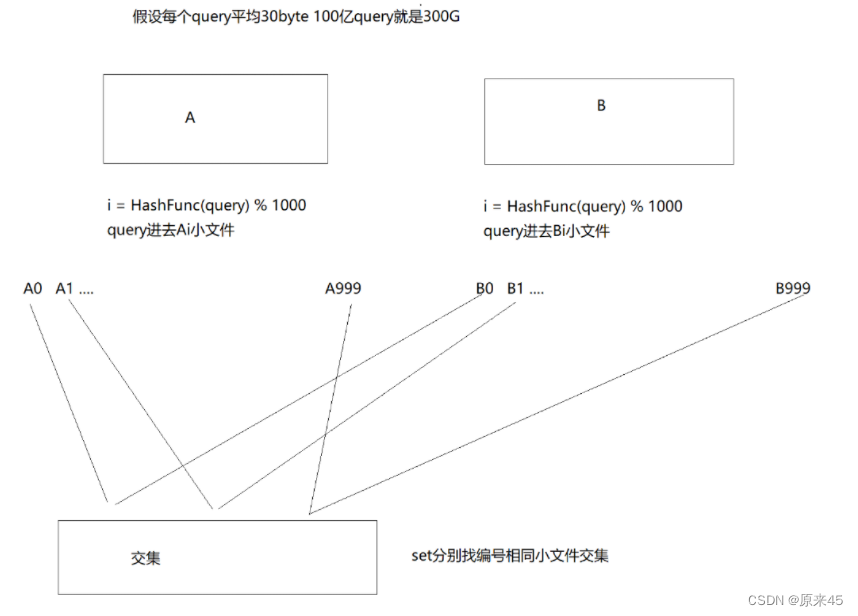
目录:
(1)初始ES-安装IK分词器
(2)IK分词器的拓展和停用词典
(3)操作索引库-mapping属性
(4)操作索引库-创建索引库
(5)操作索引库-查询-删除-修改索引库
(6)文档操作-新增-查询-删除文档
(7)文档操作-修改文档
(1)初始ES-安装IK分词器
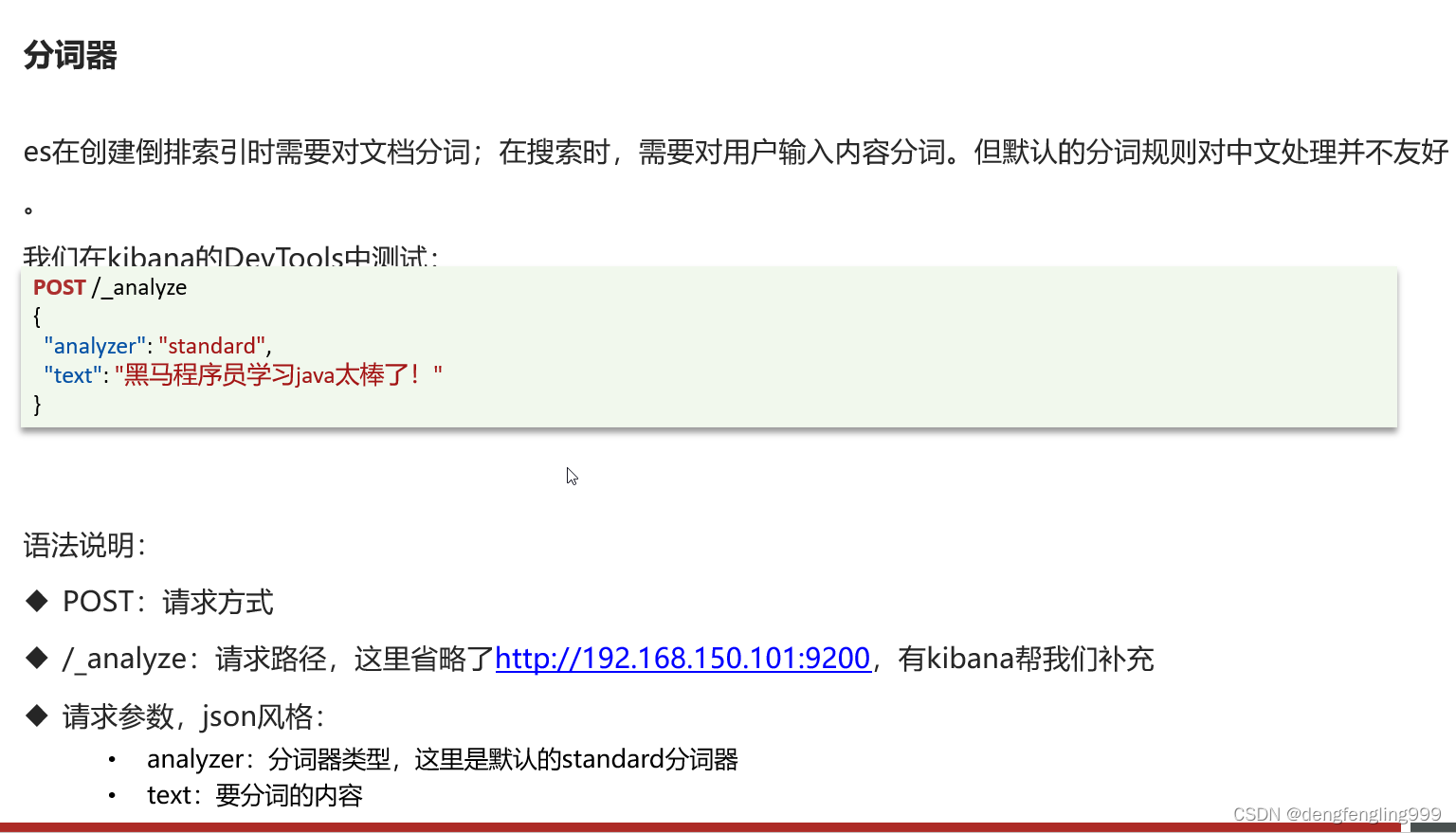
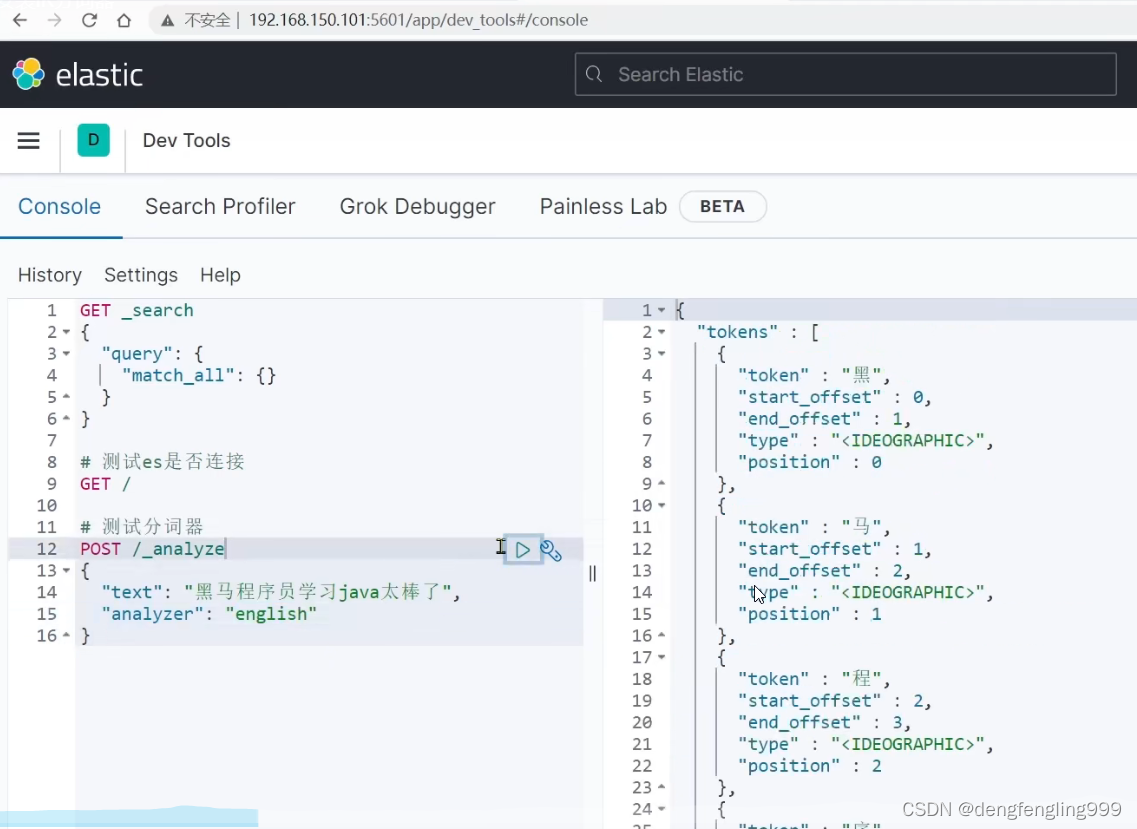 发现以英语进行分词可以,中文是一个一个的进行分词
发现以英语进行分词可以,中文是一个一个的进行分词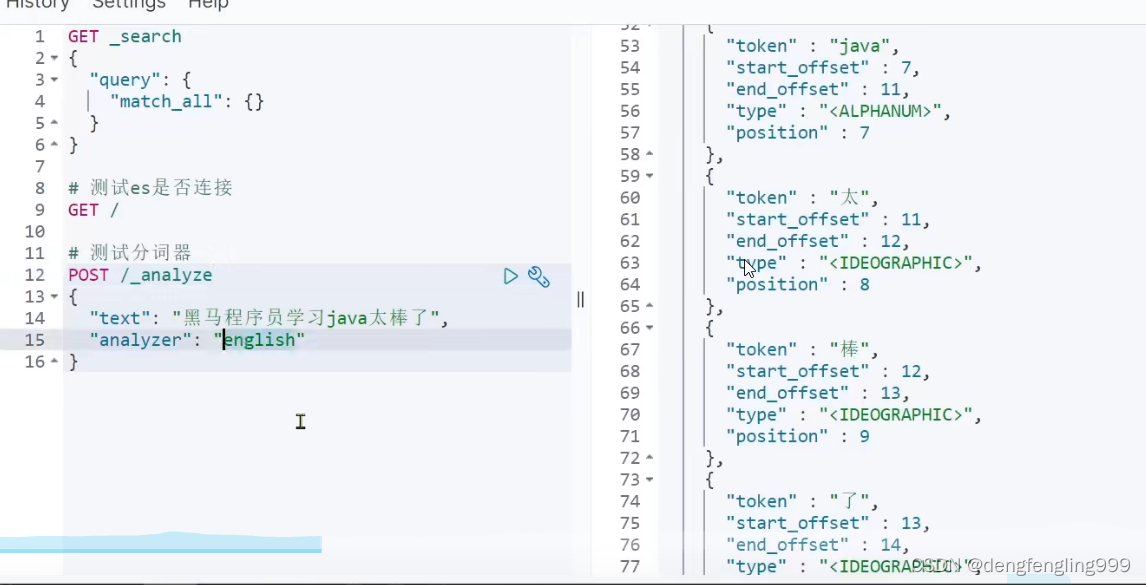
换中文进行分词:还是一字一字的分,它没有办法去理解中文含义按内容分

