目标检测:YOLO V1 思想总结
- YOLO V1
- Introduction(模型介绍)
- Network Design(网络设计)
- Backbone(骨干网络)
- Grid Cell(单元格)
- Loss Function(损失函数)
- Training
- 小结
YOLO V1
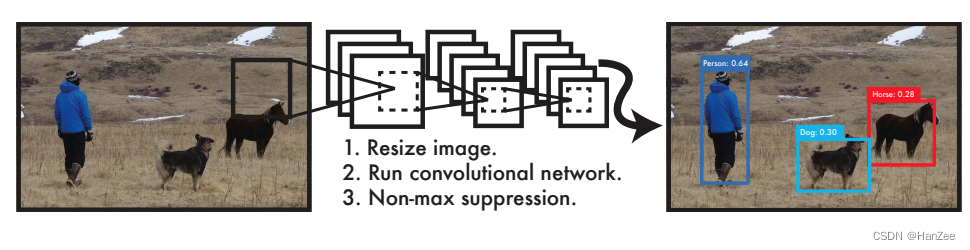
Introduction(模型介绍)
- YOLO V1在当时的速度非常快,FastYOLO可以达到150FPS。
- 它的背景误判率小于Faster RCNN,由于它直接提取全图的特征(前景与背景的关系),而后者则是提取候选框的特征。
- 迁移学习效果好。
- 在小目标上表现不佳。
Network Design(网络设计)
Backbone(骨干网络)
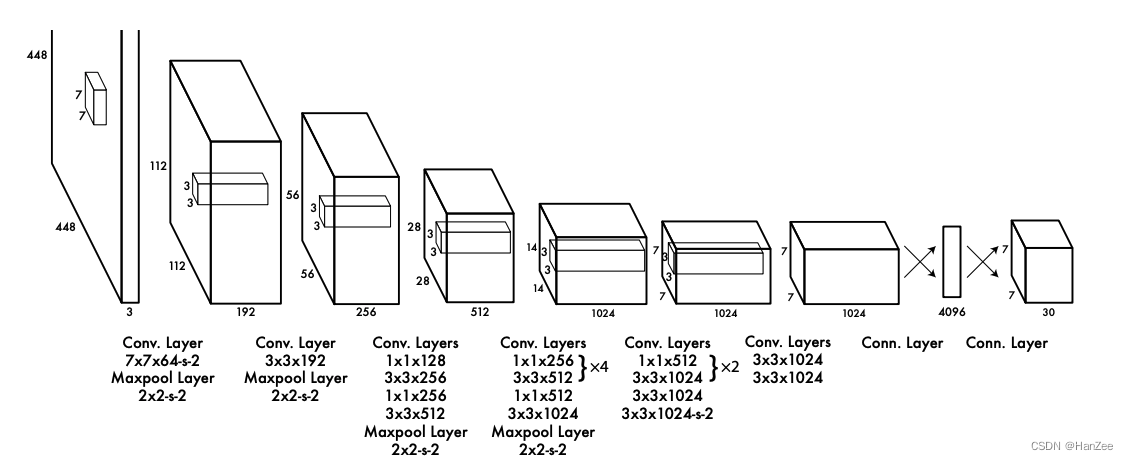
yolo的骨干网络是一个很简单网络,总体类似于VGG,采用3 * 3的卷积,最后全连接层输出4096维的向量,然后在跟一个全连接 (7 * 7 * 30)1430维的向量, 然后把它 resize成 7 * 7 * 30的一个tensor,这里面的每一个channel维就对应了一个单元格。
