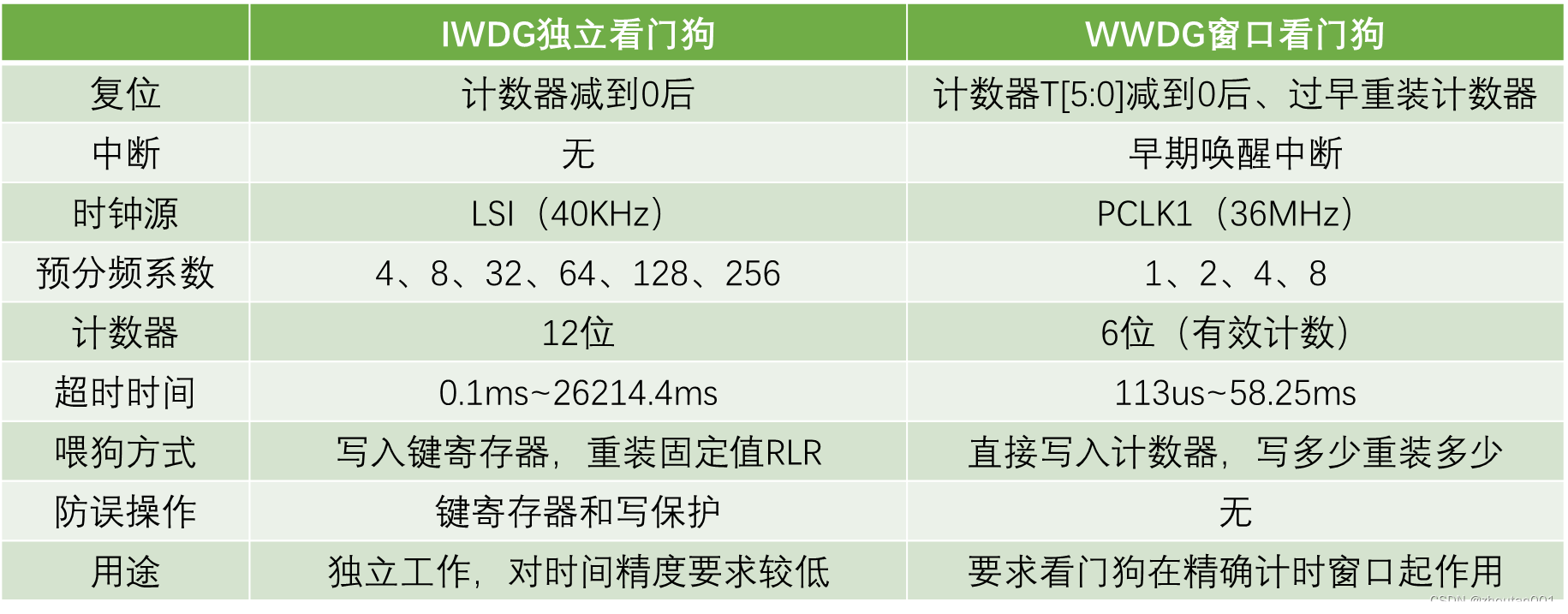
目录
- 加载图像数据
- 加载点云数据
- 模型推理并计时
- 预热操作
- 模型推理
- 检查点云输入数据量
- 打印信息中CopyLidar部分的计算和耗时
- 打印信息中ImageNrom图像预处理部分计算和耗时
该系列文章与qwe、Dorothea一同创作,喜欢的话不妨点个赞。
接上面的文章,目光聚焦回在main.cpp中。create_core、update后,基本上内存开辟、内存赋值、预计算等前期准备工作都准备的差不多了。
后续是输入数据的加载和预处理。
加载图像数据
255行加载图片,data是准备好的6张图片数据数据。通过stbi_load加载图片。把六张图片存储到vector容器中。

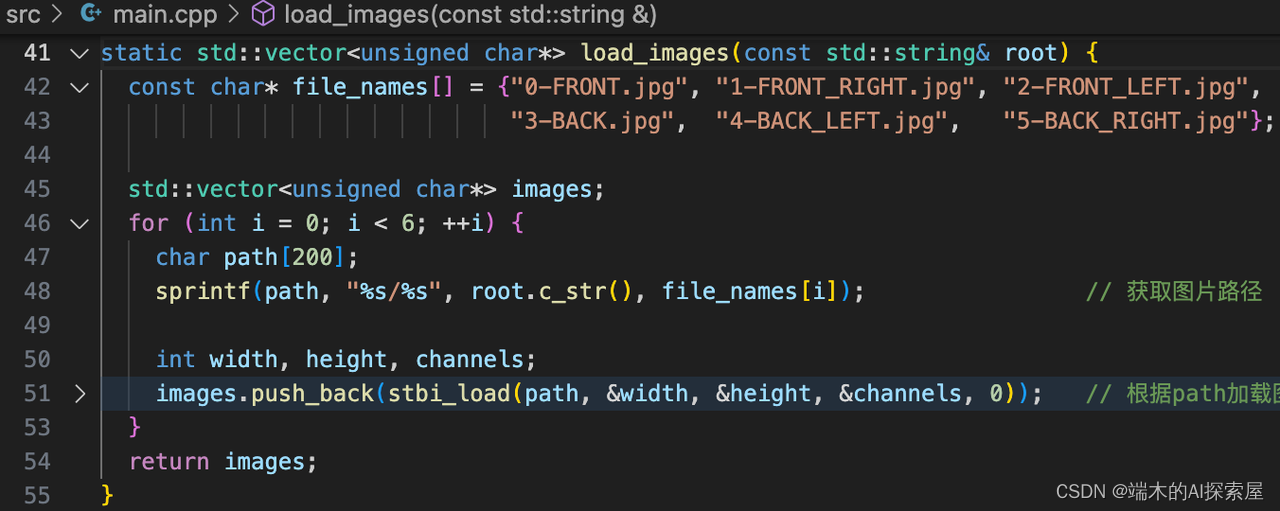
加载点云数据
点云数据的加载使用了nvidia提供在common文件夹下的nv::Tensor中加载。