标准分词:也是一样:

要想去分词中文就不能使用默认的分词器了, 我们需要它按词进行分 ,需要使用:


上次ES安装的定义的目录



查看数据卷的目录:

 把解压的文件上传
把解压的文件上传

重启容器:
它包含两种模式:先使用ik_smart:分词成功了:它分的粒度大,分词少
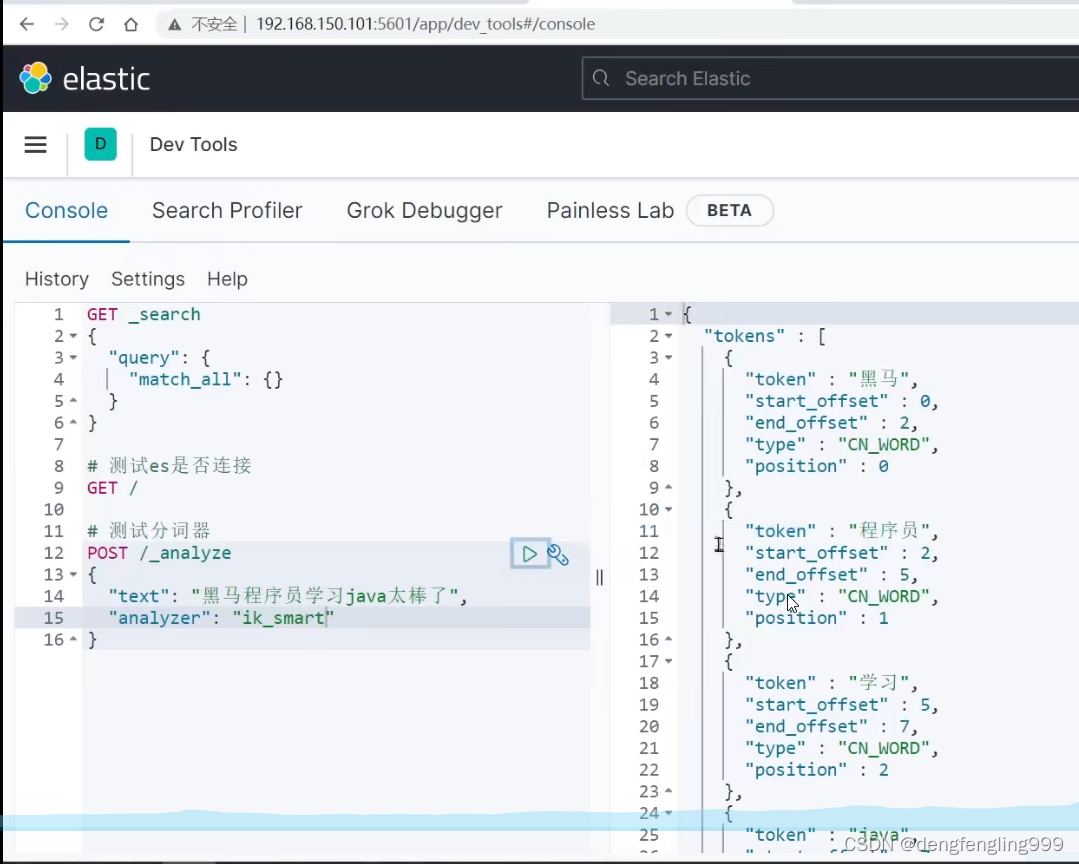
使用ik_max_word:进行分词 :它分的词语比ik_smart:分的词语更多