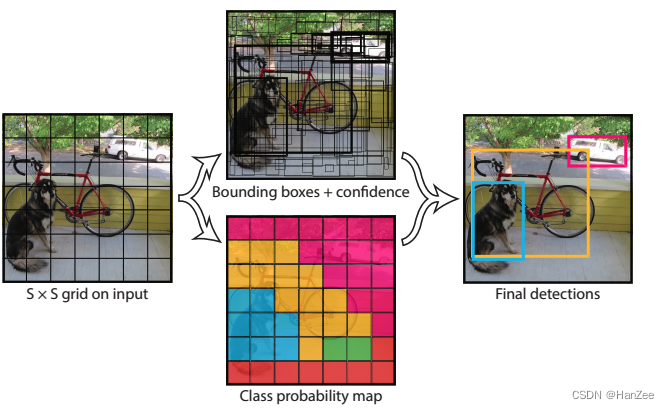
Grid Cell(单元格)
它把输入的一张图像分成 S * S 的网格(原文S=7),如果标注框的中心落在其中的一个 单元格,那么这个单元格就负责预测这个标注框对应的类别。每个单元格预测B个bounding box,每个bounding box 包含 四个坐标(x,y,w,h),和一个confidence。
其中这四个坐标为:x ,y 是bounding box的中点,用gird cell 左上角的偏移量表示,wh是相对于原图的大小,它们都是被归一化的。

confidence 的公式为:
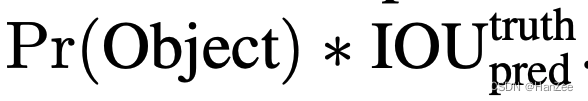
其中 Pr(object)为gird cell是否包含物体中心的概率,非0即1,后者表示如果gird cell 负责预测某一类别,它的标注框与预测框的IOU。
其中每个gird cell还会预测每个类别的概率,公式为:
