有需要互关的小伙伴,关注一下,有关必回关,争取今年认证早日拿到博客专家
Java高频面试之总纲篇
Java高频面试之集合篇
Java高频面试之异常篇
Java高频面试之并发篇
Java高频面试之SSM篇
Java高频面试之Mysql篇
Java高频面试之Redis篇
Java高频面试之消息队列与分布式篇
50道SQL面试题
奇奇怪怪的面试题
五花八门的内存溢出
请说下你对 MySQL 架构的了解?
mysql是一个c/s架构的数据库管理系统,
客户端可以是图形化界面,也可以是命令行或者java等程序
服务端由一下组成部分
- 连接管理器:管理连接,管理线程,验证身份,获取权限
- 缓存(sql字符串为key,查询结果为value)
- 解析器:解析sql,验证语法
- 优化器:优化sql,生成执行计划
可插拔的存储引擎
文件系统与日志
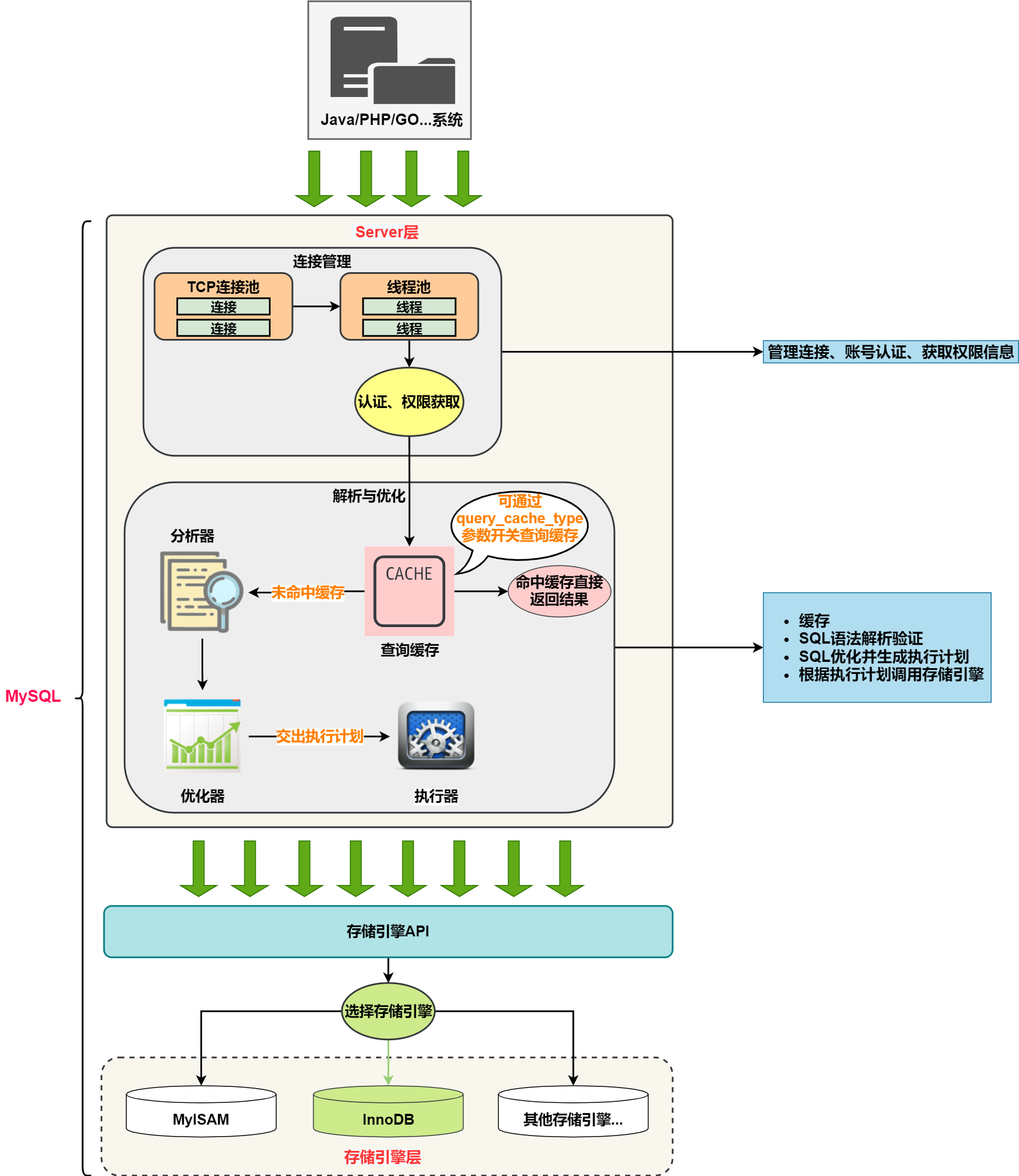
一条 SQL 语句在数据库框架中的执行流程?
