1 背景
dom4j,Jdom,w3c dom解析xml文档时速度比较慢,因此选择自己写代码解析xml文档。
2 思路
首先,对xml文件进行分析,熟悉标签;
然后,切分文档为不同的块。我们要对文档中的书签进行替换,因此需要将文档切分为书签块和非书签块;
还有就是表格中行的循环,比如当前取出的数据是一个list,我们需要根据list的大小来生成表格中的行数,并对此表格中的书签进行数据替换(如下图),此时,需要将文档进切分为“循环的行块”和非行块。

除此之外,还有需删除的行块,表示该行需要删除,一般用循环的行在合并单元格之后的表格设计上。
最后,对文档中切分好的块进行文档构建。
优化:边切分边写入,减少内存的使用
3 编码
3.1 块切分器

(1)书签切分器BookmarkCutter

(2)行切分器RowBookmarkCutter
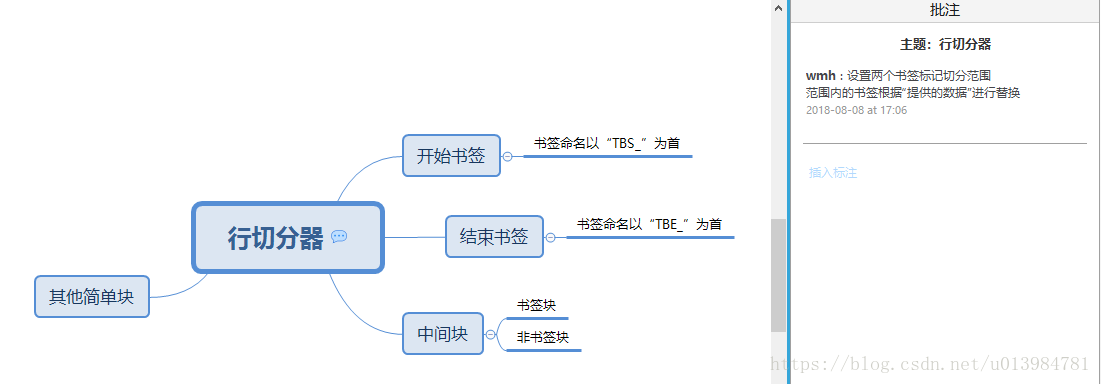
(3)不需处理的书签块(skipCutter)
(5)整个表格循环切分器
 3.2 构件xml文档
3.2 构件xml文档
文档切分完成后,分别对不同的块中的进行写入,构件成一个完整的文档。

其中最主要的写入是“书签块的写入”,由于书签块分为“头”“尾”“身体”,身体里包含“文字块”和“非文字”块,书签替换时只需将数据替换到第一个文字块中即可,之后的文字块忽略不计(因为替换的文字很难选择文字块中的某一块的样式,所以选择取第一个文字块的样式)
附上代码:https://download.csdn.net/download/u013984781/10593416