作为一名深耕自动化和人工智能领域的开发人员,我们逐渐认识到尖端工具和方法之间的显着协同作用,这些协同作用突破了可能性的界限。在这次探索中,我们想分享一个概念,它不仅彻底改变了我们的软件开发和基础设施管理方法,而且还打开了无尽创新的大门:GitOps。这种范例利用 Git 的力量作为卓越运营的基石,已经成为我们工具包中的游戏规则改变者,并为无限的可能性奠定了基础。
作为一名深耕自动化和人工智能领域的开发人员,我们逐渐认识到尖端工具和方法之间的显着协同作用,这些协同作用突破了可能性的界限。在这次探索中,我们想分享一个概念,它不仅彻底改变了我们的软件开发和基础设施管理方法,而且还打开了无尽创新的大门:GitOps。这种范例利用 Git 的力量作为卓越运营的基石,已经成为我们工具包中的游戏规则改变者,并为无限的可能性奠定了基础。
MinIO 的高性能对象存储、Weaviate 的 AI 增强元数据管理、Python 的动态脚本功能以及 GitOps 的系统方法的融合为任何渴望深入研究 AI 和机器学习的开发人员奠定了强大的基础。这些工具不仅简化了数据存储和管理的复杂性,还为快速开发和部署提供了灵活、强大的环境。通过将这些元素集成到我们的开发实践中,我们为构建在可扩展、高效和自动化基础设施上的项目奠定了基础。本文旨在引导您了解这些技术,轻松推动您的 AI 计划从概念变为现实。
这种集成由用于对象存储的 MinIO、作为元数据管理器的 Weaviate、作为动态引擎的 Python 以及用于简化基础设施管理的 GitHub/GitOps 组成,为开发本土 AI 解决方案奠定了坚实的基础。
-
MinIO — 对象存储主干:MinIO 提供高性能对象存储,这对于有效管理大量数据集至关重要。它作为骨干,确保数据可用性、安全性和可扩展性。
-
Weaviate — 使用 AI 进行元数据管理:Weaviate 充当复杂的元数据管理器,利用 AI 提供语义搜索功能,增强数据的可发现性和可用性。
-
Python——开发引擎:Python以其简单性和庞大的AI/ML库生态系统作为开发引擎,支持AI应用程序的快速原型设计和部署。
-
GitHub/GitOps — 基础设施自动化:GitHub Actions 通过自动化基础设施管理来增强 GitOps,确保顺利、无错误的部署。它简化了 GitHub 内的 CI/CD,提高了 DevOps 工作流程的效率和可靠性。
释放人工智能潜力
有了这些组件,我们不仅可以为开发应用程序建立框架,还可以为人工智能研究和开发的边缘创新建立框架。这种集成使开发人员能够花更多的时间进行探索,减少构建和测试的时间。特别是,我们正在部署的服务组合为任何有兴趣开发人工智能环境的人提供了一个出色的人工智能/机器学习起点,并有强大、可扩展和自动化的基础设施支持它们。
MinIO Weaviate Python GitOps 和工作流程
要创建用于测试的 GitOps 工作流程,请使用下面提供的 docker-compose.yaml ,其中包含应用程序、 minio 和 weaviate 服务的定义。我们将使用 CI/CD 管道方法,利用 GitHub Actions 实现自动化。
目标是在每次将更改推送到存储库时自动执行构建、测试和验证 Docker compose 设置的过程。成功的工作流程将选择您生成一个“ Status Badge ”,它在放置在 Markdown 文档中时提供实时更新。

目录树结构
所有文件都可以通过 GitHub minio/blog-assets/minio-weaviate-python-gitops 存储库文件夹获取:
├── .github/workflows
│ └── docker-workflow.yml
├── README.md
├── app
│ ├── Dockerfile
│ ├── entrypoint.sh
│ └── python_initializer.py
├── docker-compose.yaml
└── minio
├── Dockerfile
└── entrypoint.sh
本质上,关闭此存储库并将这些文件添加到您自己的 GitHub 存储库中,如上面的目录树所示。它将通过 GitHub 在特定存储库的“ Actions ”选项卡下自动运行。
什么是 GitOps?
GitOps 是一种现代的软件开发和基础设施管理方法,植根于四个关键原则,可简化和保护基础设施和应用程序的部署和管理:
-
声明式配置:系统及其所需状态是使用代码定义的,使配置易于维护和理解。
-
版本控制和不变性:所有更改和所需的状态配置都存储在 Git 中,为可审核性和回滚功能提供不可变的历史记录,从而确保一致性和可靠性。
-
自动化部署:自动化流程使实时状态与 Git 中定义的所需状态保持一致,从而增强部署一致性、减少手动错误并加快部署周期。
