Django路由层(反向解析、路由分发、命名空间、路径转换)
目录
- Django路由层(反向解析、路由分发、命名空间、路径转换)
- 路由配置
- 反向解析
- 前端用法
- 后端用法
- 反向解析的本质
- 路由分发
- 用法示例
- 分发时遇到的问题
- 解决方案1
- 解决方案2
- 命名空间
- 应用命名空间app_name
- 实例命名空间namespace
- 路径转换
- 五种转换器
路由配置
Django中默认的路由配置在创建项目的urls.py文件中
from django.contrib import admin
from django.urls import path
from django.conf.urls import include
urlpatterns = [
path('admin/', admin.site.urls),
]
每当创建新的app项目并且创建新的视图函数(类)时,记得都要在urls.py中添加路径
# views.py
def index(request):
return render(request,'home.html')
# urls.py
urlpatterns = [
path('admin/', admin.site.urls),
path('index/',views.index)
]
'index/':路径名,也就是浏览器输入的url
views.index:解析路径的视图文件中的具体函数
反向解析
前端使用连接跳转是可能会在原路径的基础上进行添加,这种情况是一定会报错的,如下
{#aaa.html#}
<body>
<p>你好,我是{% url 'aaa' %}</p>
</body>
# views.py
def aaa(request):
return render(request,'aaa.html')
# urls.py
path('aaa/',views.aaa),
报错:

解决方法:
# urls.py
path('aaa/',views.aaa,name='aaa'),

前端用法
<p>{% url 'aaa' %}</p>
后端用法
from django.urls import reverse
def aaa(request):
print(reverse('aaa'))
# 输出:/aaa/
反向解析的本质
给路由取一个别名,可以让项目的其他地方在调用该别名时正确的解析其路由地址
路由分发
路由分发是Web开发中约定俗成的代码规范,即每个app都拥有自己的路由解析文件:
- templates文件夹(名字可以随意改)
- urls.py
- static文件夹
用法示例
项目默认的路由配置
urlpatterns = [
path('admin/', admin.site.urls),
path('index/', views.index),
path('home/', views.home,name='home'),
path('register/', views.register,name='register'),
