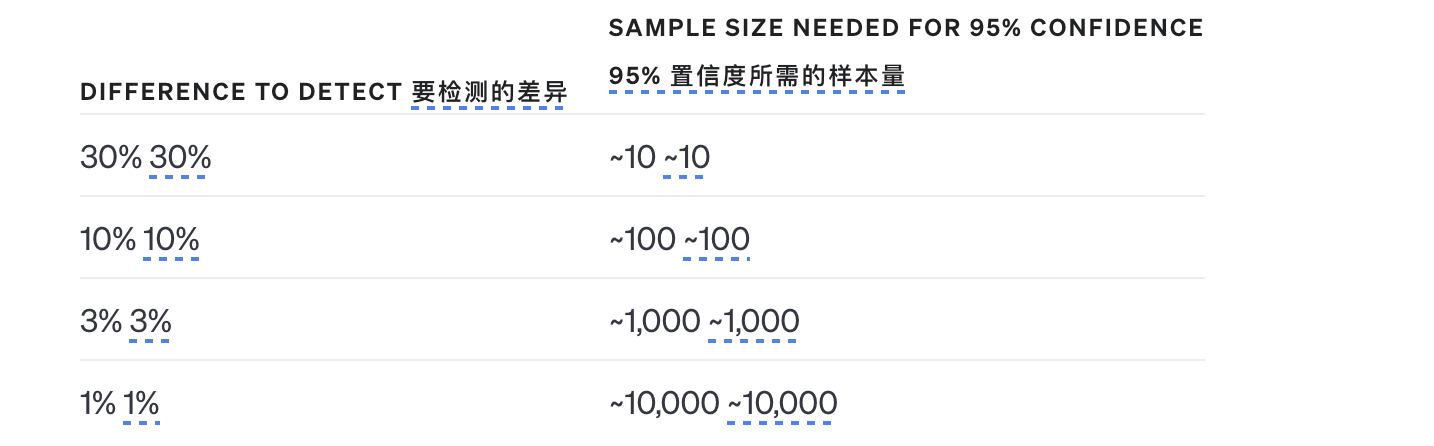
- 包含许多测试用例以获得更高的统计功效(有关指南,请参阅下表)
- 易于自动化或重复
输出的评估可以由计算机、人类或混合完成。计算机可以使用客观标准(例如,具有单个正确答案的问题)以及一些主观或模糊标准自动执行评估,其中模型输出由其他模型查询进行评估。OpenAI Evals 是一个开源软件框架,提供用于创建自动评估的工具。
当存在一系列被认为质量同样高的可能输出时,基于模型的评估可能很有用(例如,对于具有长答案的问题)。使用基于模型的评估可以实际评估的内容与需要人类评估的内容之间的界限是模糊的,并且随着模型变得越来越强大而不断变化。我们鼓励进行试验,以确定基于模型的评估值在多大程度上适用于您的用例。
6.1 参考黄金标准答案评估模型输出
假设已知问题的正确答案应参考一组特定的已知事实。然后,我们可以使用模型查询来计算答案中包含了多少个必需的事实。
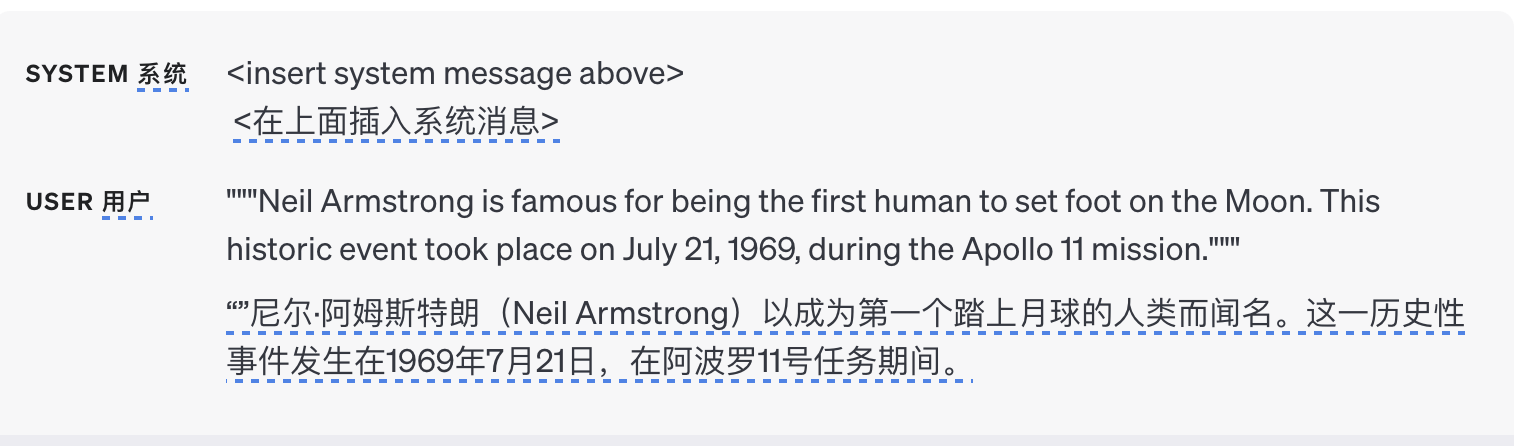
例如,使用以下系统消息:

下面是一个示例输入,其中两点都满足:
下面是一个示例输入,其中只满足一个点:

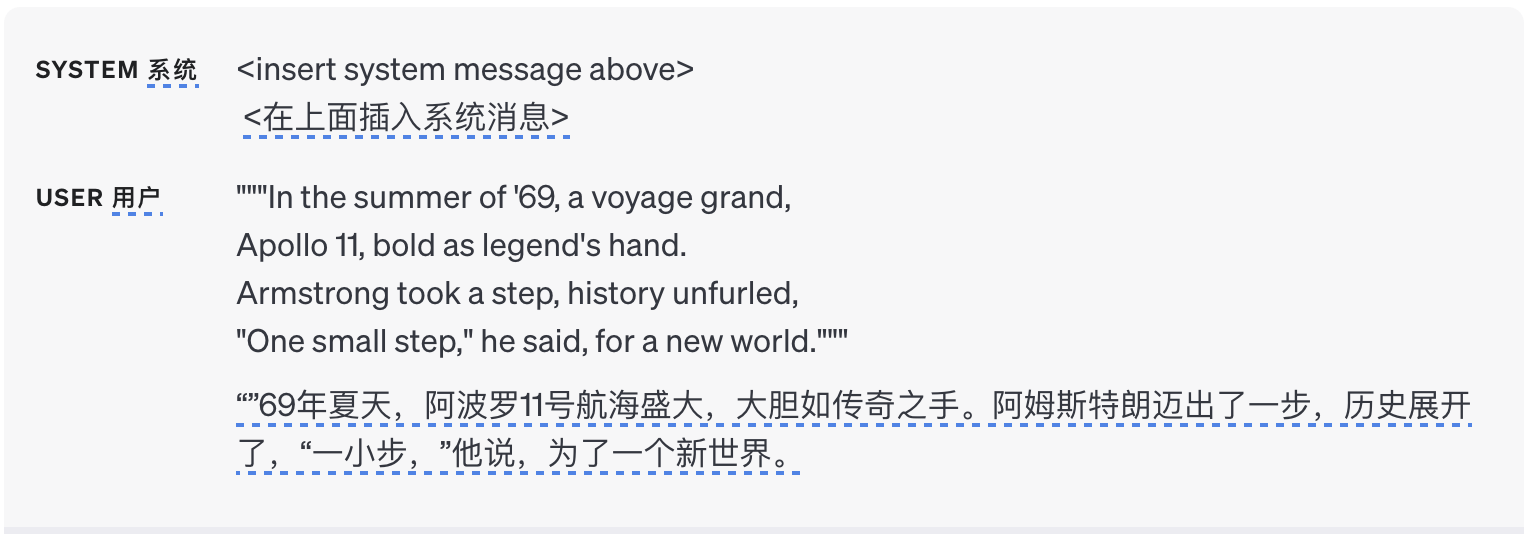
下面是一个示例输入,其中不满足任何输入:
这种基于模型的评估有许多可能的变体。考虑以下变体,它跟踪候选答案和黄金标准答案之间的重叠类型,并跟踪候选答案是否与黄金标准答案的任何部分相矛盾。

这是一个带有不合格答案的示例输入,但与专家答案并不矛盾:
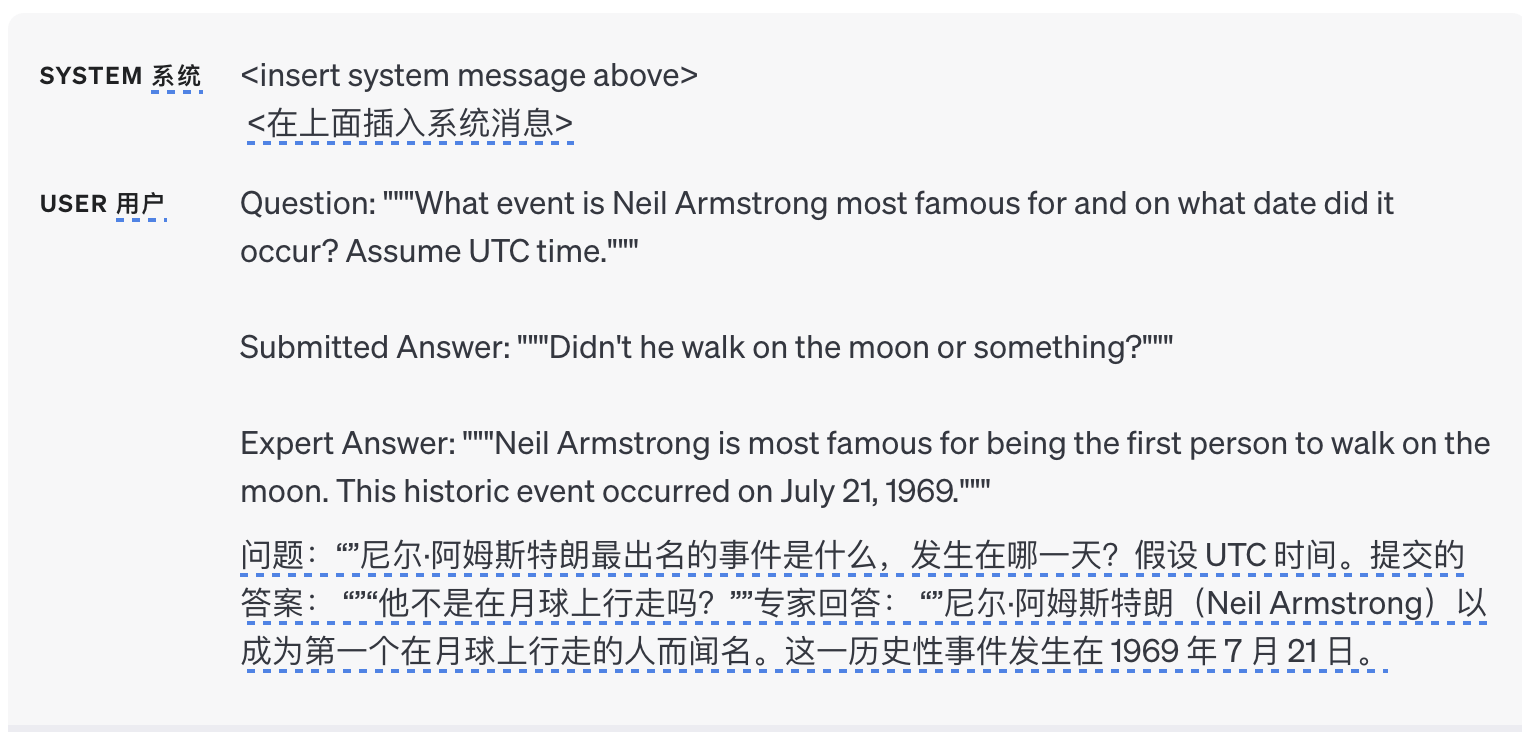
下面是一个示例输入,其答案与专家答案直接矛盾:

下面是一个包含正确答案的示例输入,该输入还提供了比必要的更多详细信息:
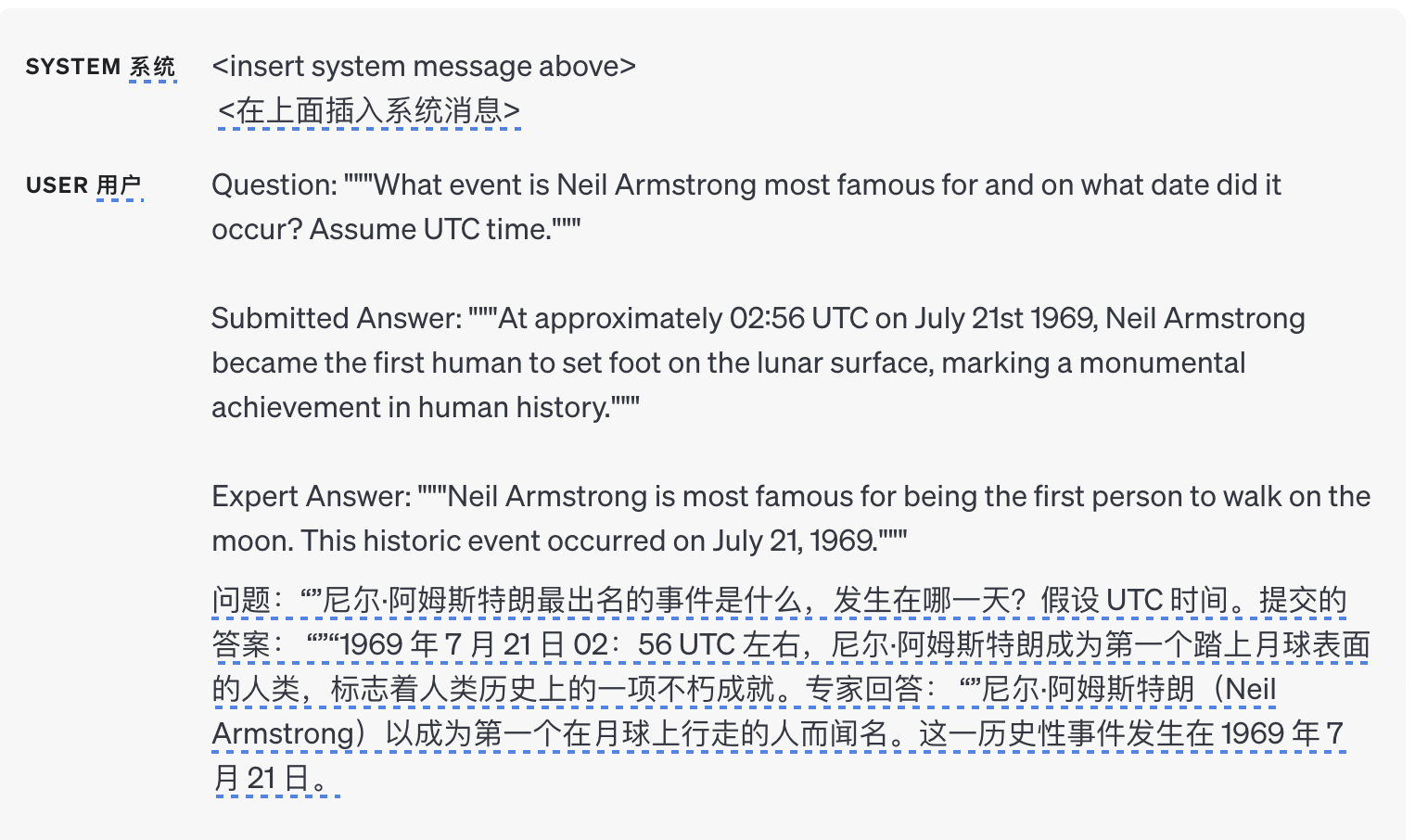
7 参考资料
