文章目录
- 一、Redis简介
- 二、Redis的特性
- 三、Redis的使用场景
- 四、Redis可以做什么
- 五、Redis不可以做什么
- 六、CentOS7安装Redis5
- 七、Redis通用命令
一、Redis简介
Redis 是⼀种基于 键值对(key-value) 的NoSQL数据库,与很多键值对数据库不同的是,Redis中的值可以是由string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合)、Bitmaps(位图)、HyperLogLog、GEO(地理信息定位)等多种数据结构和算法组成,因此Redis可以满⾜很多的应⽤场景,而且因为Redis会将所有数据都存放再内存中,所以它的读写性能⾮常惊⼈。不仅如此,Redis还可以将内存的数据利⽤快照和日志的形式保存到硬盘上,这样在发⽣类似断电或者机器故障的时候,内存中的数据不会“丢失”。除了上述功能以外,Redis还提供了键过期、发布订阅、事务、流水线、Lua脚本等附加功能。总之,如果在合适的场景使用好Redis,它就会像⼀把瑞士军刀⼀样所向披靡。

2008年,Redis的作者 SalvatoreSanfilippo 在开发⼀个叫LLOOGG的网站时,需要实现⼀个高性能的队列功能,最开始是使⽤MySQL来实现的,但后来发现⽆论怎么优化SQL语句等都不能使⽹站的性能提⾼上去,再加上⾃⼰囊中羞涩,于是他决定⾃⼰做⼀个专属于LLOOGG的数据库,这个就是Redis的前⾝。后来,SalvatoreSanfilippo将Redis1.0的源码发布到Github上,可能连他自己都没想到,Redis后来如此受欢迎。
假如现在有⼈问Redis的作者都有谁在使⽤Redis,我想他可以开句玩笑的回答:还有谁不使用Redis,当然这只是开玩笑,但是从Redis的官⽅公司统计来看,有很多重量级的公司都在使用Redis,如国外的Twitter、Instagram、StackOverflow、Github等,国内就更多了,如果单单从体量来统计,新浪微博可以说是全球最⼤的Redis使⽤者,除了新浪微博,还有像阿⾥巴巴、腾讯、搜狐、优酷⼟⾖、美团、⼩⽶、唯品会等公司都是Redis的使⽤者。除此之外,许多开源技术像ELK等已经把Redis作为它们组件中的重要⼀环,⽽且Redis还提供了模块系统让第三⽅⼈员实现功能扩展,让Redis发挥出更⼤的威⼒。所以,可以这么说,熟练使⽤和运维Redis已经成为开发运维⼈员的⼀个必备技能。
二、Redis的特性
Redis之所以受到如此多公司的⻘睐,必然有之过⼈之处,下⾯是关于Redis的8个重要特性。
速度快
