简介
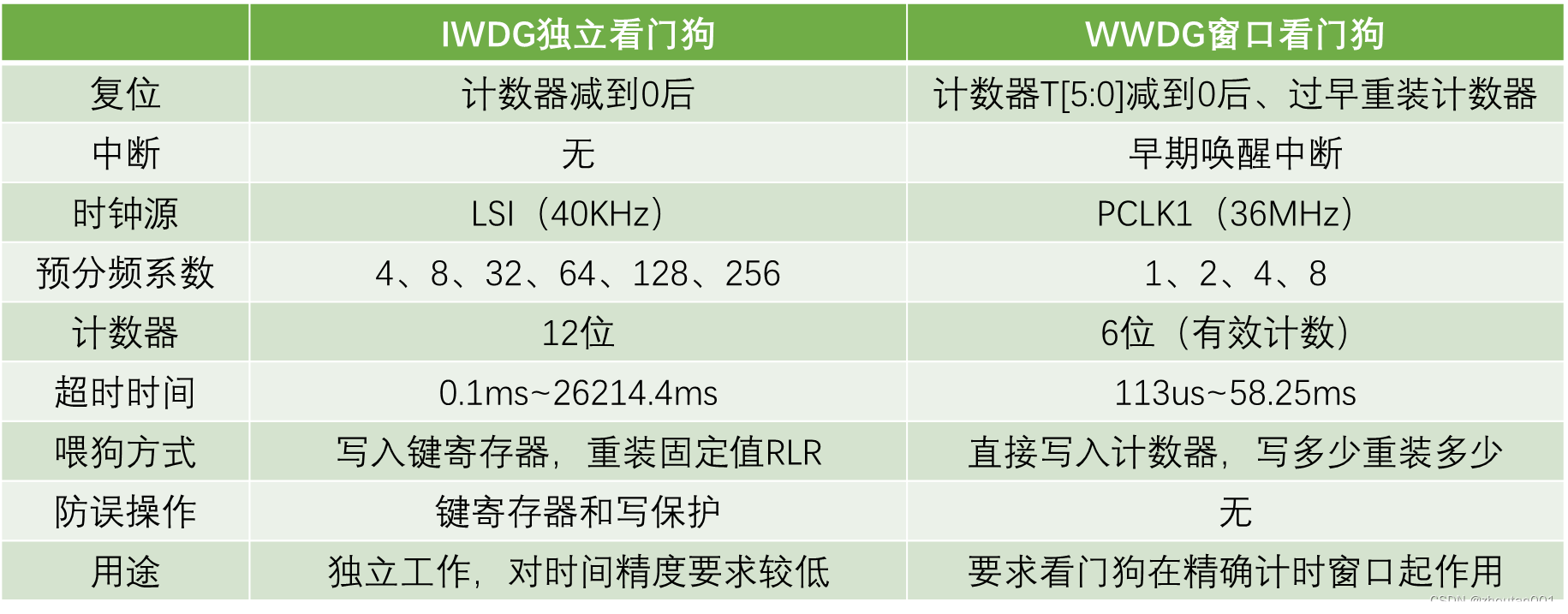
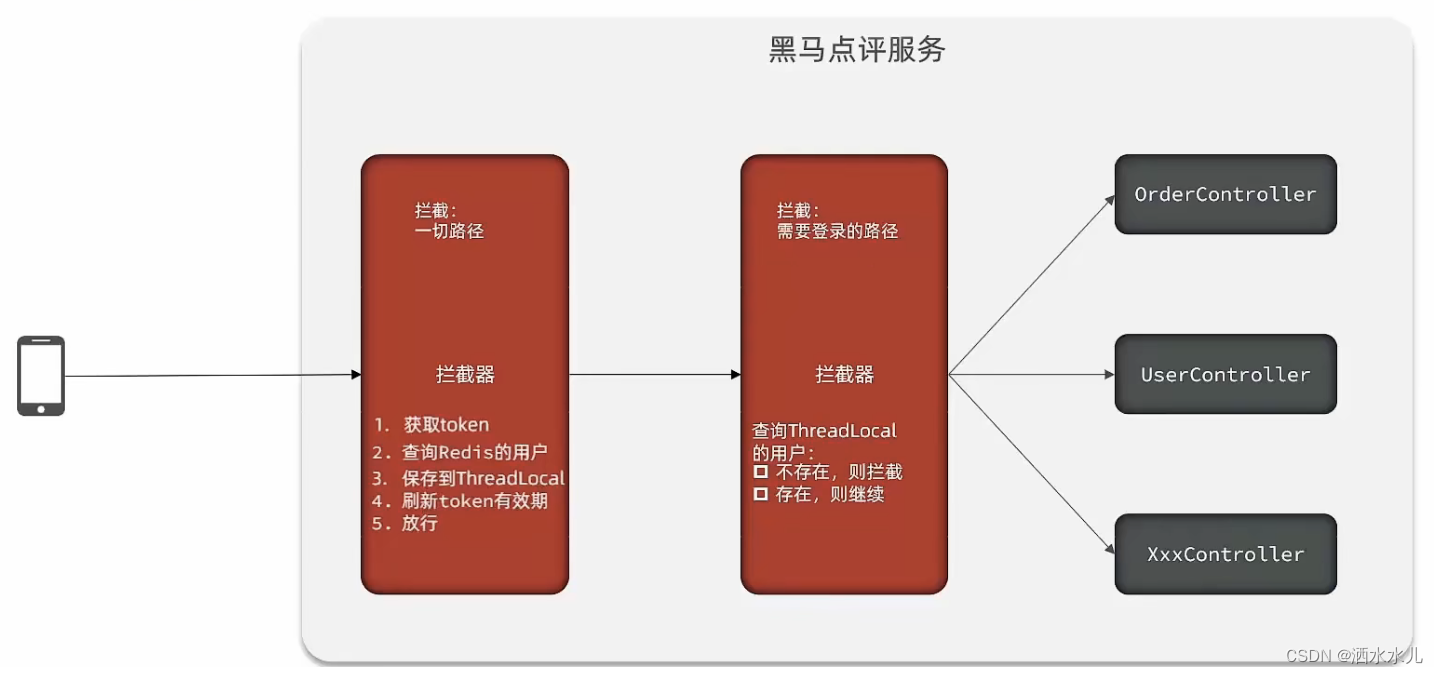
hive架构原理
1.客户端可以采用jdbc的方式访问hive
2.客户端将编写好的HQL语句提交,经过SQL解析器,编译器,优化器,执行器执行任务。hive的存算都依赖于hadoop框架,所依赖的真实数据存放在hdfs中,解析好的mapreduce程序,提交给yarn。
3.另外hive框架自带一个名为debay的数据库,其作用是用来记录hdfs上数据的存放位置,也就是说,在客户端提交任务之后,hive优先会去数据库中查询所需要数据在hdfs上面的路径信息,然后在拿着路径信息再去hdfs寻找数据。但是debay有一个缺点就是只支持单用户访问,通常情况下,会将debay数据库换成其他数据库。
安装postgresql
在hadoop集群中安装postgresql,并不需要所有节点同步,只需要安装在集群中得其中一个节点就可以,保证该节点对于得访问
cd /home/hadoop/ --进入新建用户指定目录
sudo curl -O https://ftp.postgresql.org/pub/source/v16.2/postgresql-16.2.tar.gz --下载安装包
tar -zxvf postgresql-16.2.tar.gz --解压压缩包
sudo yum install -y bison flex readline-devel zlib-devel zlib zlib-devel gcc gcc-c++ openssl-devel python3-devel python3 --下载安装数据库基本依赖包,Python依赖为可选项
cd postgresql-16.2
./configure --prefix=/home/hadoop/pg --with-openssl --with-python #拟安装至/home/hadoop/pg
sudo mkdir /home/hadoop/pg --创建装载所需文件夹
make world && make install-world
sudo vim /etc/profile
export PATH=/home/hadoop/pg/bin:$PATH --指定bin文件路径 确保准备
export PGDATA=/home/hadoop/pg/data --指定data文件路劲 在初始化时会将data装载这个路径
export PGUSER=hadoop
export PGDATABASE=postgres
sudo source /etc/profile --加载环境变量内容
cd /home/hadoop/pg/bin --进入指令包