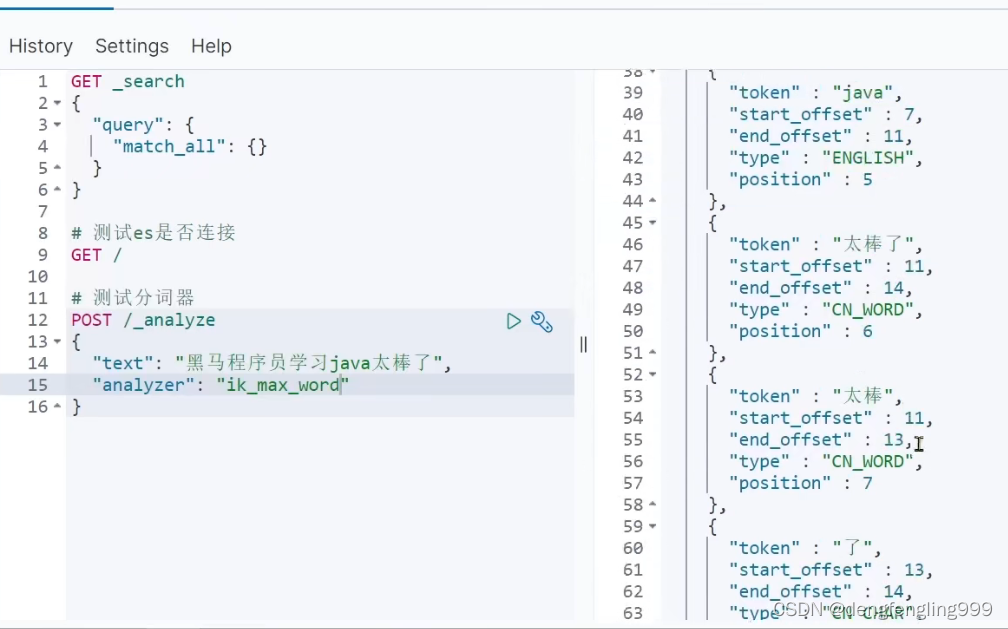
使用ik_smart分词少,被搜索到的概率比较低,它的好处是分的次少了,占用的内存空间就少了,将来我的内存中可以缓存更多的数据查询效率高
ik_max_word:分词较多,占用的内存空间较多,这是它的缺点
所以需要在内存占用搜索效率,被搜索到的概率之间做出选择
(2)IK分词器的拓展和停用词典
分词的底层一定有各种各样的字典,字典里面有各种各样的词语,当它分词的时候拿这些字去匹配,里面有没有这个词,证明它是一个词,字典中并不是包含所有的词语,比如流程的词语就没有
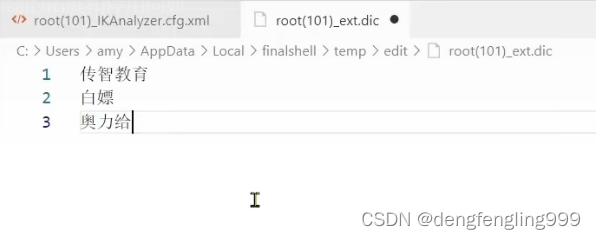
下面的搜索里面没有的词:传智教育、白嫖、奥利给等,进行了一个一个的分
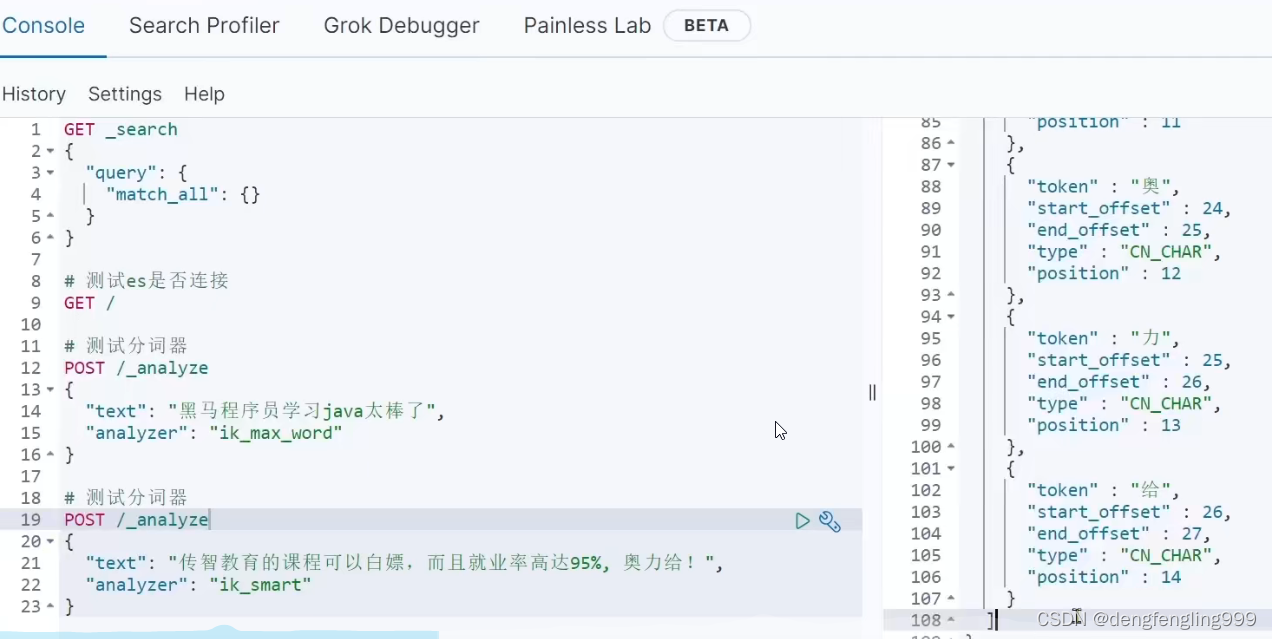
怎么去字典拓展拓展,还有象’的’这样的词,没有意义不要它分词,还有一些敏感词汇,不要它出现,把它禁掉,那么我们分词器,能否实现字典的个性化设置?
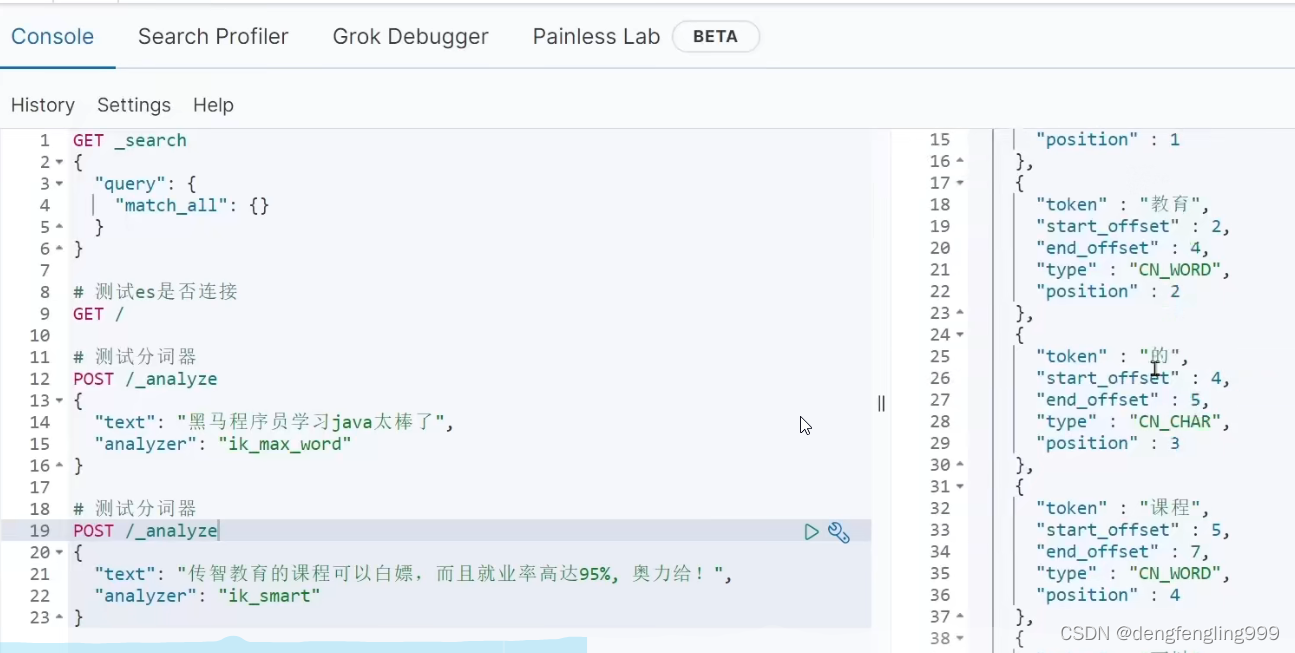
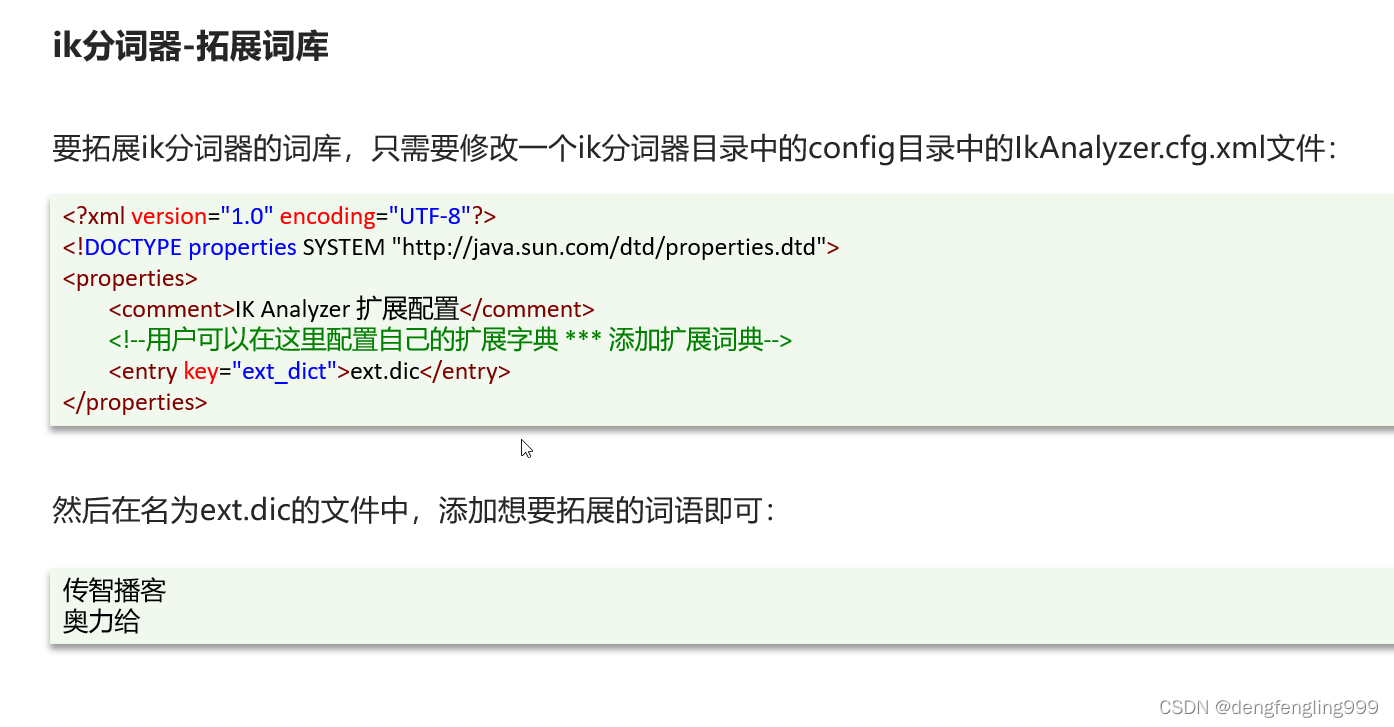
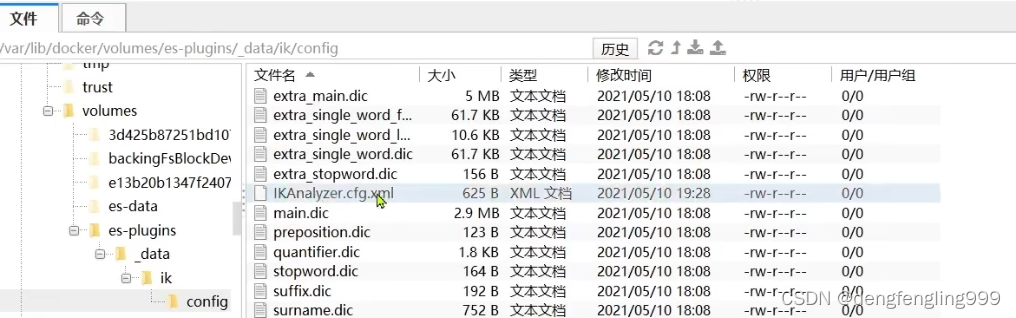