正常情况下,Redis执⾏命令的速度⾮常快,官⽅给出的数字是读写性能可以达到10万/秒,当然这也取决于机器的性能,但这⾥先不讨论机器性能上的差异,只分析⼀下是什么造就了Redis如此之快,可以⼤概归纳为以下六点:
- Redis的所有数据都是存放在内存中的,所以把数据放在内存中是Redis速度快的最主要原因。
- Redis是⽤C语⾔实现的,⼀般来说C语⾔实现的程序“距离”操作系统更近,执⾏速度相对会更快。
- 从网络上,Redis使用了IO多路复用(使用一个线程,管理多个socket)的方式(epoll)。
- Redis核心功能都是比较简单的逻辑(核心功能都是比较简单的操作内存的数据结构)
- Redis使⽤了单线程,预防了多线程可能产⽣的竞争问题
- Redis在6.0版本引⼊了多线程机制,但主要也是在处理⽹络和IO,不涉及到数据命令,即命令的执⾏仍然采⽤了单线程模式。
- 作者对于Redis源代码可以说是精打细磨,曾经有⼈评价Redis是少有的集性能和优雅于⼀⾝的开源代码。
这里我们需要注意的是,多线程提高效率的前提是:对于CPU密集型的任务,使用多个线程可以充分利用CPU多核资源。但是Redis的核心任务主要是操作内存中的数据结构,因此不会吃太多CPU。
基于键值对的数据结构服务器
⼏乎所有的编程语⾔都提供了类似字典的功能,例如C++⾥的map、Java⾥的map、Python⾥的dict等,类似于这种组织数据的⽅式叫做基于键值对的⽅式,与很多键值对数据库不同的是,Redis中的值不仅可以是字符串,⽽且还可以是具体的数据结构,这样不仅能便于在许多应⽤场景的开发,同时也能提⾼开发效率。Redis的全称是REmoteDictionaryServer,它主要提供了5种数据结构:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(orderedset/zet),同时在字符串的基础之上演变出了位图(Bitmaps)和HyperLogLog两种神奇的”数据结构“,并且随着LBS(Location Based Service,基于位置服务)的不断发展,Redis3.2.版本种加⼊有关GEO(地理信息定位)的功能,总之在这些数据结构的帮助下,开发者可以开发出各种“有意思”的应⽤。
丰富的功能
除了5种数据结构,Redis还提供了许多额外的功能:
- 提供了键过期功能,可以⽤来实现缓存。
- 提供了发布订阅功能,可以⽤来实现消息系统。
- ⽀持Lua脚本功能,可以利⽤Lua创造出新的Redis命令。
- 提供了简单的事务功能,能在⼀定程度上保证事务特性。