./initdb -D $PGDATA -U hadoop -W --初始化数据库
修改pg_hba.conf、postgresql.conf
vim $PGDATA/pg_hba.conf
调整以下ip4\ip6得访问IP白名单以及密码加密形式
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all scram-sha-256
# IPv4 local connections:
host all all 0/0 scram-sha-256
# IPv6 local connections:
host all all ::1/128 trust
修改监听配置
vim $PGDATA/postgresql.conf
定义以下参数
listen_addresses = '*' # what IP address(es) to listen on;
启动数据库
pg_ctl start --启动数据库
pg_ctl status --查看数据库运行状态
安装hive
进入hive官网下载压缩包apache-hive-3.1.3-bin.tar.gz然后上传到指定服务器上,也可以使用以下指令进行下载
wget -y https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz --no-check-certificate
修改hive配置
在3.1.3版本中hive得conf配置文件hive-site.xml并没有被创建,官方给出了该配置文件得模板文件hive-default.xml.template

创建hive-site.xml文件并进行编辑配置
touch hive-site.xml
将以下配置内容打入该配置文件,执行以下命令
cat > hive-site.xml <<EOF
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://localhost:5432/postgres</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
</configuration>
EOF
配置hive 环境变量
sudo vim /etc/profile
##加入以下环境变量
export HIVE_HOME=/home/hadoop/hive
export PATH=$HIVE_HOME/bin:$PATH
## 加载环境变量值
source /etc/profile
上传元数据库对应得JDBC驱动包上传到$HIVE_HOME/lib目录下
初始化源数据库