模型推理并计时
预热操作
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.35738 ms
[⏰ [NoSt] ImageNrom]: 2.46902 ms
[⏰ Lidar Backbone]: 5.27267 ms
[⏰ Camera Depth]: 0.03472 ms
[⏰ Camera Backbone]: 88.00665 ms
[⏰ Camera Bevpool]: 0.33485 ms
[⏰ VTransform]: 9.40954 ms
[⏰ Transfusion]: 15.54534 ms
[⏰ Head BoundingBox]: 6.94374 ms
Total: 125.548 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.35331 ms
[⏰ [NoSt] ImageNrom]: 2.57843 ms
[⏰ Lidar Backbone]: 2.65114 ms
[⏰ Camera Depth]: 0.04096 ms
[⏰ Camera Backbone]: 2.36442 ms
[⏰ Camera Bevpool]: 0.31027 ms
[⏰ VTransform]: 0.55091 ms
[⏰ Transfusion]: 1.48685 ms
[⏰ Head BoundingBox]: 3.26451 ms
Total: 10.669 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.31674 ms
[⏰ [NoSt] ImageNrom]: 2.36669 ms
[⏰ Lidar Backbone]: 2.64192 ms
[⏰ Camera Depth]: 0.02867 ms
[⏰ Camera Backbone]: 2.35008 ms
[⏰ Camera Bevpool]: 0.30925 ms
[⏰ VTransform]: 0.55398 ms
[⏰ Transfusion]: 1.48275 ms
[⏰ Head BoundingBox]: 3.26848 ms
Total: 10.635 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.29885 ms
[⏰ [NoSt] ImageNrom]: 2.41459 ms
[⏰ Lidar Backbone]: 2.65632 ms
[⏰ Camera Depth]: 0.03066 ms
[⏰ Camera Backbone]: 2.35213 ms
[⏰ Camera Bevpool]: 0.30720 ms
[⏰ VTransform]: 0.54880 ms
[⏰ Transfusion]: 1.48378 ms
[⏰ Head BoundingBox]: 3.27782 ms
Total: 10.657 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.33312 ms
[⏰ [NoSt] ImageNrom]: 2.36157 ms
[⏰ Lidar Backbone]: 2.66854 ms
[⏰ Camera Depth]: 0.02867 ms
[⏰ Camera Backbone]: 2.35827 ms
[⏰ Camera Bevpool]: 0.31642 ms
[⏰ VTransform]: 0.55296 ms
[⏰ Transfusion]: 1.48378 ms
[⏰ Head BoundingBox]: 3.24813 ms
Total: 10.657 ms
=============================================
==================BEVFusion===================
[⏰ [NoSt] CopyLidar]: 0.33293 ms
[⏰ [NoSt] ImageNrom]: 2.34477 ms
[⏰ Lidar Backbone]: 2.63680 ms
[⏰ Camera Depth]: 0.04506 ms
[⏰ Camera Backbone]: 2.35110 ms
[⏰ Camera Bevpool]: 0.31334 ms
[⏰ VTransform]: 0.55398 ms
[⏰ Transfusion]: 1.48378 ms
[⏰ Head BoundingBox]: 3.27475 ms
Total: 10.659 ms
=============================================
Avg times:
[⏰ [NoSt] CopyLidar]: 0.354070 ms
[⏰ [NoSt] ImageNrom]: 2.338320 ms
[⏰ Lidar Backbone]: 2.647456 ms
[⏰ Camera Depth]: 0.030003 ms
[⏰ Camera Backbone]: 2.361158 ms
[⏰ Camera Bevpool]: 0.313024 ms
[⏰ VTransform]: 0.556032 ms
[⏰ Transfusion]: 1.486336 ms
[⏰ Head BoundingBox]: 3.515901 ms
Total: 10.909910 ms
-
预热:上面这个是推理后的耗时结果,可以看到第一次预热的耗时是之后推理一次耗时的10倍,
engine进行推理的耗时占比最大。 -
原因:TensorRT的
IExecutionContext::enqueue函数是用来异步执行一个推理任务的。这个函数的工作流程包括准备数据、调度CUDA核函数、等待GPU操作完成等步骤。在第一次调用enqueue函数时,TensorRT可能需要进行一些额外的初始化工作,如加载模型参数、优化计算图、分配内存等。因此,第一次调用enqueue函数的时间可能会比后续调用的时间长。 -
结论:在预热阶段进行的这些初始化工作在后续的推理任务中可以得到重用,因此后续的推理时间会显著减少。
模型推理