- 提供了流⽔线(Pipeline)功能,这样客⼾端能将⼀批命令⼀次性传到Redis,减少了⽹络的开销。
简单稳定
Redis的简单主要表现在三个⽅⾯。⾸先,Redis的源码很少,早期版本的代码只有2万⾏左右,3.0版本以后由于添加了集群特性,代码增⾄5万⾏左右,相对于很多NoSQL数据库来说代码量相对要少很多,也就意味着普通的开发和运维⼈员完全可以“吃透”它。其次,Redis使⽤单线程模型,这样不仅使得Redis服务端处理模型变得简单,⽽且也使得客⼾端开发变得简单。最后,Redis不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库),Redis⾃⼰实现了事件处理的相关功能。
但与简单相对的是Redis具备相当的稳定性,在⼤量使⽤过程中,很少出现因为Redis⾃⾝BUG⽽导致宕掉的情况。
客户端语言多
Redis提供了简单的TCP通信协议,很多编程语⾔可以很⽅便地接⼊到Redis,并且于Redis受到社区和各⼤公司的⼴泛认可,所以⽀持Redis的客⼾端语⾔也⾮常多,⼏乎涵盖了主流的编程语⾔,例如C、C++、Java、PHP、Python、NodeJS等,后续我们会对Redis的客⼾端使⽤做详细说明。
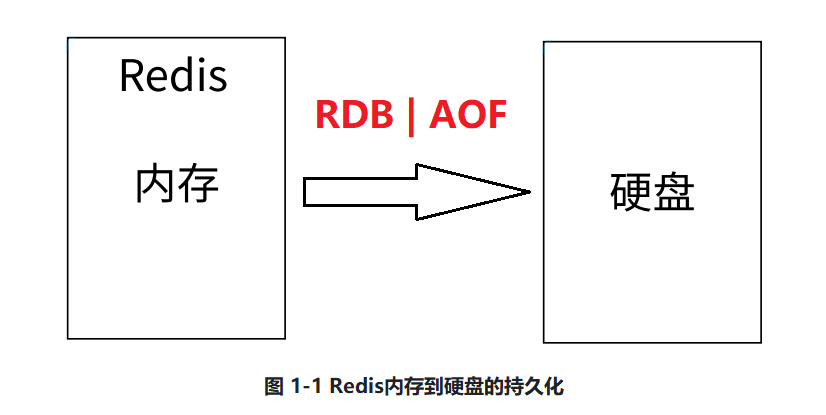
支持持久化(Persistence)
通常看,将数据放在内存中是不安全的,⼀旦发⽣断电或者机器故障,重要的数据可能就会丢失,因此Redis提供了两种持久化⽅式:RDB和AOF,即可以⽤两种策略将内存的数据保存到硬盘中(如图1-1所示),这样就保证了数据的可持久性,后续我们将对Redis的持久化进⾏详细说明。
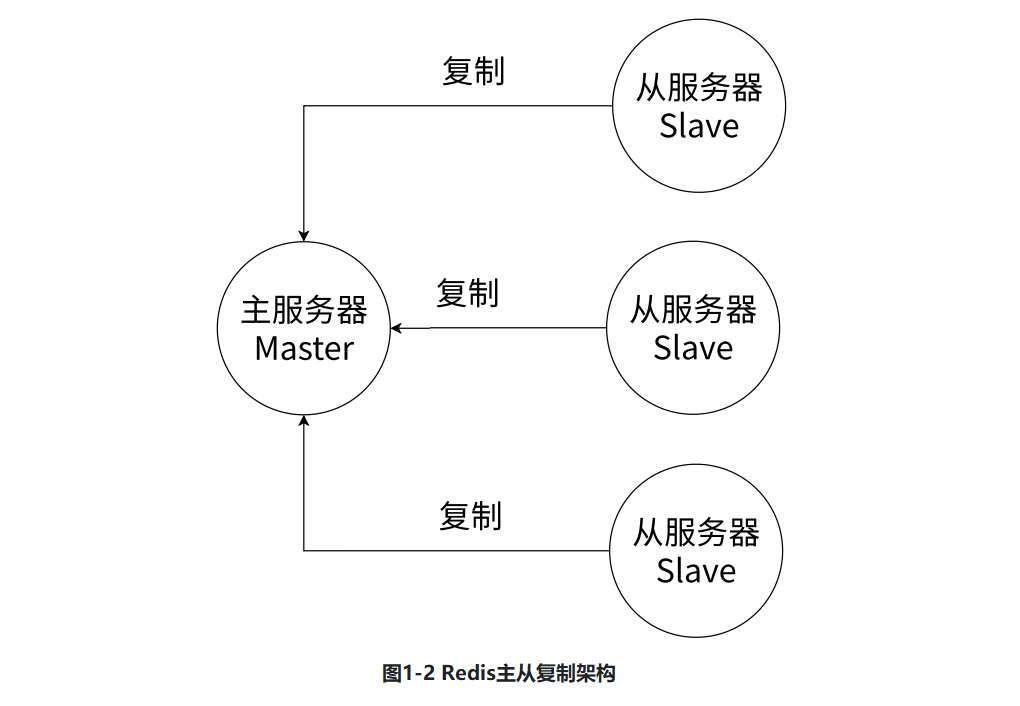
主从复制
Redis提供了复制功能,实现了多个相同数据的Redis副本(Replica)(如图1-2所示),复制功能是分布式Redis的基础。后续我们会对Redis的复制功能进⾏详细演⽰。
高可用(High Availability)和分布式(Distributed)
Redis提供了⾼可⽤实现的Redis哨兵(RedisSentinel),能够保证Redis结点的故障发现和故障⾃动转移。也提供了Redis集群(RedisCluster),是真正的分布式实现,提供了⾼可⽤、读写和容量的扩展性。
三、Redis的使用场景

Redis作为session storage的使用场景:
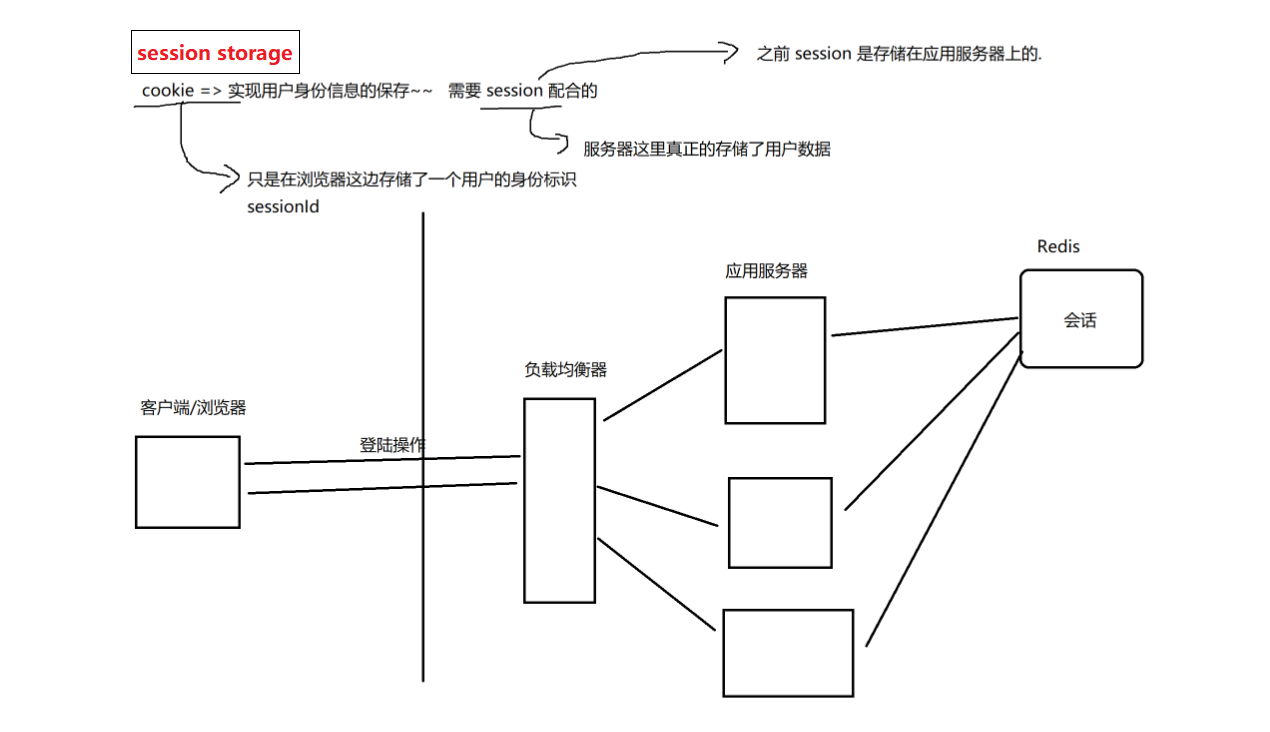
- 想办法让负载均衡器,把同一个用户的请求始终打到同一个机器上(不能轮询了,而是要通过 userid 之类的方式来分配机器)