- 查缓存
- 解析sql字符串(sql语句)
- 优化sql生成执行计划
- 存储引起执行计划
- 返回结果
数据库的三范式是什么?
目的:
1.降级冗余
-
第一范式:列不可再分
有一个学生表,假设有两个字段分别是 name,address,而address内容写的是:江苏省南京市浦口区xxx街道xxx小区。如果这时来一个需求,需要按省市区分类,显然不符需求,这样的表结构也不是符合第一范式的。
应该设计成 name,province(省),city(市),area(区),address -
第二范式:属性完全依赖与主键
每一行数据必须唯一区分(一对多的拆分成多个表减少数据冗余)
有一个订单表如下:
orderId(订单编号),roomId(房间号), name(联系人), phone(联系电话),idn(身份证)
如果这时候一个人同时订了好几个房间,就会变成一个订单编号对应多条数据,这样子联系人都是重复的,就会造成数据冗余,这时我们应该把拆分开来。
如:
订单表:
orderId(订单编号),roomId(房间号), peoId(联系人编号)
联系人表:
peoId(联系人编号),name(联系人), phone(联系电话),idn(身份证) -
第三范式:属性不依赖于其它非主属性 属性直接依赖于主键
简单点意思就是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余(不存在包含关系)。
假设有一个员工(employee)表,它有九个属性:
id(员工编号)、name(员工名称)、mobile(电话)、zip(邮编)、province(省份)、city(城市)、district(区县)、deptNo(所属部门编号)、deptName(所属部门名称)员工表的province、city、district依赖于zip
应该拆分为用户表和区域表
用户表:
id(员工编号)、name(员工名称)、mobile(电话)、deptNo(所属部门编号)、deptName(所属部门名称)区域表:
zip(邮编)、province(省份)、city(城市)、district(区县) 省市区依赖与邮编,邮编是主键
三范式存在的意义:尽可能的减少数据的冗余,三范式只是参考,实际可以适当的冗余
char 和 varchar 的区别?
结论
char:固定长度,不够会在末尾补空格,取出时删除所有末尾的空格,所以取出时会丢失末尾的空格,可能会浪费空间,查询效率比varchar高,单位字符,最多存255个字符,和字符集无关.
varchar:可变长度,存储实际字符串,不会浪费磁盘空间,查询效率比char慢,4.0前varchar(20)的单位为字节,5.0后为字符,最大存储的字符和存储引擎,字符集,当前行的其他列占用字节数有关.
-
固定长度 & 可变长度
CHAR类型用于存储固定长度字符串,比varchar类型查询效率更高.
VARCHAR类型用于存储可变长度字符串,它比固定长度类型更节省磁盘空间.
-
存储方式
char类型用空格进行剩余长度填充,取出时会丢失原字符串末尾的空格.