-
持续反馈和监控:根据 Git 中的所需状态持续监控系统,并自动更正或标记差异以供手动干预,从而确保系统的弹性和安全性。
通过围绕这些原则整合基础设施和应用程序管理,GitOps 提供了一个强大的框架,可以提高现代 DevOps 团队的速度、可靠性、安全性和协作效率。
.github/workflows/docker-workflow.yml 中定义的 GitHub 工作流程旨在自动执行基于提供的 docker-compose.yaml 构建和推送 Docker 映像的整个过程。该YAML文件编排了自定义MinIO和Python环境的部署,并使用最新的公共镜像部署了Weaviate;促进简化的开发流程。
.github/workflows/docker-workflow.yml 中定义的 GitHub 工作流程旨在自动执行基于提供的 docker-compose.yaml 构建和推送 Docker 映像的整个过程。该YAML文件编排了自定义MinIO和Python环境的部署,并使用最新的公共镜像部署了Weaviate;促进简化的开发流程。
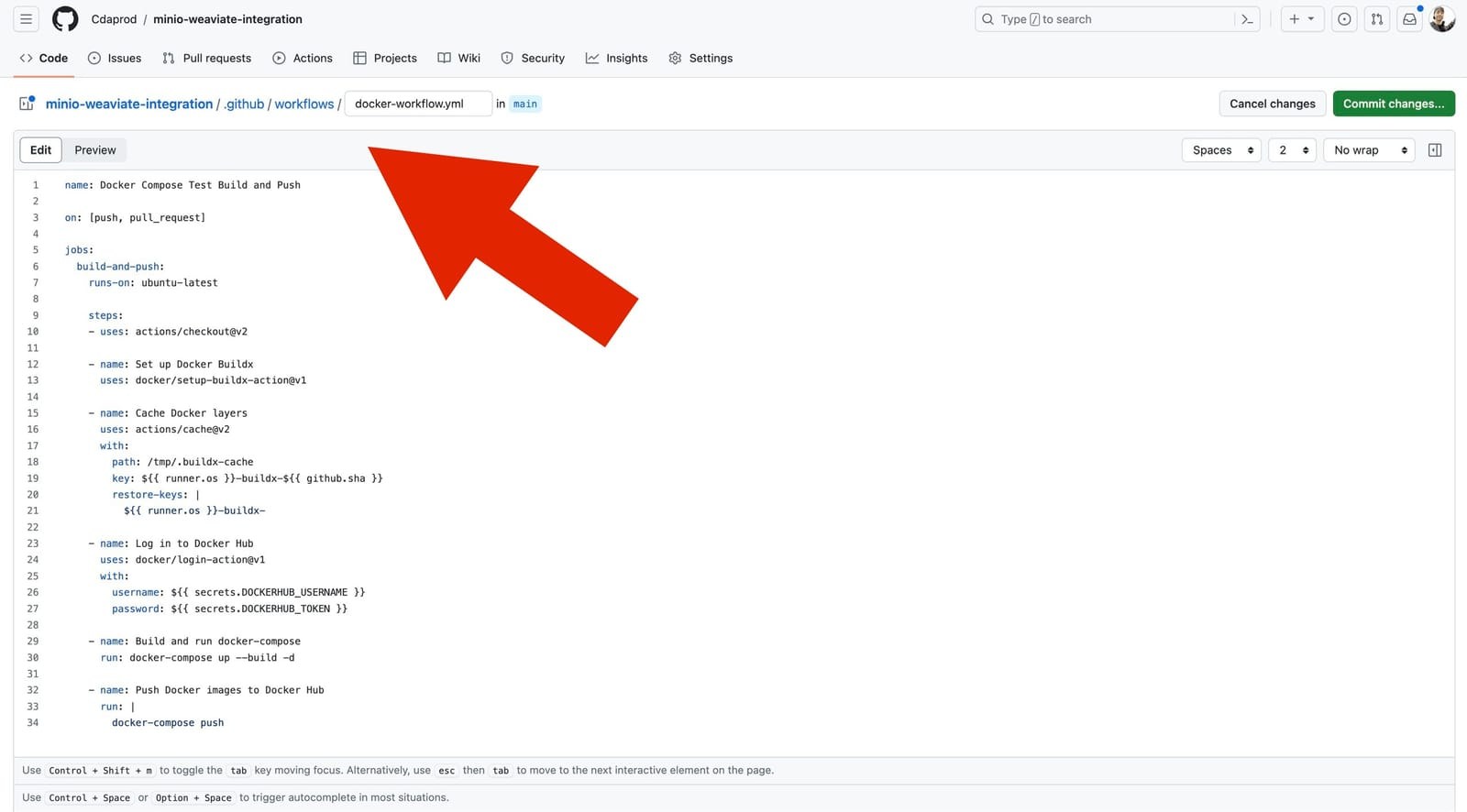
要通过 WebUI 在 GitHub 中创建嵌套目录,只需在添加新文件时在文件名前输入所需的路径即可。此方法会自动在指定目录中组织文件,从而简化文件管理,无需传统的文件夹创建步骤。
通过将 YAML 放在 /.github/workflows/ 目录中,将告诉 GitHub 将它们作为操作工作流运行。
Docker Compose 编排
当我们过渡到 Docker Compose 设置的细节时,所有基础工作都是由我们的目录结构和 GitHub 工作流程奠定的。 docker-compose.yaml 文件作为蓝图,详细说明了 MinIO、Weaviate 和我们的自定义 Python 应用程序等服务如何在我们的环境中进行容器化和交互。
此配置使您能够构建可扩展的自托管应用程序,从而挑战对 AWS 等传统云服务的需求。该蓝图使开发人员能够利用容器化的效率和灵活性来创建复杂的、基于微服务的架构。
使用 Docker Compose 和 Python 脚本进行自动模式创建和数据索引,此设置有助于开发能够在混合云环境中运行的可扩展、自托管应用程序。
/docker-compose.yaml
version: '3.8'
services:
minio:
container_name: minio_server
build:
context: ./minio
image: cdaprod/minio-server
volumes:
- ./minio/data:/data
ports:
- "9000:9000"
- "9001:9001"
command: server /data --console-address ":9001"
weaviate:
container_name: weaviate_server
image: semitechnologies/weaviate:latest
ports:
- "8080:8080"
environment:
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
QUERY_DEFAULTS_LIMIT: 25
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_MODULES: 'backup-s3, text2vec-cohere,text2vec-huggingface,text2vec-palm,text2vec-openai,generative-openai,generative-cohere,generative-palm,ref2vec-centroid,reranker-cohere,qna-openai'
BACKUP_S3_BUCKET: 'weaviate-backups'
BACKUP_S3_ENDPOINT: 'minio:9000'
BACKUP_S3_ACCESS_KEY_ID: 'minio'
BACKUP_S3_SECRET_ACCESS_KEY: 'minio123'
BACKUP_S3_USE_SSL: 'false'
CLUSTER_HOSTNAME: 'node1'
volumes:
- ./weaviate/data:/var/lib/weaviate
depends_on:
- minio
python-app:
container_name: python-app
build: ./app
image: cdaprod/python-app
volumes:
- ./app/data:/app/data