- 把会话数据单独拎出来,放到一组独立的机器上存储(Redis)(应用程序重启了,会话不丢失)
四、Redis可以做什么
缓存(Cache)
缓存机制⼏乎在所有⼤型⽹站都有使⽤,合理地使⽤缓存不仅可以加速数据的访问速度,⽽且能够有效地降低后端数据源的压⼒。Redis提供了键值过期时间设置,并且也提供了灵活控制最⼤内存和内存溢出后的淘汰策略。可以这么说,⼀个合理的缓存设计能够为⼀个⽹站的稳定保驾护航。排行版系统
排⾏榜系统⼏乎存在于所有的⽹站,例如按照热度排名的排⾏榜,按照发布时间的排⾏榜,按照各种复杂维度计算出的排⾏榜,Redis提供了列表和有序集合的结构,合理地使⽤这些数据结构可以很⽅便地构建各种排⾏榜系统。计数器应用
计数器在⽹站中的作⽤⾄关重要,例如视频⽹站有播放数、电商⽹站有浏览数,为了保证数据的实时性,每⼀次播放和浏览都要做加1的操作,如果并发量很⼤对于传统关系型数据的性能是⼀种挑战。Redis天然⽀持计数功能⽽且计数的性能也⾮常好,可以说是计数器系统的重要选择。社交网络
赞/踩、粉丝、共同好友/喜好、推送、下拉刷新等是社交⽹站的必备功能,由于社交⽹站访问量通常⽐较⼤,⽽且传统的关系型数据不太合适保存这种类型的数据,Redis提供的数据结构可以相对⽐较容易地实现这些功能。消息队列系统
消息队列系统可以说是⼀个⼤型⽹站的必备基础组件,因为其具有业务解耦、⾮实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功能,虽然和专业的消息队列⽐还不够⾜够强⼤,但是对于⼀般的消息队列功能基本可以满⾜。
五、Redis不可以做什么
实际上和任何⼀⻔技术⼀样,每个技术都有⾃⼰的应⽤场景和边界,也就是说Redis并不是万⾦油,有很多合适它解决的问题,但是也有很多不合适它解决的问题。我们可以站在数据规模和数据冷热的⻆度来进⾏分析。
站在数据规模的⻆度看,数据可以分为⼤规模数据和⼩规模数据,我们知道Redis的数据是存放在内存中的,虽然现在内存已经⾜够便宜,但是如果数据量⾮常⼤,例如每天有⼏亿的⽤⼾⾏为数据,使⽤Redis来存储的话,基本上是个⽆底洞,经济成本相当⾼。
站在数据冷热的⻆度,数据分为热数据和冷数据,热数据通常是指需要频繁操作的数据,反之为冷数据,例如对于视频⽹站来说,视频基本信息基本上在各个业务线都是经常要操作的数据,⽽⽤⼾的观看记录不⼀定是经常需要访问的数据,这⾥暂且不讨论两者数据规模的差异,单纯站在数据冷热的⻆度上看,视频信息属于热数据,⽤⼾观看记录属于冷数据。如果将这些冷数据放在Redis上,基本上是对于内存的⼀种浪费,但是对于⼀些热数据可以放在Redis中加速读写,也可以减轻后端存储的负载,可以说是事半功倍。
