目录
1. 深度学习机器学习的发展
1.1 核方法
1.2 几何学
1.3 特征工程 opencv
1.4 Hardware
2. AlexNet
3. 代码
1. 深度学习机器学习的发展
1.1 核方法
2001 Learning with Kernels 核方法 (机器学习)
特征提取、选择核函数来计算相似性、凸优化问题、漂亮的定理

1.2 几何学
2000 Multiple View Geometry in computer vision
抽取特征、描述集合、(非)凸优化、漂亮定理、如果假设满足了,效果非常好

1.3 特征工程 opencv
特征工程是关键、特征描述子:SIFT、SURF、视觉词袋(聚类)、最后用

1.4 Hardware
从上到下依次为样本大小、内存大小、CPU速度
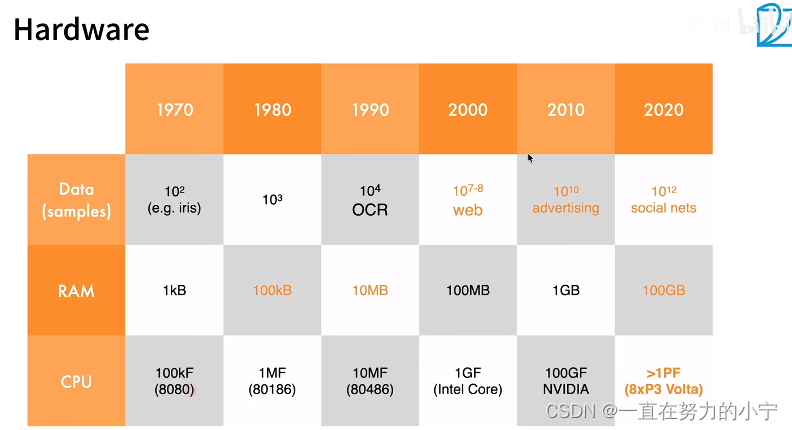
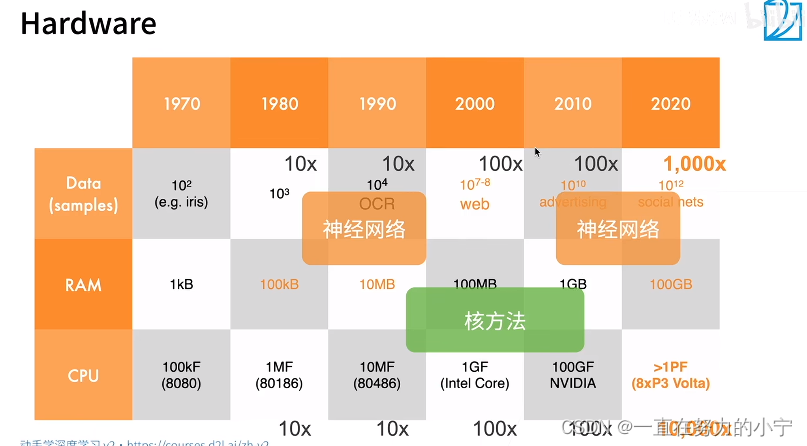
计算能力和算法能力在不同阶段的发展能力导致大家在选取上有偏好
1.5 ImageNet
2010 ImageNet 物体分类数据集:自然物体的彩色图片
2. AlexNet
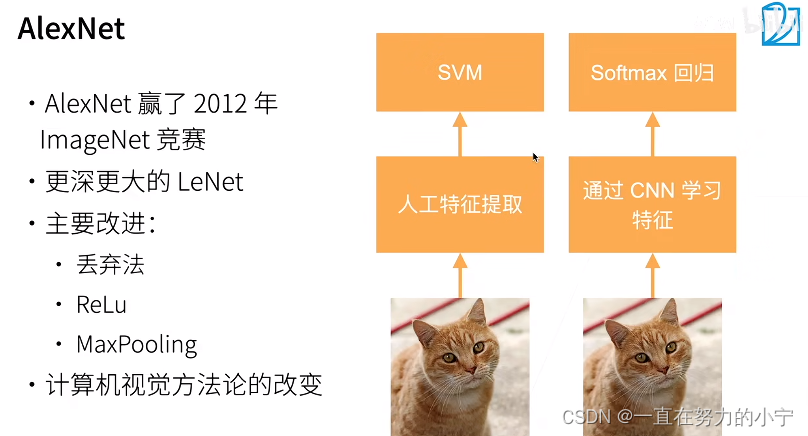
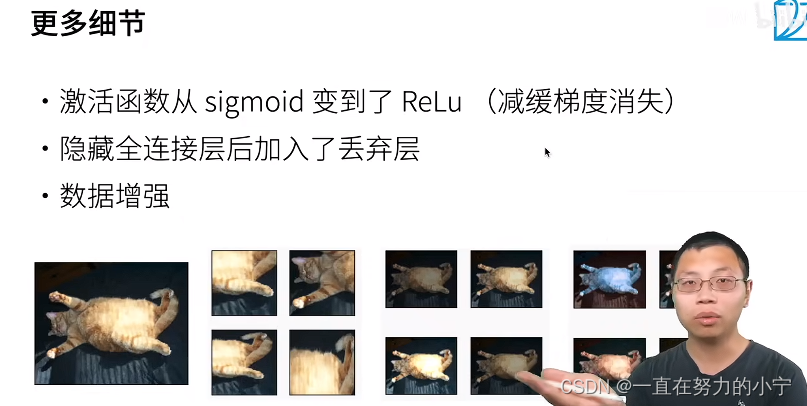
丢弃法、Relu、MaxPooling