path('test/', views.test,name='test'),
]
然后直接在app中新建urls.py,再将urlpatterns列表复制过来
from django.urls import path,include,re_path
from app01 import views
urlpatterns = [
path('index/', views.index),
path('home/', views.home,name='home'),
path('register/', views.register,name='register'),
path('test/', views.test,name='test'),
]
然后再总的项目urls.py中改写
from django.contrib import admin
from django.urls import path
from django.conf.urls import include
import app01
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/', include('app01.urls')),
]
这样在浏览器中输入路径就能访问了
分发前:http://127.0.0.1:8000/test/
分发后:http://127.0.0.1:8000/app01/test/
分发时遇到的问题
触发条件:
同时拥有app01,app02,并且分别配置了templates目录,总路由下也做了两个app的分发
现在两个app下都有同一个视图函数test
def test(request):
return render(request,'test.html')
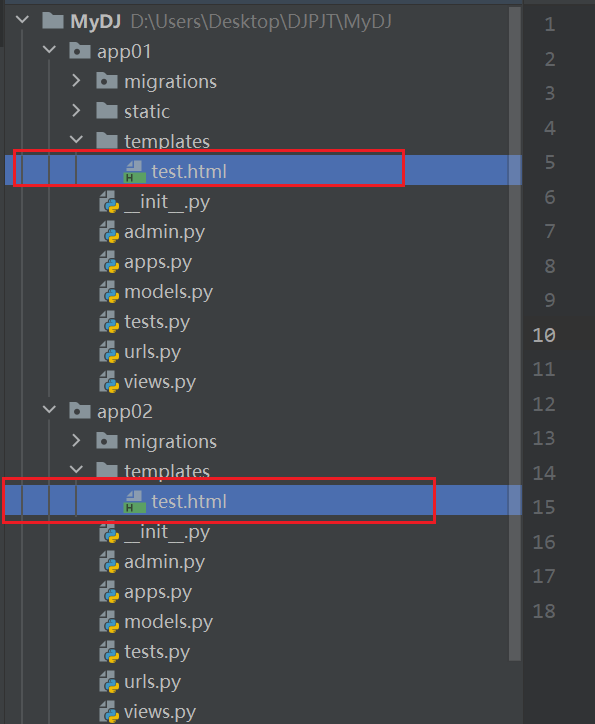
此时同时存在两个同名的test.html文件
<p>你好,我是app01{% url 'test' %}</p>
<p>你好,我是app02{% url 'test' %}</p>
那么这个时候浏览器访问app01/test应该是这样的
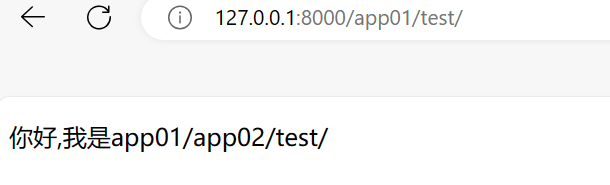
那么访问app02/test应该显示的是你好,我是app02/app02/test,但结果却是
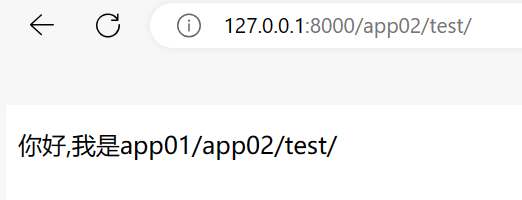
明显app2的视图函数读取到了app1中的templates目录,这是因为当存在同名路径时Django并不会区分,而是默认解析第一个读到的路由路径
解决方案1
直接修改html文件的名称,或者templates目录的名称对其进行区分
解决方案2
在各个app中的templates目录下新建一个目录,然后将该目录名添加在视图函数的render解析的路径前
例如
修改前: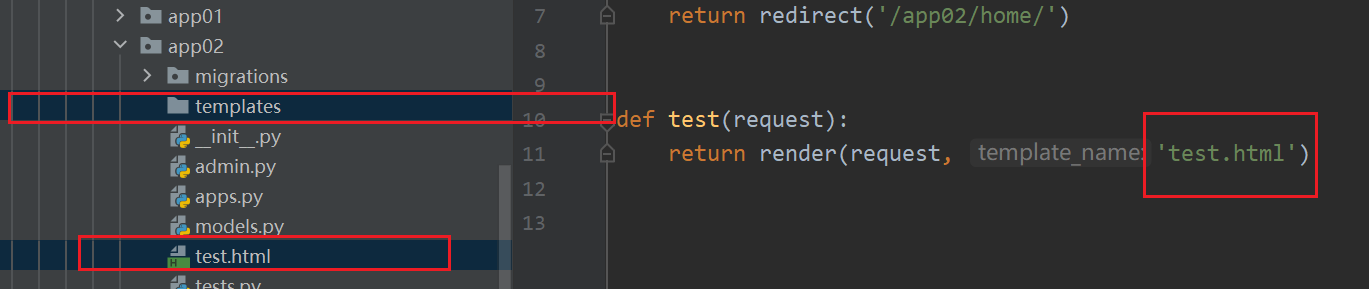
修改后: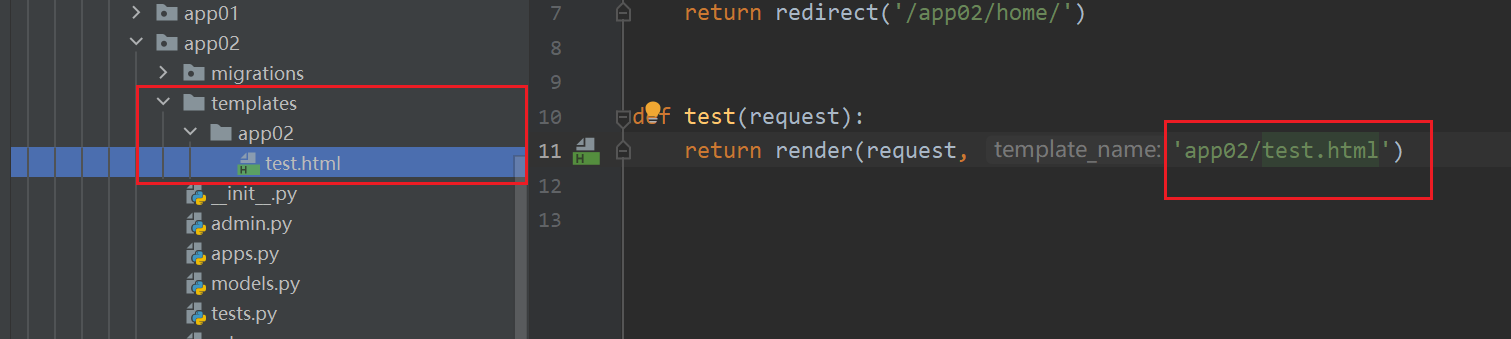
命名空间
为什么要用命名空间?