所以,Redis并不是万⾦油,相信随着我们对Redis的逐步学习,能够清楚Redis真正的使⽤场景。
六、CentOS7安装Redis5
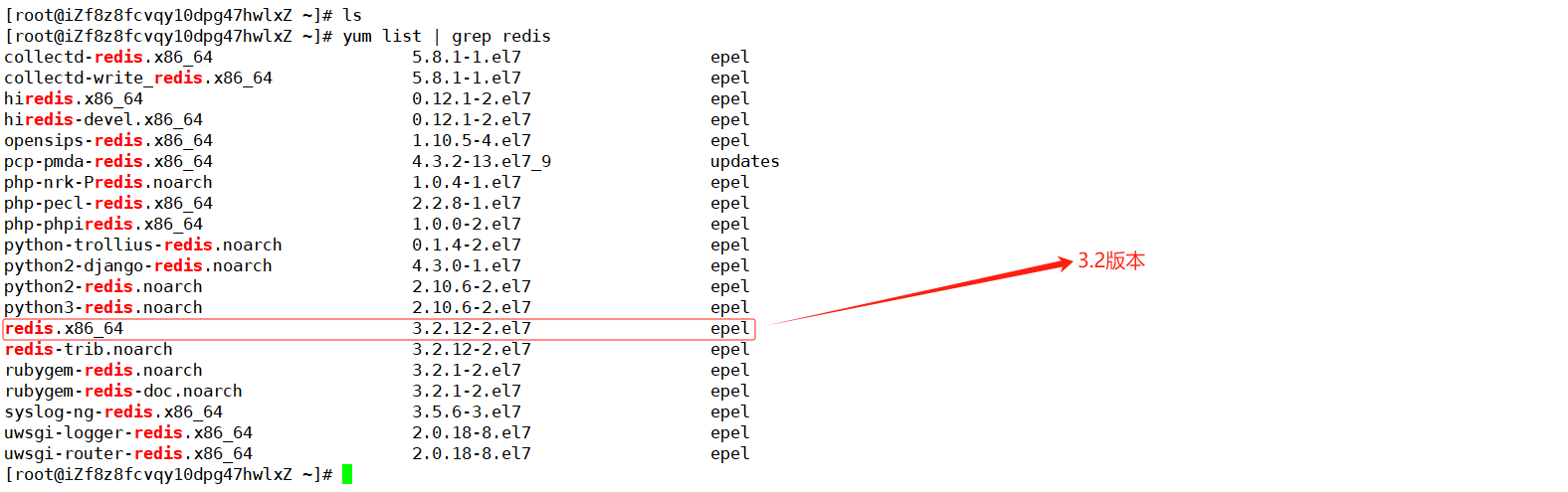
- 查看本机yum中redis默认的版本
yum list | grep redis
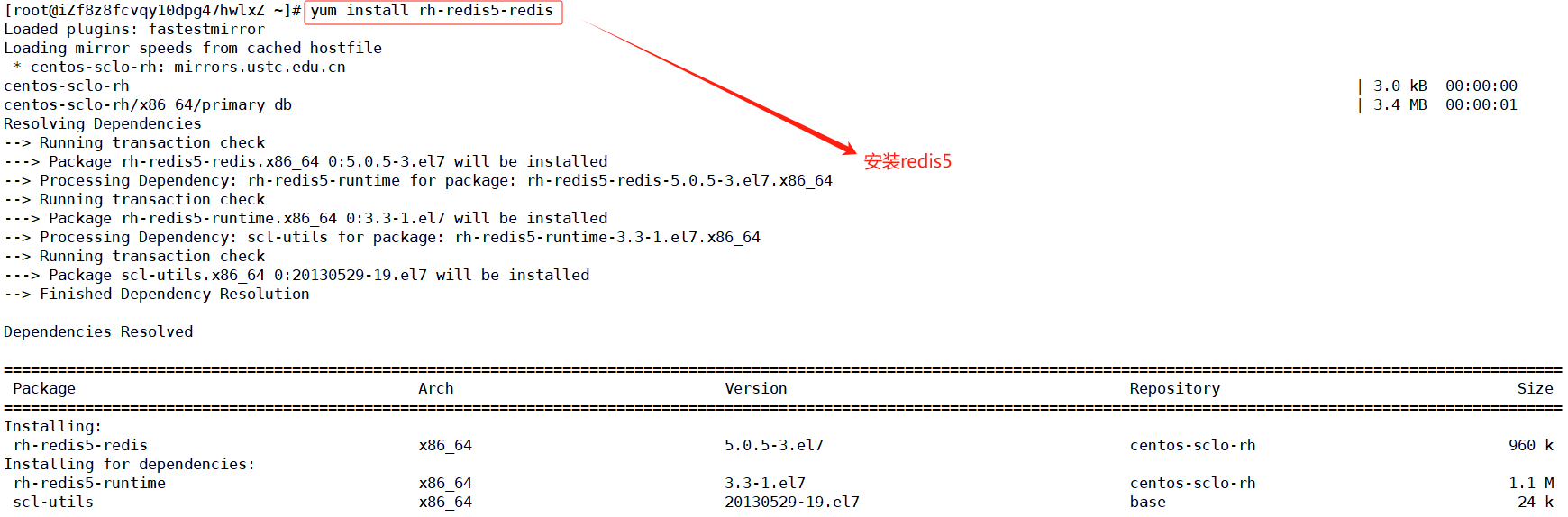
- 先安装
scl源,再安装redis
yum install centos-release-scl-rh

yum install rh-redis5-redis
- 针对可执⾏程序设置符号链接
cd /usr/bin
ln -s /opt/rh/rh-redis5/root/usr/bin/redis-server ./redis-server
ln -s /opt/rh/rh-redis5/root/usr/bin/redis-sentinel ./redis-sentinel
ln -s /opt/rh/rh-redis5/root/usr/bin/redis-cli ./redis-cli

- 针对配置文件设置符号链接
cd /etc/
ln -s /etc/opt/rh/rh-redis5/ ./redis
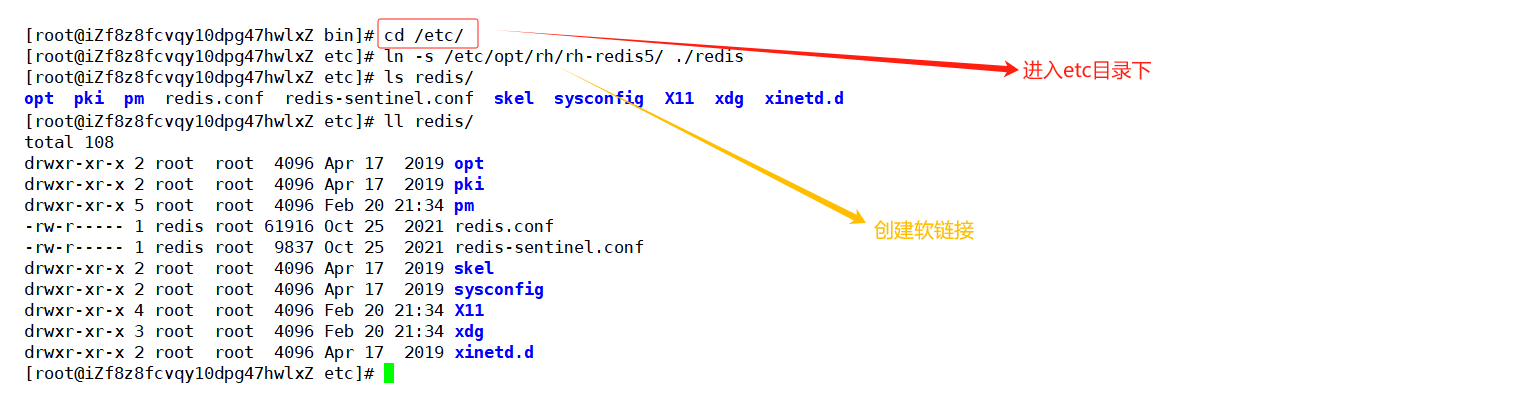
- 修改配置文件
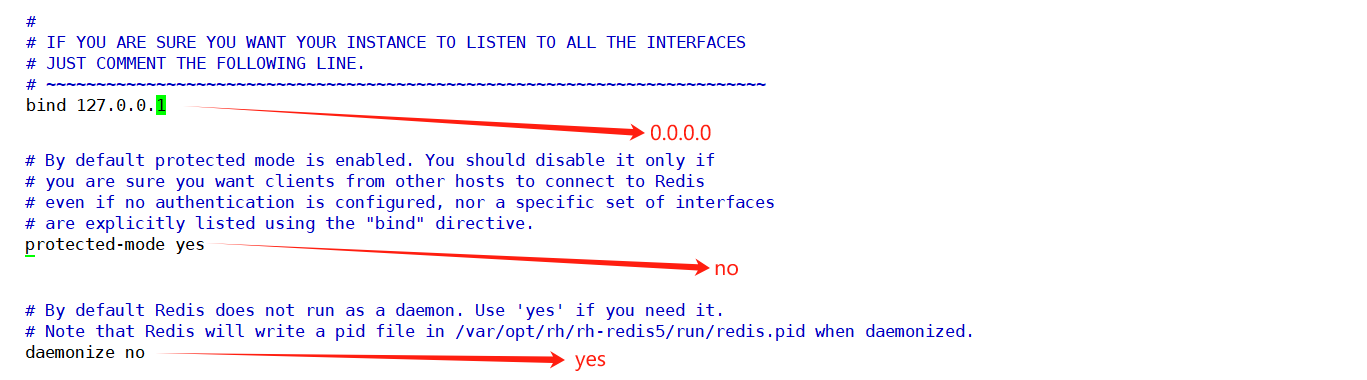
进入/etc/redis/目录下,用vim打开 redis.conf配置文件,进行如下修改
#先进入/etc/redis/目录下
cd /etc/redis/
#使用vim打开redis.conf配置文件
vim redis.conf
#设置ip地址
bind 0.0.0.0
#关闭保护模式
protected-mode no
#启动守护进程
daemonize yes
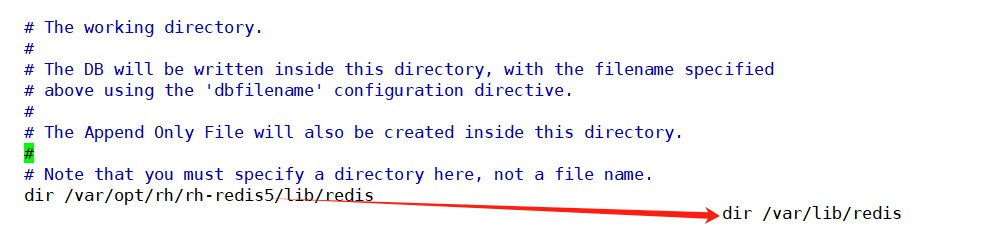
- 设置工作目录
#创建工作目录
mkdir -p /var/lib/redis
#在配置文件中设置工作目录
dir /var/lib/redis
- 设置日志目录
#先创建日志目录
mkdir -p /var/log/redis/
#在配置文件中,设置日志目录
logfile /var/log/redis/redis-server.log

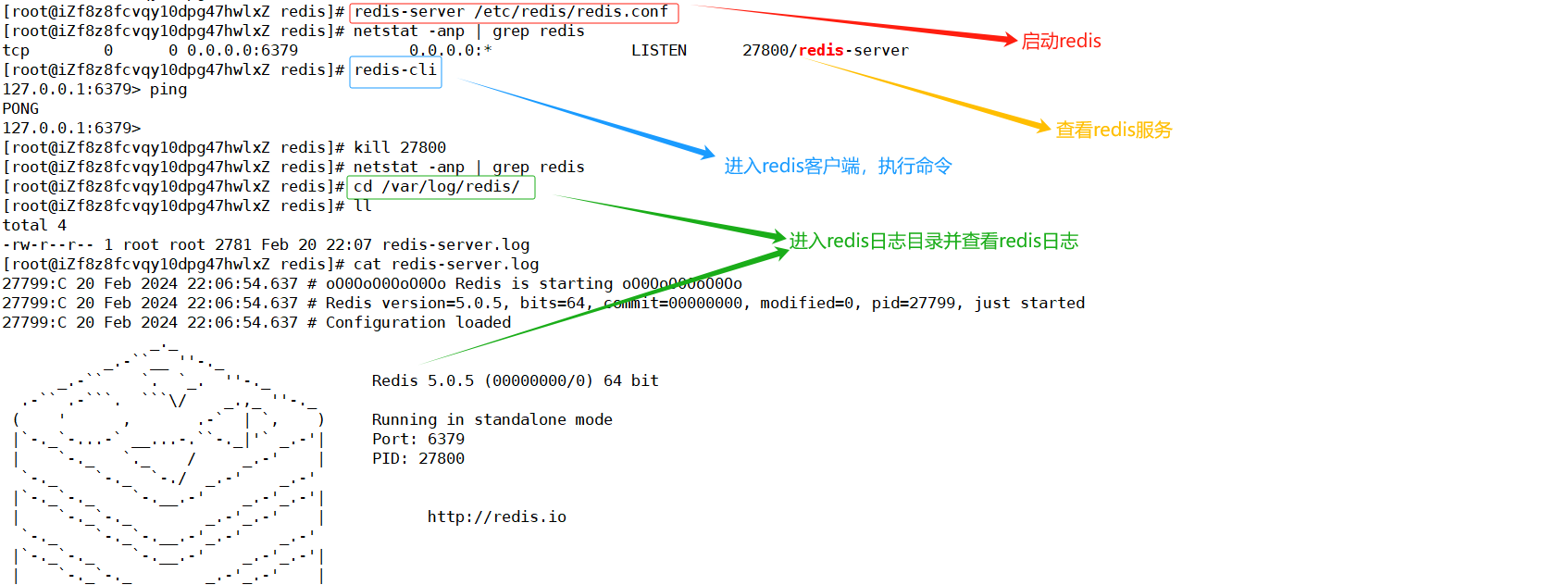
- 启动和停止redis
#启动redis