入参为图像数据,点云数据,点云数据数量和cuda流。因为最开始设置了enable_timer_属性为true,所以推理的时候会对时间进行一个统计。

检查点云输入数据量
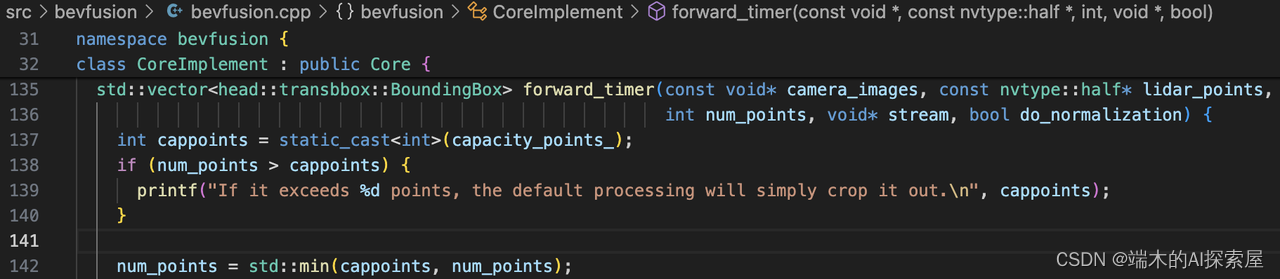
检查点云数据是否超过预设置的容量,超过的话就会调整点云数据数量。capacity_points设置为300000个点。
打印信息中CopyLidar部分的计算和耗时
146行,创建流。
147行,开始记录时间。

start内部是使用cudaEventRecord进行记录。在cuda流中插入事件begin_,并记录当前时间。


149-151行,计算点云数据占用内存大小,然后将数据在host和device上进行拷贝。

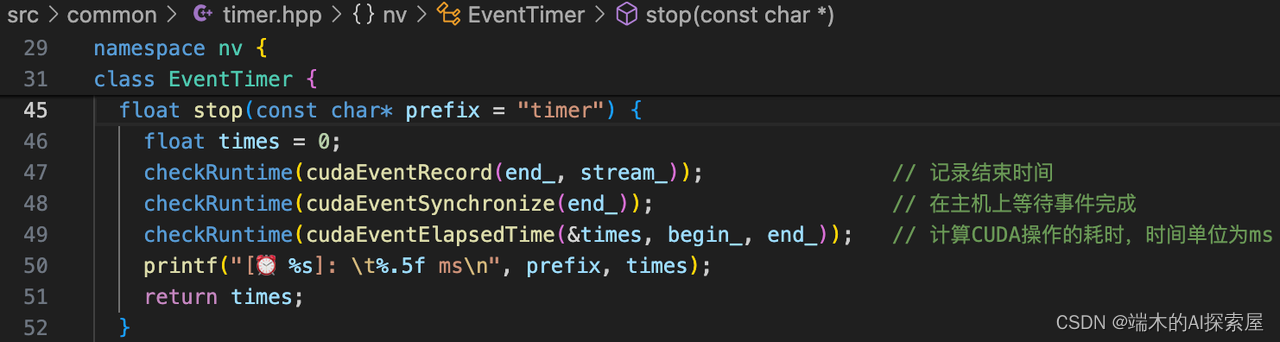
在cuda流中插入事件end_,并记录当前时间,最后通过cudaEventElapsedTime函数来计算这两个事件之间的时间,打印耗时的信息。
打印信息中CopyLidar部分的,经过10次推理的平均耗时为0.35ms。
打印信息中ImageNrom图像预处理部分计算和耗时
这里的重点在于,nvidia提供了一个专门的核函数,进行图像的预处理。
CUDA-BEVFusion的双线性插值后的像素值与opencv双线性插值结果一致。
具体我们一步一步看一看代码