open ai官方文档:https://platform.openai.com/docs/guides/prompt-engineering
7.1 关于高级提示词改进推理的论文
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022): Using few-shot prompts to ask models to think step by step improves their reasoning. PaLM's score on math word problems (GSM8K) rises from 18% to 57%.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models (2022): Taking votes from multiple outputs improves accuracy even more. Voting across 40 outputs raises PaLM's score on math word problems further, from 57% to 74%, and code-davinci-002's from 60% to 78%.
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models (2023): Searching over trees of step by step reasoning helps even more than voting over chains of thought. It lifts GPT-4's scores on creative writing and crosswords.
- Language Models are Zero-Shot Reasoners (2022): Telling instruction-following models to think step by step improves their reasoning. It lifts text-davinci-002's score on math word problems (GSM8K) from 13% to 41%.
- Large Language Models Are Human-Level Prompt Engineers (2023): Automated searching over possible prompts found a prompt that lifts scores on math word problems (GSM8K) to 43%, 2 percentage points above the human-written prompt in Language Models are Zero-Shot Reasoners.
- Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling (2023): Automated searching over possible chain-of-thought prompts improved ChatGPT's scores on a few benchmarks by 0–20 percentage points.
- Faithful Reasoning Using Large Language Models (2022): Reasoning can be improved by a system that combines: chains of thought generated by alternative selection and inference prompts, a halter model that chooses when to halt selection-inference loops, a value function to search over multiple reasoning paths, and sentence labels that help avoid hallucination.
- STaR: Bootstrapping Reasoning With Reasoning (2022): Chain of thought reasoning can be baked into models via fine-tuning. For tasks with an answer key, example chains of thoughts can be generated by language models.
- ReAct: Synergizing Reasoning and Acting in Language Models (2023): For tasks with tools or an environment, chain of thought works better if you prescriptively alternate between Reasoning steps (thinking about what to do) and Acting (getting information from a tool or environment).
- Reflexion: an autonomous agent with dynamic memory and self-reflection (2023): Retrying tasks with memory of prior failures improves subsequent performance.
- Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP (2023): Models augmented with knowledge via a "retrieve-then-read" can be improved with multi-hop chains of searches.
- Improving Factuality and Reasoning in Language Models through Multiagent Debate (2023): Generating debates between a few ChatGPT agents over a few rounds improves scores on various benchmarks. Math word problem scores rise from 77% to 85%.
7.2 视频课程
- Andrew Ng's DeepLearning.AI: A short course on prompt engineering for developers.
Andrew Ng 的 DeepLearning.AI:面向开发人员的提示工程短期课程。
- Andrej Karpathy's Let's build GPT: A detailed dive into the machine learning underlying GPT.Andrej Karpathy 的《让我们构建 GPT》:详细介绍 GPT 的机器学习基础。
- Prompt Engineering by DAIR.AI: A one-hour video on various prompt engineering techniques.
DAIR.AI的提示工程:一个小时的视频,介绍各种提示工程技术。
- Scrimba course about Assistants API: A 30-minute interactive course about the Assistants API.Scrimba 有关 Assistants API 的课程:关于 Assistants API 的 30 分钟互动课程。
- LinkedIn course: Introduction to Prompt Engineering: How to talk to the AIs: Short video introduction to prompt engineeringLinkedIn
课程:提示工程简介:如何与人工智能对话:提示工程简介视频短片
7.3 提示词指南
- Brex's Prompt Engineering Guide: Brex's introduction to language models and prompt engineering.
- learnprompting.org: An introductory course to prompt engineering.
- Lil'Log Prompt Engineering: An OpenAI researcher's review of the prompt engineering literature (as of March 2023).
- OpenAI Cookbook: Techniques to improve reliability: A slightly dated (Sep 2022) review of techniques for prompting language models.
- promptingguide.ai: A prompt engineering guide that demonstrates many techniques.
- Xavi Amatriain's Prompt Engineering 101 Introduction to Prompt Engineering and 202 Advanced Prompt Engineering: A basic but opinionated introduction to prompt engineering and a follow up collection with many advanced methods starting with CoT.
7.4 提示词库和工具
- Arthur Shield: A paid product for detecting toxicity, hallucination, prompt injection, etc.
- Chainlit: A Python library for making chatbot interfaces.
- Embedchain: A Python library for managing and syncing unstructured data with LLMs.
- FLAML (A Fast Library for Automated Machine Learning & Tuning): A Python library for automating selection of models, hyperparameters, and other tunable choices.
- Guardrails.ai: A Python library for validating outputs and retrying failures. Still in alpha, so expect sharp edges and bugs.
- Guidance: A handy looking Python library from Microsoft that uses Handlebars templating to interleave generation, prompting, and logical control.
- Haystack: Open-source LLM orchestration framework to build customizable, production-ready LLM applications in Python.
- HoneyHive: An enterprise platform to evaluate, debug, and monitor LLM apps.
- LangChain: A popular Python/JavaScript library for chaining sequences of language model prompts.
- LiteLLM: A minimal Python library for calling LLM APIs with a consistent format.
- LlamaIndex: A Python library for augmenting LLM apps with data.
- LMQL: A programming language for LLM interaction with support for typed prompting, control flow, constraints, and tools.
- OpenAI Evals: An open-source library for evaluating task performance of language models and prompts.
- Outlines: A Python library that provides a domain-specific language to simplify prompting and constrain generation.
- Parea AI: A platform for debugging, testing, and monitoring LLM apps.
- Portkey: A platform for observability, model management, evals, and security for LLM apps.
- Promptify: A small Python library for using language models to perform NLP tasks.
- PromptPerfect: A paid product for testing and improving prompts.
- Prompttools: Open-source Python tools for testing and evaluating models, vector DBs, and prompts.
- Scale Spellbook: A paid product for building, comparing, and shipping language model apps.
- Semantic Kernel: A Python/C#/Java library from Microsoft that supports prompt templating, function chaining, vectorized memory, and intelligent planning.
- Weights & Biases: A paid product for tracking model training and prompt engineering experiments.
- YiVal: An open-source GenAI-Ops tool for tuning and evaluating prompts, retrieval configurations, and model parameters using customizable datasets, evaluation methods, and evolution strategies.
8 小结
本文是对官方提示词工程的一个系统梳理,夹杂了不少官方给出的示例和翻译,目的并不是表达观点,而是作为一个留存,帮助自己和读者能快速了解官方对于提示词工程的一个说明。第7章给出了不少论文引用、参考视频和工具库,可想而知,提示词并不简单,他是一个技术活甚至是一个系统工程,希望这里的记录能带给读到文章的你一点帮助,下篇文章开启我自己的一些整理和观点。