redis-server /etc/redis/redis.conf
#停止redis
kill redisPID
#查看redis日志
cd /var/log/redis/
cat redis-server.log
七、Redis通用命令
这里知识介绍几个常用的命令,如果想要了解更多,可以去redis官方文档进行查阅
get和set:插入或获取key-value
set命令
- 功能:
存储K-V,set可以填写两个参数(key-value),参数类型必须是字符串,当然我们在敲命令时不需要刻意加''或者""。
get命令
- 功能
根据Key获取Value。get后面跟key,就可以得到value,并且是带双引号的,是字符串类型的。
如果key不存在,就会返回nil,和null一个意思。
[root@iZf8z8fcvqy10dpg47hwlxZ ~]# redis-cli
127.0.0.1:6379> set key1 value1
OK
127.0.0.1:6379> set key2 value2
OK
127.0.0.1:6379> set 'key3' 'value3'
OK
127.0.0.1:6379> get key1
"value1"
127.0.0.1:6379> get key2
"value2"
127.0.0.1:6379> get key3
"value3"
127.0.0.1:6379> get key100
(nil)
keys:用来查询当前服务器上匹配的key,可以通过一些特殊符号(通配符)来筛选key
- 语法
KEYS pattern
*:匹配任意字符序列(0个或者多个任意字符)KEYS *匹配所有的键,展示当前服务器上所有的keyKEYS prefix*匹配以 “prefix” 开头的键,如 “prefix123”、“prefixabc”。KEYS *suffix匹配以 “suffix” 结尾的键,如 “abcsuffix”、“defsuffix”
?:匹配单个字符KEYS key?匹配以 “key” 开头,并且后面跟着一个字符的键,如 “key1”、“keyA”。
[字符 abc]:匹配在括号内的任一字符- KEYS key[123] 匹配以 “key” 开头,并且后面跟着 “1"或"2” 或 “3” 的键,如 “key1”、“key2”、“key3”。
[范围 a-b]:匹配在范围内的任一字符KEYS key[1-5]匹配以 “key” 开头,并且后面跟着数字1~5任意一个数字的键,如 “key1”、“key2”、“key3”。KEYS k[a-b]ey匹配以 “k” 开头,并且后面跟着字母a-b任意一个字母的键,如 “kaeyd”、“kbey”。