- 156行、158行是计时的岂止。
- 157行,执行了
normalizer的forward,对入参图片,进行归一化。

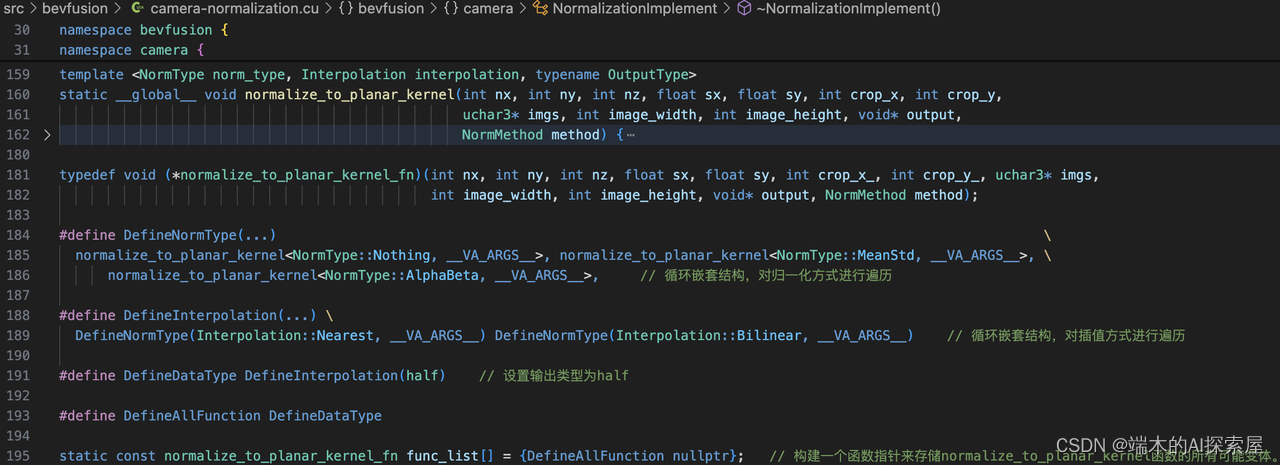
220行,是forward的具体实现。这里插值方式是双线性差值,方法实用MeanStd。即减均值除标准差(还有缩放和平移,暂时不管)。
223行,根据计算出的index,从函数指针列表func_list中,拿到具体前向的时候,要用到的那个特化的核函数指针。
这里220行之所以计算index,见下方对运行时转编译时的具体介绍,篇幅可能比较长。
-
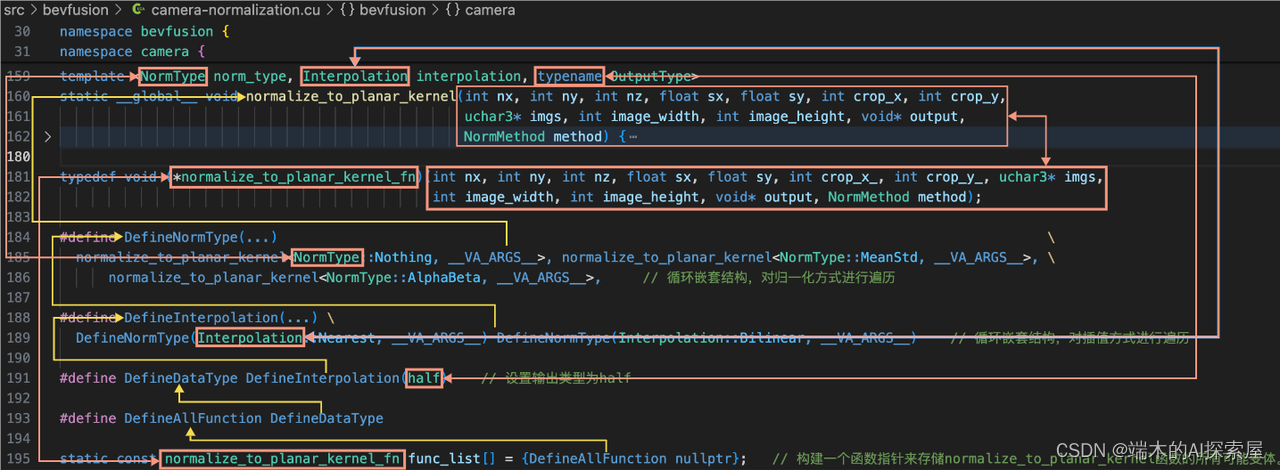
181行代码解释
-
这行代码定义了一个函数指针类型,命名为
normalize_to_planar_kernel_fn。这是 C++ 中的一个类型定义(typedef),用于创建新的类型名称。在这个特定的例子中,它定义了一个指向特定签名函数的指针类型。-
typedef: 关键字,用于定义一个新的类型名称。 -
void (*normalize_to_planar_kernel_fn): 这部分指明了normalize_to_planar_kernel_fn是一个指向函数的指针的类型。这个函数的返回类型是void,即不返回任何值。 -
函数参数列表:
int nx, int ny, int nz, float sx, float sy, int crop_x_, int crop_y_, uchar3* imgs, int image_width, int image_height, void* output, NormMethod method。这些是该函数的参数,包括整数、浮点数、指针和自定义类型NormMethod的参数。
因此,
normalize_to_planar_kernel_fn可以被用来声明任何具有上述签名的函数的指针。例如,如果有一个名为myFunction的函数,它的参数和返回类型与上述定义一致,你可以创建一个指向它的指针,如下所示: -
normalize_to_planar_kernel_fn myFunctionPtr = &myFunction;
这种类型定义在 C++ 中非常有用,尤其是在处理函数指针时,因为它提供了一种清晰和简洁的方式来引用具有特定签名的函数。在复杂的程序或库中,使用这样的类型定义可以提高代码的可读性和可维护性。

- 上图,35行介绍了3种归一化类型,2种通道类型,2种插值方式。
-
上面两幅图介绍了宏定义与函数指针、枚举类型结合的运行时转编译时。
-
func_list是一个函数指针数组,初始化为了DefineAllFunction(6个函数指针)和一个nullptr。DefineAllFunction是6个normalize_to_planar_kernel函数指针,这里使用了运行时转编译时的思路,在编译时预先通过遍历的方式构建所有版本的模版,在运行时通过索引来选择执行相应的函数。- 模版中包含了
1种输出类型,2种插值方法和3种归一化方法,所以func_list储存了6(1 * 2 * 3 + 1)个地址,最后一个地址nullptr用作结束标记,在下面打印的结果中可以看到每个地址对应的模版版本。这里实际使用了half作为输出类型,双线性插值和均值方差方法。
-
这是一个运行时转编译时的思想:
- 好处:
- 省掉了大量的if判断。
normalize_to_planar_kernel核函数实现代码只需要写一次。