-- 建表语句 CREATE TABLE `str_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `str_char` char(10) DEFAULT NULL, `str_varchar` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4; -- 插入测试数据 INSERT INTO `str_table` (`id`, `str_char`, `str_varchar`) VALUES (null, '陈哈哈', '陈哈哈'), (null, ' 陈哈哈', ' 陈哈哈'), (null, '陈哈哈 ', '陈哈哈 ');-- 测试数据查询 select id,concat("|",str_char,"|") as `char`,concat("|",str_varchar,"|") as `varchar` from str_table; +----+---------------+---------------+ | id | char | varchar | +----+---------------+---------------+ | 6 | |陈哈哈| | |陈哈哈| | | 7 | | 陈哈哈| | | 陈哈哈| | | 8 | |陈哈哈| | |陈哈哈 | | +----+---------------+---------------+ 3 rows in set (0.00 sec) -- 结论:char会丢失字符串末尾的空格(猜测:存的时候在末尾补空格,取的时候删除了所有末尾的空格)varchar类型需要额外存储1到2个字节的实际长度,长度小于等于255(28)时,占1字节;小于65535时(216),占2字节
-
存储容量
对于char类型来说,最多只能存放的字符个数为255,和编码无关,任何编码最大容量都是255。
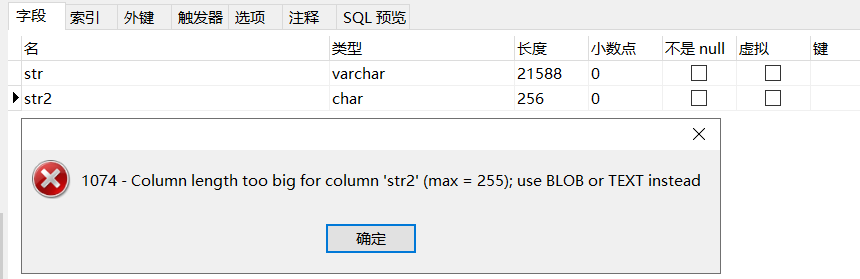
MySQL
行默认最大65535字节,是所有列共享(相加)的,所以VARCHAR的最大值受此限制。表中只有
单列字段情况下,varchar一般最多能存放(65535 - 3)个字节为什么是65532个字符?算法如下(有余数时向下取整):
最大长度(字符数) = (行存储最大字节数 - NULL标识列占用字节数 - 长度标识字节数) / 字符集单字符最大字节数NULL标识列占用字节数:允许NULL时,占一字节长度标识字节数:记录长度的标识,长度小于等于255(28)时,占1字节;小于65535时(216),占2字节- 4.0版本及以下,MySQL中varchar长度是按