[^字符]:匹配不在括号内的任一字符KEYS key[^abc]匹配以 “key” 开头,并且后面跟着的不是 “a"或"b” 或 “c” 的字符的键。
127.0.0.1:6379> set hello 1
OK
127.0.0.1:6379> set hallo 1
OK
127.0.0.1:6379> set hbllo 1
OK
127.0.0.1:6379> set hllo 1
OK
127.0.0.1:6379> set heeeeeeello 1
OK
127.0.0.1:6379> keys h?llo
1) "hello"
2) "hallo"
3) "hbllo"
127.0.0.1:6379> keys h*llo
1) "hello"
2) "hllo"
3) "hallo"
4) "hbllo"
5) "heeeeeeello"
127.0.0.1:6379> keys h[abe]llo
1) "hello"
2) "hallo"
3) "hbllo"
127.0.0.1:6379> keys h[^ae]llo
1) "hbllo"
127.0.0.1:6379> keys h[a-e]llo
1) "hello"
2) "hallo"
3) "hbllo"
127.0.0.1:6379> keys *
1) "backup4"
2) "backup1"
3) "key1"
4) "key2"
5) "key3"
6) "hello"
7) "hllo"
8) "backup2"
9) "hallo"
10) "hbllo"
11) "backup3"
12) "heeeeeeello"
注意:keys 的时间复杂度是O ( N ),因为需要遍历所有的key,然后匹配出符合要求的键,所以在生产环境当中一般禁止使用keys,尤其是keys *,它是匹配redis中的所有键,由于生产环境中key非常多,redis是一个单线程的服务器,就会导致执行keys *时间非常长,那么redis服务器就被阻塞,无法为其它客户端提供服务,给用户体验造成影响。
redis的一个经典用途就是作为数据冷热分离的热点数据缓存,热点数据首先是去查redis的,如果redis被阻塞了,此时其它的查询redis操作就超时了,此时这些请求只能去查数据库了,大量的数据同时请求数据库的查询,可能会导致过载,数据库也无法正常提供服务了,整个系统基本就处于瘫痪状态。
EXISTS用来检查给定键是否存在于数据库中。接受一个或多个键作为参数,并返回存在键的数量。
- 时间复杂度:
O(1) - 命令语法
EXISTS key [key ...]