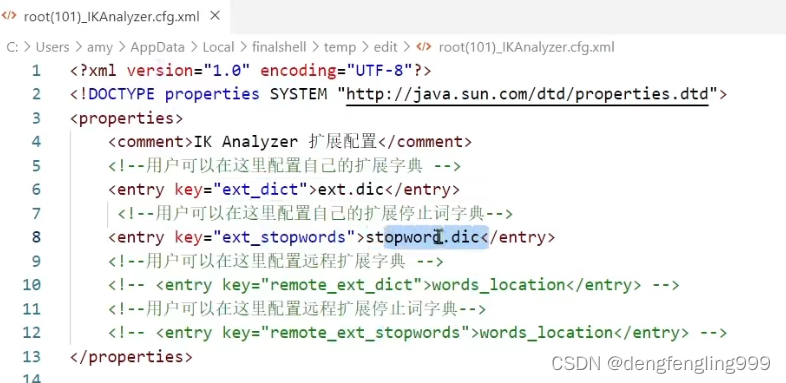
这两个是文件名,然后再这个目录下创建ext.dic文件

扩展词汇:
禁用词汇: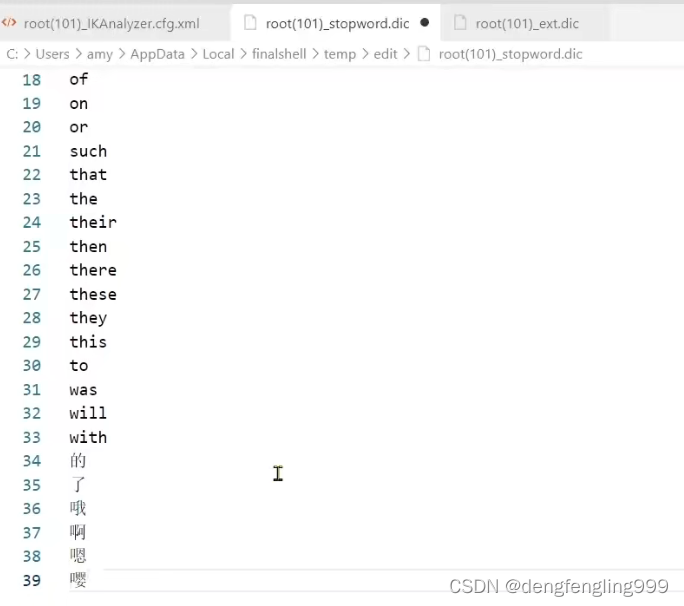

重启一下ES:

重新在测试一下:出现了白嫖,传智教育,的这个词也没有显示
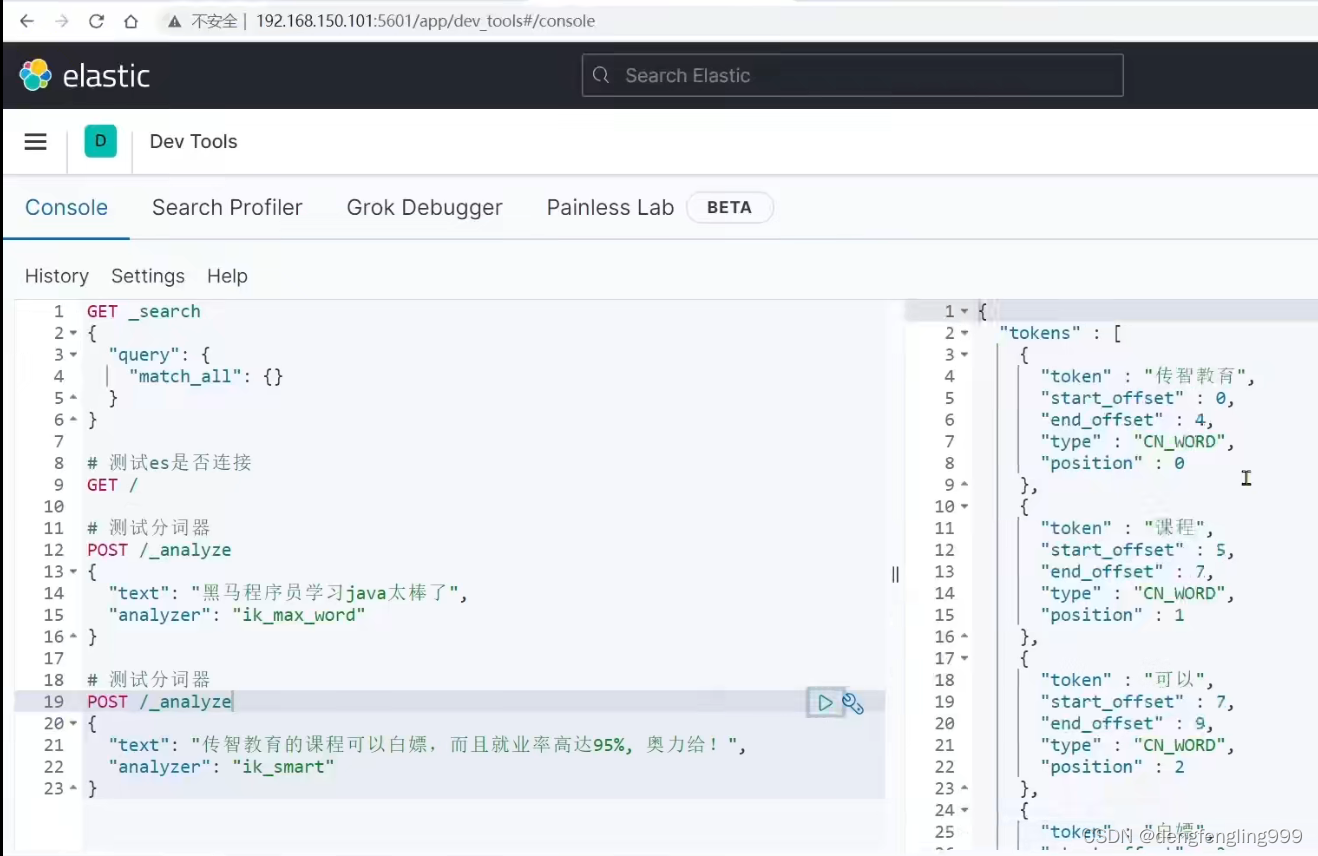
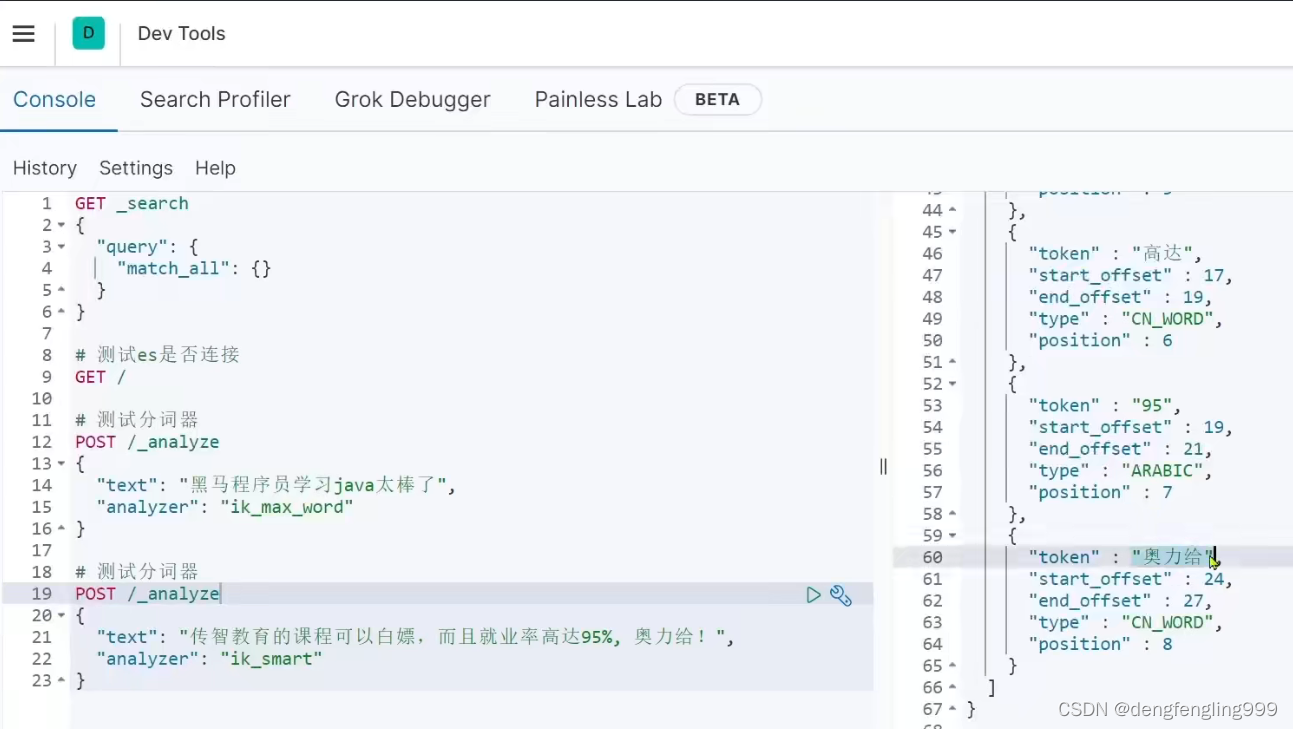
分词器分词是在:第一个给文档创建索引的时候,对文档个中的某个内容进行分词,给词条创建倒排索引
第二个是用户在搜索的时候进行分词,对用户输入的内容进行分词
(3)操作索引库-mapping属性
索引库就相当于表,索引库里面有文档,相当于数据库里面的一行一行的数据,数据库先创建表才能添加数据,ES里面也一样,先有索引库,才能往里面添加文档。创建一个个索引库,就想建表一样,如果想创建一个索引库,需要指定mapping映射,mapping是对文档的约束
先学习索引库的操作:

可以去官方查看mapping的常用属性
这里我们看几个常用的mapping属性
type:看一下这个字段需要不需要拆,需要拆的话用text,不需要拆的话用keyword
index:创建索引,默认是true 创建索引是字面意思,要不要创建倒排索引 ,然后就可以搜索了,没有倒排索引就没有办法搜索这个字段 在实际的开发过程中并不是所有的字段需要搜索,
不需要搜索的字段,把这个值设置为false
(4)操作索引库-创建索引库

创建索引库:案例:
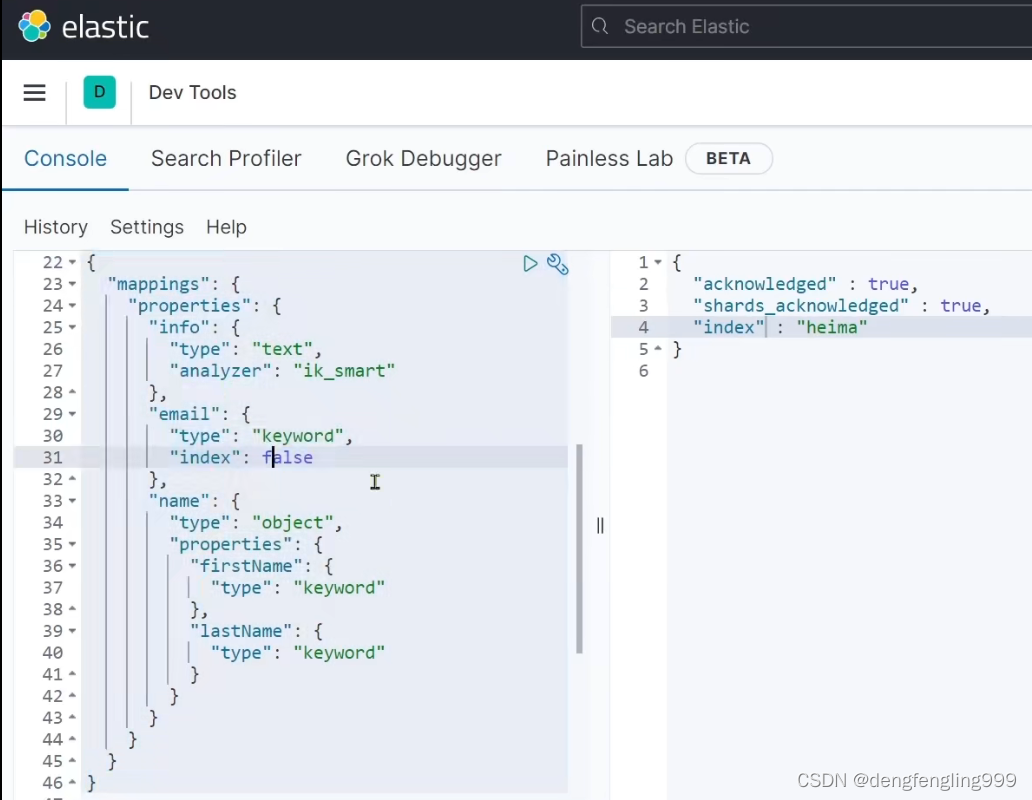
(5)操作索引库-查询-删除-修改索引库
ES一般是不允许修改索引库的,如果你要去修改一个字段的话,就会导致我们原有的倒排索引失效,但是可以修改库添加新的字段