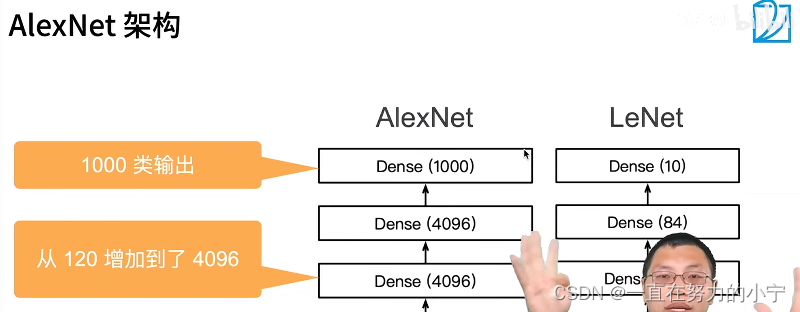

从LeNet(左)到AlexNet(右)
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
-
AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。【新加了3层卷积层;更多的输出通道;隐藏全连接层后新加了丢弃层】
-
AlexNet使用ReLU而不是sigmoid作为其激活函数。
-
更大的池化窗口、核窗口和步长;更多的输出通道。
3. 代码实现
3.1 模型设计
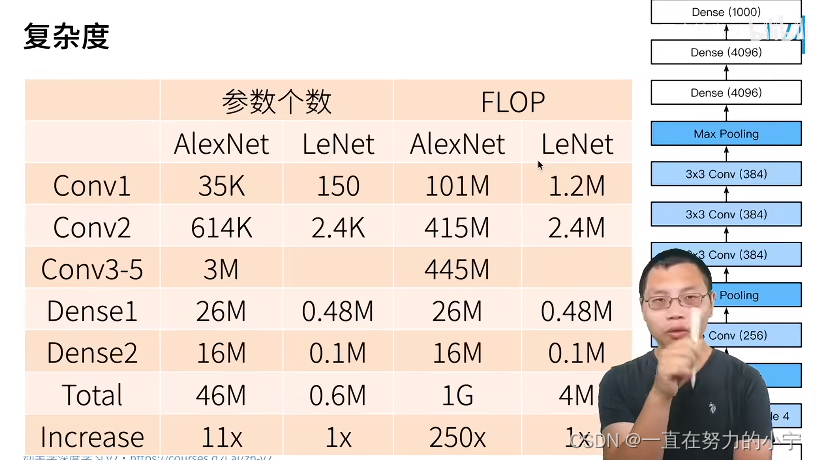
在AlexNet的第一层,卷积窗口的形状是11×11。 由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。 第二层中的卷积窗口形状被缩减为5×5,然后是3×3。 此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为3×3、步幅为2的最大汇聚层。 而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。 幸运的是,现在GPU显存相对充裕,所以现在很少需要跨GPU分解模型(因此,本书的AlexNet模型在这方面与原始论文稍有不同)。
3.2 激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
3.3 容量控制和预处理
AlexNet通过暂退法( 4.6节)控制全连接层的模型复杂度,而LeNet只使用了权重衰减。 为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))我们构造一个高度和宽度都为224的单通道数据,来观察每一层输出的形状。 它与 图7.1.2中的AlexNet架构相匹配。
X = torch.randn(1, 1, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)Conv2d output shape: torch.Size([1, 96, 54, 54]) ReLU output shape: torch.Size([1, 96, 54, 54]) MaxPool2d output shape: torch.Size([1, 96, 26, 26]) Conv2d output shape: torch.Size([1, 256, 26, 26]) ReLU output shape: torch.Size([1, 256, 26, 26]) MaxPool2d output shape: torch.Size([1, 256, 12, 12]) Conv2d output shape: torch.Size([1, 384, 12, 12]) ReLU output shape: torch.Size([1, 384, 12, 12]) Conv2d