127.0.0.1:6379> EXISTS hello
(integer) 1
127.0.0.1:6379> exists hello hallo hbllo
(integer) 3
因为redis是基于客户端-服务器架构的,通过网络通信的中间件。因此上述分开查询key是否存在和同时检查多个键是否存在是有区别的,分开查询的写法,会产生更多次数的请求响应,也即网络通信。和直接操作内存来说,网络通信成本比较高,效率比较低,而同时检查多个键只需要一次请求响应,减少网络通信。
所以redis支持一个命令能够操作多个key来减少网络通信。
DEL删除指定的key,和 EXISTS命令相同,也可以支持操作多个key,返回删除key的个数。
- 时间复杂度:
O(1) - 命令语法
DEL key [key ...]
127.0.0.1:6379> del backup4
(integer) 1
127.0.0.1:6379> del backup1
(integer) 1
127.0.0.1:6379> del key1 key2 key3
(integer) 3
在redis当中删除,和mysql中的删库删表来说危险性比较低,因为redis是作为缓存,如果丢失少量的数据,问题不大,而MySQL不能丢失数据,丢失了数据就可能后续查不到了。
但是如果丢失大批的数据,那么客户端来的查询先去redis当中进行查找,找不到就会到MySQL当中进行查找,就可能会导致MySQL过载,导致系统瘫痪。
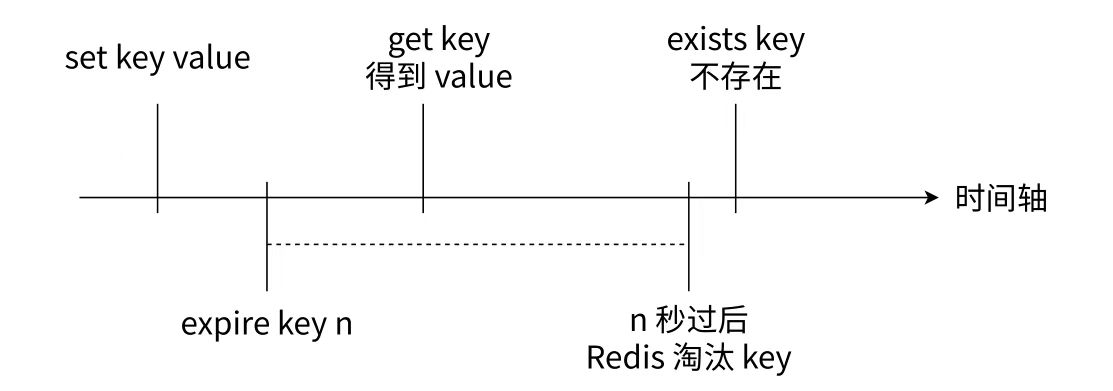
EXPIRE 用于为键设置过期时间,接受两个参数:默认以秒为单位的过期时间。
- 设置键的过期时间,过期时间到达后,该键自动被删除。
- 时间复杂度:
O(1) - 命令语法
EXPIRE key seconds
127.0.0.1:6379> set hello 111
OK
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> get hello
"111"
127.0.0.1:6379> get hello
(nil)
基于redis实现的分布式锁,为了避免出现不能正确解锁的情况,加锁时通常会设置一个过期时间,时间到达之后会自动解锁。
TTL检查键过期时间
- 返回:要检查的键剩余过期时间,以秒为单位。
- 如果键不存在,或者没有设置过期时间,则返回-1
- 如果键已经过期,则返回-2
- 时间复杂度:
O(1) - 命令语法
TTL key
127.0.0.1:6379> ttl hallo
(integer) -1
127.0.0.1:6379> set hello 111
OK
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 6
127.0.0.1:6379> ttl hello
(integer) 5
127.0.0.1:6379> ttl hello
(integer) 4
127.0.0.1:6379> ttl hello
(integer) 3
TYPE用于获取指定键的数据类型
可能返回的结果为:none string list hash set zset stream (redis作为消息队列的时候会使用这个类型作为value)。
- 命令语法
TYPE key
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> type key1
string
127.0.0.1:6379> lpush key2 111 222 333
(integer) 3
127.0.0.1:6379> type key2
list
127.0.0.1:6379> sadd key3 111 222 333
(integer) 3
127.0.0.1:6379> type key3
set
127.0.0.1:6379> hset key4 field1 value1
(integer) 1
127.0.0.1:6379> type key4
hash