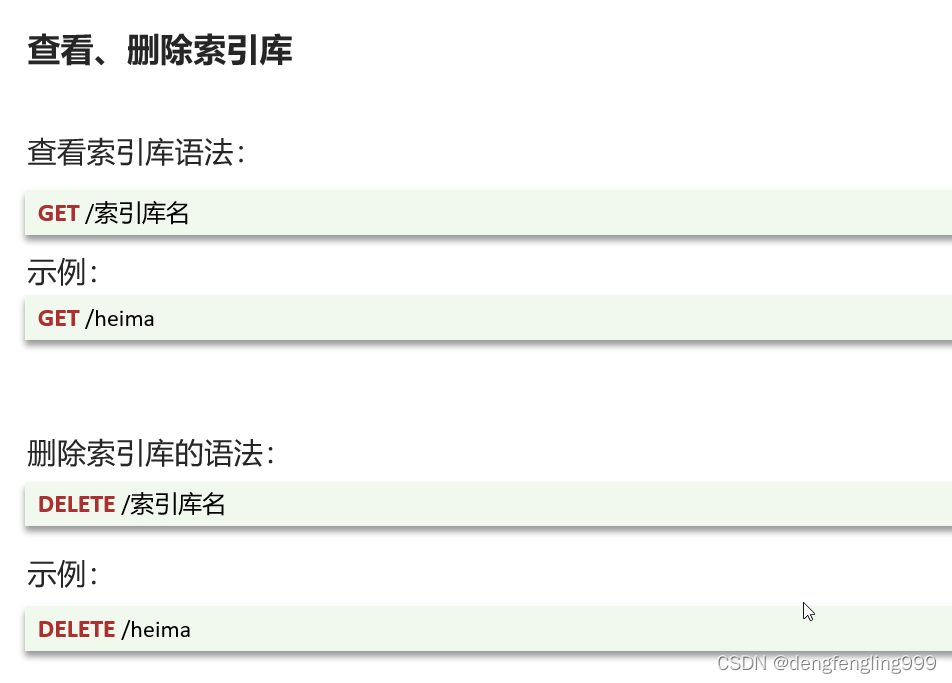
查看索引库:
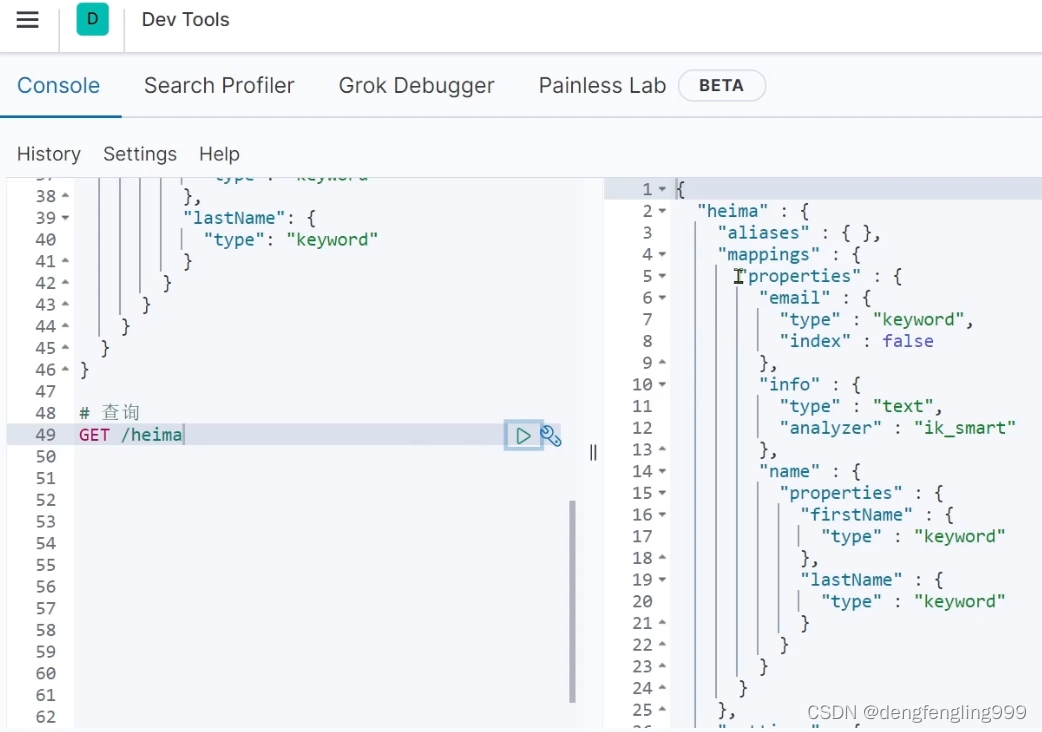
添加新字段:
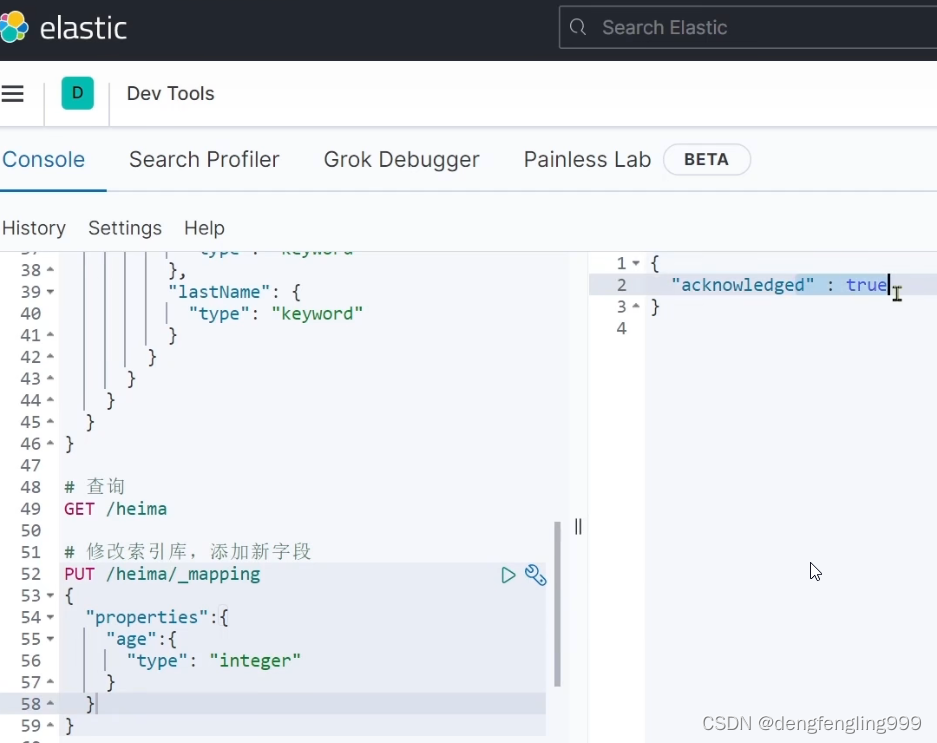
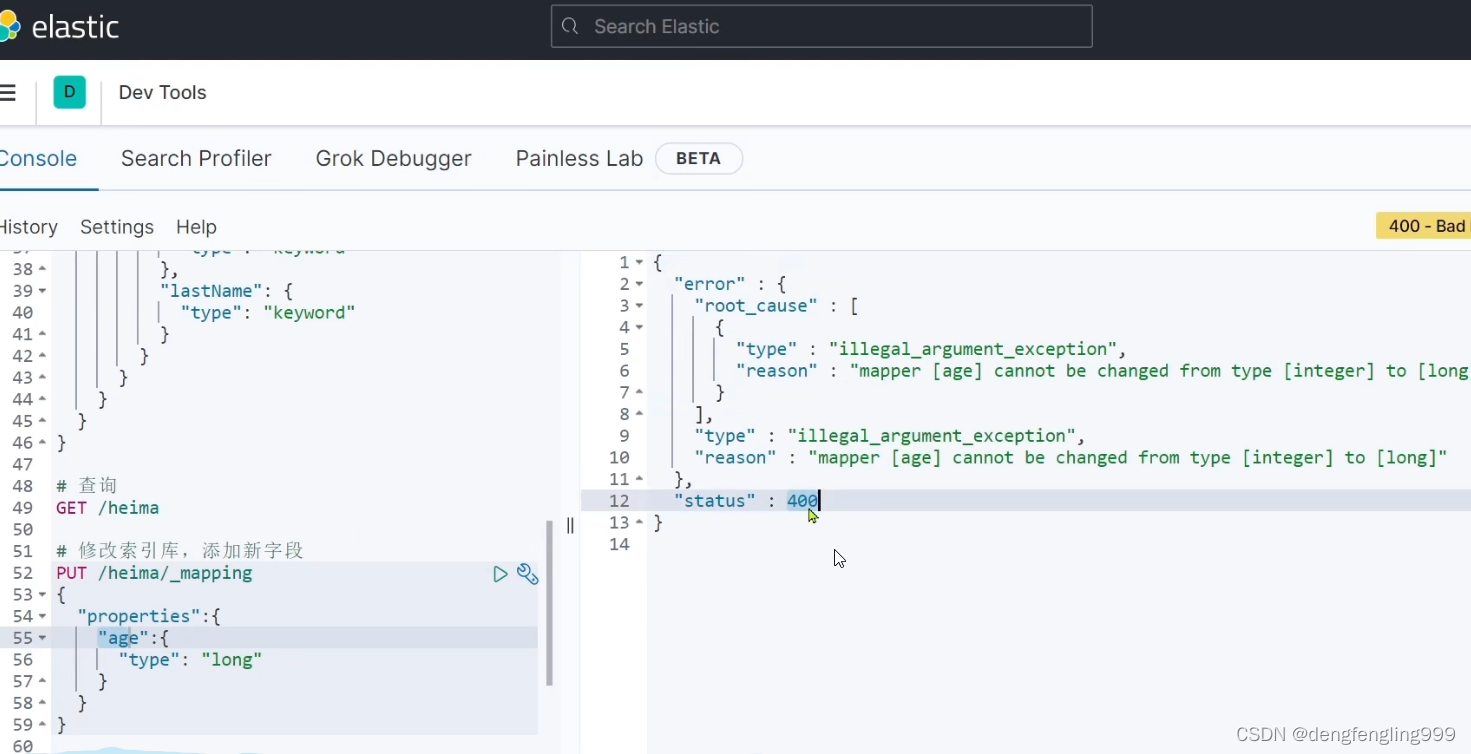