schematool -initSchema -driver org.postgresql.Driver -url jdbc:postgresql://localhost:5432/postgres -user hadoop -password hadoop -dbType postgres -verbose
在初始数据库得时候会有以下报错
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
hadoop与hive 依赖包冲突,此时删掉hive/lib下得log4j-slf4j-impl-2.17.1.jar包便可
在服务器上其启动hive得元数据进程和服务进程
nohup hive --service metastore &
nohup hive --service hiveserver2 &
##此时会将后台进程的信息自动追加存放到当前路径得nohup.out文件中
##使用以下命令查看
cat nohup.out
此时会发现有两个runjar 进程
默认情况下hiveserver2对外的端口号是10000
jps
netstat -ntulp |grep 10000
开启hdfs中的 /hive/warehouse的读写权限
执行命令:hdfs dfs -chmod -R 777 /hive/warehouse
hdfs dfs -chmod -R 777 /hive/warehouse
hdfs dfs -ls /hive/warehouse
##此时可以看到权限已经发生了表更
hdfs dfs -ls /hive/warehouse
启动spark的SparkSubmit进程
cd $SPARK_HOME
cd sbin
./start-thriftserver.sh
此时就可以使用外部编译器通过sparkSQL 链接到hive。使用的是sparkSQL的驱动,hdfs的存储,postgresql的元数据管理。
此时使用IDEA链接sparkSQL时会出现以下报错
Error: Could not open client transport with JDBC Uri: jdbc:hive2://10.0.0.105:10000:
Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: andy is not allowed to impersonate andy (state=08S01,code=0)
需要修改hadoop 下的core-site.xml文件(所有节点同步)
vim $HADOOP_HOME/etc/hadoop/core-site.xml
增加以下内容
<!-- 设置超级代理 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