字节展示,如varchar(20),指的是20字节; - 5.0版本及以上,MySQL中varchar长度是按
字符展示。如varchar(20),指的是20字符。
以下为mysql5.7,存储引擎innodb,utf8字符集
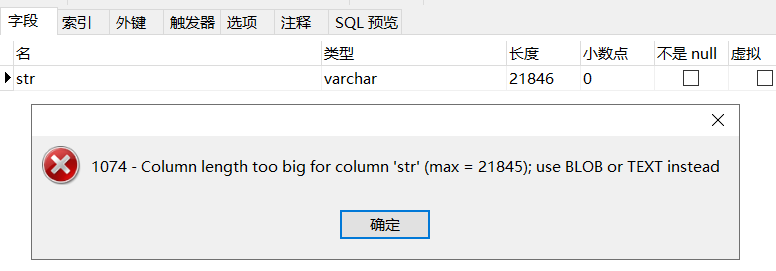
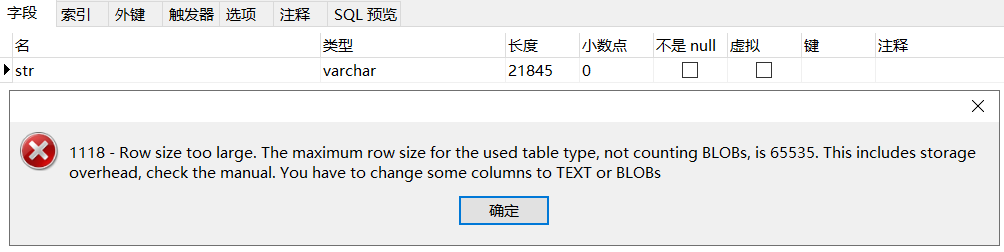

(65535-3)/3=21844
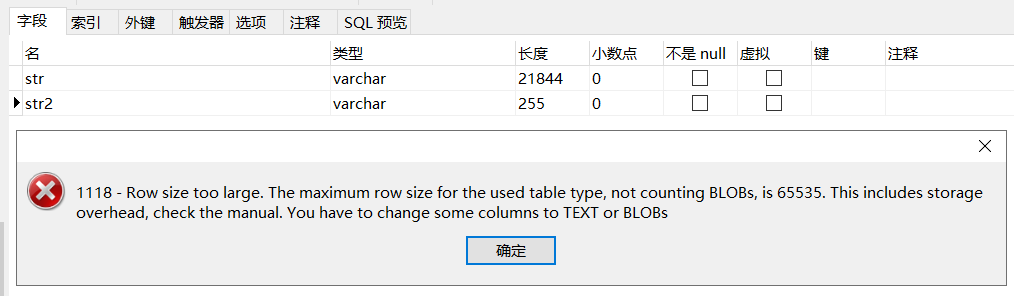
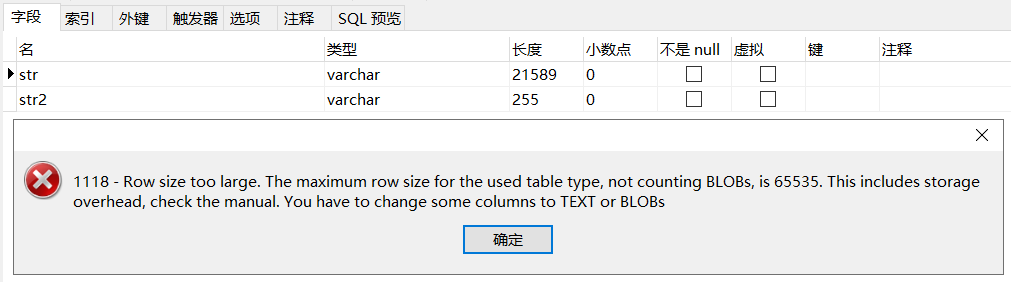
21844-255=21589

因为255也要占用额外的空间存储长度和null标识,实际需要255*3+长度+null标识
既然VARCHAR长度可变,那我要不要定到最大?
就像使用VARCHAR(5)和VARCHAR(200)存储 '陈哈哈’的磁盘空间开销是一样的。那么使用更短的列有什么优势呢?
事实证明有很大的优势。更长的列会消耗更多的内存,因为MySQL通常会分配固定大小的内存块来保存内部值。当然,在没拿到存储引擎存储的数据之前,并不会知道我这一行拿出来的数据到底有多长,可能长度只有1,可能长度是500,那怎么办呢?那就只能先把最大空间分配好了,避免放不下的问题发生,这样实际上对于真实数据较短的varchar确实会造成空间的浪费。
举例:我向数据类型为:varchar(1000)的列插入了1024行数据,但是每个只存一个字符,那么这1024行真实数据量其实只有1K,但是我却需要约1M的内存去适应他。所以最好的策略是只分配真正需要的空间。
————————————————
版权声明:本文为CSDN博主「_陈哈哈」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39390545/article/details/109379218
varchar(10) 和 varchar(20) 的区别?
因为varchar是可变字符串,所以实际存储是一样的,但是在没有从存储引擎拿到数据前,不知道给varchar分配多大的内存,所以会根据定于的长度先分配,所以varchar(20) 可能比varchar(10)占用更多的内存空间
谈谈你对索引的理解?