查询一下:成功添加: 如果你想修改这个字段,就会报错:
如果你想修改这个字段,就会报错:
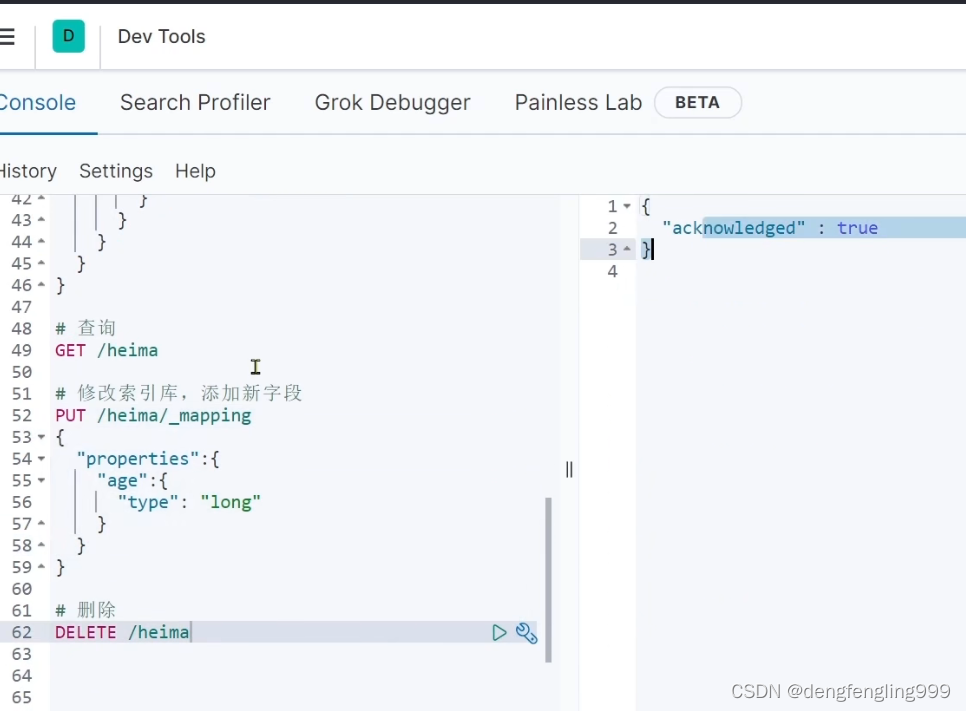
删除索引库:
查询一下:查询不到404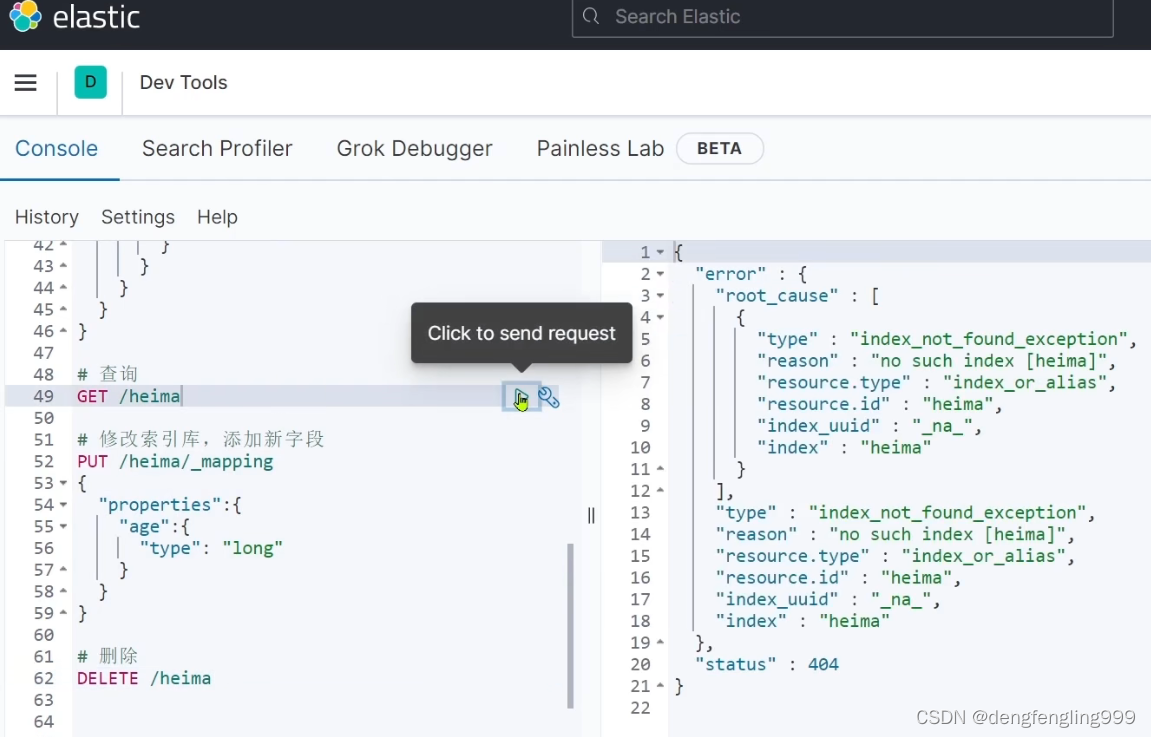