output shape: torch.Size([1, 384, 12, 12]) ReLU output shape: torch.Size([1, 384, 12, 12]) Conv2d output shape: torch.Size([1, 256, 12, 12]) ReLU output shape: torch.Size([1, 256, 12, 12]) MaxPool2d output shape: torch.Size([1, 256, 5, 5]) Flatten output shape: torch.Size([1, 6400]) Linear output shape: torch.Size([1, 4096]) ReLU output shape: torch.Size([1, 4096]) Dropout output shape: torch.Size([1, 4096]) Linear output shape: torch.Size([1, 4096]) ReLU output shape: torch.Size([1, 4096]) Dropout output shape: torch.Size([1, 4096]) Linear output shape: torch.Size([1, 10])
3.4 读取数据集
尽管原文中AlexNet是在ImageNet上进行训练的,但本书在这里使用的是Fashion-MNIST数据集。因为即使在现代GPU上,训练ImageNet模型,同时使其收敛可能需要数小时或数天的时间。 将AlexNet直接应用于Fashion-MNIST的一个问题是,Fashion-MNIST图像的分辨率(28×28像素)低于ImageNet图像。 为了解决这个问题,我们将它们增加到224×224(通常来讲这不是一个明智的做法,但在这里这样做是为了有效使用AlexNet架构)。 这里需要使用d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)3.5 训练AlexNet
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())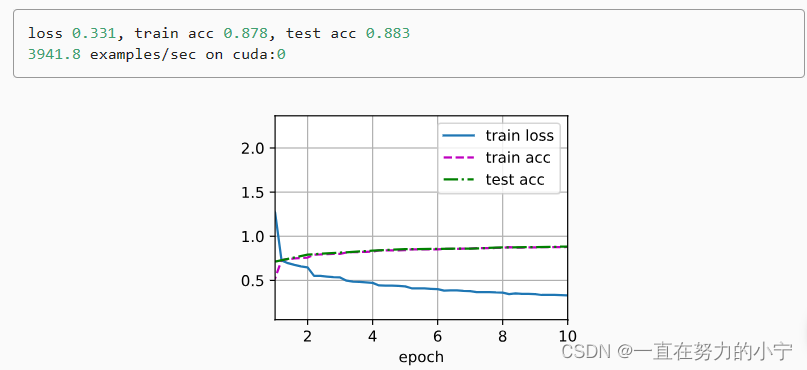
4. 小结
-
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
-
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
-
尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
-
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。












![[SAP] ABAP注释快捷键修改](https://img-blog.csdnimg.cn/direct/8c69d72b052a4d798ffc2d5a5307e5b3.png)