depends_on:
- weaviate
- minio
在 docker-compose.yaml 配置奠定的基础上,您开发的 Python 脚本可用于自动初始化和管理 Weaviate 数据库。该脚本在您的自托管容器化架构中提供两个功能:
-
模式创建:您的 Python 脚本会自动执行在 Weaviate 中定义模式的过程。该架构充当数据的蓝图,指定数据库将保存的信息类型以及不同实体如何相互关联。
-
数据索引:模式就位后,您的脚本将继续将数据索引到 Weaviate 中。此过程涉及以与预定义模式一致的方式将数据提取到数据库中,使其可搜索和检索。自动化数据索引有助于保持应用程序的流动性,因为它允许对数据库进行连续、实时更新,而无需停机或手动数据处理。
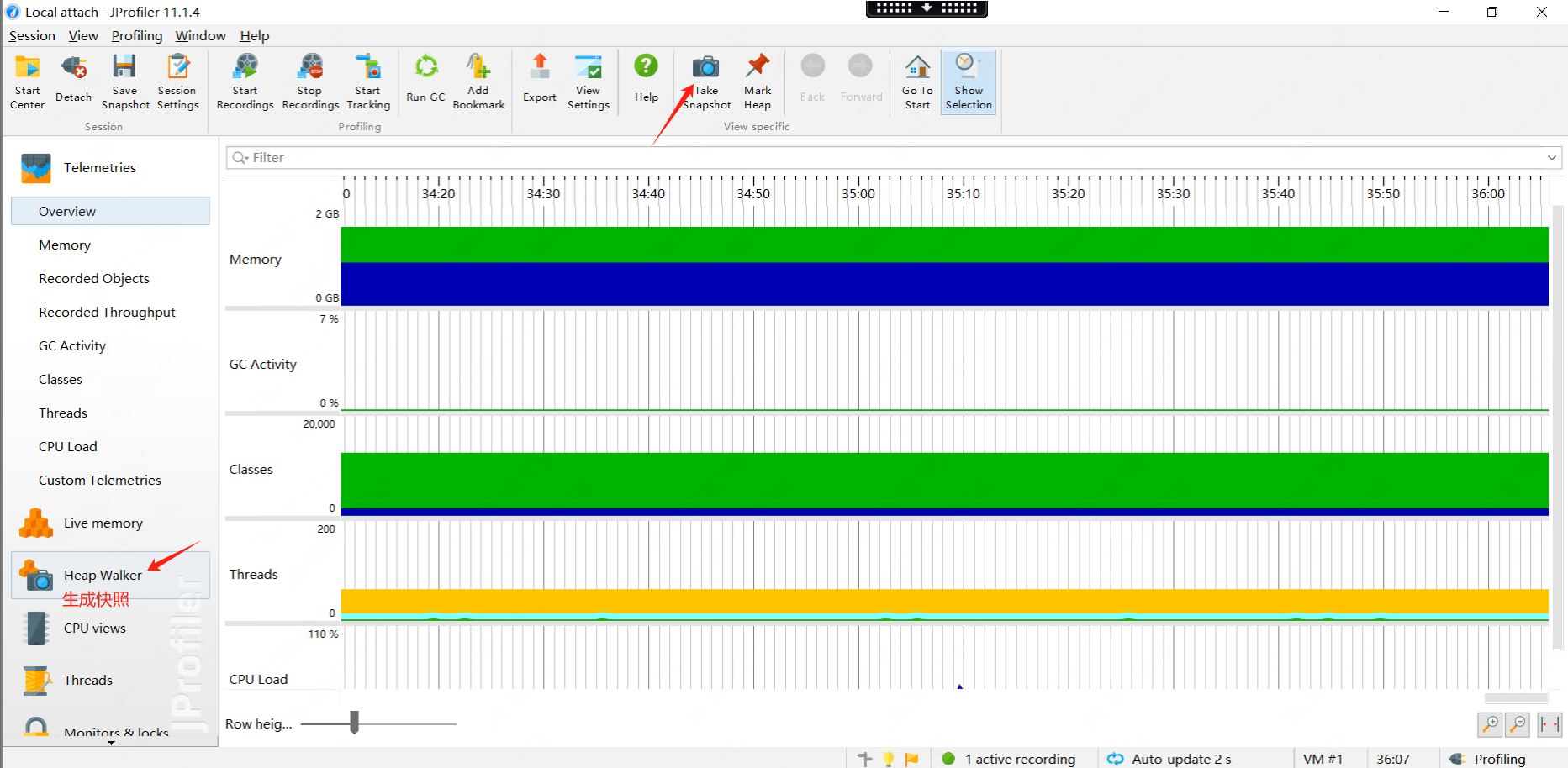
下面是 docker-compose.yaml 的屏幕截图以及使用 GitHub UI 提交的样子:

Dockerfile 和入口点脚本
docker-compose.yaml 中的每个服务都有其自定义 Dockerfile 和入口点脚本,以确保正确设置环境。 MinIO Dockerfile 和 Entrypoint Script 自定义 MinIO 服务器,包括设置必要的环境变量和准备服务器运行。
构建 MinIO 容器
此 Dockerfile 使用上游 minio/minio 映像以及在 entrypoint.sh 中实现的一些添加内容
FROM minio/minio
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh
ENV MINIO_ROOT_USER=minio \
MINIO_ROOT_PASSWORD=minio123
EXPOSE 9000 9001
ENTRYPOINT ["/entrypoint.sh"]
minio/Dockerfile 的 entrypoint.sh 做了几件事:
-
Waits 5 seconds 等待 5 秒
-
为 weaviate-backups 创建存储桶
/minio/entrypoint.sh
#!/bin/sh
set -e
# Start MinIO in the background
minio server /data --console-address ":9001" &
# Wait for MinIO to start
sleep 5
# Set up alias and create bucket
mc alias set myminio http://minio:9000 ${MINIO_ROOT_USER} ${MINIO_ROOT_PASSWORD}
mc mb myminio/weaviate-backups
# Keep the script running to prevent the container from exiting
tail -f /dev/null
应创建 MinIO Dockerfile 和 entrypoint.sh 文件,如下面的屏幕截图所示(在 /minio/ 目录中):
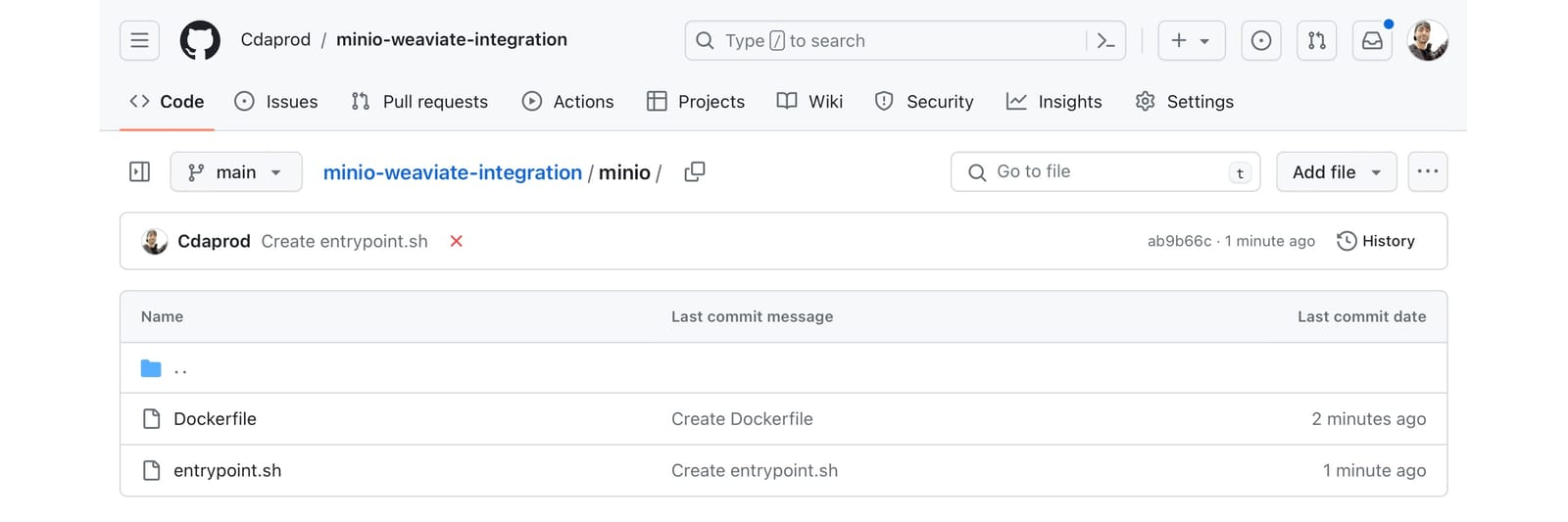
构建 Python 容器
我们的 Python 应用程序的这个应用程序/Dockerfile 做了几件事:
-
使用 python:3.9-slim 容器镜像
-
将 /app/ 设置为工作目录
-
安装 python 的 weaviate-client 库
-
将与 Dockerfile 位于同一目录中的文件复制到容器
-
设置 entrypoint.sh 脚本的权限
设置 Python 环境、安装依赖项并定义初始化 Weaviate 架构和数据的操作,然后备份到 MinIO。
/app/Dockerfile
FROM python:3.9-slim
WORKDIR /app
RUN pip install weaviate-client
COPY . /app/
RUN chmod +x /app/entrypoint.sh
ENTRYPOINT ["/app/entrypoint.sh"]
这个 entrypoint.sh 用于我们的 Python Dockerfile :
-
出错时退出
-
运行 python_initializer.py 脚本
###python_initializer.py 脚本可以在 blog-assets 存储库的 /app/ 目录中找到;它以编程方式与 Weaviate 交互,以:
/app/entrypoint.sh
#!/bin/bash
# Exit script on error
set -e
echo "Initialize Weaviate..."