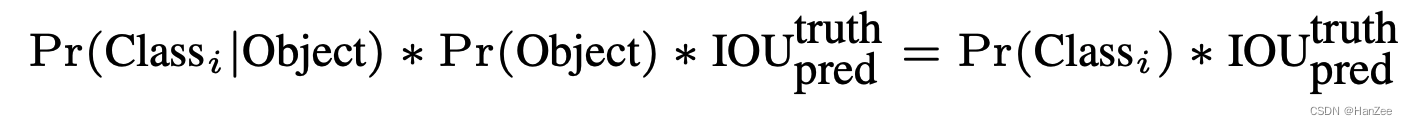
其中第一项就这个gird cell在负责预测某一类别的情况下,所有类别的softmax概率。
那么我们用什么样的feature来代表gird cell 呢?
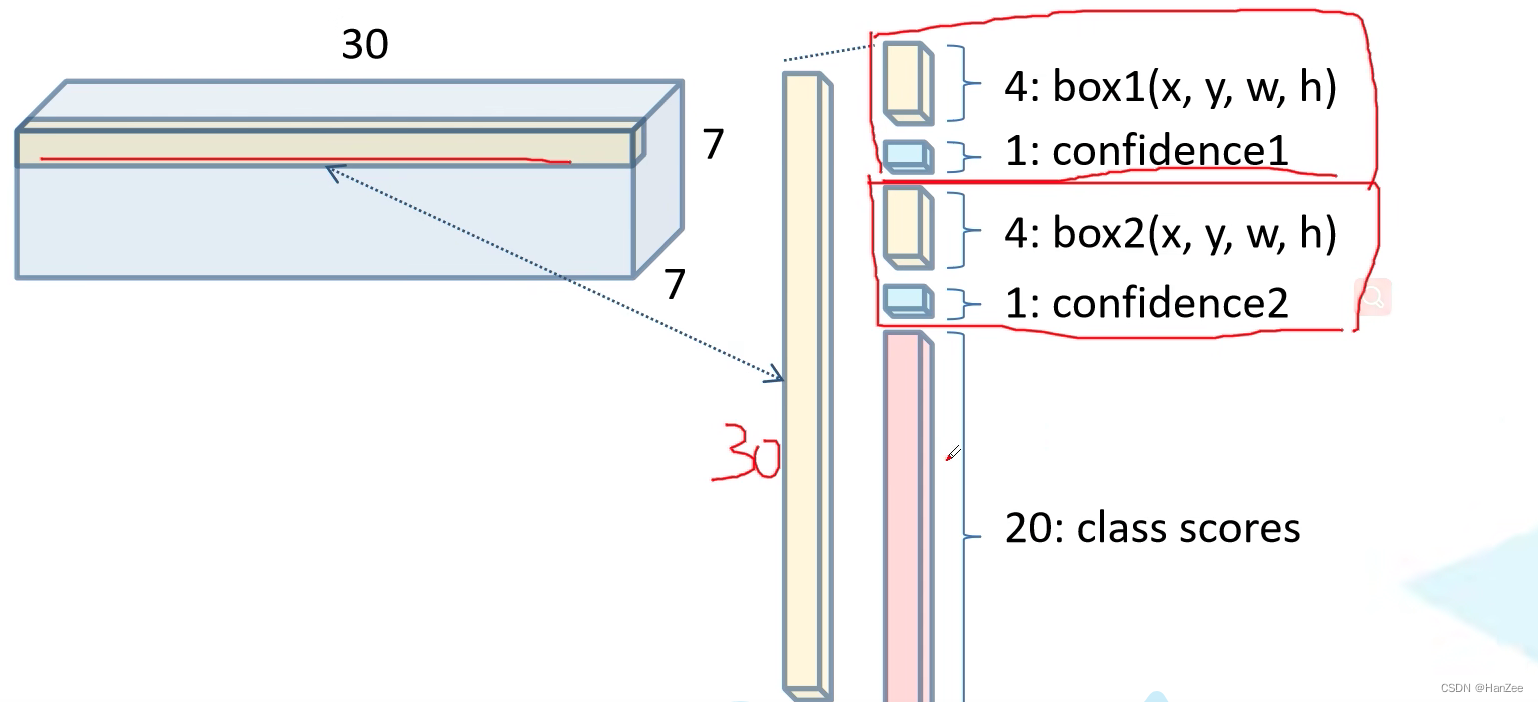
根据骨干网络输出的feature,每一个channel维就是每一个 gird cell 的 feature。
那么最终模型会输出 S * S *(5B+C)shape 的 tensor。
Loss Function(损失函数)
均方误差对需要细粒度的目标检测任务比较敏感,所以大部分都采用均方误差。
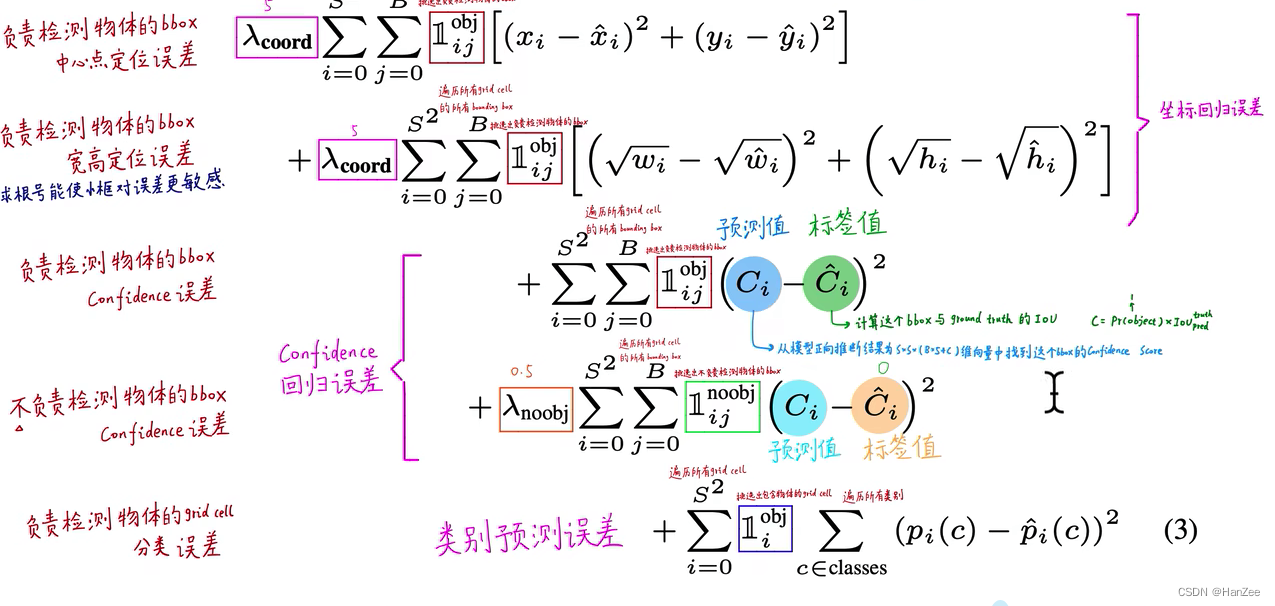
这里我们首先解释
λ
\lambda
λ,由于作者发现大部分的 gird cell 不负责预测物体,那么它们就没有坐标,只有背景的confdence,而这部分占大多数,就会掩盖住有物体的gird cell 所产生的loss,所以把下标为 coord的lambda 设为5,noobj设置为0.5,以便均衡两者。