-
是什么
索引是为了高效获取数据的一种数据结构(排好序的可以快速查找的数据结构)
-
优点与缺点
可以提高查询的速度,会降低更新的速度,索引本身也要占用一定的存储空间,所以所以并不是越多越好
-
索引的分类
按数据结构:B+tree索引、Hash索引、Full-text索引。
按物理存储:聚簇索引、二级索引(辅助索引)。
按字段特性:主键索引、唯一索引、普通索引、前缀索引。
按字段个数:单列索引、联合索引(复合索引、组合索引)。 -
哪些情况需要创建索引
频繁作为查询条件的字段(where 后面的语句)
连表字段
排序字段
分组字段
统计字段
-
哪些情况不要创建索引
数据量太少的表
经常增删改的表
区分度不高的字段(例如性别男和女)
-
详细见
mysql索引失效场景
索引的底层使用的是什么数据结构?
B+树
谈谈你对 B+ 树的理解?
为什么 InnoDB 存储引擎选用 B+ 树而不是 B 树呢?
B树一个节点存储的数据较少,要存储更多的数据,只能增加树的深度,也就增加了IO的次数
谈谈你对聚簇索引的理解?
- 聚族索引与数据存在一个文件中
- 聚族索引决定了数据行在磁盘上的顺序
- 根据聚族索引查效率高(不需要回表)
- 修改聚族索引可能导致磁盘上数据行的变动,开销问题
- mysql中如果没有主键,会生成一个rowId,用rowId作为聚族索引
谈谈你对哈希索引的理解?
谈谈你对覆盖索引的认识?
覆盖索引 是一种特殊类型的索引,它包含了查询所需的所有列(select 后面的和 where 后面的),因此可以完全覆盖查询的需求,无需回到原始数据页进行查找。这种索引可以提供更高效的查询性能,减少了磁盘I/O和数据访问的成本。
索引的分类?
谈谈你对最左前缀原则的理解?
怎么知道创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?
什么情况下索引会失效?
查询性能的优化方法?
-
索引优化
建立适当的索引
-
查询语句优化:
避免使用SELECT *,而是只选择需要的列。
使用JOIN语句代替子查询
尽量避免在WHERE子句中使用函数或表达式。
合理使用LIMIT进行分页查询。
-
数据库设计优化:
合理划分表,避免过大的表。
使用适当的数据类型和字段长度,减少存储空间的占用。
规范化和反规范化的选择要基于实际查询需求。
-
优化服务器参数:
增加缓冲区大小(如innodb_buffer_pool_size),提高查询的缓存命中率。
调整连接数(如max_connections)以适应并发查询需求。
合理设置日志和复制等功能,避免对性能造成过大的影响。
-
查询缓存优化:
MySQL的查询缓存可以缓存查询结果,但在高并发环境下可能带来性能问题。检查并适当调整查询缓存的配置,以避免频繁的缓存失效和更新。
-
数据分区和分表:对于大型表,可以考虑使用数据分区和分表技术。将数据划分为多个分区,可以提高查询的效率。使用分表将数据分散到多个表中,可以减少单个表的数据量,提高查询性能。
-
分库
-
数据库统计信息优化:MySQL提供了统计信息收集功能,通过收集和分析表和索引的统计信息,优化查询执行计划。定期更新统计信息,以确保优化器可以做出最佳的查询计划选择。
InnoDB 和 MyISAM 的比较?
| InnoDB | MyISAM | |
|---|---|---|
| 事物 | 支持 | 不支持 |
| 行锁 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 自动崩溃恢复 | 支持 | 不支持 |
| 存储方式 | 聚族索引与数据存一起(.frm和.ibd) | 索引和数据分开存*.frm,.MYD和.MYI |
|---|---|---|
https://www.runoob.com/w3cnote/mysql-different-nnodb-myisam.html
谈谈你对水平切分和垂直切分的理解?
主从复制中涉及到哪三个线程?
- 主数据库线程:负责生成二进制日志
- I/O线程:从数据库线程,负责与主数据库通信,将二进制日志传输到从库
- SQL线程:从数据库线程,负责运行二进制日志
主从同步的延迟原因及解决办法?