添加命名空间可以更好的进行url反向解析,通过指定某个app的命名空间来确保解析正确的url
应用命名空间app_name
例如在两个app中都有一个name=index的函数,那么在没有命名空间的情况下你也无法确定他通过{% url 'index' %}或reverse('index')解析出来的是哪个app的url
解决方法
直接用命名空间将各个app隔离分离
Django提供了一个叫作app_name的属性
# 注意是在app下的urls.py
from django.urls import path,include,re_path
from app01 import views
app_name = 'app01' # 生成命名空间
urlpatterns = [
path('index/', views.index),
path('home/', views.home,name='home'),
path('register/', views.register,name='register'),
path('test/', views.test,name='test'),
]
# 视图层
def test(request):
a = reverse('app01:test') # 也就前面加个app名
# 模板层
{% url 'app01:test' %}
注:如果未在app01中搜寻到test路径,他会自动搜索其他app下的test路径,直到报错
实例命名空间namespace
有一种情况会用到namespace
两次分发都指向同一路径
# 总urls.py
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/', include('app02.urls',namespace='app01')),
path('app02/', include('app02.urls',namespace='app02')),
]
# app01下的urls.py
from django.urls import path,include,re_path
from app01 import views
app_name = 'app01'
urlpatterns = [
path('home/', views.home,name='home'),
path('register/', views.register,name='register'),
path('test/', views.test,name='test'),
]
# app02下的urls.py
from django.urls import path,include,re_path
from app02 import views
app_name = 'app02'
urlpatterns = [
path('home/', views.home,name='home'),
path('test/', views.test,name='test'),
path('register/', views.register,name='register'),
]
此时当浏览器访问路径的时候app01/register和app02/register访问的都是app2中的register,当然你访问home\test都是访问的app02的

那么此时如何分辨他们的命名空间呢?
request.resolver_match.namespace可以返回当前url的命名空间
def test(request):
now_namespace = request.resolver_match.namespace
print(now_namespace)
return HttpResponse(now_namespace)

这样就可以根据不同的namespace执行不同的命令了
路径转换
五种转换器
- str
- 匹配除了 ‘/’ 之外的非空字符串。
- 如果表达式内不包含转换器,则会默认匹配字符串。
- int
- 匹配 0 或任何正整数。返回一个 int 。
- slug
- 匹配任意由 ASCII 字母或数字以及连字符和下划线组成的短标签。
- 比如,building-your-1st-django-site 。
- uuid
- 匹配一个格式化的 UUID 。为了防止多个 URL 映射到同一个页面,必须包含破折号并且字符都为小写。
- 比如,075194d3-6885-417e-a8a8-6c931e272f00。返回一个 UUID 实例。
- path
- 匹配非空字段,包括路径分隔符 ‘/’ 。
非空字符串。 - 如果表达式内不包含转换器,则会默认匹配字符串。
- 匹配非空字段,包括路径分隔符 ‘/’ 。