python python_initializer.py
# Keep the container running after scripts execution
# This line is useful if you want to prevent the container from exiting after the scripts complete.
# If your container should close after execution, you can comment or remove this line.
tail -f /dev/null
应创建 Python 环境 Dockerfile 、 entrypoint.sh 和 python_initializer.py 文件,如下面的屏幕截图所示(在 /app/ 目录中):

用于 Weaviate 初始化的 Python 脚本
-
定义用于存储数据的模式。
-
将样本数据索引到 Weaviate 中。
-
查询索引数据并导出结果。
-
使用 backup-s3 模块将 Weaviate 数据备份到 MinIO 中。
/app/python_initializer.py
import weaviate
import json
# Configuration
WEAVIATE_ENDPOINT = "http://weaviate:8080"
OUTPUT_FILE = "data.json"
# Initialize the client
client = weaviate.Client(WEAVIATE_ENDPOINT)
schema = {
"classes": [
{
"class": "Article",
"description": "A class to store articles",
"properties": [
{"name": "title", "dataType": ["string"], "description": "The title of the article"},
{"name": "content", "dataType": ["text"], "description": "The content of the article"},
{"name": "datePublished", "dataType": ["date"], "description": "The date the article was published"},
{"name": "url", "dataType": ["string"], "description": "The URL of the article"}
]
},
{
"class": "Author",
"description": "A class to store authors",
"properties": [
{"name": "name", "dataType": ["string"], "description": "The name of the author"},
{"name": "articles", "dataType": ["Article"], "description": "The articles written by the author"}
]
}
]
}
# Fresh delete classes
try:
client.schema.delete_class('Article')
client.schema.delete_class('Author')
except Exception as e:
print(f"Error deleting classes: {str(e)}")
# Create new schema
try:
client.schema.create(schema)
except Exception as e:
print(f"Error creating schema: {str(e)}")
data = [
{
"class": "Article",
"properties": {
"title": "LangChain: OpenAI + S3 Loader",
"content": "This article discusses the integration of LangChain with OpenAI and S3 Loader...",
"url": "https://blog.min.io/langchain-openai-s3-loader/"
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Webhook Event Notifications",
"content": "Exploring the webhook event notification system in MinIO...",
"url": "https://blog.min.io/minio-webhook-event-notifications/"
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Postgres Event Notifications",
"content": "An in-depth look at Postgres event notifications in MinIO...",
"url": "https://blog.min.io/minio-postgres-event-notifications/"
}
},
{
"class": "Article",
"properties": {
"title": "From Docker to Localhost",
"content": "A guide on transitioning from Docker to localhost environments...",
"url": "https://blog.min.io/from-docker-to-localhost/"
}
}
]
for item in data:
try:
client.data_object.create(
data_object=item["properties"],
class_name=item["class"]
)
except Exception as e:
print(f"Error indexing data: {str(e)}")
# Fetch and export objects
try:
query = '{ Get { Article { title content datePublished url } } }'
result = client.query.raw(query)
articles = result['data']['Get']['Article']
with open(OUTPUT_FILE, 'w', encoding='utf-8') as f:
json.dump(articles, f, ensure_ascii=False, indent=4)
print(f"Exported {len(articles)} articles to {OUTPUT_FILE}")
except Exception as e:
print(f"An error occurred: {str(e)}")
# Create backup
try:
result = client.backup.create(
backup_id="backup-id-2",
backend="s3",
include_classes=["Article", "Author"],
wait_for_completion=True,
)
print("Backup created successfully.")