- 省掉了大量的if判断。
- 好处:
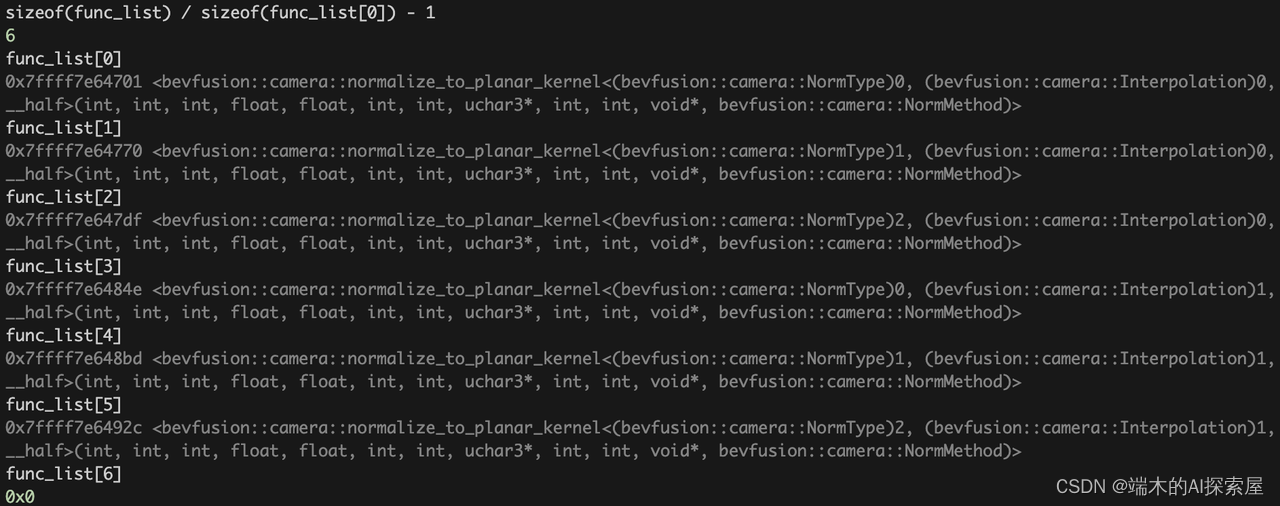
- 上图是195行函数列表中的7个元素。前面6个是2种插值方式与3种归一化类型特化出来的6个函数指针。第一个元素是
DefineAllFunction类型的一个空指针。
因此220行计算的index,与223行从func_list中取出具体的核函数就介绍完了。

- 上图无非就是将图像数据拷贝到
device上。

- 上图真正启动核函数。对图片进行归一化。
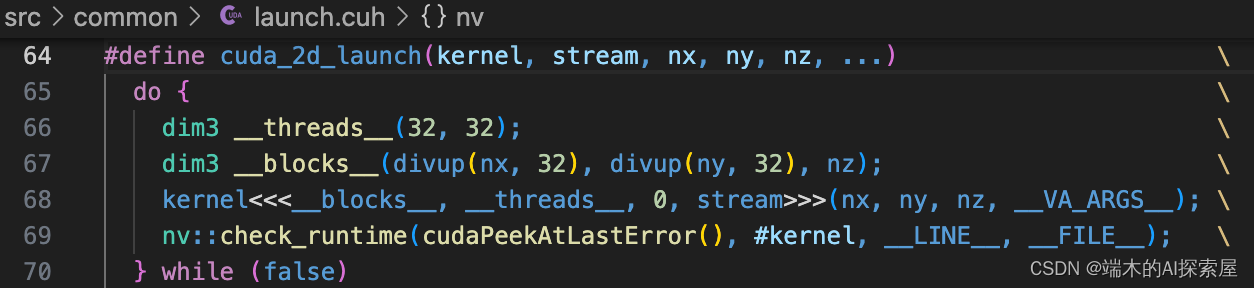
-
上图介绍了该项目核函数的启动方式,封装成了
cuda_2d_launch用于简化在 CUDA 中发起核函数(kernel)的过程。这个宏将核函数的启动和一些常见的设置封装在一起,以便于重复使用和减少代码冗余。 -
下方是具体解释
- 宏定义头部:
#define cuda_2d_launch(kernel, stream, nx, ny, nz, ...)
这行定义了一个宏,名为 cuda_2d_launch。它接受几个参数:
kernel:要启动的 CUDA 核函数。stream:CUDA 流,用于核函数的异步执行。nx,ny,nz:分别表示在x、y、z方向上的元素数量。...:表示可以传递给核函数的额外参数。
- do-while循环:
do { /* ... */ } while (false)
这是一个只执行一次的 do-while 循环,用于在宏定义中创建一个局部作用域。这样做可以避免在宏展开时可能出现的命名冲突。
- 线程和块的配置:
dim3 __threads__(32, 32);
dim3 __blocks__(divup(nx, 32), divup(ny, 32), nz);
这两行设置了 CUDA 核函数的线程和块维度。
__threads__:每个块的线程数,设置为32x32。__blocks__:根据输入的nx,ny,nz计算需要多少个块。divup是一个辅助函数,用于确保即使nx或ny不是32的倍数时,也能涵盖所有元素。
- 核函数启动:
kernel<<<__blocks__, __threads__, 0, stream>>>(nx, ny, nz, __VA_ARGS__);
使用 CUDA 的核函数启动语法 <<< >>> 启动核函数。__blocks__ 和 __threads__ 分别指定了块和线程的数量,0 表示核函数的动态共享内存大小(这里为0),stream 是执行核函数的 CUDA 流。kernel 后的括号中是传递给核函数的参数。
- 错误检查:
nv::check_runtime(cudaPeekAtLastError(), #kernel, __LINE__, __FILE__);
这行调用了一个错误检查函数,检查核函数启动后是否有错误发生。cudaPeekAtLastError 获取最后一次 CUDA 运行时调用的错误状态。
cudaPeekAtLastError获取最后一次 CUDA 运行时调用的错误状态。