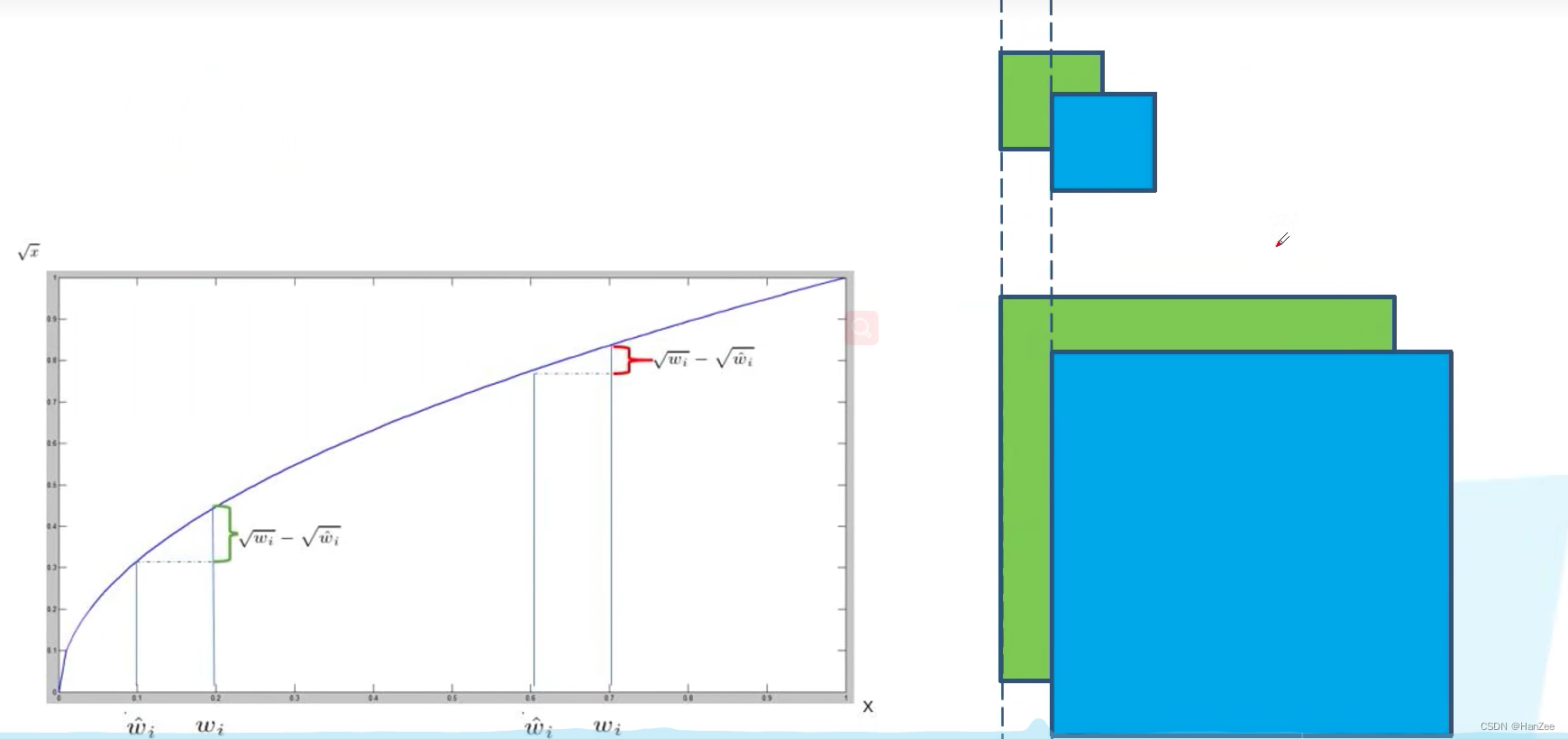
其中对不同尺度的IOU而言,当他们的偏移量一致的时候,小的bounding box 产生的误差要更大,所有为 w h 去根号,小的wh 会获得较小的loss,反之较大。
Training
首先把骨干网络 在Image Net上跑一遍,达到了很好的精度后,然后把权重拿到yolo,把input size 改为 448 * 448 因为检测任务对feature map 细粒度要求大。
激活函数采用 Leaky relu,根据训练epoch衰减lr, dropour =0.5. 数据增强。
小结
YOLO以速度见长,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。
不足之处是小对象检测效果不太好(尤其是一些聚集在一起的小对象),对边框的预测准确度不是很高,总体预测精度略低于Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。 更多细节请参考原论文。