https://blog.51cto.com/u_14014612/5677262
Stream到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
“集合讲的是数据,Stream讲的是计算!”
流的构成
当我们使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示。
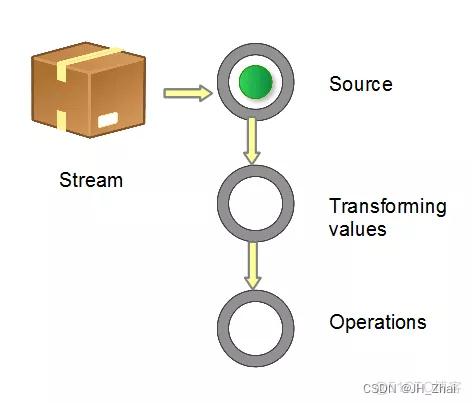
流的操作类型分为两种:
- Intermediate:一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
- Terminal:一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
Stream 的特性可以归纳为:
- 不是数据结构
- 它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。
- 它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
- 所有 Stream 的操作必须以 lambda 表达式为参数
不支持索引访问 - 你可以请求第一个元素,但无法请求第二个,第三个,或最后一个。不过请参阅下一项。
- 很容易生成数组或者 List
- 惰性化
- 很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。
- Intermediate 操作永远是惰性化的。
- 并行能力 当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
- 可以是无限的
- 集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成。






![【寒假每日一题】洛谷 P6263 [COCI2014-2015#3] STROJOPIS](https://img-blog.csdnimg.cn/2449ed9d6755445594a83385ecdb51b2.png)