这里使用了2维的方式构建网格维度和块维度,下面就是这些线程块和线程的布局,使用这种方式就可以表示3维的坐标系,将整个数据划分为32x32的块,为每个像素分配一个线程进行处理。补充
(0-31, 0-31, 0) (32-63, 0-31, 0) (64-95, 0-31, 0) ... (671-703, 0-31, 0)
(0-31, 32-63, 0) (32-63, 32-63, 0) (64-95, 32-63, 0) ... (671-703, 32-63, 0)
(0-31, 64-95, 0) (32-63, 64-95, 0) (64-95, 64-95, 0) ... (671-703, 64-95, 0)
(0-31, 96-127, 0) (32-63, 96-127, 0) (64-95, 96-127, 0) ... (671-703, 96-127, 0)
... ... ... ... ...
(0-31, 223-225, 0) (32-63, 223-225, 0) (64-95, 223-225, 0) ... (671-703, 223-225, 0)
... ... ... ... ...
(0-31, 0-31, 1) (32-63, 0-31, 1) (64-95, 0-31, 1) ... (671-703, 0-31, 1)
... ... ... ... ...
(0-31, 223-225, 5) (32-63, 223-225, 5) (64-95, 223-225, 5) ... (671-703, 223-225, 5)

- 163、164行,获取输出图像中像素的宽度和高度的索引,并获取指向当前相机对应的图像中第一个像素点特征的指针。


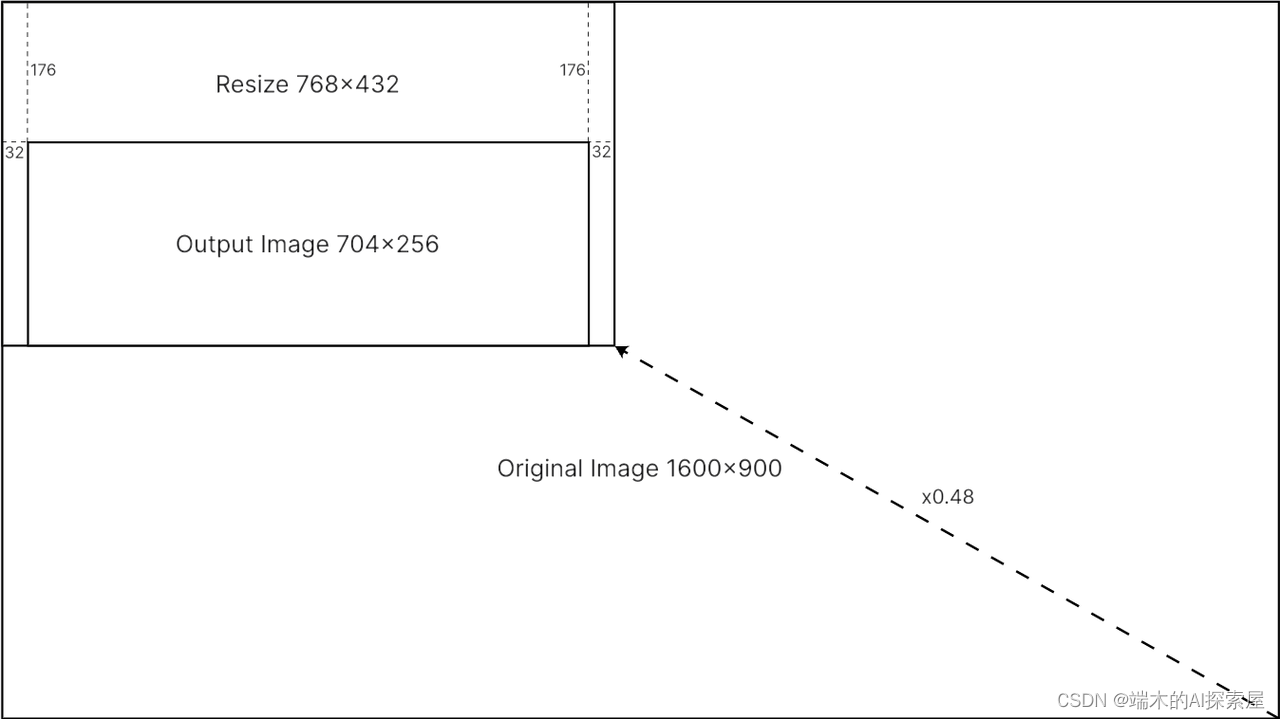
上面这张图像是MIT中的做法,将图像先进行缩放,然后进行裁剪,得到了预处理后的图像。
这里是使用双线性插值,需要获得尺寸为704x256的预处理图像,需要对图像左侧填充32个像素,然后对上侧填充176个像素,进行逆缩放得到704x256图像中每个像素点对应原图1600x900上的位置,之后对当前像素点的四个临近点应用双线性插值来计算像素值。rgb用于存储相对于还原后像素点最近的左下、左上、右上和右下四个点的像素值。