except Exception as e:
print(f"Error creating backup: {str(e)}")
将容器镜像推送到 Docker Hub - Artifact Registry
GitHub Actions 工作流程自动执行以下过程:
-
检查存储库代码。
-
设置 Docker Buildx 以构建多架构映像。
-
缓存 Docker 层以加快构建速度。
-
登录Docker Hub推送镜像。
-
构建 docker-compose.yaml 中定义的 Docker 镜像。
-
使用 docker-compose up 部署服务。
-
(可选)将构建的镜像推送到 Docker Hub。
-
使用 docker-compose down 拆除部署。
要获取 Docker Hub 用户名并生成用于 Docker CLI 身份验证或将 Docker Hub 与其他工具集成的个人访问令牌 (PAT),请执行以下步骤:
-
创建 Docker Hub 帐户:如果您还没有,请在 Docker Hub 的网站上注册以获取用户名。
-
生成个人访问令牌 (PAT):
-
登录您的 Docker Hub 帐户并导航至您的帐户设置。
-
在屏幕左侧的菜单中找到“ Security ”部分。
-
单击“ New Access Token ”按钮创建新令牌。
-
为您的令牌分配一个名称,这将帮助您识别其用途或预期的服务。
-
创建后,请确保复制令牌并安全存储,因为它只会显示一次。
个人访问令牌提供了一种比使用密码更安全的替代方案,特别是对于 CLI 操作或集成。可以通过 Docker Hub 用户界面管理(创建和撤销)令牌,从而提供安全灵活的跨服务身份验证方式。
如何使用 GitHub 秘密
以下是将机密添加到 GitHub 存储库的一般过程,您可以将其应用于添加 Docker Hub 凭据:
-
导航到您的 GitHub 存储库:转到要添加机密的 GitHub 存储库。
-
访问存储库设置:单击存储库页面顶部的“设置”选项卡。
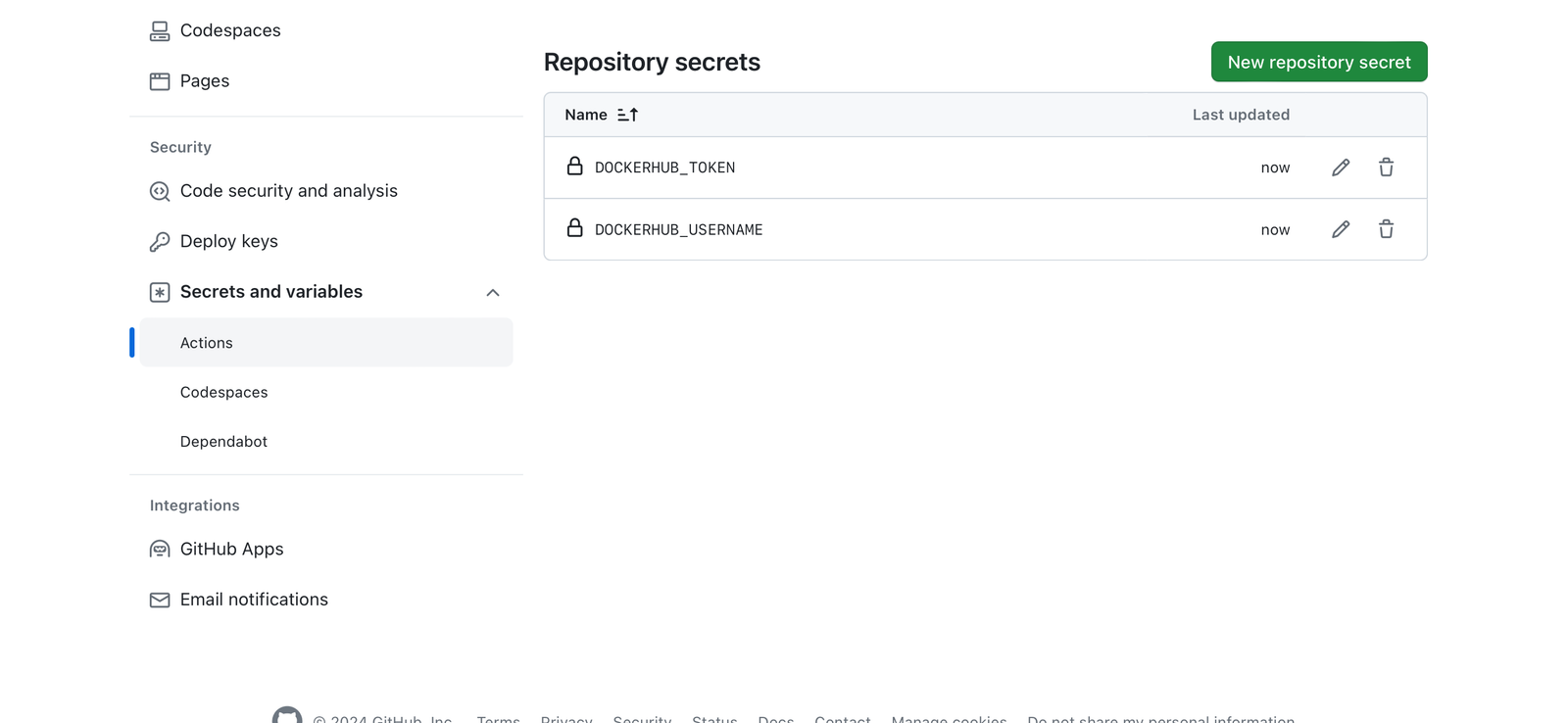
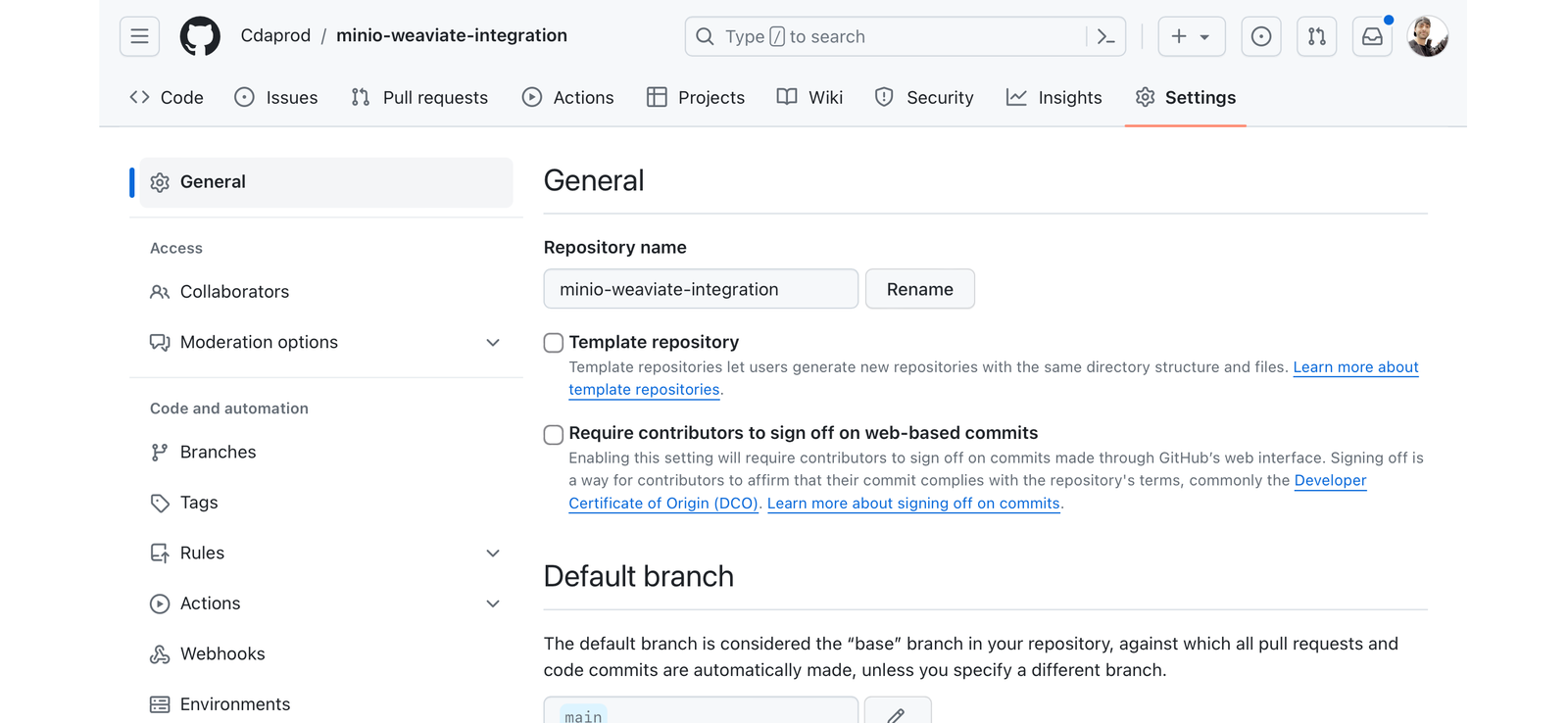 3. 转到 Secrets:在左侧边栏上,单击“Secrets & Variables”以展开该部分,然后选择“Actions”以查看 GitHub Actions 的 Secrets 页面。
3. 转到 Secrets:在左侧边栏上,单击“Secrets & Variables”以展开该部分,然后选择“Actions”以查看 GitHub Actions 的 Secrets 页面。

-
添加新密码:单击“新存储库密码”按钮。
-
输入秘密名称和值:
-
保存每个秘密:输入每个秘密的名称和值后,单击“ Add secret ”按钮将它们保存到您的存储库。