(6)文档操作-新增-查询-删除文档

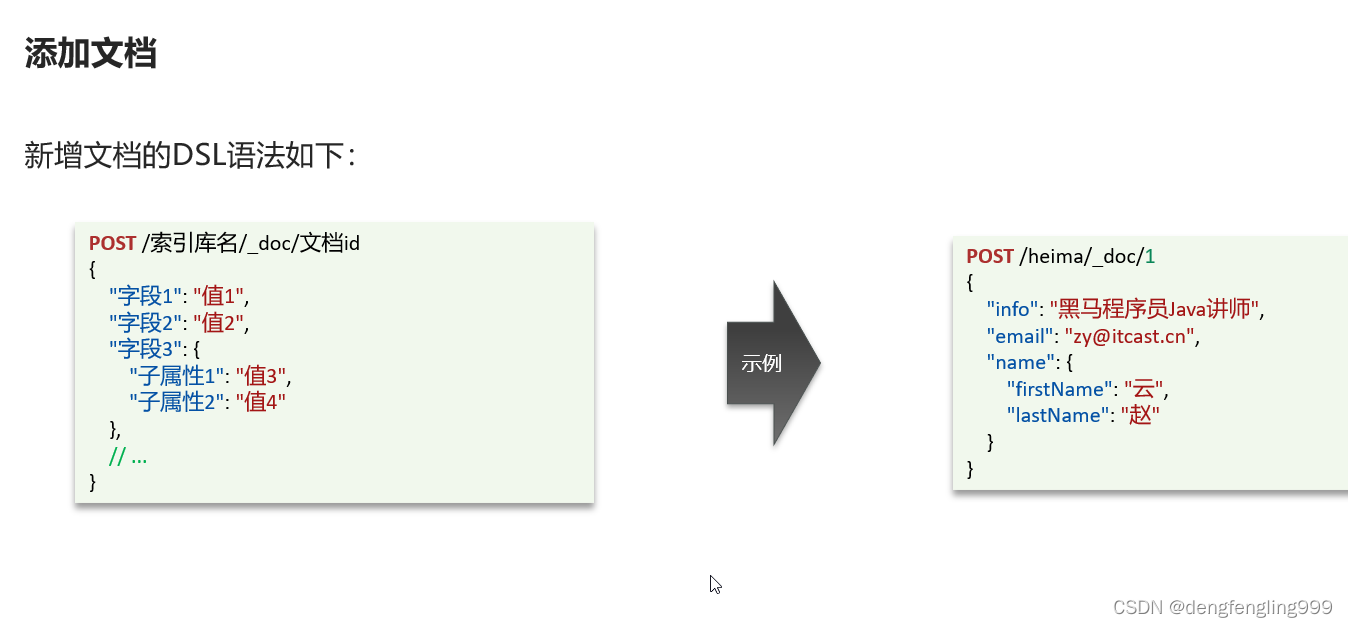 插入文档:
插入文档:
 查看一下添加的数据:_vesion:每次的写操作版本都会增加
查看一下添加的数据:_vesion:每次的写操作版本都会增加
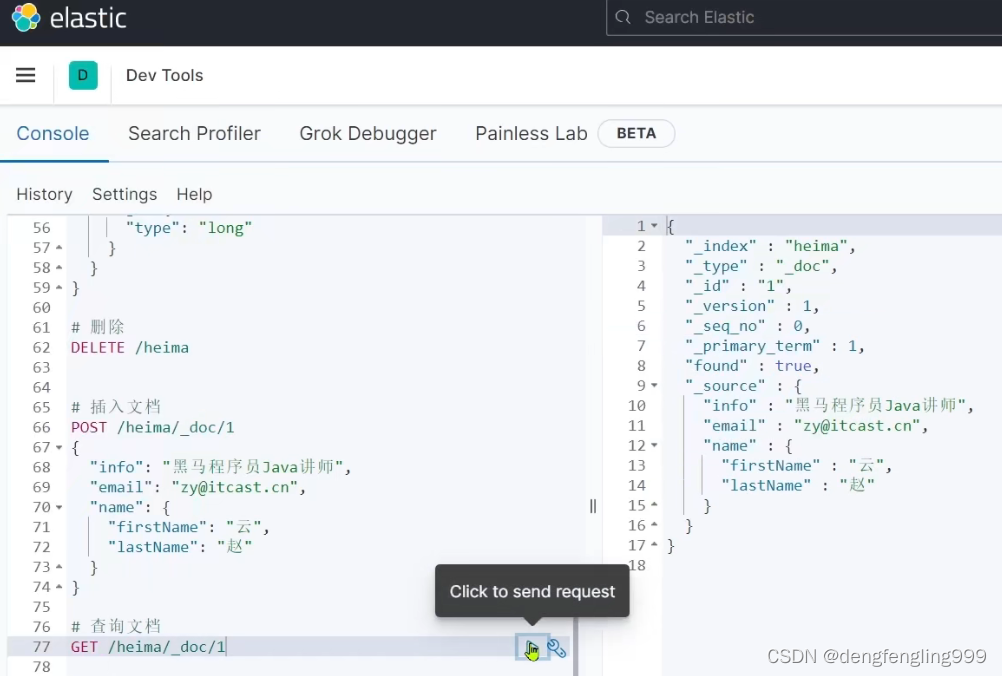
 删除文档:
删除文档:
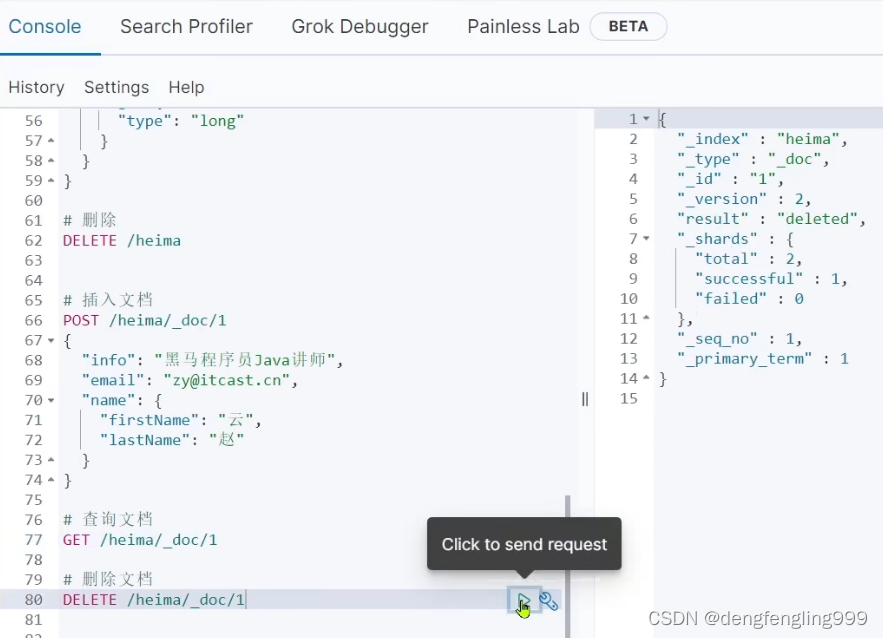
删除之后,在查询:
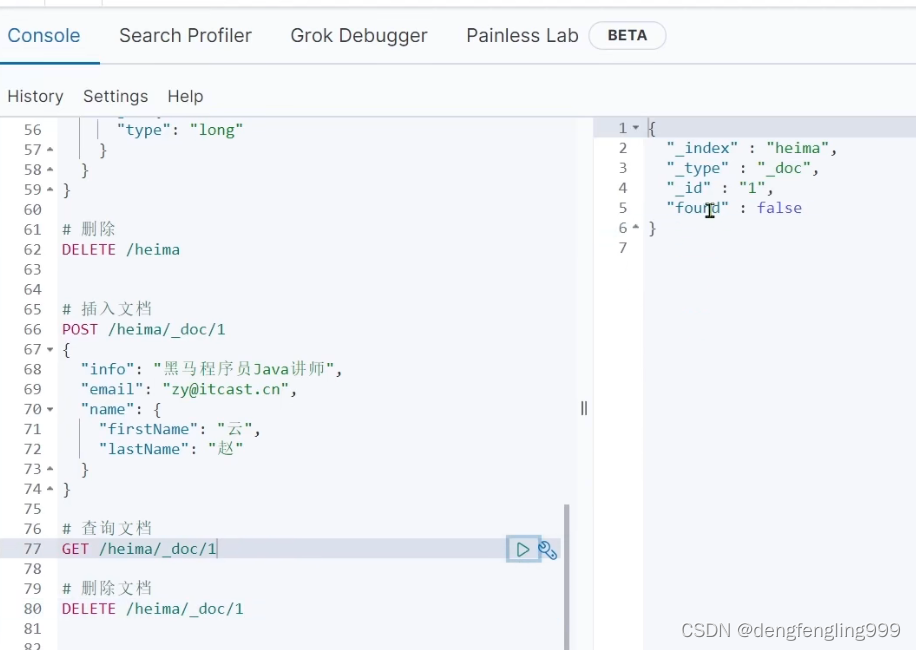
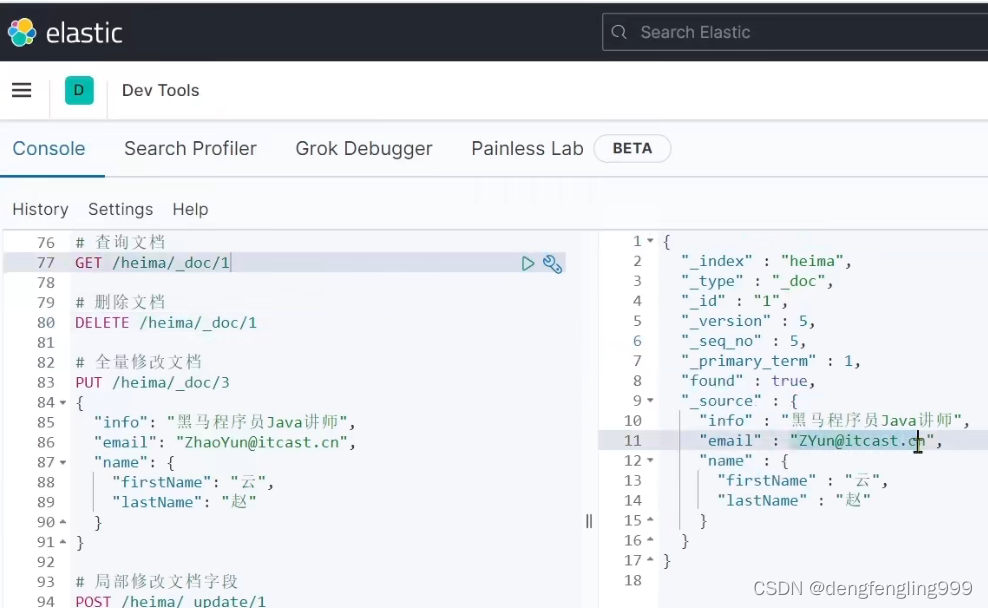
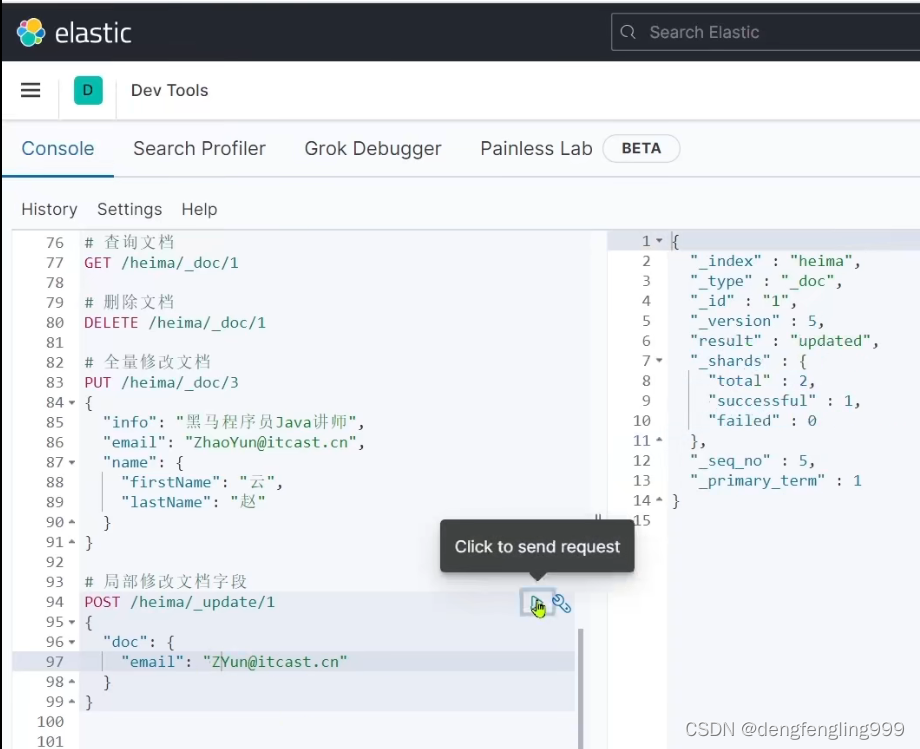
(7)文档操作-修改文档
方式一:
它跟新增文档的写法相似,只是更换了请求方式 ,它会根据id查询查询出来删除旧数据,添加新数据

修改文档:修改文档的email字段
在查询一下: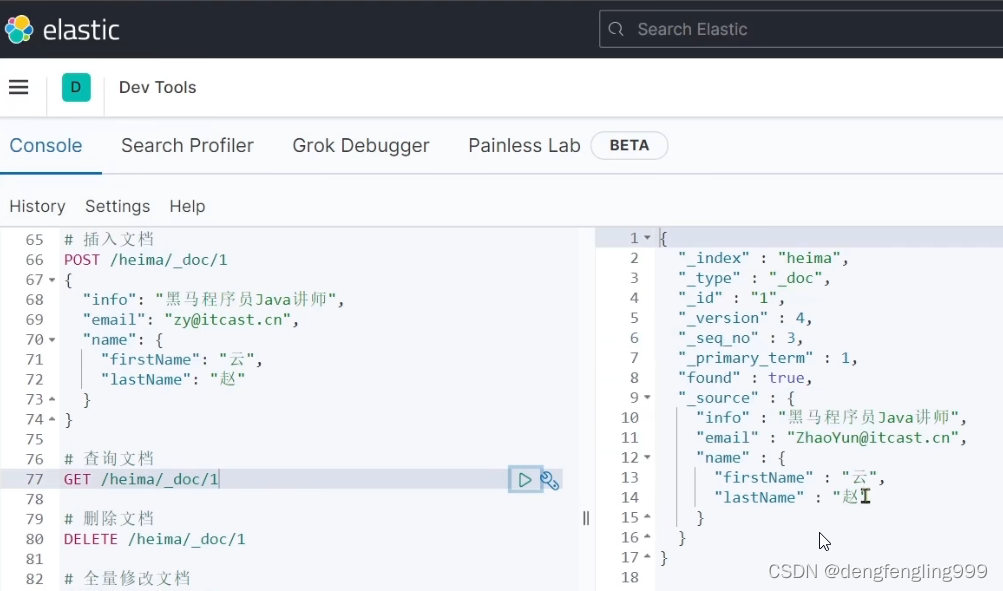
当id不存在时,变成了新增数据
方式二:(增量修改)局部修改:局部修改字段
修改email:
查询一下: