目录
一、SQLite 语句基础
1、创建表:create 语句
2、创建表:create 语句 (设置主键)
编辑
3、查看表
4、修改表:alter
5、删除表:drop table 语句
6、插入新行:insert into 语句--全部赋值
7、插入新行:insert into 语句--部分赋值
8、修改表中的数据:update 语句
9、删除表中的数据:delete 语句
10、查询:select 语句(基础)
11、匹配条件语法:(提高)
12、order by 语句
13、复制表以及修改表结构
14、事务
二、SQLite语句进阶
1、函数和聚合
2、数据分组 group by
3、过滤分组 having
4、约束
三、联结表(多表操作)
四、视图(虚拟的表 )
五、触发器
六、查询优化--索引
SQLite 是一个开源的、内嵌式的关系型数据库,第一个版本诞生于 2000 年 5 月,目前最高版本为 SQLite3。
下载地址:http://www.sqlite.org/download.html 学习网站:http://www.runoob.com/sqlite/sqlite-tutorial.html
安装方法(ubantu系统下):
字符界面:
sudo apt-get install sqlite3
图形界面:
sudo apt-get install sqliteman
SQLite 特性: 1、零配置 5、灵活 2、可移植 6、自由的授权 3、紧凑 7、可靠 4、简单 8、易用
一、SQLite 语句基础
SQL 是一种结构化查询语言(Structured Query Language)的缩写,SQL 是一种专门用来与数据库通信的语言。 SQL 目前已成为应用最广的数据库语言。
SQL 已经被众多商用数据库管理系统产品所采用,不同的数据库管理系统在其实践过程中都对 SQL 规范作了 某些改编和扩充。故不同数据库管理系统之间的 SQL 语言不能完全相互通用
SQLite 数据类型:
一般数据采用固定的静态数据类型,而 SQLite 采用的是动态数据类型,会根据存入值自动判断。 SQLite 具有以下五种基本数据类型:
1、integer:带符号的整型(最多 64 位)。
2、real:8 字节表示的浮点类型。
3、text:字符类型,支持多种编码(如 UTF-8、UTF-16),大小无限制。
4、blob:任意类型的数据,大小无限制。 BLOB(binary large object)二进制大对象,使用二进制保存数
5、null:表示空值。
对数据库文件 SQL 语句:
1、创建、打开数据库
sqlite3 *.db 提示: 当*.db 文件不存在时,sqlite 会创建并打开数据库文件。 当*.db 文件存在时,sqlite 会打开数据库文件。
2、退出数据库命令: .quit 或 .exit
其他语句
1、查看表:.table
2、查看表及其结构属性:.schema [表名]
2、左对齐列模式: .mode colum
3、显示表头:.header on

SQL 的语句格式:
所有的 SQL 语句都是以分号结尾的,SQL 语句不区分大小写。两个减号“--”则代表注释。 关系数据库的核心操作:
一、创建、修改、删除表
二、添加、修改、删除行
三、查表
1、创建表:create 语句
语法:create table 表名称 (列名称 1 数据类型, 列名称 2 数据类型, 列名称 3 数据类型, ...);
创建一表格该表包含 3 列,列名分别是:“num”、“name”、“addr”。 在终端下输入:

2、创建表:create 语句 (设置主键)
在用 sqlite 设计表时,每个表都可以通过 primary key 手动设置主键,每个表只能有一个主键,设置为 主键的列数据不可以重复。
语法: create table 表名称 ( 列名称 1 数据类型 primary key, 列名称 2 数据类型, 列名称 3 数据类型, ...);

3、查看表
1、查看所有表:.table
2、查看数据表的属性结构: .schema [表名]
2、切换表的查看方式: .mode colum
3、显示表头:.header on
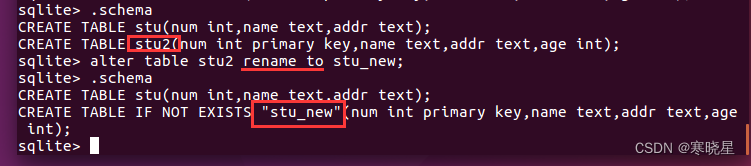
4、修改表:alter
在已有的表中添加列以及修改表名。删除表和修改已存在的列-sqlite3 暂不支持
语法: (添加列) alter table 表名 add 列名 数据类

语法: (修改表名) alter table 表名 rename to 新表名
5、删除表:drop table 语句
用于删除表(表的结构、属性以及表的索引也会被删除)
语法: drop table 表名称;
6、插入新行:insert into 语句--全部赋值
给一行中的所有列赋值。
语法: insert into 表名 values (列值 1, 列值 2, 列值 3,列值 4, ...);
注意: 当列值为字符串时要加上‘ ’号。

7、插入新行:insert into 语句--部分赋值
给一行中的部分列赋值
语法: insert into 表名 (列名 1, 列名 2, ...) values (列值 1, 列值 2, ...);
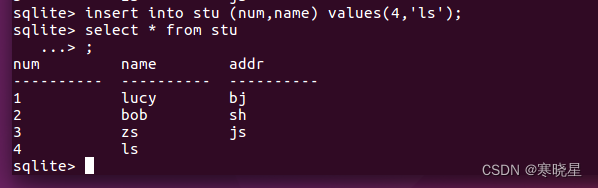
8、修改表中的数据:update 语句
使用 where 根据匹配条件,查找一行或多行,根据查找的结果修改表中相应行的列值(修改哪一列由 列名指定)。
语法: update 表名 set 列 1 = 值 1 [, 列 2 = 值 2, ...] [匹配条件];
匹配条件:where 子句
where 子句用于规定匹配的条件。

匹配条件语法:(基础) where 列名 操作符 列值
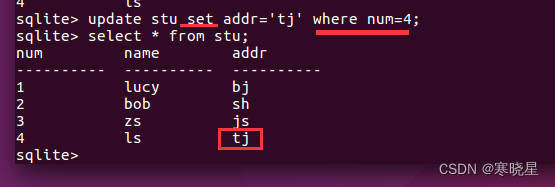
注意: 当表中有多列、多行符合匹配条件时会修改相应的多行。当匹配条件为空时则匹配所有。
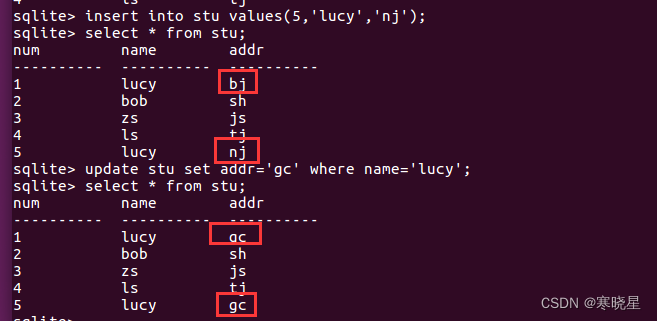
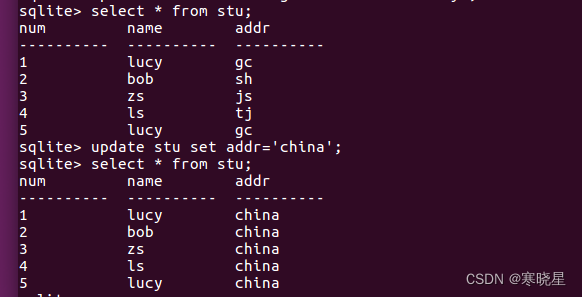
9、删除表中的数据:delete 语句
使用 where 根据匹配条件,查找一行或多行,根据查找的结果删除表中的查找到的行。
语法:delete from 表名 [匹配条件];

注意: 当表中有多列、多行符合匹配条件时会删除相应的多行。
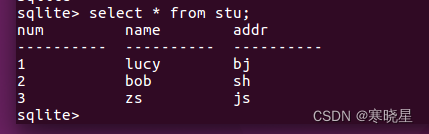
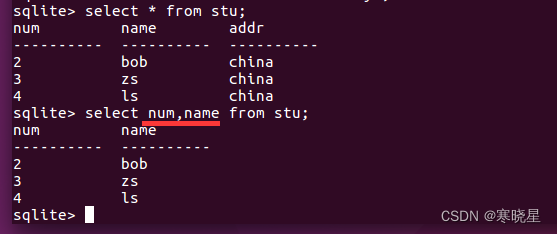
10、查询:select 语句(基础)
用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
语法: 1、select * from 表名 [匹配条件];
2、select 列名 1[, 列名 2, ...] from 表名 [匹配条件];
提示:星号(*)是选取所有列的通配符。
11、匹配条件语法:(提高)
数据库提供了丰富的操作符配合 where 子句实现了多种多样的匹配方法。
如:
一、in 操作符
二、and 操作符
三、or 操作符
四、between ...and ...操作符
五、like 操作符
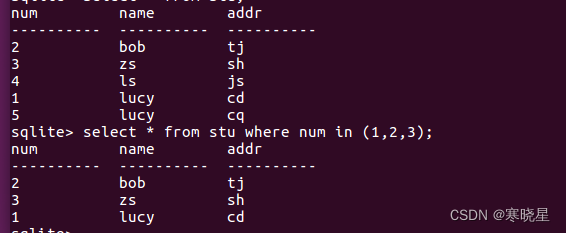
六、not 操作符 in 允许我们在 where 子句中规定多个值。
例: in 允许我们在 where 子句中规定多个值。
匹配条件语法: where 列名 in (列值 1, 列值 2, ...)
1、select * from 表名 where 列名 in (值 1, 值 2, ...);
2、select 列名 1[,列名 2,...] from 表名 where 列名 in (列值 1, 列值 2, ...)
操作符 between A and B 会选取介于 A、B 之间的数据范围。
这些值可以是数值、文本或者日期。
注意: 不同的数据库对 between A and B 操作符的处理方式是有差异的。
(1)有些数据库包含 A 不包含 B。
(2)有些包含 B 不包含 A。
(3)有些既不包括 A 也不包括 B。
(4)有些既包括 A 又包括 B
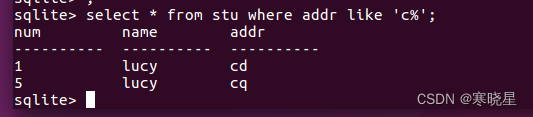
like 用于模糊查找。
匹配条件语法: where 列名 like 列值
1、若列值为数字 相当于列名=列值。

2、若列值为字符串 可以用通配符“%”代表缺少的字符(一个或多个)。
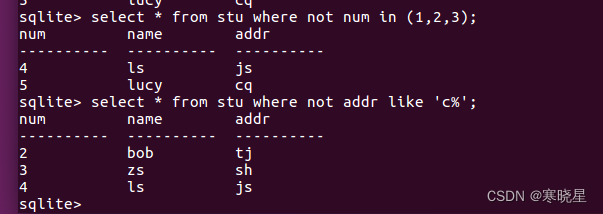
not 可取出原结果集的补集。
匹配条件语法:where 列名 not in 列值等
例:
- where 列名 not in (列值 1, 列值 2, ...)
- where not (列 1 = 值 1 [and 列 2 = 值 2 and ...])
- where not (列 1 = 值 1 [or 列 2 = 值 2 or ...])
- where 列名 not between A and B
- where 列名 not like 列值
12、order by 语句
根据指定的列对结果集进行排序。 默认按照升序对结果集进行排序,可使用 desc 关键字按照降序对结果集进行排序。
例: 升序 select * from 表名 order by 列名;
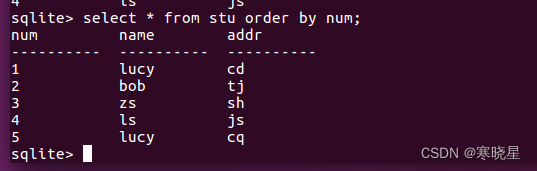
降序 select * from 表名 order by 列名 desc;
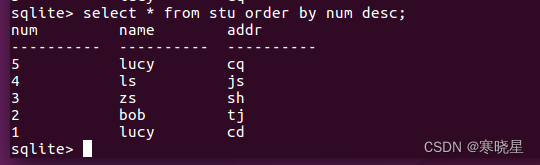
13、复制表以及修改表结构
(1) 复制一张表:
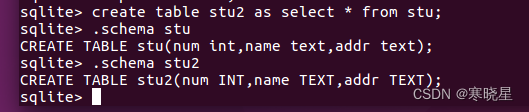
(2)复制 一张表的部分内容:
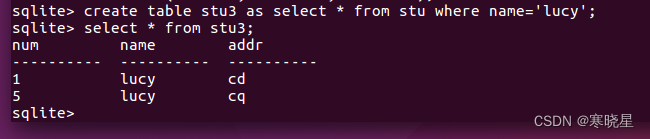
(3)修改表的结构
第一步,创建新表:
create table stu4(num int primary key,name text,addr text);
第二部,导入数据: (主键不能重复)
insert into stu4(num,name,addr) select num,name,addr from stu;
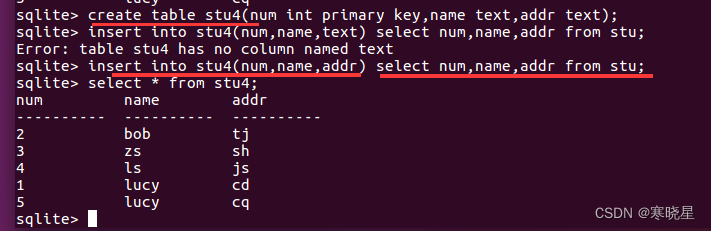 第三步,删除旧表,修改新表名为旧表名:
第三步,删除旧表,修改新表名为旧表名:
sqlite> drop table stu;
sqlite> alter table stu4 rename to stu;

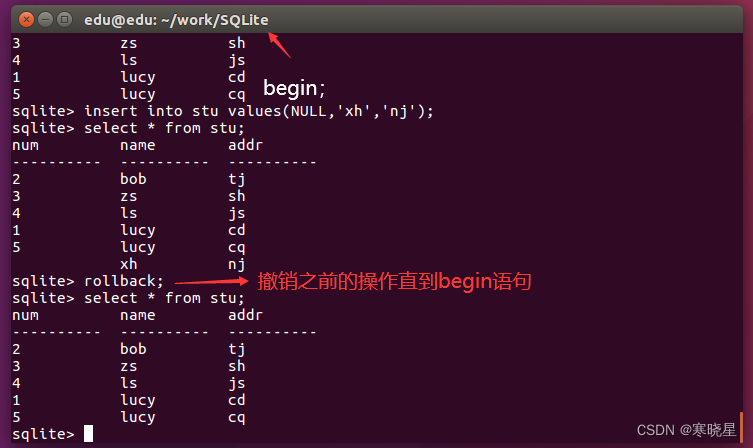
14、事务
事务(Transaction)可以使用 BEGIN TRANSACTION 命令或简单的 begin 命令来启动。此类事务通常会持续执行下 去,直到遇到下一个 COMMIT 确认命令或 ROLLBACK 回滚命令。不过在数据库关闭或发生错误时,事务处理也会回滚。以下是启动一 个事务的简单语法:
在 SQLite 中,默认情况下,每条 SQL 语句自成事务。
- begin:开始一个事务,之后的所有操作都可以取消
- commit:使 begin 后的所有命令得到确认。
- rollback:取消 begin 后的所有操作。

二、SQLite语句进阶
1、函数和聚合
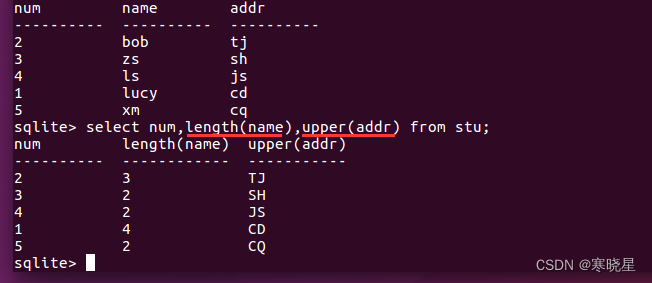
函数: SQL 语句支持利用函数来处理数据,函数一般是在数据上执行的,它给数据的转换和处理提供了方便
常用的文本处理函数:
- length() 返回字符串的长度
- lower() 将字符串转换为小写
- upper() 将字符串转换为大写
语法:select 函数名(列名) from 表名;
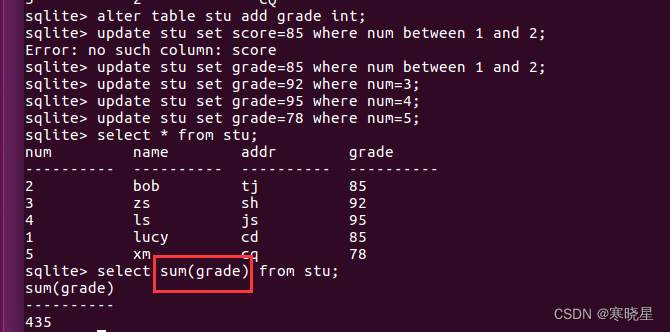
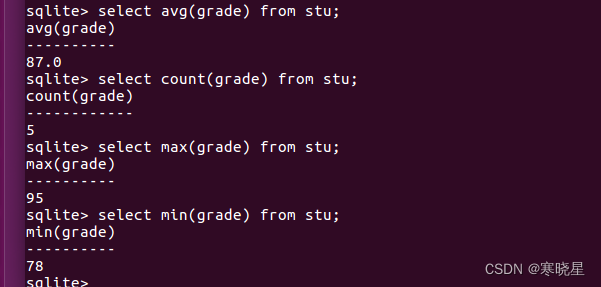
常用的聚集函数: 使用聚集函数,用于检索数据,以便分析和报表生成
- avg() 返回某列的平均值
- count() 返回某列的行数
- max() 返回某列的最大值
- min() 返回某列的最小值
- sum() 返回某列值之和
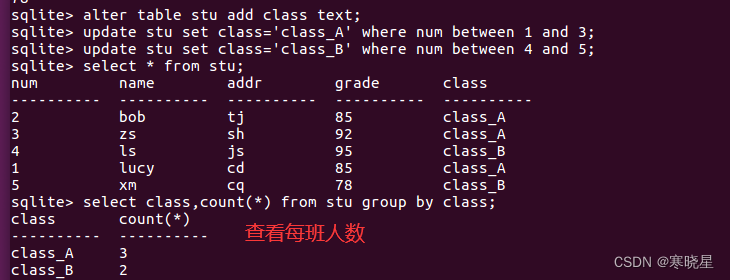
2、数据分组 group by
分组数据,以便能汇总表内容的子集,常和聚集函数搭配使用。例如查询每个班级中的人数、平均分
语法:select 列名 1[, 列名 2, ...] from 表名 group by 列
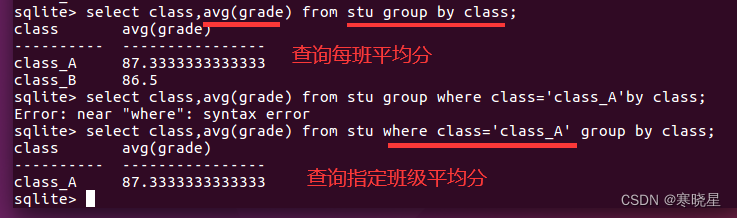
3、过滤分组 having
除了能用 group by 分组数据外,还可以包括哪些分组,排除哪些分组。例如:查看班级平均分大于 90 的班级 通过 having 实现
语法:select 函数名(列名 1)[, 列名 2, ...] from 表名 group by 列名 having

4、约束
管理如何插入或处理数据库数据的规则。
常用约束分类:主键约束、唯一约束、检查约束。
主键:
- 惟一的标识一行(一张表中只能有一个主键)
- 主键应当是对用户没有意义的(常用于索引)
- 永远不要更新主键,否则违反对用户没有意义原则
- 主键不应包含动态变化的数据,如时间戳、创建时间列、修改时间列等
- 主键应当有计算机自动生成(保证唯一性)
语法: create table 表名称 ( 列名称 1 数据类型 primary key, 列名称 2 数据 类型,......)

唯一约束:
- 用来保证一个列(或一组列)中数据唯一,类似于主键,但跟主键有区别
- 表可包含多个唯一约束,但只允许一个主键
- 唯一约束列可修改或更新
- 创建表时,通过 unique 来设置
语法: create table 表名 (列名称 1 数据类型 unique[,列名称 2 数据类型 unique,...]);
检查约束:
- 用来保证一个列(或一组列)中的数据满足一组指定的条件。
- 指定范围,检查最大或最小范围,通过 check 实现
create table 表名 (列名 数据类型 check (判断语句)) ;
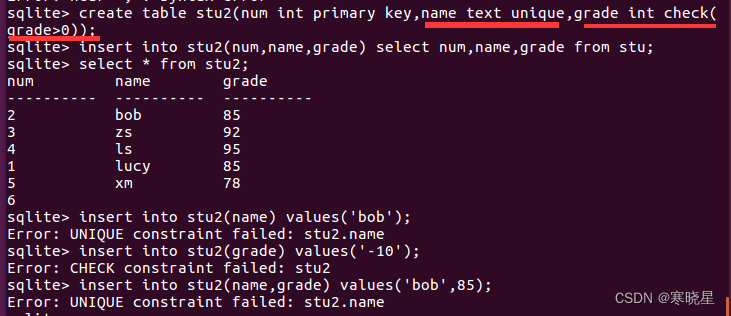
主要区别:
主键约束:主要区分内容相同的行,只能有一列
唯一约束:主要保证被约束的列所有元素不能重复出现,可以设置多列检查约束:主要约束插入或修改的元素合法性,检查条件自己设定
三、联结表(多表操作)
保存数据时往往不会将所有数据保存在一个表中,而是在多个表中存储,联结表就是从多个表中查询数据。
在一个表中不利于分解数据,也容易使相同数据出现多次,浪费存储空间;使用联结表查看各个数据更直观, 这使得在处理数据时更简单。
使用联结: 通过 select 语句将要联结的所有表以及它们如何关联
常用语句: select 列名 1,列名 2,.. from 表 1,表 2,.. where 判断语句
创建两张表:persons(学生信息) 和 grade(学生成绩),并插入相应的数据并联结成表:
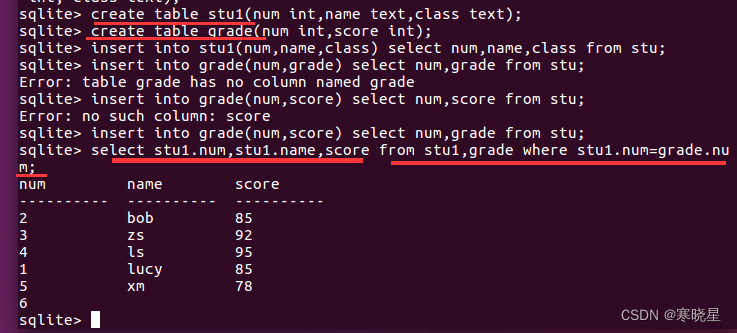
注:
在联结两个表时,实际上是将第一个表中的每一行与第二个表中每一行配对,where 子句作为过滤条件, 只有满足条件的才显示出来,匹配语句(连接条件): stu.num= grade.num。
当前面指定列名二义性时,需要通过完全限定名引用:完全限定列名,用一个点(.)分隔表名和列名