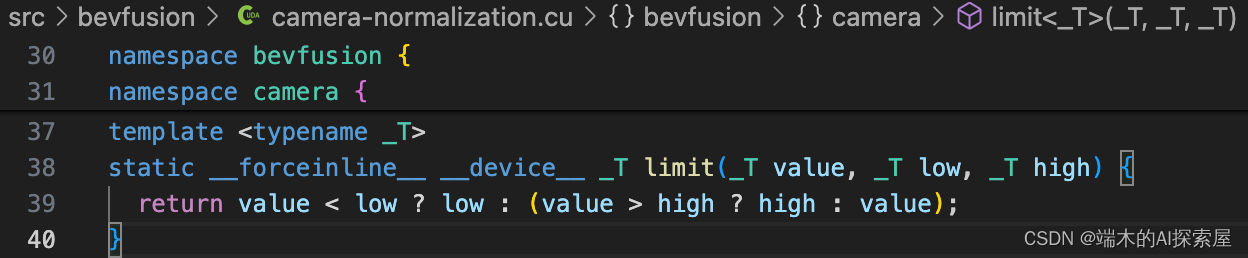
floorf函数是一个单精度浮点数的向下取整函数。通过向下取整获得了相对于还原后像素点的最近的整数左边界和上边界,通过这两个值加1就可以获得右边界和下边界,然后通过判断是否超过最小或最大边界来更新边界数值。


rint 函数是标准数学库 <cmath> 中的一个函数,用于将double类型的数值四舍五入到最接近整数,返回的数值还是double类型。然后隐式转换成int
将间距1划分为2048份,计算四个相邻点的权重值。

存储左上、右上、左下、右下四个像素点的特征。
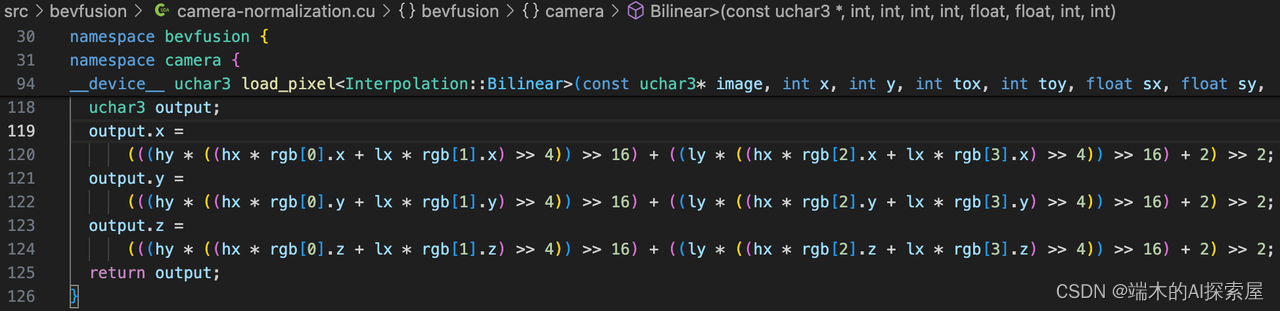
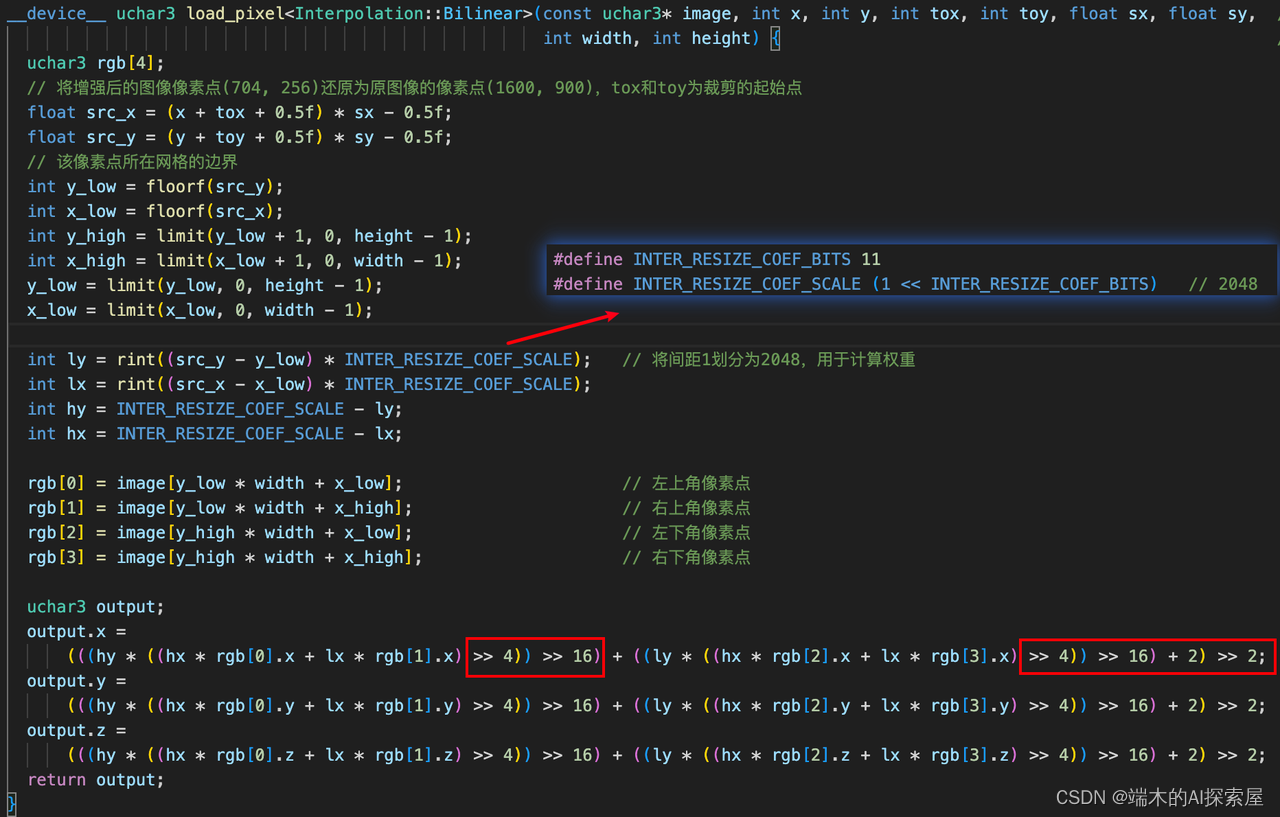
-
上图计算output.x中