延迟原因:
- 大事务
- 从库所在服务器性能比主库差(主库生成二进制日志文件是顺序写,效率高,从库执行二进制文件是随机写,效率低)
- 主库上挂的从库太多
解决方案:
谈谈你对数据库读写分离的理解?
数据库读写分离是一种数据库架构模式,通过将读操作和写操作分离到不同的数据库实例或服务器上,以提高数据库的性能和可伸缩性。在数据库读写分离模式下,主数据库负责处理写操作(INSERT、UPDATE、DELETE),而从数据库负责处理读操作(SELECT)。
主要优势:
-
提高数据库系统的整体性能
读写分离,读可以水平扩展
-
提高数据库系统的可用写
主库发生故障时切换到从库
请你描述下事务的特性?
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):多个并发执行的事务之间相互隔离,每个事务的执行都应该与其他事务相互独立,互不干扰。通过锁+。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。(即使在系统崩溃或断电的情况下,数据的修改仍然是可恢复的)
4大特性可以分为两部分:原子性(undo log)、一致性(undo log)、持久化(redo log),实际上是由InnoDB中的两份日志来保证的,一份是redo log日志,一份是undo log日志。 而隔离性是通过数据库的锁,加上MVCC来保证的(当前读是锁,快照读是MVCC)。
谈谈你对事务隔离级别的理解?
-
读未提交
-
读已提交(每次读取都生成一个读视图,会有幻读问题)
-
可重复读(默认级别 在mysql中不存在幻读 在开启事务时生成读视图,在当前事务里面复用第一次生成的读视图)
-
串行化(读写锁)
mysql InnoDB 默认隔离界别不会出现幻读演示
开启会话1->会话1读取->开启会话2->会话2插入一条数据->提交会话2->会话1读取(结果在会话2提交前后会话1读取到的是一致的)
会话1
mysql# begin; Query OK, 0 rows affected (0.00 sec) mysql# select * from t1; +----+---------+ | id | content | +----+---------+ | 1 | t1_926 | +----+---------+ 1 row in set (0.00 sec) # 等待会话2提交事物,然后查询 mysql# select * from t1; +----+---------+ | id | content | +----+---------+ | 1 | t1_926 | +----+---------+ 1 row in set (0.00 sec)会话2
mysql# begin; Query OK, 0 rows affected (0.00 sec) mysql# select * from t1; +----+---------+ | id | content | +----+---------+ | 1 | t1_926 | +----+---------+ 1 row in set (0.00 sec) mysql# insert into t1(content)values('xxx'); Query OK, 1 row affected (0.00 sec) mysql# select * from t1; +----+---------+ | id | content | +----+---------+ | 1 | t1_926 | | 2 | xxx | +----+---------+ 2 rows in set (0.00 sec) mysql# commit; Query OK, 0 rows affected (0.01 sec) mysql#
解释下什么叫脏读、不可重复读和幻读?
脏读:读其他事务未提交的数据(如果其他事务回滚数据就错误了)
不可重复读:在一个事务里面,两次读取到的数据列不一致(另一个事务修改了数据行,并且已经提交了)
幻读:在一个事务里面,两次读取到的行不一致(另一个事务新增或删除了数据,并且已经提交)
MySQL 默认的隔离级别是什么?
可重复读,但是在InnoDB中此隔离级别不存在幻读问题
谈谈你对 MVCC 的了解?
MVCC(Multi-Version Concurrency Control)。它通过在事务中使用不同的版本来实现并发读写操作,从而提供了更好的并发性和隔离性。
基本原理(数据行隐藏字段+undo log版本链+读视图)
- 每个事务在开始时都会创建一个唯一的事务ID。
- 每个数据行都会维护多个版本。
- 对于读操作,事务只能看到在它开始之前已经提交的版本。。
- 对于写操作,事务会创建新的版本,并将回滚指针指向上一个本本。
- 当事务提交时,它所做的修改会变为其他事务可见的新版本。
MVCC的优点包括:
- 高并发性:不同事务可以并行地读取和写入不同版本的数据,减少了事务之间的冲突和锁竞争,提高了并发性能。
- 高隔离性:每个事务读取的是一致性的数据版本,不会受到其他事务的修改影响,提供了更好的隔离性。
- 无锁读:读操作不会阻塞其他事务的写操作,避免了读写冲突,提高了并发性能。
说一下 MySQL 的行锁和表锁
InnoDB 存储引擎的锁的算法有哪些?