此时对重启hadoop集群以及相关组件(hbase、spark等) 和metastore 、hiveserver2 服务
start-all.sh ##主节点停掉hadoop,再此重新开启
nohup hive --service metastore &
nohup hive --service hiveserver2 &
再次尝试便可以连接成功
此时使用sparkSQL就和使用平时使用的数据库一样
在SPAKR页面我创建了一个表,实际存储时在hdfs
使用以下命令进行查看
[hadoop@vm05 ~]$ hdfs dfs -ls /hive
Found 1 items
drwxrwxrwx - hadoop supergroup 0 2024-03-03 14:36 /hive/warehouse
[hadoop@vm05 ~]$ hdfs dfs -ls /hive/warehouse
Found 2 items
drwxrwxrwx - hadoop supergroup 0 2024-03-03 13:34 /hive/warehouse/daemo.db
drwxr-xr-x - hadoop supergroup 0 2024-03-03 14:37 /hive/warehouse/text_db.db
[hadoop@vm05 ~]$ hdfs dfs -ls /hive/warehouse/text_db.db
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2024-03-03 14:37 /hive/warehouse/text_db.db/text1
[hadoop@vm05 ~]$
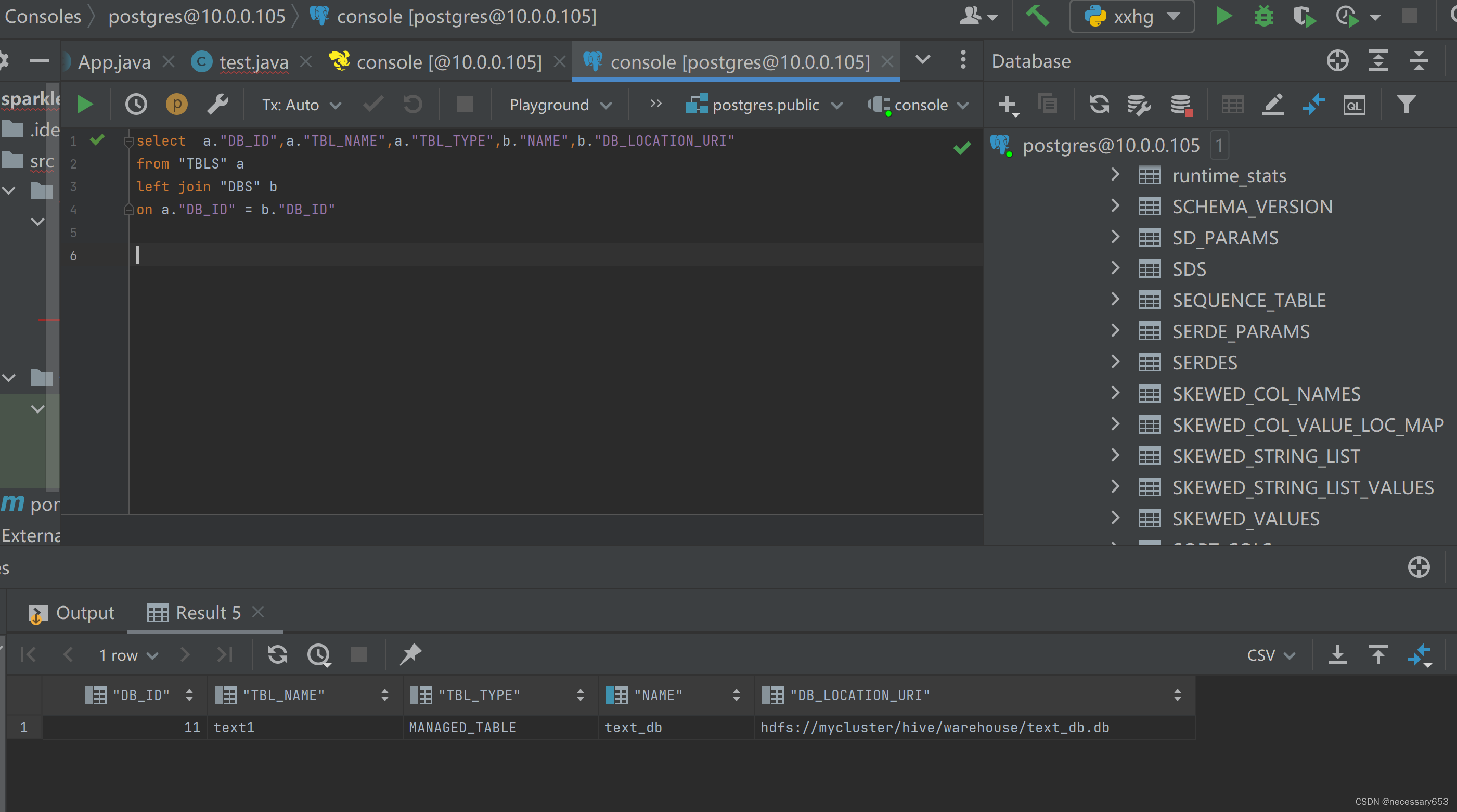
也可以通过元数据管理进行查看
打开postgresql 执行以下代码。可以查看到创建的表存储的
select a."DB_ID",a."TBL_NAME",a."TBL_TYPE",b."NAME",b."DB_LOCATION_URI"
from "TBLS" a
left join "DBS" b
on a."DB_ID" = b."DB_ID"
![Sqli-labs靶场第19关详解[Sqli-labs-less-19]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/b8b5350609474fb6b9fd413c076cfad3.png)

![Sqli-labs靶场第20关详解[Sqli-labs-less-20]自动化注入-SQLmap工具注入](https://img-blog.csdnimg.cn/direct/99238a6364ee4c5eb53801faff3fe72a.png)