 这些机密现在可在您的 GitHub Actions 工作流程中使用。可以在工作流程文件中使用语法
{{ secrets.DOCKERHUB_TOKEN }} 引用它们。
这些机密现在可在您的 GitHub Actions 工作流程中使用。可以在工作流程文件中使用语法
{{ secrets.DOCKERHUB_TOKEN }} 引用它们。
此方法可确保您的 Docker Hub 凭据安全存储,并且不会暴露在存储库的代码或日志中。
使用 GitHub Actions 进行构建和测试
将 GitHub Actions 集成到开发和部署工作流程中代表了向自动化和效率的范式转变。 GitHub Actions 是一个 CI/CD 平台,可自动化您的软件构建、测试和部署管道,使您可以自动化所有软件工作流程,现在拥有世界一流的 CI/CD。
为 Docker Compose 设置 GitHub 操作
要利用 GitHub Actions 自动化 Docker Compose 工作流程,您首先需要在存储库中创建工作流程文件。该文件通常名为 docker-workflow.yml,位于 .github/workflows/ 目录中,并指定 GitHub Actions 应执行的步骤。
-
工作流程定义 docker-workflow.yml 文件以工作流名称和触发它的事件的定义开始。例如,您可能希望它在每次向主分支推送和拉取请求时运行:
name: Docker Compose Test Build and Push
on:
push:
branches:
- main
pull_request:
branches:
- main
-
工作及步骤 在工作流程中,您可以定义指定要执行的任务的作业。每个作业都在 runs-on 指定的环境中运行,并包含执行命令、设置工具或使用 GitHub 社区创建的操作的步骤。
/.github/workflows/docker-workflow.yml
name: Docker Compose Test Build and Push
on: [push, pull_request]
jobs:
build-and-push:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Cache Docker layers
uses: actions/cache@v2
with:
path: /tmp/.buildx-cache
key: ${{ runner.os }}-buildx-${{ github.sha }}
restore-keys: |
${{ runner.os }}-buildx-
- name: Log in to Docker Hub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Docker Compose Build