表锁
行锁
间隙锁
临键锁:(]
元数据锁:只要有活动事务(即便是select),就不能修改表结构
意向锁:解决的是行锁与表锁的冲突(加表锁(共享与排他)是要判断有没有行锁,兼不兼容,逐行判断太效率低)
意向共享锁(IS): 由语句select … lock in share mode添加 。 与 表锁共享锁(read)兼容,与表锁排他锁(write)互斥。
意向排他锁(IX): 由insert、update、delete、select…for update添加 。与表锁共享锁(read)及排他锁(write)都互斥,意向锁之间不会互斥。
一旦事务提交了,意向共享锁、意向排他锁,都会自动释放。
MySQL 问题排查都有哪些手段?
- 重现问题:如果能够重现问题,可以通过创建测试环境并重现问题来进一步分析和调试。这可能需要使用适当的测试数据和配置,并且可能需要模拟特定的负载。
- 索引和查询优化:针对具体的查询问题,可以通过添加或修改索引、优化查询语句、调整数据库参数等手段来改善查询性能。
- 日志分析:MySQL提供了多种类型的日志记录,如错误日志、查询日志、慢查询日志等。通过分析这些日志可以找出可能的问题原因。错误日志可以查看是否有任何错误发生,查询日志可以用来检查具体的查询语句,慢查询日志可以用来找出执行时间超过某个阈值的查询。
- 性能分析:使用 MySQL 的性能分析工具,如 EXPLAIN、SHOW PROFILES、SHOW STATUS、SHOW PROCESSLIST 等,可以获得关于查询执行计划、查询性能指标、当前正在执行的查询等方面的信息。这些信息可以帮助确定性能瓶颈的位置。
- 监控工具:使用监控工具可以实时监测 MySQL 数据库的各种指标,如 CPU 使用率、内存使用率、磁盘 I/O、网络流量等。这些指标可以提供有关数据库负载、性能问题和资源利用情况的宝贵信息。
- 硬件和操作系统层面的排查:如果性能问题不仅限于 MySQL,还可能涉及硬件或操作系统层面的问题。因此,排查硬件故障、资源限制、操作系统配置等问题也是很重要的。
MySQL 数据库 CPU 飙升到 500% 的话他怎么处理?
- 检查当前活动的查询:使用 SHOW PROCESSLIST 命令查看当前正在执行的查询。确定是否有某个查询导致了 CPU 飙升。如果有,可以进一步分析该查询的执行计划、索引使用情况等,优化查询语句或添加适当的索引。
- 慢查询分析:通过启用慢查询日志或使用性能分析工具(如 Percona Toolkit 或 pt-query-digest)来分析慢查询。慢查询可能导致 CPU 使用率过高。通过识别并优化慢查询可以减少负载。
- 分析索引使用情况:检查表的索引是否正确使用。缺乏或错误使用索引可能导致全表扫描,增加 CPU 负载。通过优化索引,可以提高查询性能并降低 CPU 使用率。
- 调整数据库参数:检查 MySQL 的配置参数,如缓冲区大小、并发连接数等,根据系统资源和负载情况进行调整。适当增加缓冲区大小、调整线程池和连接池配置等,可以提高数据库的性能。
- 看看有没有必要主从或分库
- 看看有没有必要加缓存层
Java高频面试之总纲篇
Java高频面试之集合篇
Java高频面试之异常篇
Java高频面试之并发篇
Java高频面试之SSM篇
Java高频面试之Mysql篇
Java高频面试之Redis篇
Java高频面试之消息队列与分布式篇
50道SQL面试题
奇奇怪怪的面试题
五花八门的内存溢出