《Investigating Critical Frequency Bands and Channels for EEG-based Emotion Recognition with Deep Neural Networks》
方法:
A.预处理根据被试的反应,只选择诱发目标情绪的实验时期进行进一步分析。
将原始脑电图数据降采样至200Hz采样率。目视检查脑电图信号,人工去除受肌电图和脑电图污染严重的记录。在实验中还记录了眼动图,并用于从记录的脑电图数据中识别闪烁伪影。为了滤除噪声和伪影,对EEG数据进行了0.3Hz至50Hz的带通滤波器处理。经过预处理后,我们提取了每部电影时长对应的脑电图片段。EEG数据的每个通道被划分为相同长度的1s周期,互不重叠。一个实验大约有3300个干净的年代。在脑电图数据的每个历元上进一步计算特征。所有信号处理均在Matlab软件中完成。
B.特征提取
一种称为微分熵(DE)[35]的高效特征,[36]扩展了香农熵的思想,用于度量连续随机变量[46]的复杂性。由于EEG数据的低频能量高于高频能量,因此DE具有区分EEG模式低频和高频能量的平衡能力,这是由Duan等人[36]首次引入到基于EEG的情绪识别中。原微分熵的计算公式定义为:

如果随机变量服从高斯分布N(µ,σ2),则微分熵可以简单地计算为:

针对特定的脑电信号序列,采用256点无重叠汉宁窗口(1s)的短时傅里叶变换提取脑电信号的5个频段。然后计算每个频带的微分熵。由于每个频带信号有62个通道,我们为一个样本提取了310维的微分熵特征。
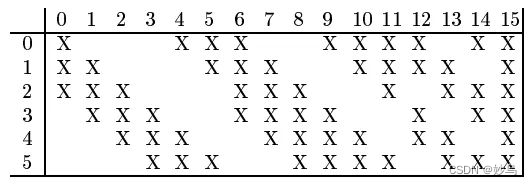
[38]和[47]的研究表明,不对称的大脑活动(左右侧化和前后尾化)似乎对情绪处理有效。所以我们也计算不对称微分(DASM)和理性的不对称(RASM)特性[36]DE特征之间的差异和比率27双半球不对称电极(F₁,F7, F3, F T7, F C3, T7, P7, C3, T P7 CP3, P3, O1, AF3, F5、F7, F C5, F C1, C5, C1, CP5, CP1, P5, p1, P O7, P O5, P O3, CB1左脑,和F p2, F8, F4, F T8, F C4, T8, P8, C4, T P8 CP4, P4, O2, AF4, F6, F8, F C6, F C2, C6, C2, CP6, CP2, P6, p2, P O8, P O6, P O4,右半球CB2)。DASM和RASM分别定义为:

其中xleft t和Xright分别代表左右半球的电极对。我们将DCAU特征定义为23对额后电极(F T7-T P7、F C5-CP5、F C3-CP3、F C1-CP1、F CZ-CP Z、F C2-CP2、F C4-CP4、F C6-CP6、F T8-T P8、F7-P7、F5-P5、F3-P3、F1-P1、F Z-P Z、F2-P2、F4-P4、F6-P6、F8-P8、F P1-O1、F P2-O2、F P Z- oz、AF3-CB1和AF4-CB2) DE特征之间的差异。DCAU定义为:

其中,Xf rontal和Xposterior表示前后电极对。为了进行比较,我们还提取了常规功率谱密度(PSD)作为基线。PSD、DE、DASM、RASM和DCAU特征的尺寸分别为310、310、135、135和115。我们应用线性动态系统(LDS)方法进一步过滤不相关的成分,并考虑情绪状态的时间动态。
C.深度信念网络分类
深度信念网络是一个具有深度架构的概率生成模型,它使用隐藏变量[25],[29]来表征输入数据分布。DBN的每一层由一个受限玻尔兹曼机(RBM)组成,RBM包含可见单元和隐藏单元,如图2(a)所示。没有可见-可见的联系,也没有隐藏-隐藏的联系。可见单元和隐藏单元分别有一个偏置向量c和b.
DBN是通过将预定义数量的RBM堆叠在一起来构造的,其中低级RBM的输出是高级RBM的输入,如图2(b)所示。一种高效的贪婪分层算法用于预训练网络的每一层。
在RBM中,联合分布P(v, h;θ)除以可见单位v和隐藏单位h,给定模型参数θ,定义为能量函数E(v, h;θ)

其中Z 是归一化因子:

模型赋给可见向量v的边际概率为:

对于高斯(可见)-伯努利(隐)RBM,能量函数定义为:

其中wij为可见单元vi与隐藏单元hj之间的对称相互作用项,bi和aj为偏置项,I和J为可见和隐藏单元的个数。条件概率可以有效地计算为:

其中σ(x) =1 /(1 + exp(x)), vi取实值,服从均值PJ j=1 wijhj + bi,方差为1的高斯分布。
取对数似然对数p(v;θ),我们可以推导出调整RBM权值的更新规则为

其中Edata(vihj)是在训练集中观察到的期望,而Emodel(vihj)是在模型定义的分布下的相同期望。但Emodel(vihj)难以计算,因此使用梯度的对比散度近似,其中Emodel(vihj)被运行在数据处初始化的吉布斯采样器取代。有时权重更新中的动量被用于防止陷入局部极小值,正则化可以防止权重变得太大。
在这项工作中,训练分为三个步骤:
1)对每层进行无监督的预训练,
2)对所有层进行无监督的反向传播微调,
3)对所有层进行有监督的反向传播微调。对于无监督微调,展开n个rbm以形成一个2n−1有向编码器和解码器网络,该网络可以通过反向传播[25],[49]进行微调。图2(c)显示了展开的DBN的图形描述。训练这个深度自编码器的目标是学习每一层之间的权重和偏差,以便重建和输入尽可能接近。对于监督微调,在预训练DBN的顶部添加标签层,并通过误差反向传播更新权重。