run: docker-compose -f docker-compose.yaml build
- name: Docker Compose Up
run: docker-compose -f docker-compose.yaml up -d
- name: Push Docker images to Docker Hub
run: docker-compose -f docker-compose.yaml push
- name: Docker Compose Down
run: docker-compose -f docker-compose.yaml down
-
环境与秘密
该工作流程利用 GitHub 机密( DOCKERHUB_USERNAME 和 DOCKERHUB_TOKEN )安全登录 Docker Hub。此方法可确保工作流文件中不会暴露敏感信息。
-
构建和推送 Docker 镜像
作业中的步骤自动执行使用 Docker Compose 构建 Docker 映像、将其推送到 Docker Hub 以及使用 docker-compos e up 和 docker-compose down 命令管理部署生命周期的过程。
-
测试
部署后,可以运行自动化测试以确保应用程序按预期运行。
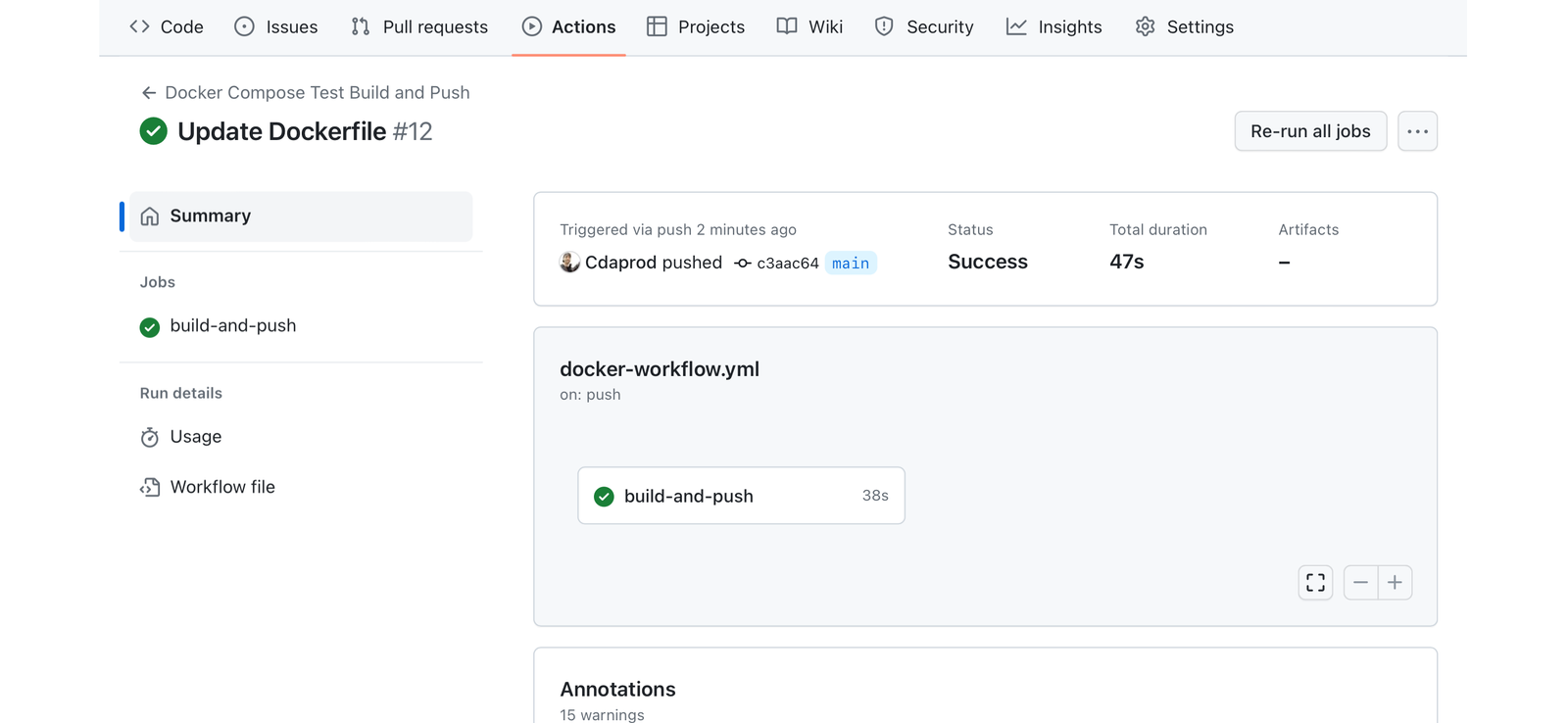
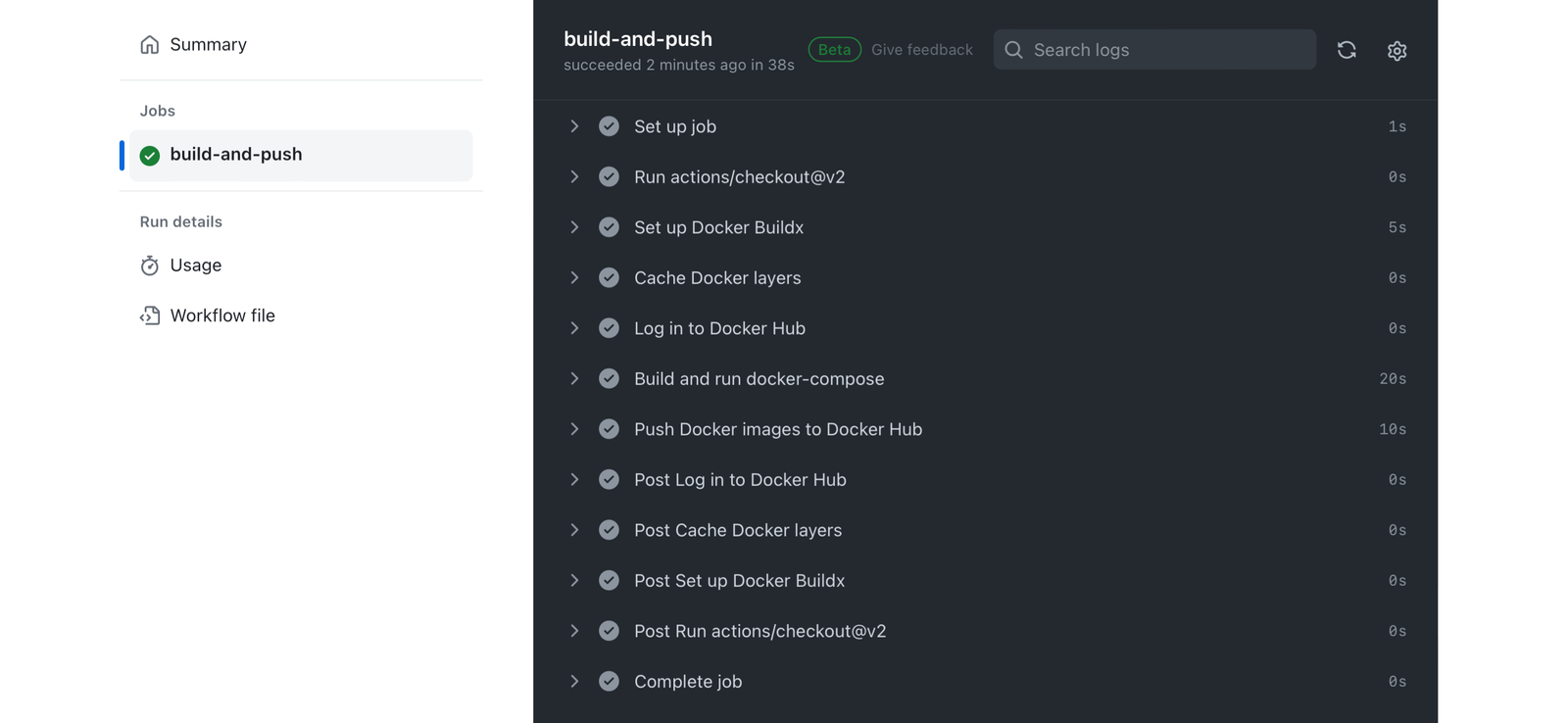 这些测试对于在整个开发生命周期中维护代码质量和功能至关重要。
这些测试对于在整个开发生命周期中维护代码质量和功能至关重要。
在 GitHub Actions 中创建状态徽章
-
转到您的存储库:打开托管项目的 GitHub 存储库。
-
访问“操作”选项卡:单击存储库页面顶部的“操作”选项卡。此选项卡显示与您的存储库关联的工作流程运行。
-
选择工作流程:找到要为其创建状态徽章的工作流程。您可以通过单击左侧列表中的工作流程名称来选择它。
-
查找徽章 Markdown:选择工作流程后,查找类似“ Copy status badge Markdown ”的部分或链接。单击此按钮将打开一个模式,显示徽章的降价代码。

-
复制 Markdown 代码:复制提供的 Markdown 代码。您将将此代码嵌入到 README.md 文件或任何其他您希望显示徽章的 Markdown 文件中。
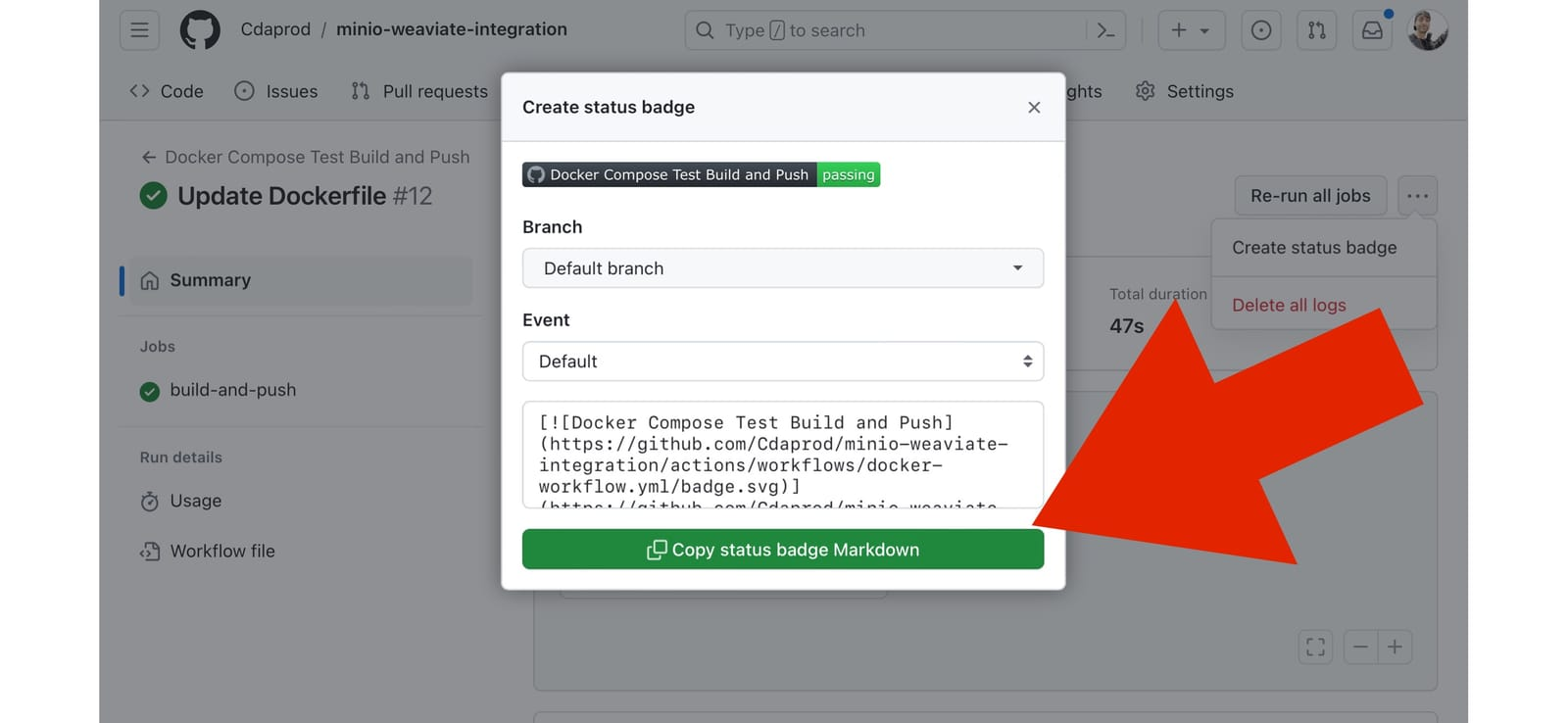
-
嵌入徽章:将复制的 Markdown 代码粘贴到 README.md 文件中您希望徽章显示的位置。
-
GitHub Actions 的代码通常如下所示:

分别将用户、存储库和工作流文件名替换为您的 GitHub 用户名、存储库名称和工作流文件名。
-
提交您的更改:将更新的 README.md 文件提交到您的存储库。现在,无论您在何处放置 Markdown 代码,状态徽章都会出现,显示工作流程的当前状态(例如,通过、失败)。

如果您使用不同的平台(例如 GitLab、Bitbucket 等),该过程应该有些相似:查找 CI/CD 设置或管道配置,您可以在其中找到用于创建状态徽章的选项。
如果您一直在关注我们,那么恭喜您!使用此状态徽章,我们现在可以查看构建进度和 GitOps 的状态。到目前为止,您应该在利用 Git 作为基础设施和应用程序部署的单一事实来源方面打下了坚实的基础。
使用 GitHub Actions 的好处
-
自动化:简化构建、测试和部署流程,减少手动错误并节省时间。
-
灵活性:支持多种编程语言和框架。
-
集成:与 GitHub 存储库无缝集成,增强协作和反馈。
-
可扩展性:轻松适应任何规模的项目,从小型初创公司到大型企业。
通过将 GitHub Actions 合并到 Docker Compose 项目的工作流程中,团队可以实现更高的效率、更好的可靠性和更快的部署周期。这种集成体现了现代软件开发中自动化的力量,使开发人员能够更多地关注创新,而不是部署机制。
本教程演示了如何应用 GitOps 原则来自动化涉及 MinIO 及其服务的复杂应用程序设置的任何部署和测试。通过利用 GitHub Actions,对存储库的更改会自动触发工作流程,确保应用程序的组件始终处于可部署和测试状态。
用 GitOps 和 AI 拥抱未来
正如我们通过 MinIO 与 GitOps 和 AI 开发工具(Weaviate 和 Python)的深度集成共同展示的那样,我们已经制定了重新定义技术和 AI 研究格局的蓝图。这种融合不仅简化了我们的开发流程,而且使我们能够以新的敏捷性和精确性解决人工智能的复杂性。
MinIO 的存储弹性,加上 Weaviate 的智能元数据管理和 Python 的动态功能,所有这些都按照 GitOps 的原则进行编排,为开发、部署和管理 AI 应用程序提供了一个全面的环境。这个坚实的基础鼓励我们思考更大、更进一步,在高效、可扩展和自动化基础设施的支持下探索人工智能的巨大潜力。
作为本土开发人员、爱好者或行业资深人士,我们利用这些进步、从头开始推动创新的时机已经成熟。无论您是开始第一个人工智能项目还是希望增强现有工作流程,所讨论的工具和方法都可以提供一条成功之路,最大限度地减少障碍并最大限度地发挥潜力。我鼓励您吸收这些见解并将其应用到您自己的发展工作中。试验这些技术,将它们集成到您的项目中,并与社区分享您的经验。通过这样做,我们不仅为人工智能的发展做出了贡献,而且还确保我们保持在这个令人兴奋的领域的最前沿,准备好利用未来的机遇。
我们期待成为您探索这些先进解决方案并在数据驱动的努力中达到新高度的旅程的一部分。如果您有任何疑问或只是想打个招呼,请务必通过 Slack 与我们联系。
一次一行代码,构建未来!