select 语句中可以联结的表的数目没有限制
四、视图(虚拟的表 )
重用 SQL 语句 简化复杂的 SQL 操作(如:多表查询)
创建视图: 视图不包含数据,因此在每次使用视图时,实际上都必须执行查询语句,从返回结果信息中再检索 视图与表一样,必须唯一命名(通过.tables 和.schema 查看)
语法:create view 视图名 as 语句;
例:将上面联结表操作创建成视图并查看:
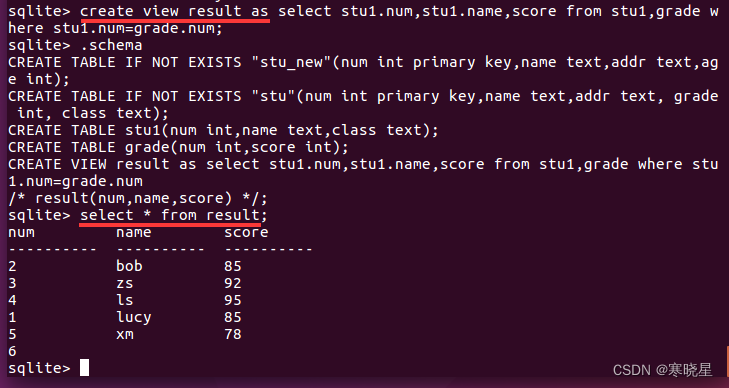
删除视图:
语法:drop view 视图
总结:
1、视图不包含数据,因此在每次使用视图时,实际上都必须执行查询语句
2、视图相当于 创建视图的时候 as 后面 SQL 语句查询得到的结果集合。
3、从返回结果信息(视图)中再检索视图与表一样
五、触发器
SQLite 的触发器是数据库的回调函数,它会在指定的数据库事件发生时自动执行调用
调用时机:
- 1、只有每当执行 delete,insert 或 update 操作时,才会触发,并执行指定的一条或多条 SQL 语句。
- 2、触发器常用于保证数据一致,以及每当更新或删除表时,将记录写入日志表
创建触发器:
语法: create trigger 触发器名 [before|after] [insert|update|delete] on 表名begin 语句; end
例1:delete操作
create trigger tg_delete after delete on persons begin delete from grade where id=old.id; end;
注意: old.id 等价于 stu.id,但此处不能写 stu.id,old.id 代表删除行的 id(id 代表两个表的关联列)
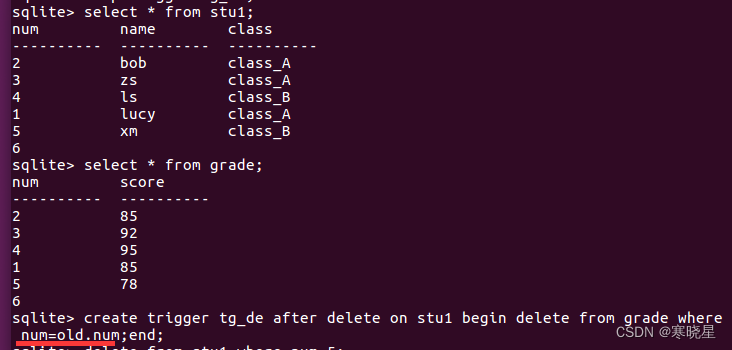
说明: 当执行:delete from stu where id=1;语句时,事件触发,执行 begin 与 end 之间的 SQL 语句(即回调函数)
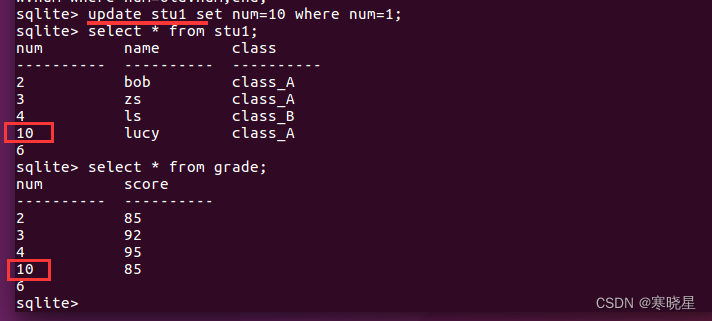
 例2:update操作
例2:update操作
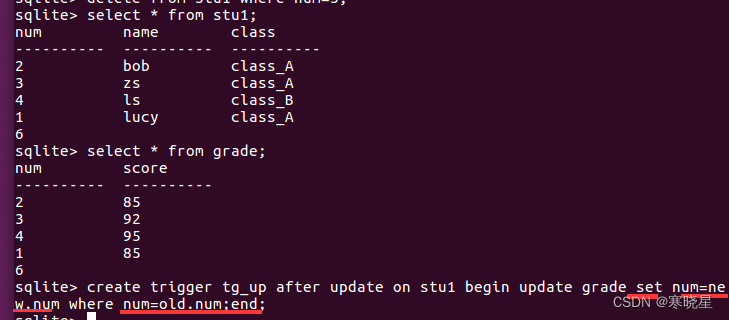
例3:写入日志
注意:datetime(‘now’)获取到当前系统的时间 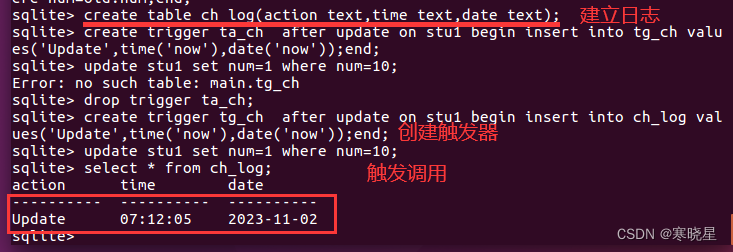
查看触发器和删除触发器:
- 查看:select name from sqlite_master where type='trigger' and tbl_name='表名';
- 删除:drop trigger 触发器
六、查询优化--索引
数据库中往往存储了大量的数据,普通查询的默认方法是调用顺序扫描。例如这样一个查询:select * from table1 where id=10000;如果没有索引,必须遍历整个表,直到 ID 等于 10000 的这一行被找到为止 为了提高查询的效率,可以使用索引 。
索引是对数据库表中一列或多列的值进行排序的一种结构,经过某种算法优化,使用索引可快速访问数据库表中的特定信息 ,使查找次数要少的多。
索引的缺点:
- 索引数据可能要占用大量的存储空间,因此并非所有数据都适合索引
- 索引改善检索操作的性能,但降低了数据插入、修改和删除的性能
创建索引: 语法:create index 索引名 on 表名(列名);
查看索引:.indices
删除索引:drop index 索引名;
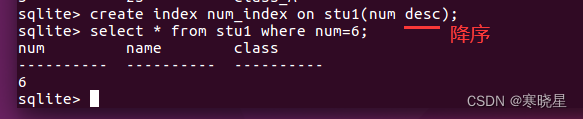
索引创建注意:
1、在作为主键的列上创建索引
2、在经常需要排序的列上创建索引
3、在经常使用在 WHERE 子句中的列上面创建索引,加快条件的判断速度
索引避免使用情况:
1、表的数据量不大
2、表的大部分操作不是查询3、大量出现NULL值的情况