INTER_RESIZE_COEF_SCALE = 1 << 11- 任何数据乘以
(1 << 11)实际上是将该数据乘以 2 11 2^{11} 211。在二进制层面上,这等同于将数据的所有位向左移动 11 位。
- 任何数据乘以
((hx * rgb[0].x + lx * rgb[1].x) >> 4)相当于将左移11位的数,右移4位。目前是左移7hy * ((hx * rgb[0].x + lx * rgb[1].x) >> 4))左移11的与左移7的相乘,目前是左移18((hy * ((hx * rgb[0].x + lx * rgb[1].x) >> 4)) >> 16),目前是左移2- 最后再右移2.精度对齐。
- 这里的对齐:主要指将数据的二进制表示向左或向右移动一定数量的位。
- 右移4,16,2与OpenCV中的双线性插值匹配,两者的双线性插值结果相同。
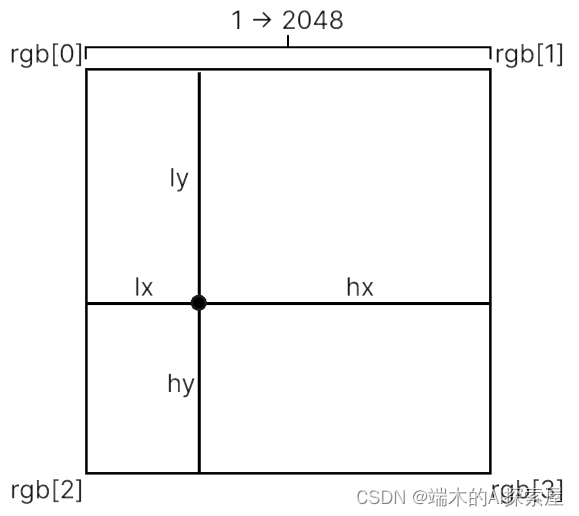
通过加权和来计算还原后的像素点的三个通道的数值,作为缩放和裁剪后图像中像素点的特征值。

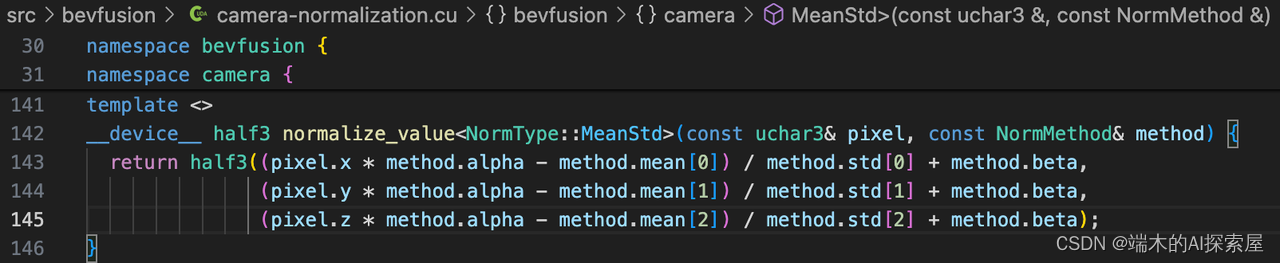
-
对像素点的特征进行均值方差归一化计算。
-
注意:这里是用了模板特化

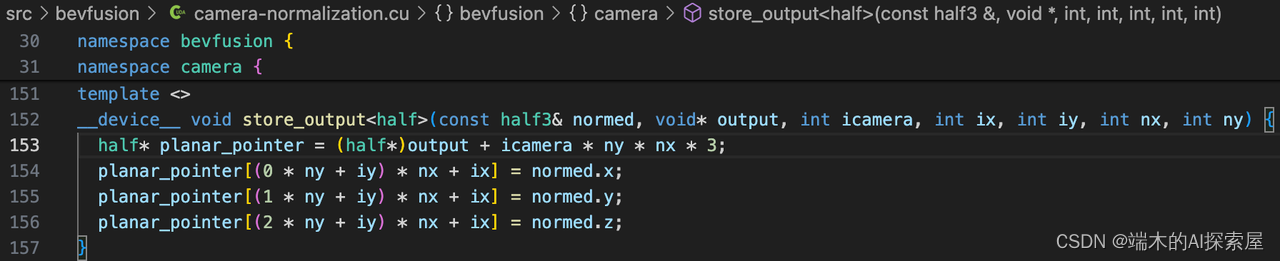
将预处理的图像像素点的特征值保存到output中,数据类型为half。

namespace nvtype {
typedef struct {
unsigned short __x;
} half;
}
struct __CUDA_ALIGN__(2) __half {
protected:
unsigned short __x;
...
}
最后返回预处理后的图像,并将类型从half转换为nvtype::half,从数值上看没有什么区别,都是unsigned short类型。



![Sqli-labs靶场第19关详解[Sqli-labs-less-19]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/b8b5350609474fb6b9fd413c076cfad3.png)

![Sqli-labs靶场第20关详解[Sqli-labs-less-20]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/99238a6364ee4c5eb53801faff3fe72a.png)